谷粒学苑笔记day4-乐观锁
Posted 一只耗子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谷粒学苑笔记day4-乐观锁相关的知识,希望对你有一定的参考价值。
MP实现乐观锁
乐观锁:默认在任何操作影响下,都不会影响该操作
乐观锁主要解决丢失更新问题
面试题:
什么是并发?
至少两人以上同时对这个事务操作
不考虑事务隔离性,会产生哪些读的问题?
脏读、幻读、不可重复读
不考虑事务隔离性,会产生哪些写的问题?
丢失更新
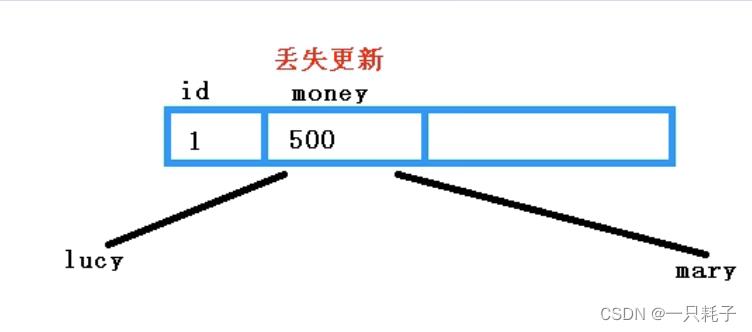
图片上是工资条,假如Lucy和Mary都想对工资条进行操作,lucy想改工资,Mary也想改,不可能两人同时提交,lucy先提交事务,Mary后提交事务,那么lucy会丢失更新,结果为Mary的修改值。这就是丢失更新
解决方式:悲观锁 乐观锁
悲观锁:只能一个人操作,别人只能看着。串行操作,单线程。
乐观锁:给定一个版本号,用户操作时比较当前版本和数据库版本是否一致,更新数据时要连着版本号一起更新。
(另外,在redis解决高并发也有redis分布锁,使用synchronized,为什么要使用synchronized?
在并发编程中存在线程安全问题,主要原因有:1.存在共享数据 2.多线程共同操作共享数据。
关键字synchronized可以保证在同一时刻,只有一个线程可以执行某个方法或某个代码块,使用redis的setnx命令,可以简单的解决集群下的分布式锁问题)
在MP中实现乐观锁
1.在数据库创建一个version字段,
2.在User类里面加一个version属性,属性上加一个@Version注解,
3.配置乐观锁插件
在MP中,使用@Configuration注解配置类,将所有配置类写到一起
创建一个config类,将启动类中的@MapperScan 移动到config里。
/**
* 乐观锁插件
*/
@Bean
public OptimisticLockerInterceptor optimisticLockerInterceptor()
return new OptimisticLockerInterceptor();
然后在test里,新建一个用户,再新建test测试乐观锁,先使用
User user =userMapper.selectById(1558704593221742594L) ;查找到对应的用户,再setAge改变年龄,最后userMapper.UpdateById(user)。结果是版本号更新了
MP简单查询
1.根据id查询
SelectById()
2.多个id批量查询
List<Users> users =UserMapper.SelectBatchIds(Arrays.asList(1L,2L,3L)
3.简单条件查询
SelectByMap
4.分页查询
(1)配置分页插件,也放到之前的config类里面
/**
分页插件
*/
@Bean
public PaginationInterceptor paginationInterceptor()
return new PaginationInterceptor();
(2)编写分页代码,传入两个参数,当前页和记录数
Page<User>page=new Page<>(1,3)
UserMapper.SelectPage(page,null)
(3)通过page获取分页数据
Day412.分布式锁redisson与缓存 -谷粒商城
分布式锁redisson与缓存
- 读模式缓存使用流程

- 缓存
本地缓存:和微服务同一个进程。缺点:分布式时本都缓存不能共享
分布式缓存:缓存中间件
一、本地缓存
category、brand、product
- 安装docker-redis
https://blog.csdn.net/qq_43284469/article/details/120397138
- product导入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- 配置redis主机地址
spring:
redis:
host: 192.168.109.101
port: 6379
-
自动注入了RedisTemplate
-
优化菜单获取业务getCatalogJson
@Override
public Map<Long, List<Catelog2Vo>> getCatelogJson() {
String catelogJson = redisTemplate.opsForValue().get("catelogJson");
if (StringUtils.isEmpty(catelogJson)){
//缓存中没有
Map<Long, List<Catelog2Vo>> catelogJsonFromDB = getCatelogJsonFromDB();
redisTemplate.opsForValue().set("catelogJson",JSON.toJSONString(catelogJsonFromDB));
return catelogJsonFromDB;
}
//因为转化的对象是复杂对象,所以通过TypeReference
Map<Long, List<Catelog2Vo>> catelogJsonFromDB = JSON.parseObject(catelogJson,new TypeReference<Map<Long, List<Catelog2Vo>>>(){});
return catelogJsonFromDB;
}
//从数据库查询数据
public Map<Long, List<Catelog2Vo>> getCatelogJsonFromDB() {
//将数据库的多次交互,转为一次,一次性查询所有数据
List<CategoryEntity> allList = baseMapper.selectList(null);
//查出所有分类
List<CategoryEntity> level1Categorys = getParent_cid(allList,0L);
//分装数据
Map<Long, List<Catelog2Vo>> resultMap = level1Categorys.stream().collect(Collectors.toMap(CategoryEntity::getCatId, v -> {
//每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> list = getParent_cid(allList,v.getCatId());
List<Catelog2Vo> catelog2VoList = null;
if (!StringUtils.isEmpty(list)) {
catelog2VoList = list.stream().map(item -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, item.getCatId().toString(), item.getName());
//封装二级分类的三级分类
List<CategoryEntity> entityList = getParent_cid(allList,item.getCatId());
if (!StringUtils.isEmpty(entityList)){
List<Catelog2Vo.Catelog3Vo> catelog3Vos = entityList.stream().map(m -> {
Catelog2Vo.Catelog3Vo catelog3Vo = new Catelog2Vo.Catelog3Vo(item.getCatId().toString(),m.getCatId().toString(),m.getName());
return catelog3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(catelog3Vos);
}
return catelog2Vo;
}).collect(Collectors.toList());
return catelog2VoList;
}
return catelog2VoList;
}));
return resultMap;
}
private List<CategoryEntity> getParent_cid(List<CategoryEntity> allList,Long parent_cid) {
List<CategoryEntity> collect = allList.stream().filter(item -> {
return item.getParentCid().equals(parent_cid);
}).collect(Collectors.toList());
return collect;
// return baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", v.getCatId()));
}
-
lettuce堆外内存溢出bug
当进行压力测试时后期后出现堆外内存溢出OutOfDirectMemoryError
-
产生原因:
- 1)、springboot2.0以后默认使用lettuce作为操作redis的客户端,它使用netty进行
网络通信 - 2)、lettuce的bug导致netty堆外内存溢出。netty如果没有指定堆外内存,默认使
用Xms的值,可以使用-Dio.netty.maxDirectMemory进行设置
- 1)、springboot2.0以后默认使用lettuce作为操作redis的客户端,它使用netty进行
-
解决方案
由于是lettuce的bug造成,不要直接使用
-Dio.netty.maxDirectMemory去调大虚拟机堆外内存,治标不治本。- 1)、升级lettuce客户端。但是没有解决的
- 2)、切换使用jedis
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <exclusions> <exclusion> <groupId>io.lettuce</groupId> <artifactId>lettuce-core</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> </dependency>lettuce和jedis是操作redis的底层客户端,RedisTemplate是再次封装
-
-
缓存失效
-
缓存穿透【不存在的数据】
-
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id 为“-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导 致数据库压力过大。
-
解决:
- 缓存空对象、布隆过滤器、mvc拦截器
-
-
缓存雪崩【缓存在某一时刻 同时失效】
-
缓存雪崩是指在我们设置缓存时key采用了相同的过期时间,导致缓存在某一时刻 同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
-
解决方案
- 规避雪崩:缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
如果缓存数据库是分布式部署,将热点数据均匀分布在不同缓存数据库中。
设置热点数据永远不过期。
出现雪崩:降级 熔断
事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
事后:利用 redis 持久化机制保存的数据尽快恢复缓存
- 规避雪崩:缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
-
-
缓存击穿【并发查同一条数据】
-
缓存击穿 指 并发查同一条数据。缓存击穿是指缓存中没有但数据库中有的数据 (一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据, 又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力 缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
-
解决方案:
- 设置热点数据永远不过期。
加互斥锁:业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效
的时候(判断拿出来的值为空),不是立即去load db去数据库加载,而是先使用
缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache
的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设
缓存;否则,就重试整个get缓存的方法。
- 设置热点数据永远不过期。
-
-
-
缓存击穿:加锁
-
不好的方法是synchronized(this),肯定不能这么写 ,不具体写了 锁时序问题:之前的逻辑是查缓存没有,然后取竞争锁查s数据库,这样就造成多 次查数据库。
-
解决方法:
- 竞争到锁后,再次确认缓存中没有,再去查数据库。
@Override public Map<Long, List<Catelog2Vo>> getCatelogJson() { String catelogJson = redisTemplate.opsForValue().get("catelogJson"); //缓存中没有 if (StringUtils.isEmpty(catelogJson)) { //获取数据返回 Map<Long, List<Catelog2Vo>> catelogJsonFromDB = getCatelogJsonFromDB(); return catelogJsonFromDB; } //因为转化的对象是复杂对象,所以通过TypeReference Map<Long, List<Catelog2Vo>> catelogJsonFromDB = JSON.parseObject(catelogJson, new TypeReference<Map<Long, List<Catelog2Vo>>>() { }); return catelogJsonFromDB; } //从数据库查询数据 public Map<Long, List<Catelog2Vo>> getCatelogJsonFromDB() { synchronized (this) { //判断缓存是否已经有数据,防止之前的线程已经放好数据 String catelogJson = redisTemplate.opsForValue().get("catelogJsonFromDB"); if (!StringUtils.isEmpty(catelogJson)) { //因为转化的对象是复杂对象,所以通过TypeReference Map<Long, List<Catelog2Vo>> resultMap = JSON.parseObject(catelogJson, new TypeReference<Map<Long, List<Catelog2Vo>>>() { }); return resultMap; } //将数据库的多次交互,转为一次,一次性查询所有数据 List<CategoryEntity> allList = baseMapper.selectList(null); //查出所有分类 List<CategoryEntity> level1Categorys = getParent_cid(allList, 0L); //分装数据 Map<Long, List<Catelog2Vo>> resultMap = level1Categorys.stream().collect(Collectors.toMap(CategoryEntity::getCatId, v -> { //每一个的一级分类,查到这个一级分类的二级分类 List<CategoryEntity> list = getParent_cid(allList, v.getCatId()); List<Catelog2Vo> catelog2VoList = null; if (!StringUtils.isEmpty(list)) { catelog2VoList = list.stream().map(item -> { Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, item.getCatId().toString(), item.getName()); //封装二级分类的三级分类 List<CategoryEntity> entityList = getParent_cid(allList, item.getCatId()); if (!StringUtils.isEmpty(entityList)) { List<Catelog2Vo.Catelog3Vo> catelog3Vos = entityList.stream().map(m -> { Catelog2Vo.Catelog3Vo catelog3Vo = new Catelog2Vo.Catelog3Vo(item.getCatId().toString(), m.getCatId().toString(), m.getName()); return catelog3Vo; }).collect(Collectors.toList()); catelog2Vo.setCatalog3List(catelog3Vos); } return catelog2Vo; }).collect(Collectors.toList()); return catelog2VoList; } return catelog2VoList; })); //放入缓存 redisTemplate.opsForValue().set("catelogJson", JSON.toJSONString(resultMap),1L, TimeUnit.DAYS); return resultMap; } } private List<CategoryEntity> getParent_cid(List<CategoryEntity> allList, Long parent_cid) { List<CategoryEntity> collect = allList.stream().filter(item -> { return item.getParentCid().equals(parent_cid); }).collect(Collectors.toList()); return collect; // return baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", v.getCatId())); }
-
加锁时序图
保证【确认缓存】、【查数据结果】、【放入缓存】是一个原子操作

上面的本地锁只能锁住当前进程,在分布式的情况下无法保证锁住整个集群服务
二、分布式缓存
- 本地缓存问题
每个微服务都要有缓存服务、数据更新时只更新自己的缓存,造 成缓存数据不一致
- 解决方案
分布式缓存,微服务共用 缓存中间件
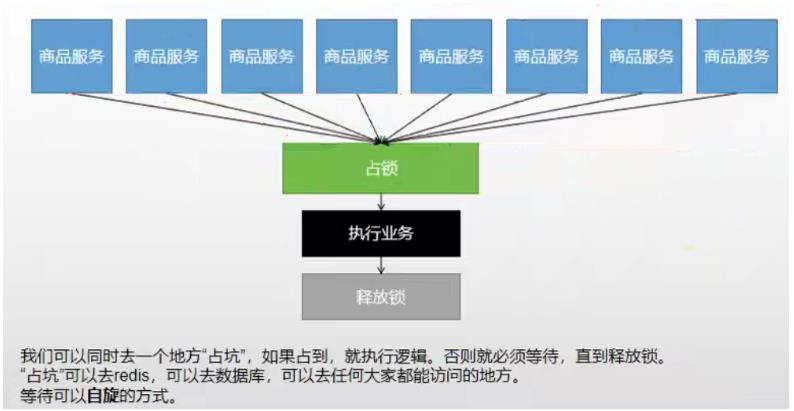
- 分布式锁
分布式项目时,但本地锁只能锁住当前服务,需要分布式锁
- redis分布式锁的原理
setnx,同一时刻只能设置成功一个 前提,锁的key是一定的,value可以变,
没获取到锁阻塞或者sleep一会
设置好了锁,万一服务出现宕机,没有执行删除锁逻辑,这就造成了死锁
-
解决
- 设置过期时间
- 业务还没执行完锁就过期了,别人拿到锁,自己执行完去删了别人的锁
- 锁续期(redisson有看门狗)
- 删锁的时候明确是自己的锁。如uuid 判断uuid对了,但是将要删除的时候锁过期了,别人设置了新值,那删除了别人 的锁
- 删除锁必须保证原子性(保证判断和删锁是原子的)
- 使用redis+Lua脚本 完成,脚本是原子的
- 设置过期时间
-
最终版代码—redis分布式锁
//从数据库查询数据【Redis分布式锁】
public Map<Long, List<Catelog2Vo>> getCatelogJsonFromDBWithRedisLock() {
String uuid = UUID.randomUUID().toString();
//设置redis分布式锁,30s自动删除锁
Boolean isLock = redisTemplate.opsForValue().setIfAbsent("lock", uuid,300L,TimeUnit.SECONDS);
if (isLock){
//抢锁成功。。。执行业务
Map<Long, List<Catelog2Vo>> resultMap = null;
try {
resultMap = getLongListMap();
}finally {
//lua脚本解锁:让获取数据+对比数据成为原子操作
String script = "if redis.call(\\"get\\",KEYS[1]) == ARGV[1] then\\n" +
" return redis.call(\\"del\\",KEYS[1])\\n" +
"else\\n" +
" return 0\\n" +
"end";
Long lock = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class),Arrays.asList("lock"),uuid);
}
return resultMap;
}else {
//抢锁失败。。。重试
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 睡眠0.2s后,重新调用 //自旋
return getCatelogJsonFromDBWithRedisLock();
}
}
- 上面的lua脚本写法每次用分布式锁时比较麻烦,我们可以采用
redisson现有框架
三、Redisson
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。其中包括(BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter, Remote service, Spring cache, Executor service, Live Object service, Scheduler service) Redisson提供了使用Redis的最简单和最便捷的方法。Redisson的宗旨是促进使用者对Redis的关注分离(Separation of Concern),从而让使用者能够将精力更集中地放在处理业务逻辑上。
https://redis.io/topics/distlock
- Redisson
https://github.com/redisson/redisson
1、环境搭建
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.4以上是关于谷粒学苑笔记day4-乐观锁的主要内容,如果未能解决你的问题,请参考以下文章
含泪经验分享!25 个月 79 场 Java 岗面试,程序员的入职门槛到底是什么?