angr 文档翻译(3):解析器引擎——符号表达式和约束求解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了angr 文档翻译(3):解析器引擎——符号表达式和约束求解相关的知识,希望对你有一定的参考价值。
参考技术A angr的强大能力不仅因为它是一个模拟器,还因为它能够使用我们称为“符号变量”的东西参与程序的执行。它可以使用一个符号,也就是一个名字,来代替程序执行中的确切数值。然后,在使用符号进行数学运算的过程中,将会产生一棵树(这棵树在编译理论中被称为抽象语法树或AST)。这些AST可以被解释为SMT解析器中的约束条件,就像Z3(另一个python的约束求解库)做的一样。为了回答这样一个问题:“已知经过一系列操作之后得到的输出,输入应该满足怎样的条件?”,在这里,你将会学习如何使用angr来解决这个问题。让我们获取一个Project和state来开始和数字们玩耍吧!
一个位向量就是一个比特序列,可以解释为数学上的有界整数。让我们先生成一些位向量:
正如你看到的,你可以声明许多比特序列并且把他们称为位向量。你还可以对他们进行数学计算:
你不能做诸如 one+weird_nine 这样的操作。对不同长度的位向量做数学运算,将会导致一个类型错误。然而,你可以扩展这个 weird_nine ,让他具有合适的比特长度:
zero_extend 将会用零扩展位向量的高位。为了在扩展时保持二进制补码表示的有符号整数的值,你还可以使用 sign_extend 来带符号扩展一个位向量
现在让我们混入一些符号参与计算:
x 和 y 现在是“符号变量”,这跟咱们小学学的未知数是一个意思。注意,你提供的符号名(第一个参数)的后面被添加了一个递增的计数值。你可以对这些符号变量做数学计算,想做多少就做多少,但是你不会得到一个数值的结果,而是得到一个AST:
从技术概念上说 x 和 y 甚至 one 都是AST——即使只有一层。为了理解这一点,让我们学习如何处理AST。
每一个AST都有 .op 和一个 .args 。“op”是一个定义了要执行的运算的属性,“args”是参与运算的操作数。除非op是字符串"BVV"或"BVS",所有的args都是AST。AST的终结节点是BVV或BVS。
从现在开始,我们将会使用“位向量”这个词来表示一个最上层运算产生一个位向量的AST。通过AST还可以表示其他数据类型,包括浮点数和布尔类型(我们很快会看到)。
将任意两个类型相似的AST进行比较操作将会产生一个新的AST——不是一个位向量,而是一个符号化的布尔类型:
从上述例子中你可以看出AST间的比较默认是无符号的。例子中的-5将会被包装为 <BV64 0xfffffffffffffffb> ,这个数被解释为无符号数之后,显然大于100 。如果你想让比较是带符号的,你可以使用 one_hundred.SGT(-5) (SGT意思是“signed greater-than”)。在本章的最后可以找到完整的AST操作列表。
上面的例子还阐述了一个使用angr的要点——你不应该直接在一个if或while语句中使用两个变量的比较结果作为判断标准,因为这个比较结果可能不是一个确定的真值。即使比较的结果为真, if one > one_hundred 将会产生异常。你应该使用 solver.is_true 和 solver.is_false ,它们将会测试出一个具体的真假值,而不执行约束求解。
你可以用加入一个约束条件到一个state中的方法( state.solver.add ),将每一个符号化的布尔值作为一个关于符号变量合法性的断言。之后可以通过使用 state.solver.eval(symbol) 对各个断言进行评测来求出一个合法的符号值(若有多个合法值,返回其中的一个)。
一个例子可能会比文字更清楚:
通过添加这些约束到一个state中,我们已经迫使约束求解器考虑我们添加的断言,求解器返回的值必须满足这些断言。如果你运行上面的例子,你可能会得到x的不同值,但是这个值将必然大于3(因为y > 2且x >= y 且 x <= 10)。此外,如果你接着用 state.solver.eval(y) 求解y,你将会得到一个被之前求解出的x的值限制的y值。
如果在两次求解之间你没有添加任何其他的约束条件,那么两次求解的结果将会是一致的。
从现在开始,我们就明白了该如何解决本章开头提出的问题——找到一个产生指定输出的输入:
再次提醒,这样的求解方式只适用于位向量的语义下(也就是之前提到的AST)。如果我们在整数域上做上面的操作,将会是无解的。
如果我们将两个互相矛盾或相反的约束加入一个state.solver中,比如没有一个值能够满足所有约束,那么这个state就变成了 unsatisfiable ,或者unsat,并且对这样的state求解会导致异常。你可以用 state.satisfiable() 检查一个state是否可解,接着上面的例子:
你还可以加入更复杂的表达式,而不仅是包含一个符号变量的表达式:
这里我们可以看到, eval 是一个通用的方法,它在考虑整个state(的约束)的情况下,将任意位向量转换为python基本类型。这也是为什么我们使用 eval 来将具体的位向量转换为python的int类型的原因。
还需要注意的是符号变量x和y可以在新的state中被使用,尽管它在旧的state中被创建。符号变量不和state绑定,它们是自由存在的。
z3(一个约束求解的python库)已经提供了对IEEE754浮点数标准的支持,并且因此angr也能够使用它们(因为angr集成了z3)。创建浮点数向量和创建一个向量主要的不同在于,浮点数向量的第二个参数不是位向量宽度,而是一个 sort 。你可以使用 FPV 和 FPS 来创建一个浮点值和符号。
有许多需要解释的东西——首先对于浮点数向量的显示并不是很好,但是抛开这个不谈,大多数的浮点数操作实际上都有第三个参数,它在你使用二进制运算符时被隐式地添加——这个参数是舍入模式。IEEE754定义了多个舍入模式(向最近的数舍入,向0舍入,舍入到正数等等),所以z3必须支持它们。如果你想要对某个操作(比如 solver.fpAdd )指定舍入模式,你就得在使用该操作时显示声明一个舍入模式( solver.fp.RM_* 中的一个)作为参数。
浮点数符号的约束和求解工作按照和整型符号相同的方式工作,但是使用 eval 将会返回一个浮点值:
这很好,但是有时候我们需要能够直接和浮点数的位向量形式直接交互。你可以使用 raw_to_bv 和 raw_to_fp 将位向量解析为浮点数,反之亦可:
这些转换保留了位模式,就像把一个int指针转为浮点指针(或相反)一样。然而,如果你想尽量不丢失精度,当你想将一个浮点数转为int(或反过来)你可以使用另一组方法: val_to_fp 和 val_to_bv 。由于浮点数的浮点特性,这些方法必须将目标值的位宽或种类作为参数:
这些方法还可以加一个 signed 参数,指定源或目的位向量是否是有符号的。
eval 将会给出一个符合约束条件的可行解,但是如果你想要多个可行解时怎么办呢?你如何确定这个解是不是唯一的?解析器为你提供了一些通用的解决方案:
另外,上述这些方法都可以接收如下关键字参数:
内容真多!读完本章之后,你应该能够创建和操作位向量、布尔值和浮点数来形成操作树,之后用附加在state上的约束求解器,根据约束条件集,求得一个(或多个)可行解。希望你读完本章能够体会到用AST来表示运算以及约束求解器的强大。
在 附录 中,你能够找到可以对AST进行的所有操作。
sharding jdbc之解析引擎
1. 解析引擎
解析过程分为词法解析和语法解析。 解析引擎在 parsing 包下,包含两大组件:
- Lexer:词法解析器。
- Parser:SQL解析器。
词法解析器用于将SQL拆解为不可再分的原子符号,称为Token。并根据不同数据库方言所提供的字典,将其归类为关键字,表达式,字面量和操作符。 再使用语法解析器将SQL转换为抽象语法树。例如:
SELECT id, name FROM t_user WHERE status = \'ACTIVE\' AND age > 18
解析成的抽象语法树如:
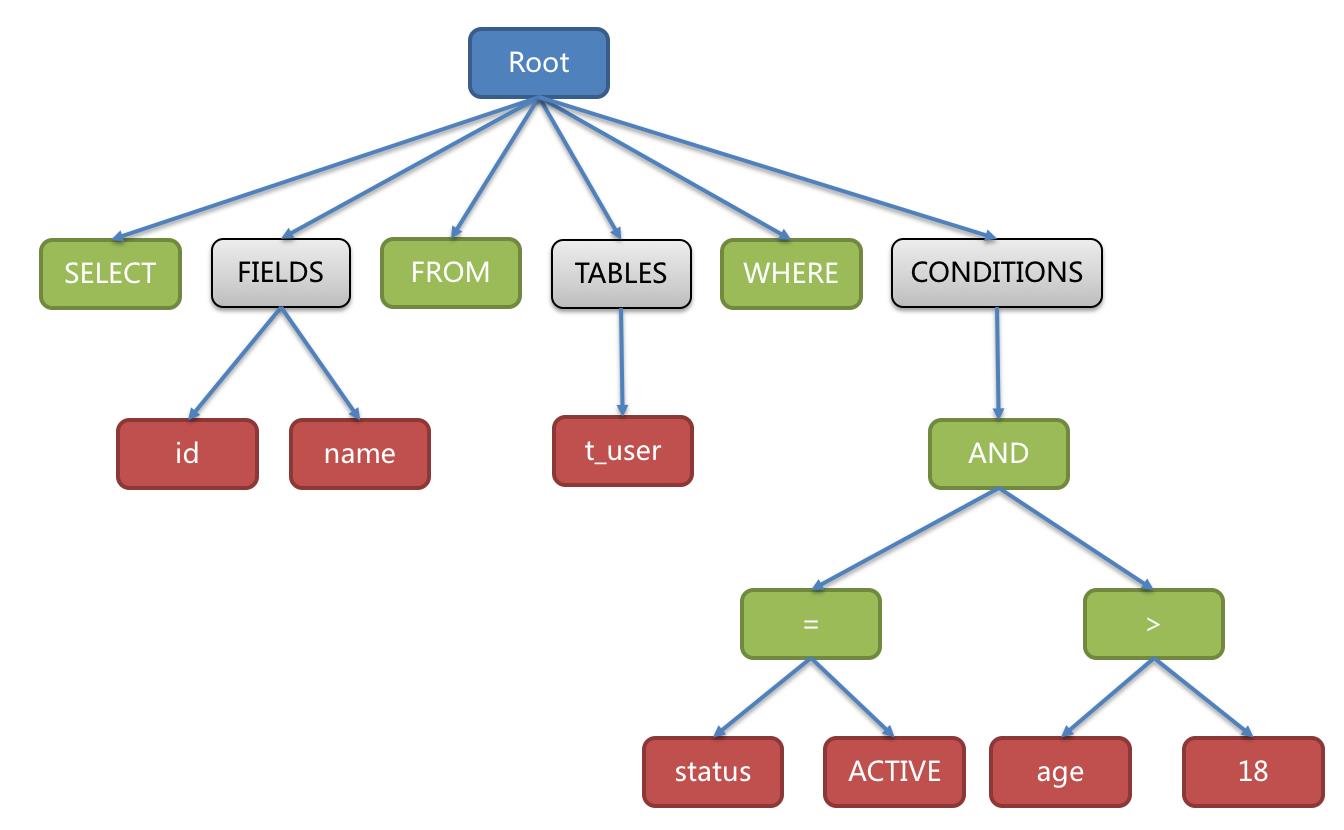
两者都是解析器,区别在于 Lexer 只做词法的解析,不关注上下文,将字符串拆解成 N 个分词。而 Parser 在 Lexer 的基础上,进一步理解 SQL表示的行为 。
1.1 Lexer 词法解析器
作用:顺序解析 SQL,将sql字符串分解成 N 个分词(token)。那么每个分词该如何表示呢?
1.1.1 token 和 tokenType
token用于描述当前分解出的词法,包含3个属性:
- TokenType type :词法标记类型
- String literals :当前词法字面量
- int endPosition :literals 在 SQL 字符串中的位置
TokenType 用于描述当前token的类型,分成 4 大类:
- DefaultKeyword :词法关键词
- Literals :词法字面量标记
- Symbol :词法符号标记
- Assist :词法辅助标记
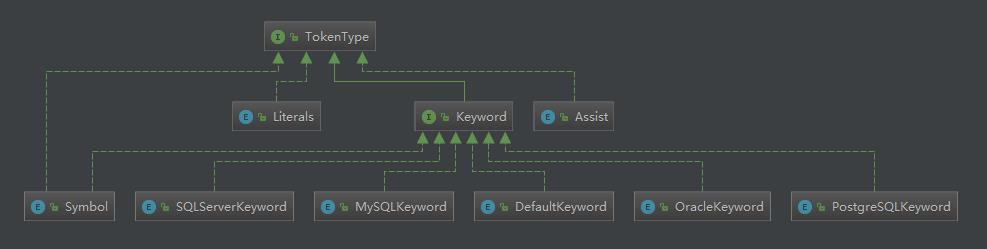
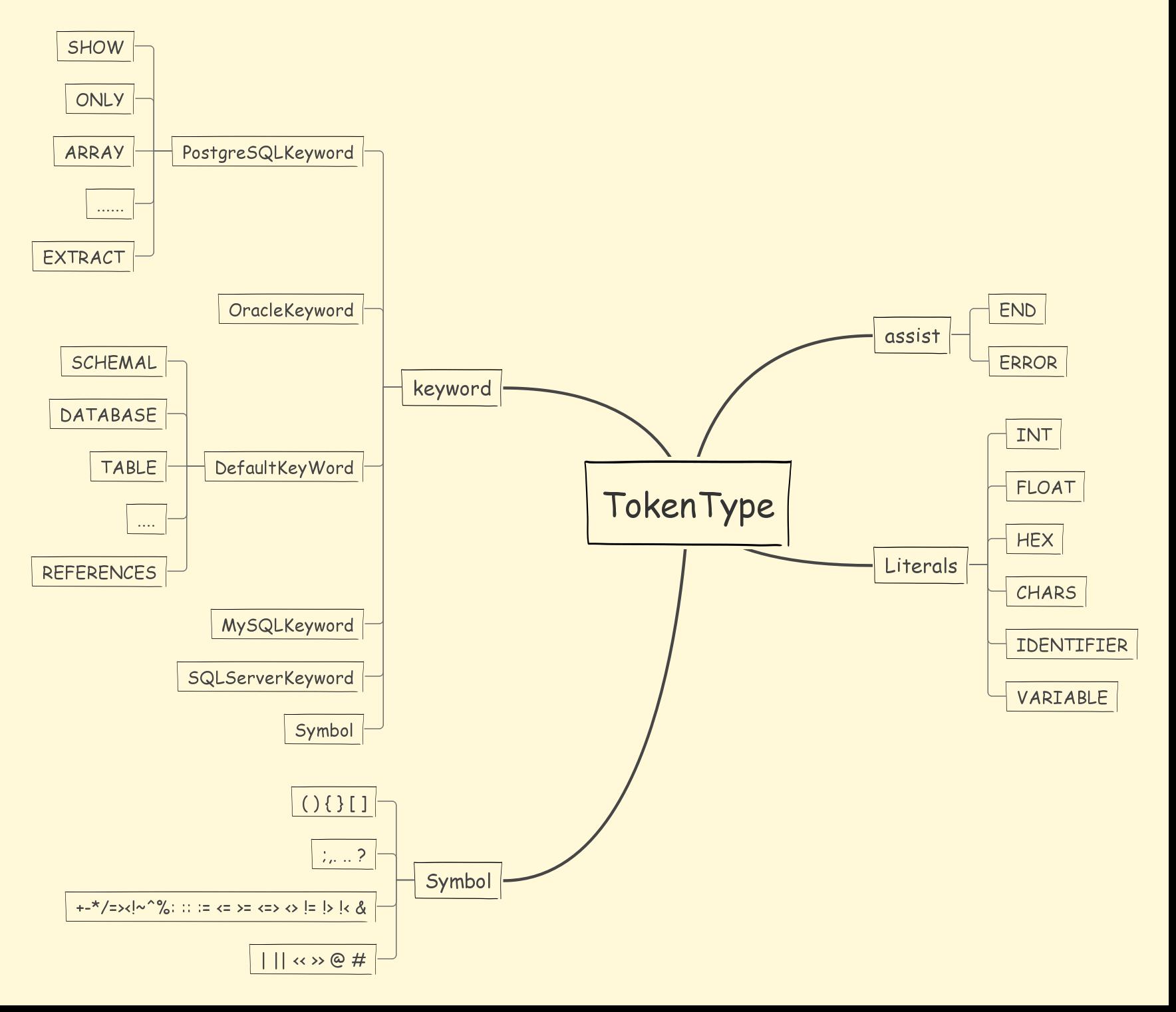
1.1.2 词法解析器
由于不同数据库遵守的 SQL 规范有所不同,所以不同的数据库对应存在不同的 Lexer,维护了对应的dictionary。Lexer内部根据相应数据库的dictionary与sql语句生成一个Tokenizer分词器进行分词。
public final class Tokenizer { //输入 private final String input; //字典 private final Dictionary dictionary; //偏移量 private final int offset; }
分词器具体的api如下:
| 方法名 | 说明 |
|---|---|
| int skipWhitespace() | 跳过所有的空格 返回最后的偏移量 |
| int skipComment() | 跳过注释,并返回最终的偏移量 |
| Token scanVariable() | 获取变量,返回分词Token |
| Token scanIdentifier() | 返回关键词分词 |
| Token scanHexDecimal() | 扫描16进制返回分词 |
| Token scanNumber() | 返回数字分词 |
| Token scanChars() | 返回字符串分词 |
| Token scanSymbol() | 返回词法符号标记分词 |
核心代码如下:
// Lexer.java public final void nextToken() { skipIgnoredToken(); if (isVariableBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanVariable(); } else if (isNCharBegin()) { currentToken = new Tokenizer(input, dictionary, ++offset).scanChars(); } else if (isIdentifierBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanIdentifier(); } else if (isHexDecimalBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanHexDecimal(); } else if (isNumberBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanNumber(); } else if (isSymbolBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanSymbol(); } else if (isCharsBegin()) { currentToken = new Tokenizer(input, dictionary, offset).scanChars(); } else if (isEnd()) { currentToken = new Token(Assist.END, "", offset); } else { throw new SQLParsingException(this, Assist.ERROR); } offset = currentToken.getEndPosition(); System.out.println(currentToken.getLiterals() + " | " + currentToken.getType() + " | " + currentToken.getEndPosition() + " |"); }
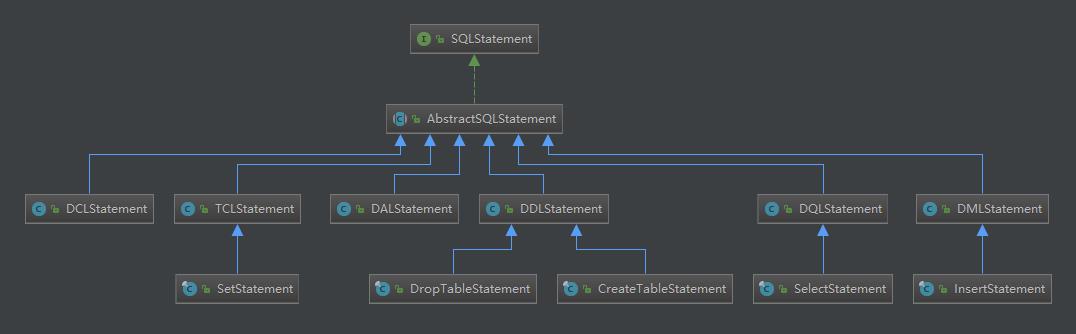
类继承图:

总结:Lexer通过 nextToken() 方法,不断解析出当前 Token。Lexer的nextToken()方法里,使用 skipIgnoredToken() 方法跳过忽略的 Token,通过 isXxx() 方法判断好下一个 Token 的类型后,交给 Tokenizer 进行分词并返回 Token。
1.2 SQLParser 语法解析器
语法解析器的作用是根据不同类型的sql语句在词法解析器的基础上,由不同类型的语法解析器解析成SQLStatement,具体语法解析类结构如图:
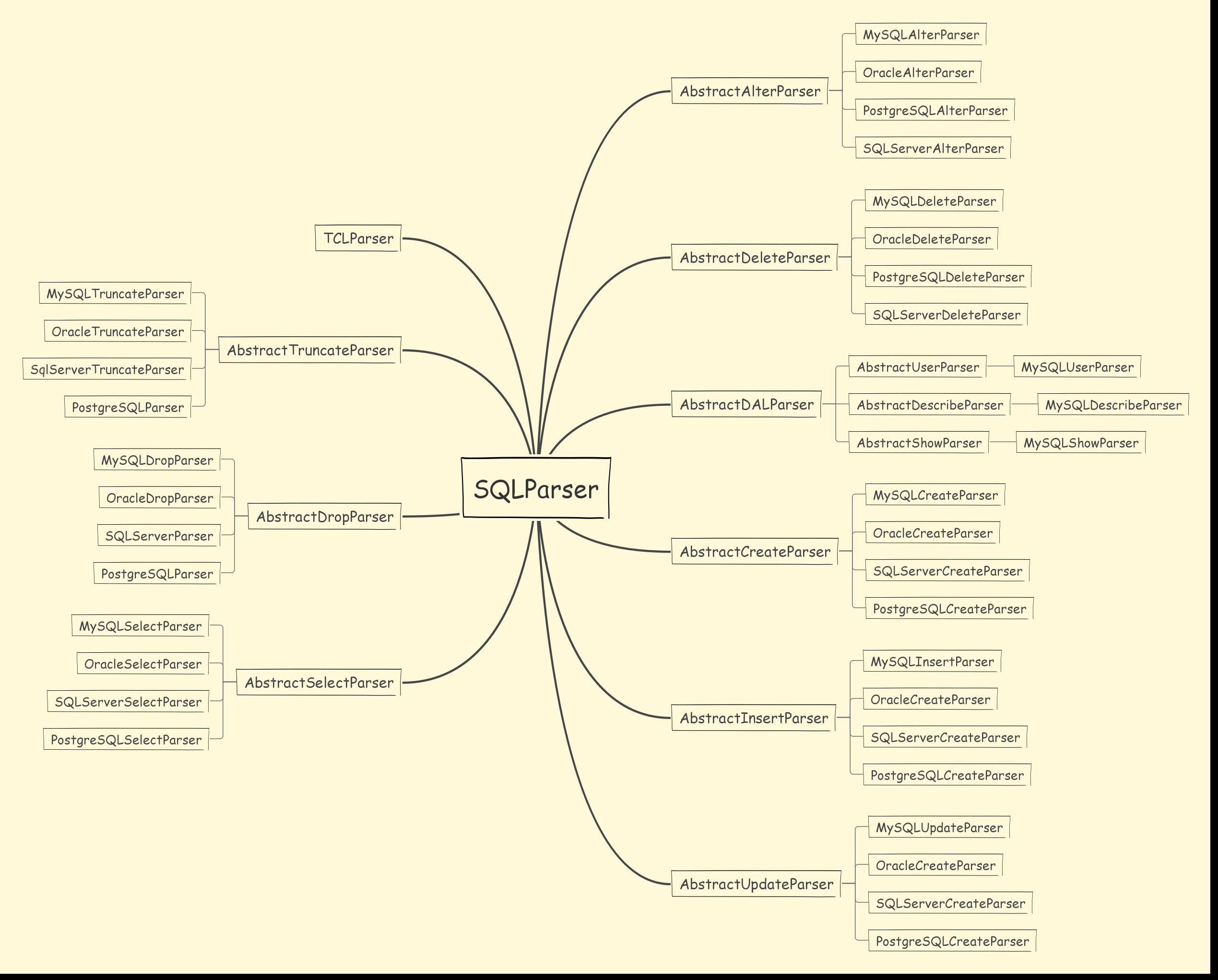
可以看到,不同类型的sql,不同厂商的数据库,存在不同的处理解析器去解析,解析完成之后,会将SQL解析成SQLStatement。
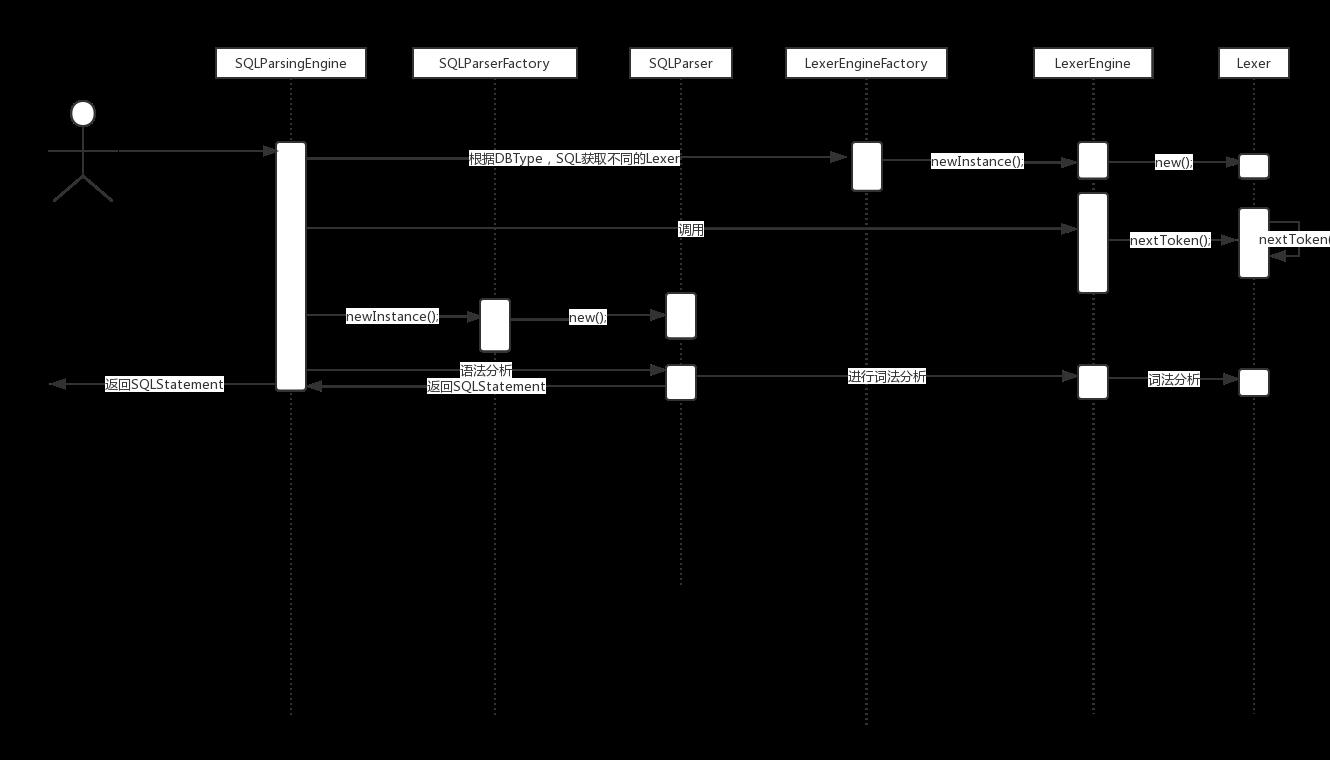
SQLParsingEngine,SQL 解析引擎。其 parse() 方法作为 SQL 解析入口,本身不带复杂逻辑,通过调用对应的 SQLParser 进行 SQL 解析,返回SQLStatement。
@RequiredArgsConstructor public final class SQLParsingEngine { private final DatabaseType dbType; private final String sql; private final ShardingRule shardingRule; private final ShardingTableMetaData shardingTableMetaData; /** * Parse SQL. * * @param useCache use cache or not * @return parsed SQL statement */ public SQLStatement parse(final boolean useCache) { Optional<SQLStatement> cachedSQLStatement = getSQLStatementFromCache(useCache); if (cachedSQLStatement.isPresent()) { return cachedSQLStatement.get(); } LexerEngine lexerEngine = LexerEngineFactory.newInstance(dbType, sql); lexerEngine.nextToken(); SQLStatement result = SQLParserFactory.newInstance(dbType, lexerEngine.getCurrentToken().getType(), shardingRule, lexerEngine, shardingTableMetaData).parse(); if (useCache) { ParsingResultCache.getInstance().put(sql, result); } return result; } }
SQLStatement对象是个超类,具体实现类有很多。按照不同的语句,解析成不同的SQLStatement。
sql语句解析的过程如下图:
参考:
http://www.iocoder.cn/categories/Sharding-JDBC/
https://www.jianshu.com/u/c6408f5e4b0e
以上是关于angr 文档翻译(3):解析器引擎——符号表达式和约束求解的主要内容,如果未能解决你的问题,请参考以下文章