去重是distinct还是group by
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了去重是distinct还是group by相关的知识,希望对你有一定的参考价值。
参考技术A 他们的功能基本上是不一样的。distinct消除重复行。groupby是分组语句。举例来说可能方便一点。A表idnuma1b2c3a4c7d3e5如果只选出id列,用distinct和groupby一样的。selectdistinct(id)fromA;idabcde;selectidfromAgroupbyi本回答被提问者采纳Oracle 用group by 去重计数还是用distinct 计数
Oracle 用group by 去重计数还是用distinct 计数
Oracle 对去重计数的性能比较
--Oracle 聚合优化
--新建测试表 带索引
drop table student;
CREATE TABLE student
(
t_id number,
t_name VARCHAR2(32),
t_class VARCHAR2(32),
t_num number,
CONSTRAINT PK_student PRIMARY KEY (t_id) ENABLE
);
--创建索引
create index t_student_name on student(t_name);
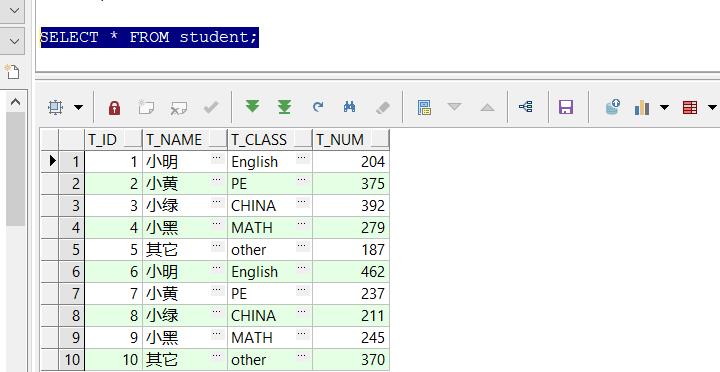
初始化表结构后,插入测试数据(内容不重要)
--插入测试数据
INSERT INTO student(T_ID,t_Name,T_CLASS,T_NUM)
SELECT ROWNUM,
decode(mod(ROWNUM,5),1,'小明',2,'小黄',3,'小绿',4,'小黑','其它') as t_Name,
decode(mod(ROWNUM,5),1,'English',2,'PE',3,'CHINA',4,'MATH','other') as T_CLASS,
rannum2 as T_NUM
FROM (
SELECT rownum ,round(dbms_random.value(1,5)) as rannum1,
round(dbms_random.value(100,500)) as rannum2
from dual connect by rownum<=100
)
COMMIT;
这边统计计数要测试两个方法,一个是通过嵌套group by,一个是count(distinct col)
主要通过执行计划来观察他们的效率
第一种:
explain plan for SELECT COUNT(DISTINCT t_Name) FROM student ; --生成执行计划
commit;
SELECT plan_table_output from table(dbms_xplan.display('plan_table',null,'all')); --查看执行计划
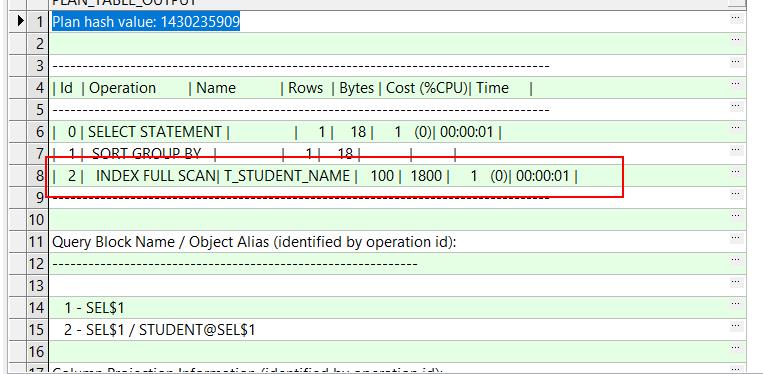
可以看到count(distinct col 这个操作是走索引的)
第二种:
explain plan for SELECT count(1) FROM
(
SELECT t_name FROM student group by t_name
);
commit;
SELECT plan_table_output from table(dbms_xplan.display('plan_table',null,'all'));
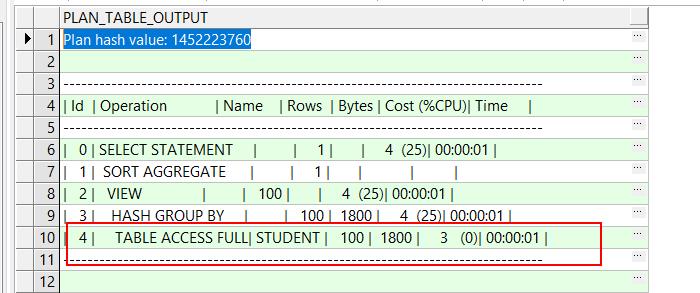
可以看到,按照第二种group by 的去重方法的话是不走索引的
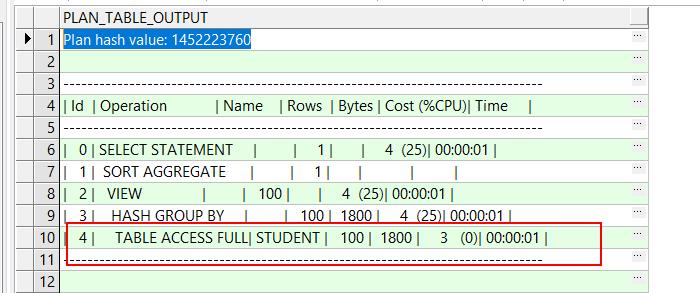
可以看到,按照第二种group by 的去重方法的话是不走索引的,是通过全表扫描取值的
因为走索引的效率>全表扫描,所以尽量避免全表扫描可以有效提高查询效率
以上是关于去重是distinct还是group by的主要内容,如果未能解决你的问题,请参考以下文章
对单个字段的结果进行去重,用distinct执行效率快,还是用group by快
MySQL中的 distinct 和 group by 去重效率区别