(个人笔记)Just For Fun!!!
Posted Xurtle
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(个人笔记)Just For Fun!!!相关的知识,希望对你有一定的参考价值。
OS
操作系统中一些容易混淆的概念!
39页20题
ELF 可重定位目标文件的 sections(CSAPP 451 页):
- .rodata: 只读数据
- .data: 已初始化的全局C变量; 局部C变量在运行时保存在栈中,即不在 .data 中,也不在 .bss 中
- .bss: 未初始化的全局C变量
Dynamically allocated space(using malloc, calloc, realloc) 在堆内存中!
Stack Overflow 中给了答案:Where in memory are my variables stored in C
39页27题
https://www.zhihu.com/question/31274481/answer/179151672
DMA方式:在内存和IO设备之间直接进行数据交换,不需要CPU的干预。当需要IO数据传输时,CPU将DMA初始化,之后DMA接管总线的使用权,将所需要的数据全部读入内存后,IO设备的控制器才会发出中断。
通道(Channel I/O):能执行有限通道指令的IO控制器,代替CPU管理控制外设。通道有自己的指令系统,是一个协处理器,一般用在大型计算机系统中(不是大型机)。通道实质是一台能够执行有限的输入输出指令,并能被多台外设共享的小型DMA专用处理机。
通道解决了两个问题:
- 由CPU承担输入输出的工作。虽然DMA无需CPU进行外设与内存的数据交换工作,但是这只是减少了CPU的负担,输入输出的初始化仍然要由CPU来完成。
- 大型计算机系统中高速设备共享DMA接口的问题。大型计算机系统的外设太多以至于不得不共享有限的DMA接口(小型计算机系统比如pc机中每个高速设备分配一个DMA接口)。
通道与DMA相比:
共同点:
都能实现IO设备和内存之间建立数据直传通路;
不同点:
- DMA只能实现固定的数据传送控制,而通道有自己的指令和程序,具有更强的独立处理数据输入和输出的能力。
- DMA只能控制一台或者少数几台同类设备,而一个通道可以控制多台同类或者不同的设备。
40页29题
原语操作系统或计算机网络用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程。primitive or atomic action 是由若干个机器指令构成的完成某种特定功能的一段程序,具有不可分割性·即原语的执行必须是连续的,在执行过程中不允许被中断。
61页9题
Mostly, the scheduler runs when an clock interrupt fires, but it may run at other times, too. Clock interrupts (a.k.a. timer interrupts) occur on the order of every millisecond (typically configurable by the OS).
也就是说,当一个时钟中断发生时,进入中断处理程序,处理程序启动 scheduler,然后它调度一个进程开始运行,如果调度的这个进程并不是时钟中断前的进程,那么就会发生 context switch,开始进程的切换!
下面给出 clock tick (与题目无关)的概念:
Same as a cycle, the smallest unit of time recognized by a device. For personal computers, clock ticks generally refer to the main system clock, which runs at 66 MHz. This means that there are 66 million clock ticks (or cycles) per second. Since modern CPUs run much faster (up to 3 GHz), the CPU can execute several instructions in a single clock tick.
73页 Peterson’s Algorithm
turn 变量的含义代表该轮到哪个线程执行了。访问临界区分为2种情况:
1、只有一个线程想访问临界区
在这种情况下,while 循环中的第一个条件不成立(即另一个线程对进入临界区不感兴趣),因此就不需要测试第2个条件了!当它退出临界区时,调用 unlock 函数,取消自己进入临界区的愿望。
2、两个线程同时想访问临界区
当2个线程同时调用 lock 函数想进入临界区时,while 循环中的第一个条件就可能会成立(当2个线程都执行完第1条语句时),但是谁先完成第2条语句谁就会先获取到锁,从而先执行。如果你仔细考虑每一种情况,这个算法都能做到互斥地访问临界区。
int flag[2];
int turn;
void lock_init()
flag[0] = flag[1] = 0;
turn = 0;
// Executed before entering critical section
void lock(int self)
// Set flag[self] = 1 saying you want to acquire lock
flag[self] = 1;
// But, first give the other thread the chance to
// acquire lock
turn = 1-self;
// Wait until the other thread looses the desire
// to acquire lock or it is your turn to get the lock.
while (flag[1-self]==1 && turn==1-self) ;
// Executed after leaving critical section
void unlock(int self)
// You do not desire to acquire lock in future.
// This will allow the other thread to acquire
// the lock.
flag[self] = 0;
https://www.geeksforgeeks.org/petersons-algorithm-for-mutual-exclusion-set-1/
75页信号量
Mutex(互斥量) 与 Semaphore(信号量)区别
它们都有用来提供 synchronization primitives 的内核资源,但是它们的机制不同。
A mutex is locking mechanism used to synchronize access to a resource. Only one process can acquire the mutex. It means there is ownership associated with mutex, and only the owner can release the lock (mutex). Semaphore is signaling mechanism.
They have different purposes. Mutex is for exclusive access to a resource. A Binary semaphore should be used for Synchronization (i.e. “Hey Someone! This occurred!”). The Binary “giver” simply notifies whoever the “taker” that what they were waiting for happened.
关于更加详细的解释参考:Difference between binary semaphore and mutex
Semaphores in operating system
The two most common kinds of semaphores are counting semaphores and binary semaphores. Counting semaphore can take non-negative integer values and Binary semaphore can take the value 0 & 1. only.
下面2个操作用来改变信号量变量的值:
// P operation is also called wait, sleep or down operation
P(Semaphore s)
s = s - 1;
if (s < 0)
// add process to queue
block();
// V operation is also called signal, wake-up or up operation
V(Semaphore s)
s = s + 1;
if (s <= 0)
// remove process p from queue
wakeup(p);
链接中有一个忙等待的实现,上面的代码是一个修改过后的版本,它允许信号量的值小于0. When a process executes wait(), the semaphore count is automatically decremented. The magnitude of the negative value would determine how many processes were waiting on the semaphore:
上面的 P 与 V 2个操作都是原子的,二元信号量变量 s 的初始化值必须为1. A critical section is surrounded by both operations to implement process synchronization. The code below describes critical section of Process P in between P and V operation.
// Some code
P(s);
// critical section
V(s)
// remainder sectionNow, let us see how it implements mutual exclusion. Let there be two processes P1 and P2 and a semaphore s is initialized as 1. Now if suppose P1 enters in its critical section then the value of semaphore s becomes 0. Now if P2 wants to enter its critical section then it will wait until s > 0, this can only happen when P1 finishes its critical section and calls V operation on semaphore s.
The description above is for binary semaphore which can take only two values 0 and 1. There is one other type of semaphore called counting semaphore which can take values greater than one. For example, suppose there are 4 process P1, P2, P3, P4 and they all call wait operation on S(initialized with 4). If another process P5 wants the resource then it should wait until one of the four process calls signal function and value of semaphore becomes positive.
https://en.wikibooks.org/wiki/Operating_System_Design/Processes/Semaphores
管程(Monitors)
管程是一个包含:共享数据结构,condition variables,和操作共享数据结构的过程(procedure)的集合。比如对于下面的 Producer-Consumer 问题来说,右半部分的代码是一个管程,它包含共享数据结构 buffer,条件变量 full 和 empty,以及操作 buffer 的过程 Enter 和 Remove.

上图中左半部分的代码分别是一个 “生产者” 和 “消费者”,它们不可以直接访问管程内部的数据结构,只能通过管程内部定义的过程。管程也是进程安全的,一次仅允许一个进程执行管程内部的代码。
上面管程中的代码还有2个操作:wait 和 signal. 它们是作用在条件变量上的2个操作。Process performing wait operation on any condition variable are suspended. The suspended processes are placed in block queue of that condition variable. Each condition variable has its unique block queue. When a process performs signal operation on condition variable, one of the blocked processes is given chance.
https://www.cs.princeton.edu/courses/archive/fall09/cos318/lectures/SemaphoresMonitors.pdf
https://www.geeksforgeeks.org/monitors/
234页FAT (File-allocation table)
FAT 是 Linked Allocation 的一个变种,在介绍它之前,我们先谈一谈文件的 Linked Allocation 方式!一图胜千言,先看一下 Linked Allocation 的图示,Directory entry 包含了文件的第一个 block 和最后一个 block 的指针,每个 block 中都有下一个 block 的指针,所以每个 block 都需要4字节来存储指针,相比于 Contiguous Allocation 的方法,这会浪费一定的存储空间。对于一个512字节的block,指针所占的容量为0.78%,为了解决这样的问题,通常把多个 blocks 合并成一个 clusters(簇),比如 the file system may define a cluster as four blocks and operate on the disk only in cluster units. Pointers then use a much smaller percentage of the file’s disk space. 当然了,更大的 cluster 会导致增大 internal fragmentation 问题!
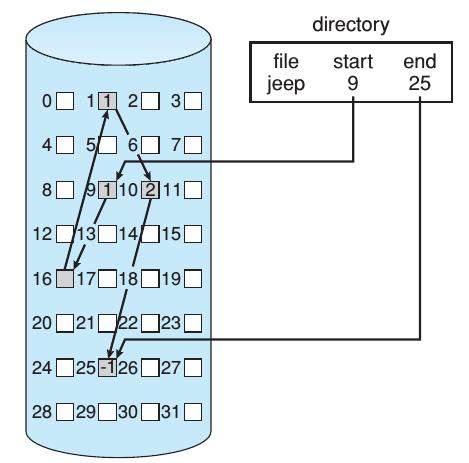
这种分配方式的另一个缺点就是它只能 sequential-access files. To find the ith block of a file, we must start at the beginning of that file and follow the pointers until we get to the ith block. Each access to a pointer requires a disk read, and some require a disk seek. 通过 FAT,我们可以大大减小 random-access time,这是因为对于先前的方法来说,如果你想读一个文件的第10个 block,你需要逐一访问前面的 block,从而你才能得到访问第10个 block 的指针,这会导致大量的「磁盘读」,效率低; 而现在通过下图中的FAT(起初它在每个 volume 的起始位置,然后会被缓存到内存中),你可以得到任何一个 block 的指针,通过读FAT.
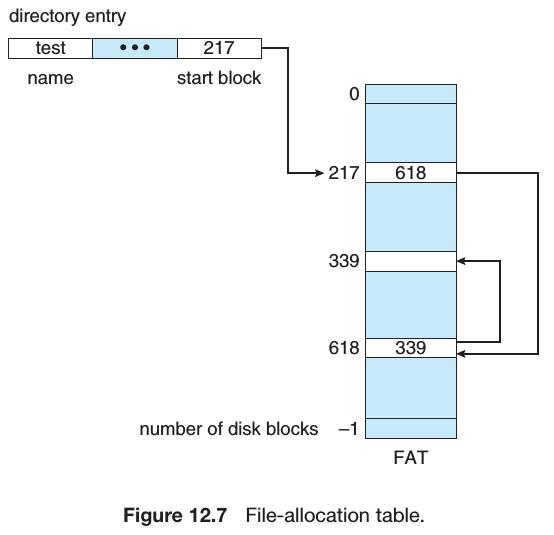
图片来源:牛逼的大学
以上是关于(个人笔记)Just For Fun!!!的主要内容,如果未能解决你的问题,请参考以下文章