Zookeeper在hadoop中充当啥角色,dubbo使用zookeeper又是干嘛的?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper在hadoop中充当啥角色,dubbo使用zookeeper又是干嘛的?相关的知识,希望对你有一定的参考价值。
Apache Zookeeper是我最近遇到的最酷的技术,我是在研究Solr Cloud功能的时候发现的。Solr的分布式计算让我印象深刻。你只要开启一个新的实例就能自动在Solr Cloud中找到。它会将自己分派到某个分片中,并确定出自己是一个Leader(源)还是一个副本。不一会儿,你就可以在你的那些服务器上查询到了。即便某些服务器宕机了也可以继续工作。非常动态、聪明、酷。将运行多个应用程序作为一个逻辑程序并不是什么新玩意。事实上,我在几年前就已写过类似的软件。这种架构比较让人迷惑,使用起来也费劲。为此Apache Zookeeper提供了一套工具用于管理这种软件。
为什么叫Zoo?“因为要协调的分布式系统是一个动物园”。
在本篇文章中,我将说明如何使用php安装和集成Apache ZooKeeper。我们将通过service来协调各个独立的PHP脚本,并让它们同意某个成为Leader(所以称作Leader选举)。当Leader退出(或崩溃)时,worker可检测到并再选出新的leader。
ZooKeeper是一个中性化的Service,用于管理配置信息、命名、提供分布式同步,还能组合Service。所有这些种类的Service都会在分布式应用程序中使用到。每次编写这些Service都会涉及大量的修bug和竞争情况。正因为这种编写这些Service有一定难度,所以通常都会忽视它们,这就使得在应用程序有变化时变得难以管理应用程序。即使处理得当,实现这些服务的不同方法也会使得部署应用程序变得难以管理。
虽然ZooKeeper是一个Java应用程序,但C也可以使用。这里就有个PHP的扩展,由Andrei Zmievski在2009创建并维护。你可以从PECL中下载,或从GitHub中直接获取PHP-ZooKeeper。
要使用该扩展你首先要安装ZooKeeper。可以从官方网站下载。
$ tar zxfv zookeeper-3.4.5.tar.gz
$ cd zookeeper-3.4.5/src/c
$ ./configure --prefix=/usr/
$ make
$ sudo make install
这样就会安装ZooKeeper的库和头文件。现在准备编译PHP扩展。
$ cd$ git clone https://github.com/andreiz/php-zookeeper.git
$ cd php-zookeeper
$ phpize
$ ./configure
$ make
$ sudo make install
将“zookeeper.so”添加到PHP配置中。
$ vim /etc/php5/cli/conf.d/20-zookeeper.ini
因为我不需要运行在web服务环境下,所以这里我只编辑了CLI的配置。将下面的行复制到ini文件中。
extension=zookeeper.so
使用如下命令来确定扩展是否已起作用。
$ php -m | grep zookeeper
zookeeper
现在是时候运行ZooKeeper了。目前唯一还没有做的是配置。创建一个用于存放所有service数据的目录。
$ mkdir /home/you-account/zoo
$ cd$ cd zookeeper-3.4.5/
$ cp conf/zoo_sample.cfg conf/zoo.cfg
$ vim conf/zoo.cfg
找到名为“dataDir”的属性,将其指向“/home/you-account/zoo”目录。
$ bin/zkServer.sh start
$ bin/zkCli.sh -server 127.0.0.1:2181[zk: 127.0.0.1:2181(CONNECTED) 14] create /test 1
Created /test[zk: 127.0.0.1:2181(CONNECTED) 19] ls /[test, zookeeper]
此时,你已成功连到了ZooKeeper,并创建了一个名为“/test”的znode(稍后我们会用到)。ZooKeeper以树形结构保存数据。这很类似于文件系统,但“文件夹”(译者注:这里指非最底层的节点)又和文件很像。znode是ZooKeeper保存的实体。Node(节点)的说法很容易被混淆,所以为了避免混淆这里使用了znode。
因为我们稍后还会使用,所以这里我们让客户端保持连接状态。开启一个新窗口,并创建一个zookeeperdemo1.php文件。
<?php
class ZookeeperDemo extends Zookeeper
public function watcher( $i, $type, $key )
echo "Insider Watcher\n";
// Watcher gets consumed so we need to set a new one
$this->get( '/test', array($this, 'watcher' ) );
$zoo = new ZookeeperDemo('127.0.0.1:2181');$zoo->get( '/test', array($zoo, 'watcher' ) );
while( true )
echo '.';
sleep(2);
现在运行该脚本。
$ php zookeeperdemo1.php
此处应该会每隔2秒产生一个点。现在切换到ZooKeeper客户端,并更新“/test”值。
[zk: 127.0.0.1:2181(CONNECTED) 20] set /test foo
这样就会静默触发PHP脚本中的“Insider Watcher”消息。怎么会这样的?
ZooKeeper提供了可以绑定在znode的监视器。如果监视器发现znode发生变化,该service会立即通知所有相关的客户端。这就是PHP脚本如何知道变化的。Zookeeper::get方法的第二个参数是回调函数。当触发事件时,监视器会被消费掉,所以我们需要在回调函数中再次设置监视器。
现在你可以准备创建分布式应用程序了。其中的挑战是让这些独立的程序决定哪个(是leader)协调它们的工作,以及哪些(是worker)需要执行。这个处理过程叫做leader选举,在ZooKeeper Recipes and Solutions你能看到相关的实现方法。
这里简单来说就是,每个处理(或服务器)紧盯着相邻的那个处理(或服务器)。如果一个已被监视的处理(也即Leader)退出或者崩溃了,监视程序就会查找其相邻(此时最老)的那个处理作为Leader。
在真实的应用程序中,leader会给worker分配任务、监控进程和保存结果。这里为了简化,我跳过了这些部分。
创建一个新的PHP文件,命名为worker.php。
<?php
class Worker extends Zookeeper
const CONTAINER = '/cluster';
protected $acl = array(
array(
'perms' => Zookeeper::PERM_ALL,
'scheme' => 'world',
'id' => 'anyone' ) );
private $isLeader = false;
private $znode;
public function __construct( $host = '', $watcher_cb = null, $recv_timeout = 10000 )
parent::__construct( $host, $watcher_cb, $recv_timeout );
public function register()
if( ! $this->exists( self::CONTAINER ) )
$this->create( self::CONTAINER, null, $this->acl );
$this->znode = $this->create( self::CONTAINER . '/w-',
null,
$this->acl,
Zookeeper::EPHEMERAL | Zookeeper::SEQUENCE );
$this->znode = str_replace( self::CONTAINER .'/', '', $this->znode );
printf( "I'm registred as: %s\n", $this->znode );
$watching = $this->watchPrevious();
if( $watching == $this->znode )
printf( "Nobody here, I'm the leader\n" );
$this->setLeader( true );
else
printf( "I'm watching %s\n", $watching );
public function watchPrevious()
$workers = $this->getChildren( self::CONTAINER );
sort( $workers );
$size = sizeof( $workers );
for( $i = 0 ; $i < $size ; $i++ )
if( $this->znode == $workers[ $i ] )
if( $i > 0 )
$this->get( self::CONTAINER . '/' . $workers[ $i - 1 ], array( $this, 'watchNode' ) );
return $workers[ $i - 1 ];
return $workers[ $i ];
throw new Exception( sprintf( "Something went very wrong! I can't find myself: %s/%s",
self::CONTAINER,
$this->znode ) );
public function watchNode( $i, $type, $name )
$watching = $this->watchPrevious();
if( $watching == $this->znode )
printf( "I'm the new leader!\n" );
$this->setLeader( true );
else
printf( "Now I'm watching %s\n", $watching );
public function isLeader()
return $this->isLeader;
public function setLeader($flag)
$this->isLeader = $flag;
public function run()
$this->register();
while( true )
if( $this->isLeader() )
$this->doLeaderJob();
else
$this->doWorkerJob();
sleep( 2 );
public function doLeaderJob()
echo "Leading\n";
public function doWorkerJob()
echo "Working\n";
$worker = new Worker( '127.0.0.1:2181' );$worker->run();
打开至少3个终端,在每个终端中运行以下脚本:
# term1
$ php worker.php
I'm registred as: w-0000000001Nobody here, I'm the leader
Leading
# term2
$ php worker.php
I'm registred as: w-0000000002I'm watching w-0000000001
Working
# term3
$ php worker.php
I'm registred as: w-0000000003I'm watching w-0000000002
Working
现在模拟Leader崩溃的情形。使用Ctrl+c或其他方法退出第一个脚本。刚开始不会有任何变化,worker可以继续工作。后来,ZooKeeper会发现超时,并选举出新的leader。
虽然这些脚本很容易理解,但是还是有必要对已使用的Zookeeper标志作注释。
$this->znode = $this->create( self::CONTAINER . '/w-', null, $this->acl, Zookeeper::EPHEMERAL | Zookeeper::SEQUENCE );
每个znode都是EPHEMERAL和SEQUENCE的。
EPHEMRAL代表当客户端失去连接时移除该znode。这就是为何PHP脚本会知道超时。SEQUENCE代表在每个znode名称后添加顺序标识。我们通过这些唯一标识来标记worker。
在PHP部分还有些问题要注意。该扩展目前还是beta版,如果使用不当很容易发生segmentation fault。比如,不能传入普通函数作为回调函数,传入的必须为方法。我希望更多PHP社区的同仁可以看到Apache ZooKeeper的好,同时该扩展也会获得更多的支持。
ZooKeeper是一个强大的软件,拥有简洁和简单的API。由于文档和示例都做的很好,任何人都可以很容易的编写分布式软件。让我们开始吧,这会很有趣的。 参考技术A zookeeper是Dubbo服务的注册中心,provider提供服务后注册在zookeeper上, consumer可以接口和版本信息从zookeeper中获取相应的服务,服务对于consumer来说完全透明,根本感知不到该接口是来自本地和provider,就像引用本地的一个bean一样。 zookeeper可以实现服务的分布式,同时可以监控每个服务的状态以及调用次数情况等。追问
这里的zookeeper和hadoop中那个动物园管理者是一个东西吗
HDFS-SecondaryNameNode(SNN)角色介绍
它出现在Hadoop1.x版本中,又称辅助NameNode,在Hadoop2.x以后的版本中此角色消失。如果充当datanode节点的一台机器宕机或者损害,其数据不会丢失,因为备份数据还存在于其他的datanode中。但是,如果充当namenode节点的机器宕机或损害导致文件系统无法使用,那么文件系统上的所有文件将会丢失,因为我们不知道如何根据datanode的块重建文件。因此,对namenode实现容错非常重要。Hadoop提供了两种机制实现高容错性。
第一种机制是备份那些组成文件系统元数据持久状态的文件。Hadoop可以通过配置使namenode在多个文件系统上保存元数据的持久化状态。这些写操作是实时同步的,是原子操作。一般的配置是,将持久状态写入本地磁盘的同时,写入一个远程挂载的网络文件系统(NFS)。
另一种可行的方法是运行一个辅助namenode,但是它不能用作namenode,这个辅助namenode,在hadoop1.x中被称为secondary namenode,在hadoop2.x中,利用高可用(HA)解决单点故障问题。
Secondary namenode,以下简称SN,其重要作用是定期将编辑日志和元数据信息合并,防止编辑日志文件过大,并且能保证其信息与namenode信息保持一致。SN一般在另一台单独的物理计算机上运行,因为它需要占用大量CPU时间来与namenode进行合并操作,一般情况是单独开一个线程来执行操作过程。但是,SN保存的信息永远是滞后于namenode,所以在namenode失效时,难免会丢失部分数据。在这种情况下,一般把存储在NFS上的namenode元数据复制到SN并作为新的namenode。SN不是namenode的备份,可以作为备份。SN主要工作是帮助NN合并edits和fsimage,减少namenode的启动时间。
它不是NameNode的备份,但可以做备份,其主要工作是帮助NameNode合并editslog,减少NameNode的启动时间。SecondaryNameNode执行合并的时机决定于:
(1) 配置文件设置的时间间隔fs.checkpoint.period,默认为3600秒。
(2) 配置文件设置edits log大小fs.checkpoint.size,规定edits文件的最大值默认是64MB。
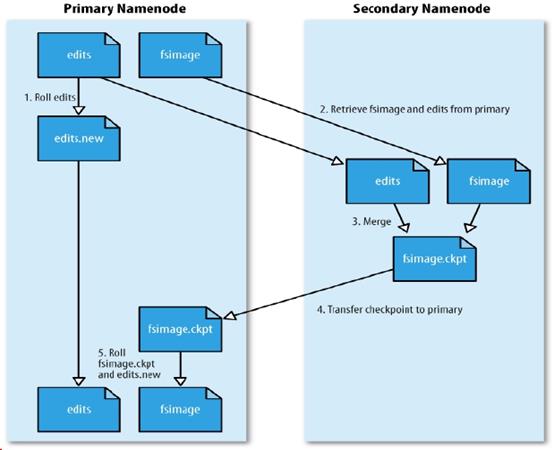
图1.6 SecondaryNameNode合并流程
如上图,当namenode运行了3600s后,SN取出fsimage和edits,合并,更新fsimage,命名为fsimage.ckpt,将fsimage.ckpt文件传入namenode中,合并过程中,客户端会继续上传文件。同时,namenode会创建新的edits.new文件,将合并过程中,产生的日志存入edits.new,namenode将 fsimage.ckpt,更名为fsimage,edits.new更名为edits。
如果在合并过程中,namenode损坏,那么,丢失了在合并过程中产生的edits.new,因此namenode失效时,难免会丢失部分数据。
以上是关于Zookeeper在hadoop中充当啥角色,dubbo使用zookeeper又是干嘛的?的主要内容,如果未能解决你的问题,请参考以下文章