C++ : C++基础 :从内存的角度看 char[]和char*
Posted John_xx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++ : C++基础 :从内存的角度看 char[]和char*相关的知识,希望对你有一定的参考价值。
char*和char[]区别
1:数据在内存中的存储
- 栈:就是在那些由编译器在需要的时候分配,在不需要的时候自动清楚变量的存储区,里面的变量通常是局部变量,函数参数等。
- 堆:就是那些由new或malloc分配的内存,在不使用的时候,要手动用 delete或free来释放内存区域
- 全局/静态存储区:全局变量和静态变量被分配到同一块内存中,他们共同占用同一块内存区域。
- 常量存储区:这是一块特殊存储区,他们里面存放的是常量,不允许修改
2:char*和 char[]分析
#include<iostream>
using namespace std;
int main()
char* a = "abc";
char b[] = 'a','b';
b[0] = 'b';
a[0] = 'b';
cout <<a << " "<< endl;
上述代码至少会有两个问题
问题1 :
char* a = “abc”;

分析:
- 等号右边的"abc"是一个不变常量,在c++中叫做string literal,type是const char *
- a则是一个char指针。如果强行赋值会发生什么呢?没错,就是将右边的常量强制类型转换成一个指针,结果就是我们在修改一个const常量。
- 编译运行的结果会因编译器和操作系统共同决定,有的编译器会通过,有的会抛异常,就算过了也可能因为操作系统的敏感性而被杀掉。
问题2:

因为"abc"在常量存储区中保存有一份,并且任何指向该存储器的任何写操作都是非法的。
💚💚💚
#include<iostream>
using namespace std;
int main()
const char* a = "abc";
char b[] = 'a','b';
b[0] = 'b';
cout <<b[0] << " "<< endl;
但是上述代码是没有什么问题的
可以直接输出 :b
分析
- char b[3] = ‘a’,‘b’的字符a和b是存放在栈区的所以可以进行写操作。
- 字符’a’, ‘b’ 是在 栈中开辟一段内存,内存的大小为3字节(char数组后面自动加一个 ‘\\0’),然后 ‘a’, ‘b’ 被保存在栈中。
3:char* p2 和 char p1[]
从某种意义上来说, char p 和 char p[] 是没有区别 的,比如下面的代码:*
字符数组 char p1[] 编译器会在末尾自动加上’\\0’ p1 = &p1[0] ; cout << p1 ;
直接输出这个字符串,本质就是通过这个地址 char *p 定义一个指针变量p,然后打印出这个变量指向的内存保存的值。
但是 char p1[] 和 char p2 又是有区别的。*
char* p2 是指向的常量区域是不能修改的
char[] p1 由于保存在栈中,是可以修改的,比如将 p1[0] 修改成 b"
#include<iostream>
int main()
char p1[] = "hello java";
const char *p2 = "hello C++";
p1[0] = 'b';
std::cout << p1 << std::endl << p2 << std::endl;
std::cout << *p1 << std::endl <<p2[0] <<std::endl;

3.1 修改指针所指向的地址
修改p2的指,程序运行就会出错,但可以修改p2所指向的地址
#include<iostream>
int main()
char p1[] = "hello java";
const char *p2 = "hello C++";
// 修改指针所指向的地址
p2 = p1;
std::cout << p2 << std::endl;
std::cout << p1 << std::endl;
return 0;

4: string转char*
#include<iostream>
#include<cstring>
int main()
char t[10];
// error: 'string' was not declared in this scope
// 这里需要带上 std命名空间。
// answer :
// 如果不使用using std::string,就在程序中使用string 类型变量,程序不能识别是标准库中的string 变量。
// 因为程序自定义头文件中也可能含有string变量。所以一定要声明using std::string。这样程序里面的string类型变量就都是std标准库中的string变量了。
std::string str = "abc";
strcpy(t,str.c_str());
std::cout<< t << std::endl;
return 0;

5: char * 转string
#include<iostream>
#include<string>
int main()
char t[10] = "abc";
std::string str = t;
std::cout << str;
return 0;

5.1 to_string()用法
1: to_string()是标头的库函数,用于将数值(数字)转换为字符串。
原型
string to_string(numberic_value);
string:是返回类型,即函数返回一个字符串对象,其中包含字符串格式的数字值。
numbric_value:是可以为整数,浮点数,长整数,双精度数的数字。
#include <iostream>
#include <string>
using namespace std;
int main ()
//定义不同类型的数据类型
int intVal =12345;
float floatVal = 123.45f;
long longVal = 123456789;
//将值转换为字符串以打印
cout<<"intVal (string format) : "<<to_string (intVal) <<endl;
cout<<"floatVal (string format) : "<<to_string (floatVal) <<endl;
cout<<"floatVal (string format) : "<<to_string (longVal) <<endl;
return 0;
输出结果
intVal (string format) : 12345
floatVal (string format) : 123.449997
floatVal (string format) : 123456789
C++搞懂char与wchar_t字符串
C++里的字符串类型是比较二的,因为有太多表示方法:char*、string、字符串数组、wchar_t*、wstring,今天就来缕一缕这些玩意。
1. char*
char* 貌似是C++字符串最基础最核心的。
看以下四个字符串声明及输出结果:
先说说核心,C里面的字符串就是一连串内存,以内存为0的字节作为结尾。
来分析一下代码,其中str1、str3、str4是一个东西(str3区别只是内存在堆上),str2是字面值常量,str5是单纯的字符数组。
1.1. 常规字符串
对于str1、str3、str4这种正常的字符串,就可以随意拿字符串函数和下标访问,进行各种操作。
在windows下,char*的字符串编码是多字节,用的本地编码,就是我们的GBK。linux下char*直接就是utf8,所以两个平台char*字符串直接交流是不行的。。。
1.2. 字符数组
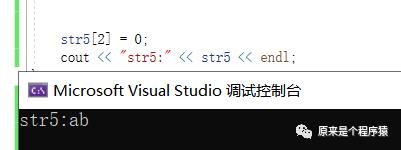
对于str5这种字符数组,因为末尾没有0,所以把他当作字符串直接输出就会有内存里其他数据,就出现了“烫”。。
当我们把字符数组里的某个位置改成0,就可以截断出一个字符串。比如以下代码,把第三个位置设置为0,然后就是字符串“ab”。
1.3. 字面值
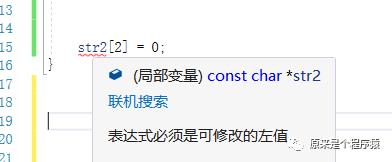
对于str2这种在写代码的时候就是一个常量,当你对这个数据的内存操作的时候就会报错。
比如直接修改str2的元素,ide环境就可以给你报错:
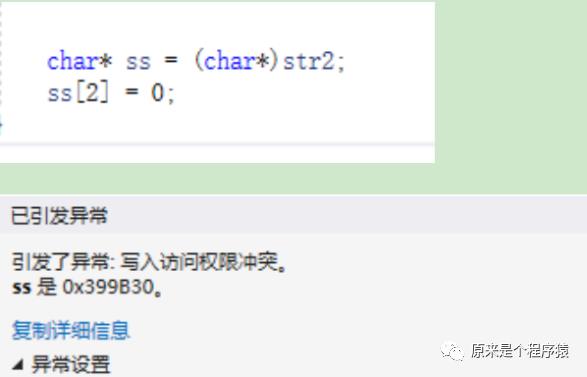
如果我们来硬的,运行的时候就会错误:
2. wchar_t*
首先我们再敲一下重点:C里面的字符串就是一连串内存,以内存为0的字节作为结尾。
记住,这非常重要!!!
wchar_t*与char*字符串主要不同,那就是字符的编码而已。
先看下以下代码和输出:
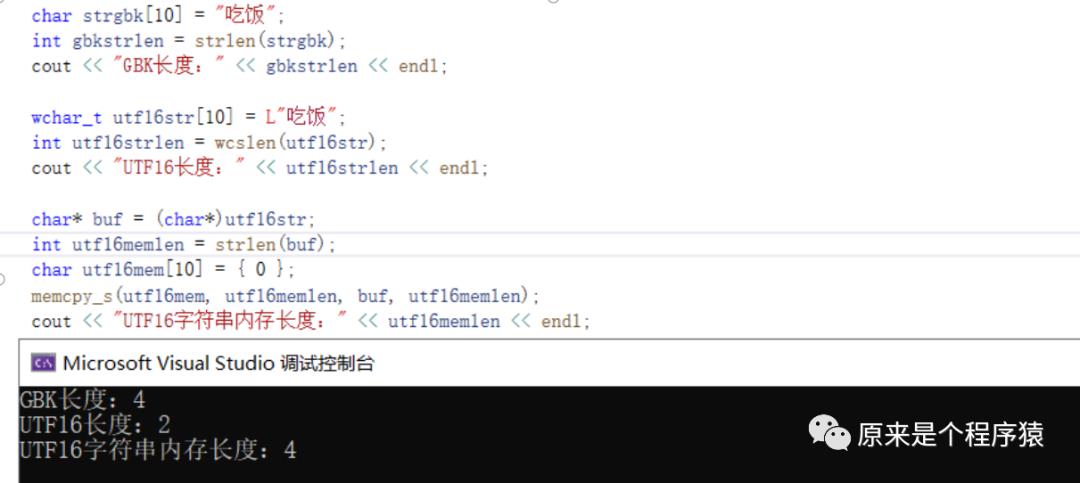
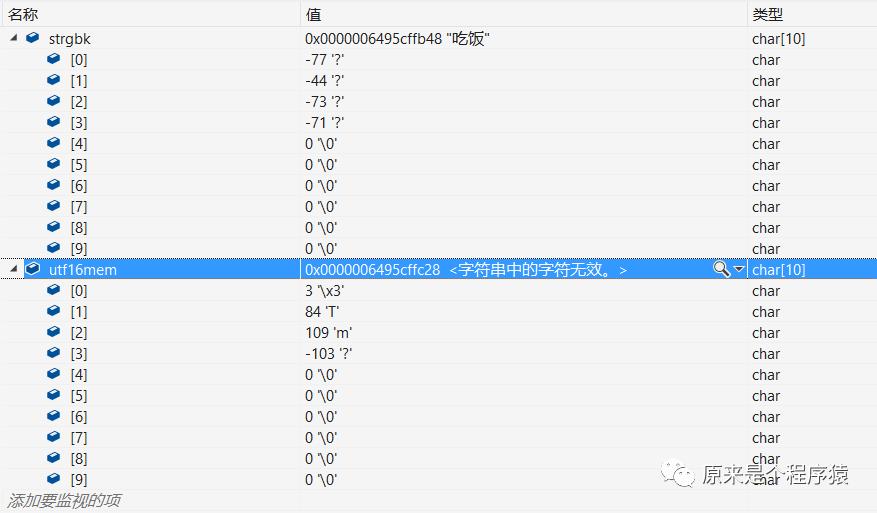
“吃饭”这个字符串,用GBK编码后一共占了5个字节,其中4个字节是用来存放字符串内容的,最后末尾为0。
strlen这个函数,他是一个字节统计一次,出现0就停止,所以gbkstrlen就是4。
对于纯字母来说这没毛病,但对于中文来说,显然“吃饭”这是两个字符。
utf16是用unicode编码(全世界所有字符都有唯一一个数字表示),每个字符都用两个字节来存储unicode编码数字。
C++里utf16字符串需要用L开头,所以得写成 L"吃饭" 这种。
这时,我们用wcslen函数就可以计算出"吃饭"的长度是2。
哎,其实这也真的挺二的。。。因为简单来说utf16一定是每个字符2个字节,所以用strlen计算到末尾长度一定是2的倍数。除以2就肯定是实际长度了。
所以当我们用char* buf = (char*)utf16str;强转成char*然后用strlen计算出的utf16memlen就是4。
看一下内存里的情况,两个字符串都是占用4个字节,但是每个字节里存储的内容是不一样的。
其实C++里的wchar_t*挺鸡肋的感觉,现在utf8比较普遍。因为一刀切地用2个字节表示,对于纯英文字符那直接是浪费一倍的空间。所以utf8这种变长编码就比较合适。
utf8也是Unicode编码数字,就是根据每个字节前面的二进制位决定后面使用几个字节来表示一个unicode编码。
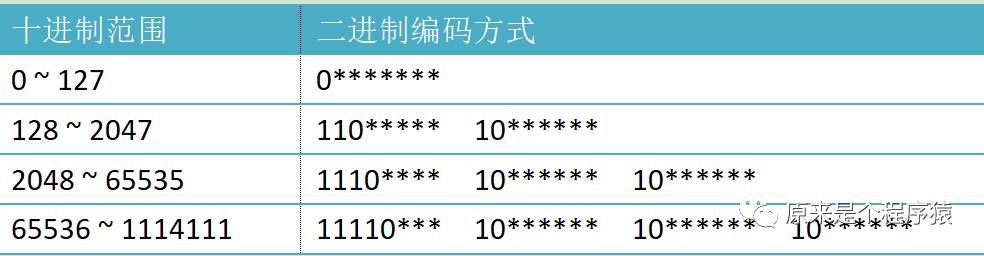
比如对于0到127,因为第一个字节第一个位是0,所以后面不使用任何字节,就一个字节表示Unicode编码。
对于128-2047,因为第一个字节0之前出现2个1,所以后面再使用两个字节(每个字节最前面都是10)。
我们用windowsAPI将wchar_t*字符串转utf8看下:
可以看出来用WideCharToMultiByte得出的内存占用大小和强制按照char*算出的utf8字符串的一样长。
对比看下,内存中和gbk与utf16的都不一样:
可惜的是VC++中没法显示utf8字符串,不过在linux下就用char*就够了,直接utf8。
3. string和wstring
这俩就是char*和wchar_t*的封装,变成了类对象管理字符串。
以上是关于C++ : C++基础 :从内存的角度看 char[]和char*的主要内容,如果未能解决你的问题,请参考以下文章