基于Python实现的电影数据可视化分析系统附完整代码
Posted 琪琪%¥%
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Python实现的电影数据可视化分析系统附完整代码相关的知识,希望对你有一定的参考价值。
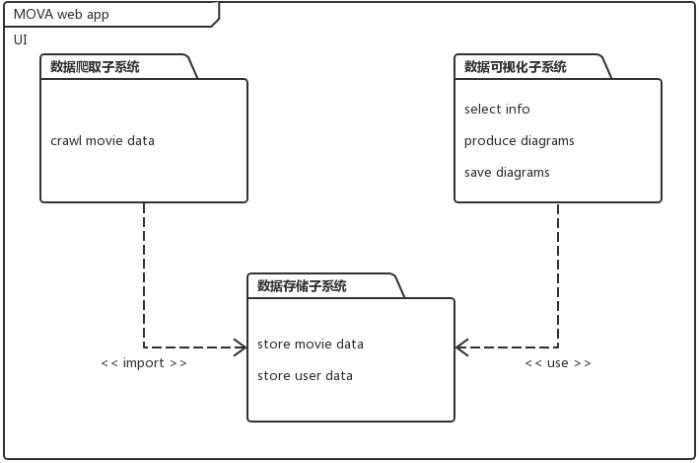
3.1系统的划分
MOVA由前端UI以及三个子系统构成:数据爬取子系统、数据可视化子系统、数据存储子系统。其包图如下所示:
3.2 数据爬取子系统的功能
3.2.1 数据爬取的用例图
用例名称:数据爬取 |
1 目标 本用例能够根据用户所选择的条件,对相关网页进行数据爬取 |
2 时间流 (1)常规流程 当用户或者管理员指定查询电影条件,并且确认查询时,本用例开 始执行 I. 用户或管理员提供查询条件(上映时间、电影类型等) II. 查询按钮被确认 III. 爬虫开始从网页爬取数据,并把数据存在数据库 IV. 其他子系统处理相关数据,向用户展示信息 (2)扩展流程 用户或管理员提供的查询条件错误 如果条件错误,系统将显示错误信息,用例结束。 (提供与查询条件最接近的信息,暂定) |
3 前置条件:用例开始前,用户或管理员属于注册且登陆成功状态 |
4 后置条件:如果用例执行成功,数据库和可视化子系统可以更新数据,并提供相应的功能 |
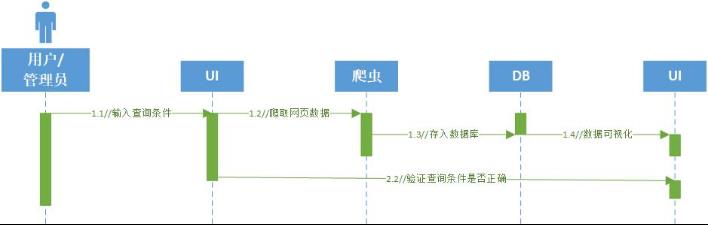
3.2.2 数据爬取用例的描述
|
用户登陆系统后,找到电影信息查询区域,在系统提供的查询框选择想查询的电影信息,数据爬取模块会根据用户的输入,爬取网页信息并将结果展示给用户;如果用户输入不合法,系统会报错提示。
3.2.3 数据爬取的用例描述
无
3.3 数据可视化子系统的功能
3.3.1 数据可视化子系统的用例图
用例图:
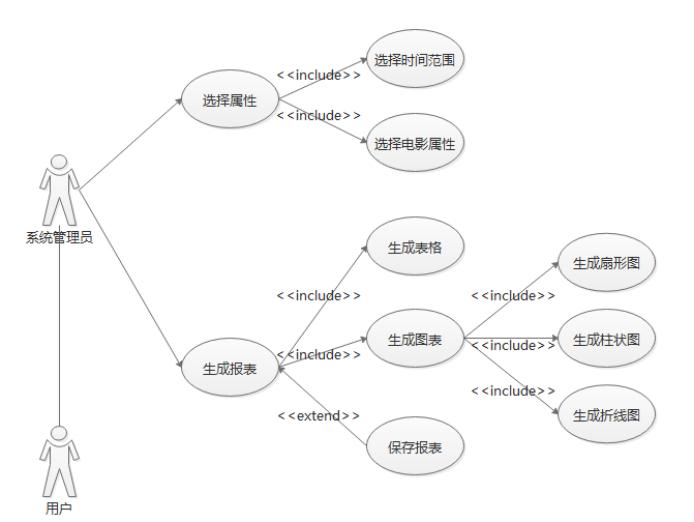
在数据可视化子系统中,用户可以通过系统管理员来进行选择报表属性、生成报表操作。“选择属性”用例包括“选择时间范围”“选择电影属性”,即用户可选择生成报表的限定时间范围,以及根据需要选择不同的电影属性生成报表,如Top10劳模演员、电影票房变化趋势等等。
“生成报表”用例包括“生成表格”与“生成图表”,即可以生成文字形式的表格,也可以生成扇形图、柱状图、折线图等不同形式的图表。此外,“生成报表”用例还可扩展出“保存报表”用例,即用户在生成报表后可以选择将报表保存,方便随时查看。
顺序图:
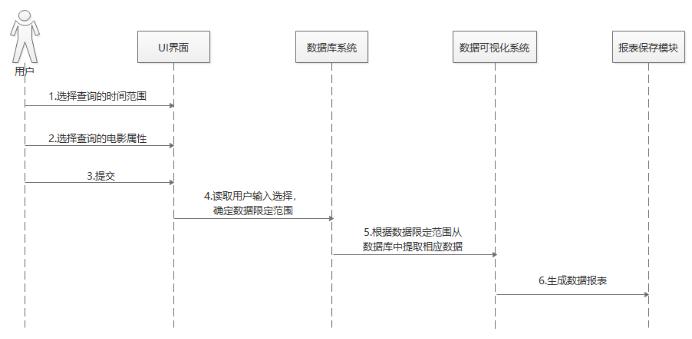
3.3.2 数据可视化子系统的用例描述 其一
“选择属性”用例:
根据用户输入的选择(时间范围、电影属性),从数据库中提取相应的数据,以用于后续生成报表。
顺序图:
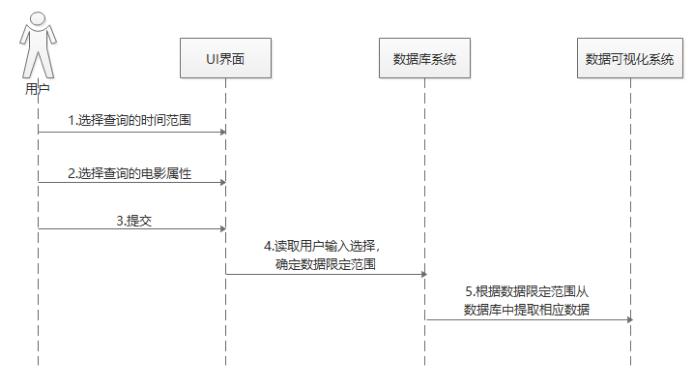
3.3.3 数据可视化子系统的用例描述 其二
“生成报表”用例:
根据数据库中提取的相应数据,生成数据报表。
顺序图:
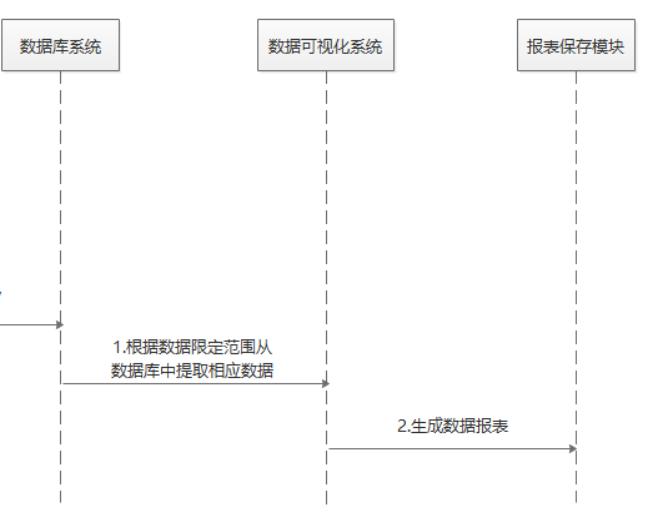
3.4 数据库系统的功能
3.4.1 数据库系统的用例图
用例名称:数据存储与读取 |
1 目标 本用例能够将爬虫爬取到的数据录入到数据库中,以及提供给可视化模块数据 |
2 时间流 (1)常规流程 当用户或者管理员使用爬虫爬取到数据后,或者可视化模块请求数据时,本用例开始执行 I. 爬虫从网页上爬取到电影相关数据(上映时间、电影类型、导演等) II. 将爬取到的数据按照类别存入数据库中的不同表中 III. 建立表格之间的联系 IV. 写入到db文件中 (2)扩展流程 可视化模块请求电影相关数据:根据请求的数据类型,按照索引从数据库中读取数据并返回给可视化模块,或者根据提供的信息,按照需求的关系,搜索数据库中的数据返回给可视化模块。 |
3 前置条件:用例开始前,用户或管理员属于注册且登陆成功状态 |
4 后置条件:如果用例执行成功,数据库更新数据,或提供给可视化模块数据 |
3.4.2 数据库系统用例的描述
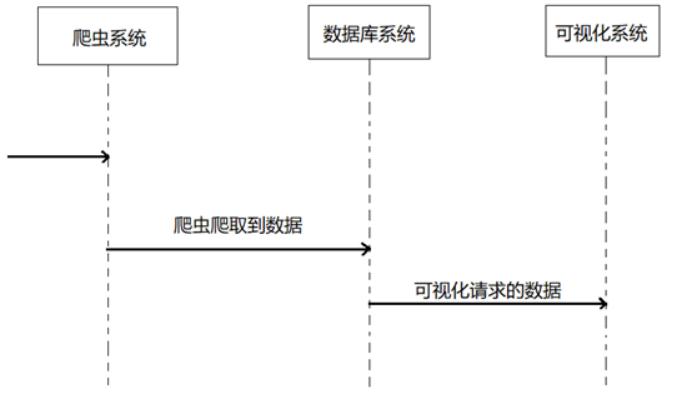
爬虫提供数据,数据库系统将其存储,在根据可视化的需求,传递给数据可视化模块
4. 其它需求描述
4.1 性能要求
运行效率较高,响应速度快
4.2 设计约束
开发工具:PyCharm,Atom
运行环境:Windows,OS X
4.3 界面要求
清晰简洁
4.4 进度要求
2018.12.25前有可使用的第一版软件
4.5 交付要求
满足软件需求且使用方便的可执行文件
4.6 验收要求
能够对电影信息进行查询
能够得到相关电影信息的可视化效果
能够保存勾选的图表
软件界面简洁好看
5. 软件原型
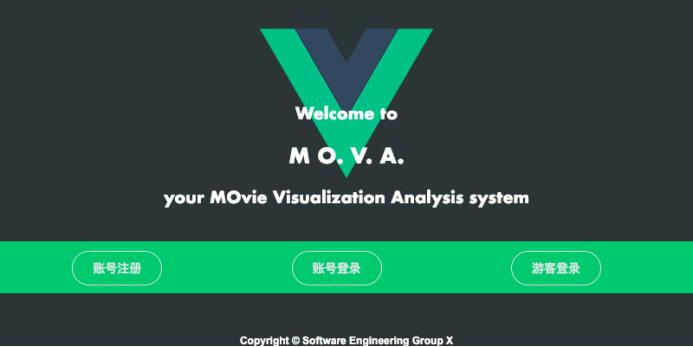
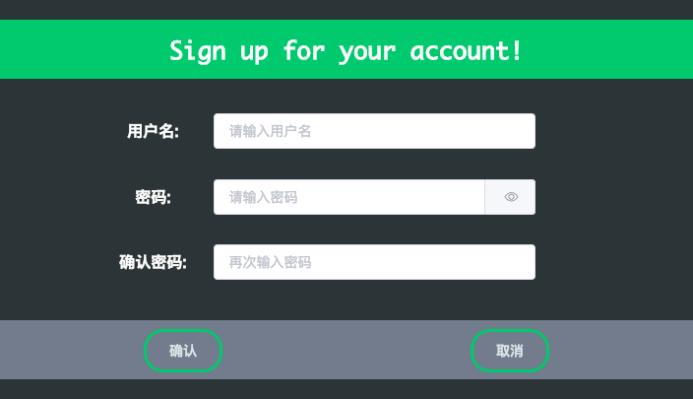
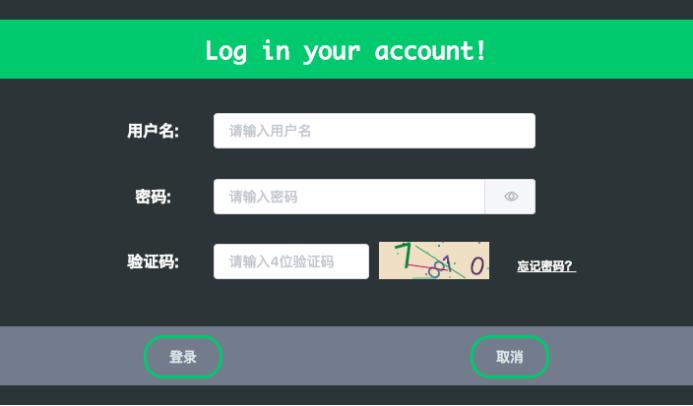
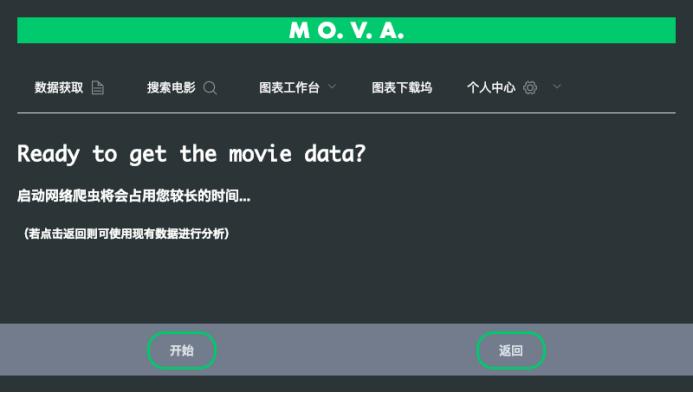
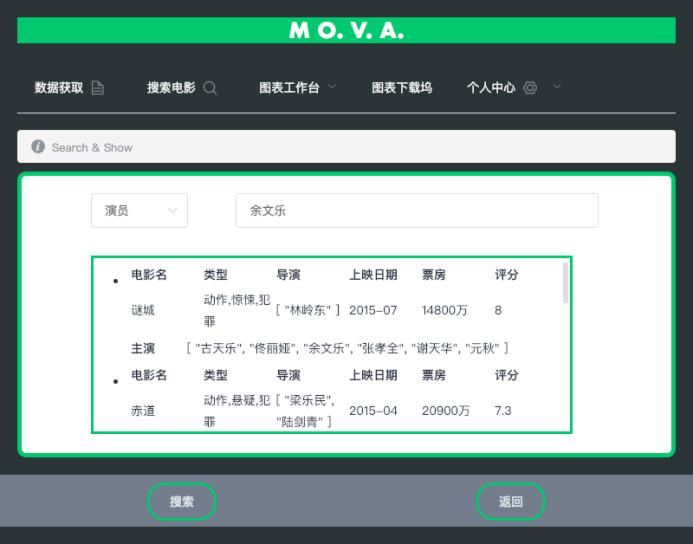
软件界面如下所示:

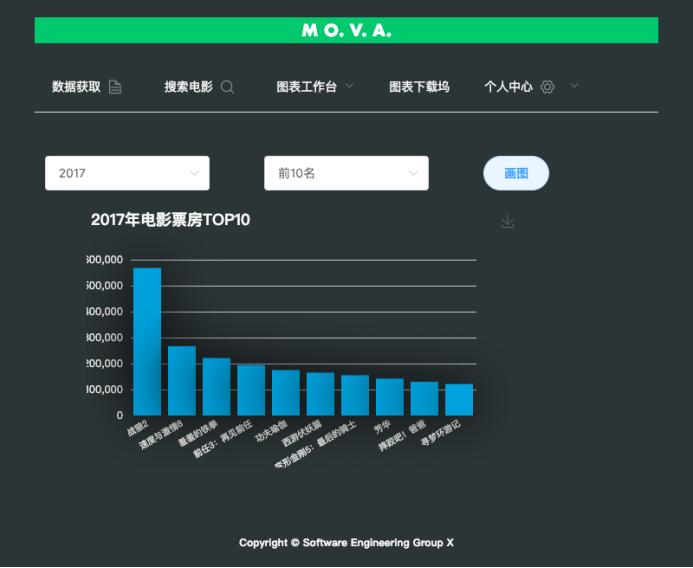
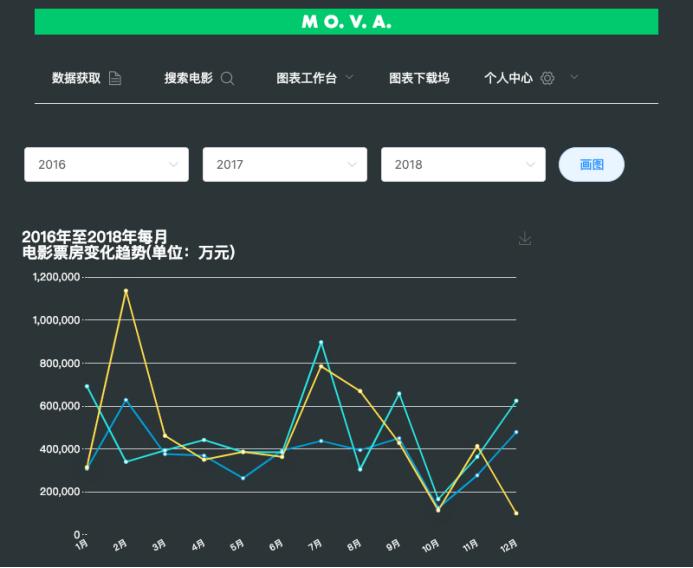
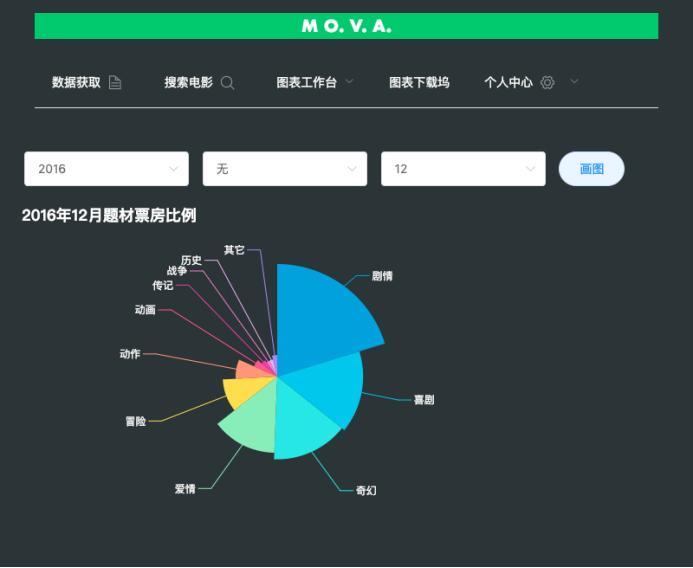
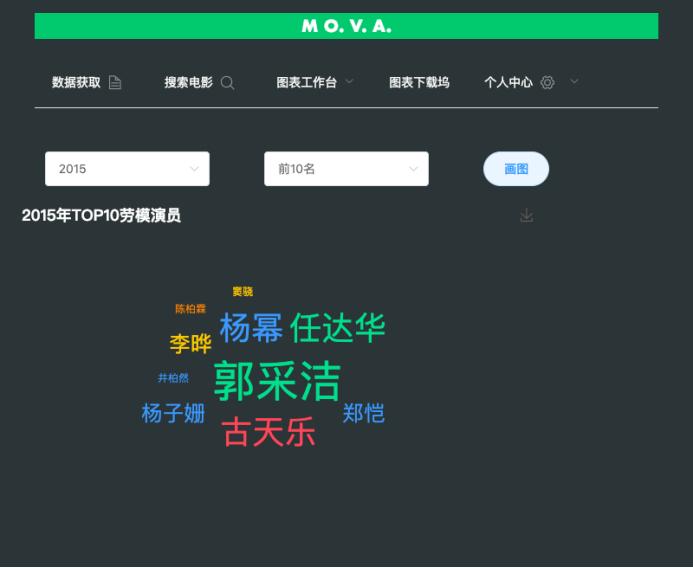
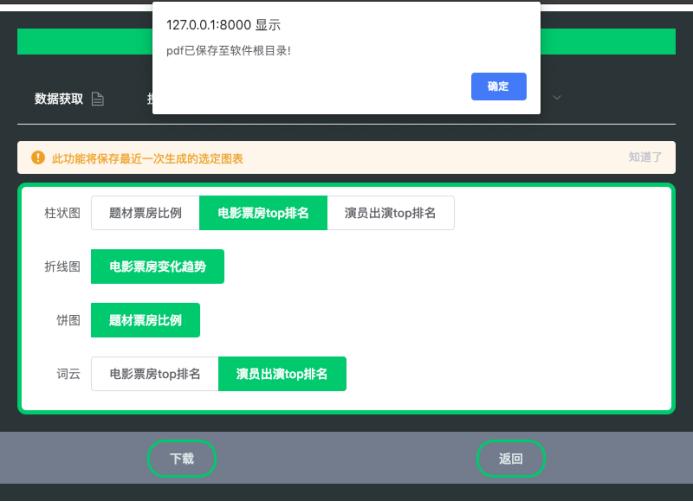
完整代码:https://download.csdn.net/download/pythonyanyan/87399296
基于python的电影数据可视化分析与推荐系统
温馨提示:文末有 CSDN 平台官方提供的博主 Wechat / QQ 名片 :)
1. 项目简介
本项目利用网络爬虫技术从国外某电影网站和国内某电影评论网站采集电影数据,并对电影数据进行可视化分析,实现电影的检索、热门电影排行和电影的分类推荐,同时对电影的评论进行关键词抽取和情感分析。
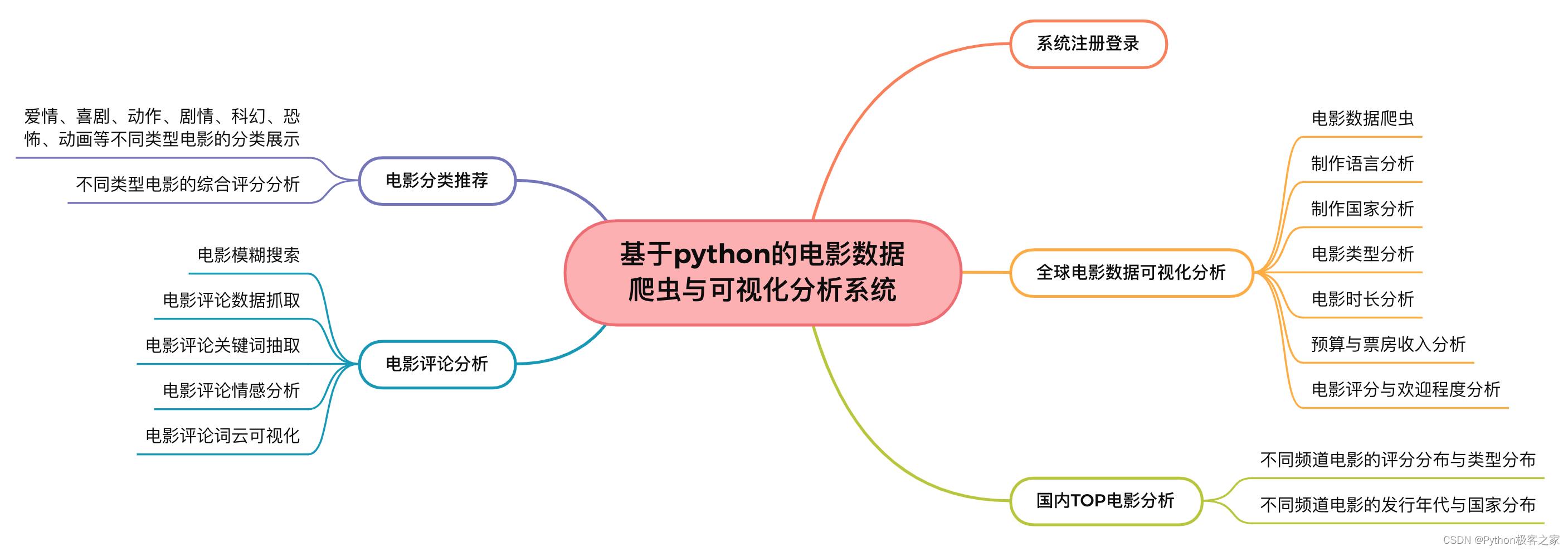
2. 功能组成
基于python的电影数据可视化分析系统的功能组成如下图所示:
3. 基于python的电影数据可视化分析与推荐系统
3.1 系统注册登录
系统的其他页面的访问需要注册登录,否则访问受限,其首页注册登录页面如下:

3.2 全球电影数据爬虫
互联网电影资料库,隶属于xxx公司旗下网站,是一个关于电影演员、电影、电视节目、电视明星和电影制作的在线数据库,包括了影片的众多信息、演员、片长、内容介绍、分级、评论等。
def get_movie_detail(url):
"""获取电影发行的详细信息"""
response = requests.get(url, headers=headers)
response.encoding = 'utf8'
soup = BeautifulSoup(response.text, 'lxml')
intro_text = soup.find('span', class_='a-size-medium').text.strip()
summary = soup.find('div', class_='mojo-summary-values')
items = summary.find_all('div', class_='a-section a-spacing-none')
movie_detail =
for item in items:
spans = item.find_all('span')
key = spans[0].text.strip()
if key == 'Domestic Distributor': # 经销商
movie_detail['Domestic_Distributor'] = spans[1].text.strip().split('See')[0]
elif key == 'Domestic Opening': # 国内开放
opening = item.find('span', class_='money').text.strip()
movie_detail['Domestic_Opening'] = float(opening.replace(',', '')[1:])
elif key == 'Budget': # 电影发行时候的预算
budget = item.find('span', class_='money').text.strip()
movie_detail['Budget'] = float(budget.replace(',', '')[1:])
elif key == 'Earliest Release Date': # 首次发行时间
movie_detail['Earliest_Release_Date'] = spans[1].text.strip().split('(')[0].strip()
elif key == 'MPAA':
movie_detail['MPAA'] = spans[1].text.strip()
elif key == 'Running Time': # 电影时长
run_time = spans[1].text.strip()
run_time = int(run_time.split('hr')[0].strip()) * 60 + int(run_time.split('hr')[1].strip()[:-3])
movie_detail['Running_Time'] = run_time
elif key == 'Genres': # 电影题材
genres = spans[1].text.strip()
movie_detail['Genres'] = genres.split()
else:
continue
mojo_gutter = soup.find('div', class_='a-section mojo-h-scroll')
# 发行地域数
areas = mojo_gutter.select('table')
movie_detail['Relase_Areas'] = len(areas)
# 发行的版本数
release_trs = mojo_gutter.select('tr')
movie_detail['Relase_Count'] = len(release_trs) - len(areas)
return movie_detail
3.3 全球电影数据可视化分析
-
电影出品的年份和制作语言分布情况

-
不同制作国家或地区的电影数目分布情况

-
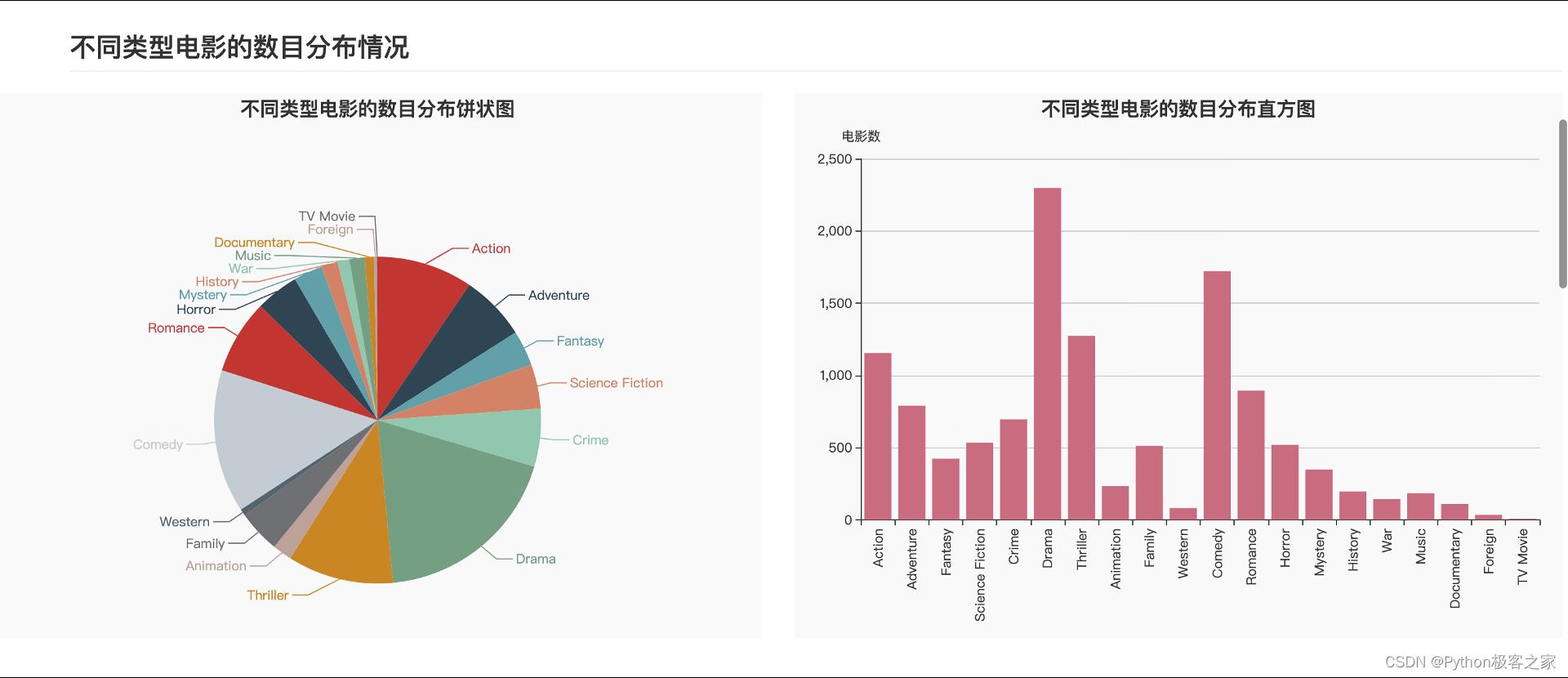
不同类型电影的数目分布情况
-
不同类型电影的时长分布箱型图

-
不同类型电影的拍摄预算与票房收入的分布箱型图
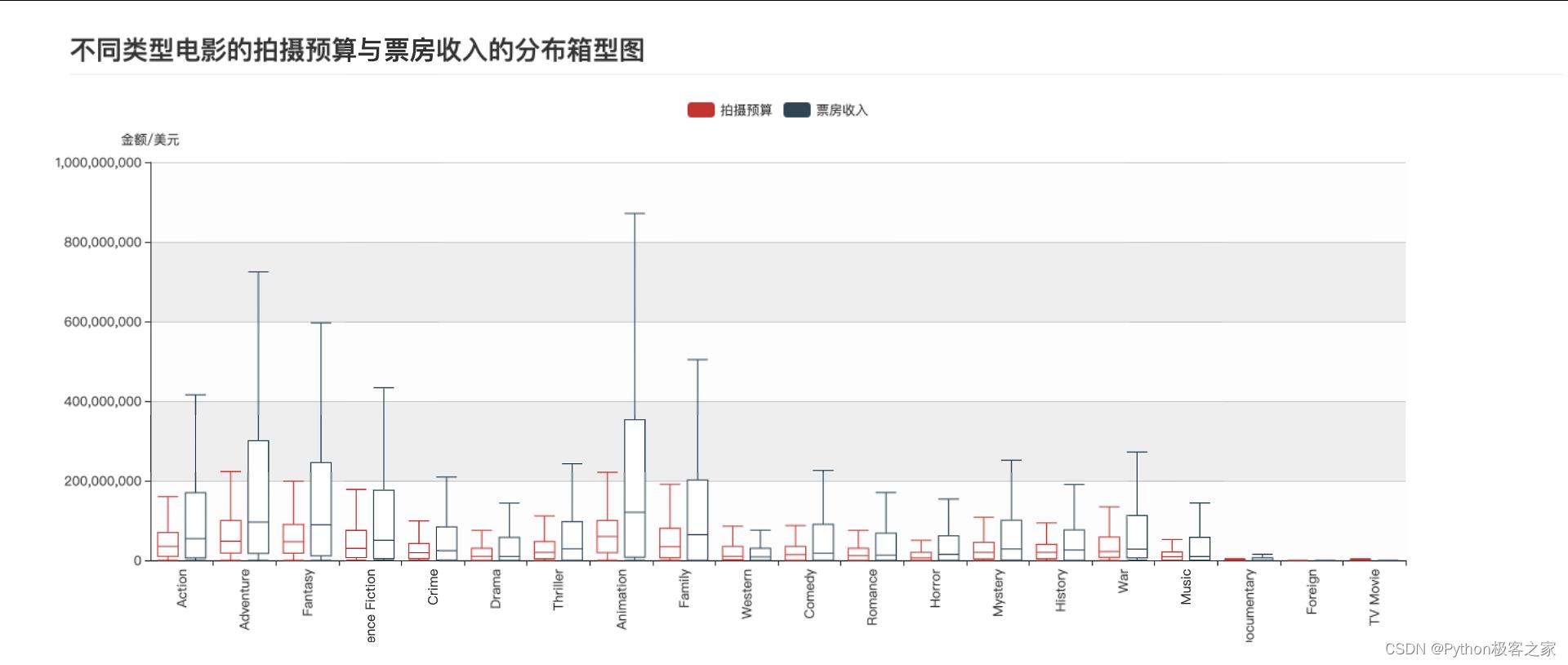
-
不同类型电影的评分分布箱型图
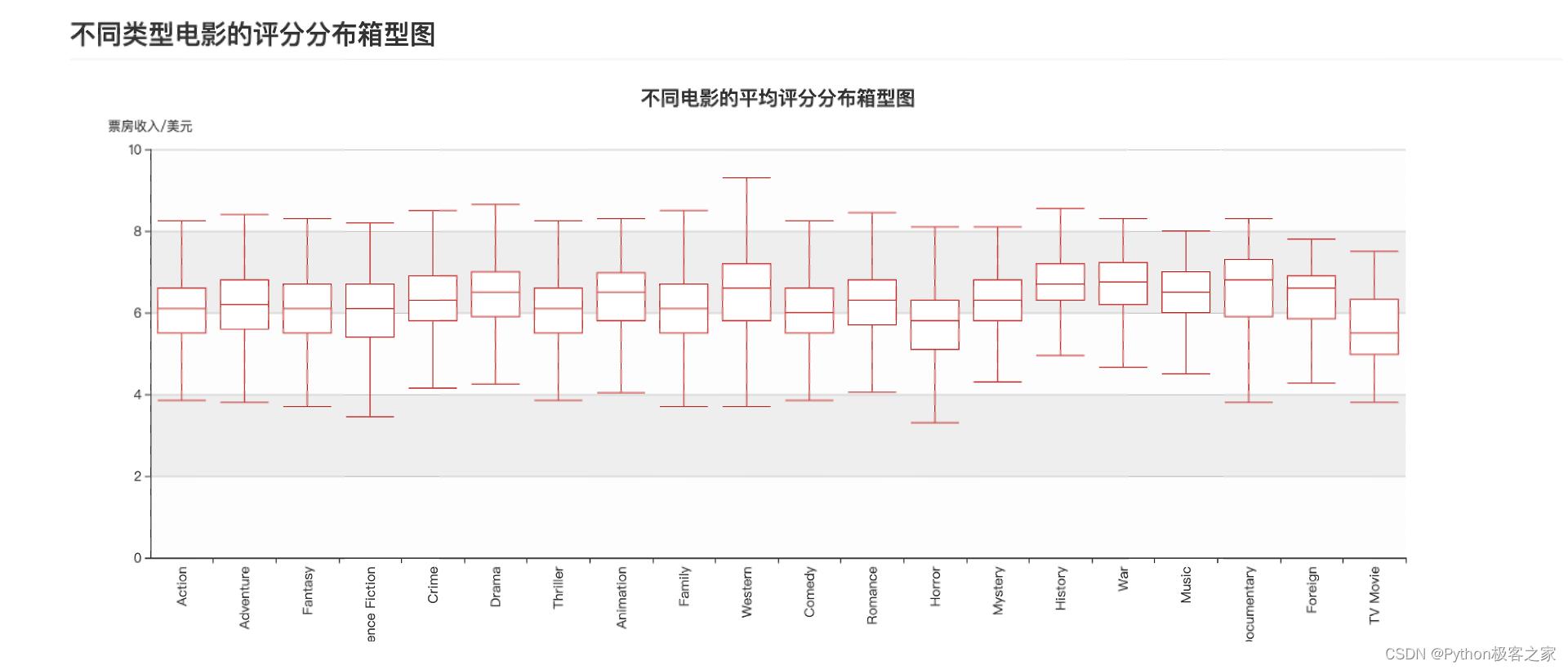
-
不同电影风格的受欢迎程度分布箱型图

-
电影评分对票房的影响

3.4 国内电影网站的 TOP 电影分析
实时抓取国内某电影评论网站不同分类下的TOP电影排名数据:
def top20_movie_analysis(cate):
""" Top20 电影 """
url = 'https://movie.xxxx.com/j/search_subjects?type=movie&tag=&sort=recommend&page_limit=20&page_start=0'.format(
cate)
print(url)
headers['Cookie'] = 'your cookie'
headers['Host'] = 'movie.xxxx.com'
headers['Referer'] = 'https://movie.xxxx.com/explore'
response = requests.get(url, headers=headers)
response.encoding = 'utf8'
resp = response.json()['subjects']
movies = []
for movie in resp:
movie_url = movie['url']
movie_info =
'电影名称': movie['title'],
'评分': movie['rate'],
print(movie_url)
# 获取影片的简介信息
resp = requests.get(movie_url, headers=headers)
resp.encoding = 'utf8'
soup = BeautifulSoup(resp.text, 'lxml')
summary = soup.find('span', attrs='property': 'v:summary')
# 年份
year = soup.find('span', attrs='class': 'year').text[1:-1]
movie_info['年代'] = year
info = soup.find('div', attrs='id': 'info')
for d in info.text.split('\\n'):
if '语言' in d:
movie_info['语言'] = d.split(':')[1].strip()
if '类型' in d:
movie_info['类型'] = d.split(':')[1].strip().split('/')
if '制片国家/地区' in d:
movie_info['制片国家/地区'] = d.split(':')[1].strip()
if '语言' not in movie_info:
movie_info['语言'] = '未知'
if '类型' not in movie_info:
movie_info['类型'] = ['未知']
if '制片国家/地区' not in movie_info:
movie_info['制片国家/地区'] = '未知'
movies.append(movie_info)
time.sleep(1)
# 按照评分排序
results =
movies = sorted(movies, key=lambda x: x['评分'], reverse=True)
results['评分排序_电影'] = [m['电影名称'] for m in movies]
results['评分排序_评分'] = [m['评分'] for m in movies]
# 按照时间排序
movies = sorted(movies, key=lambda x: x['年代'], reverse=True)
results['年代排序_电影'] = [m['电影名称'] for m in movies]
results['年代排序_年代'] = [int(m['年代']) for m in movies]
# 地区排序
diqu =
for m in movies:
for c in m['制片国家/地区'].split('/'):
c = c.strip()
if c not in diqu:
diqu[c] = 0
diqu[c] += 1
results['地区排序_地区'] = list(diqu.keys())
results['地区排序_数量'] = list(diqu.values())
# 类型排序
leixin =
for m in movies:
for l in m['类型']:
l = l.strip()
if l not in diqu:
leixin[l] = 0
leixin[l] += 1
results['类型排序_类型'] = list(leixin.keys())
results['类型排序_数量'] = list(leixin.values())
return jsonify(results)
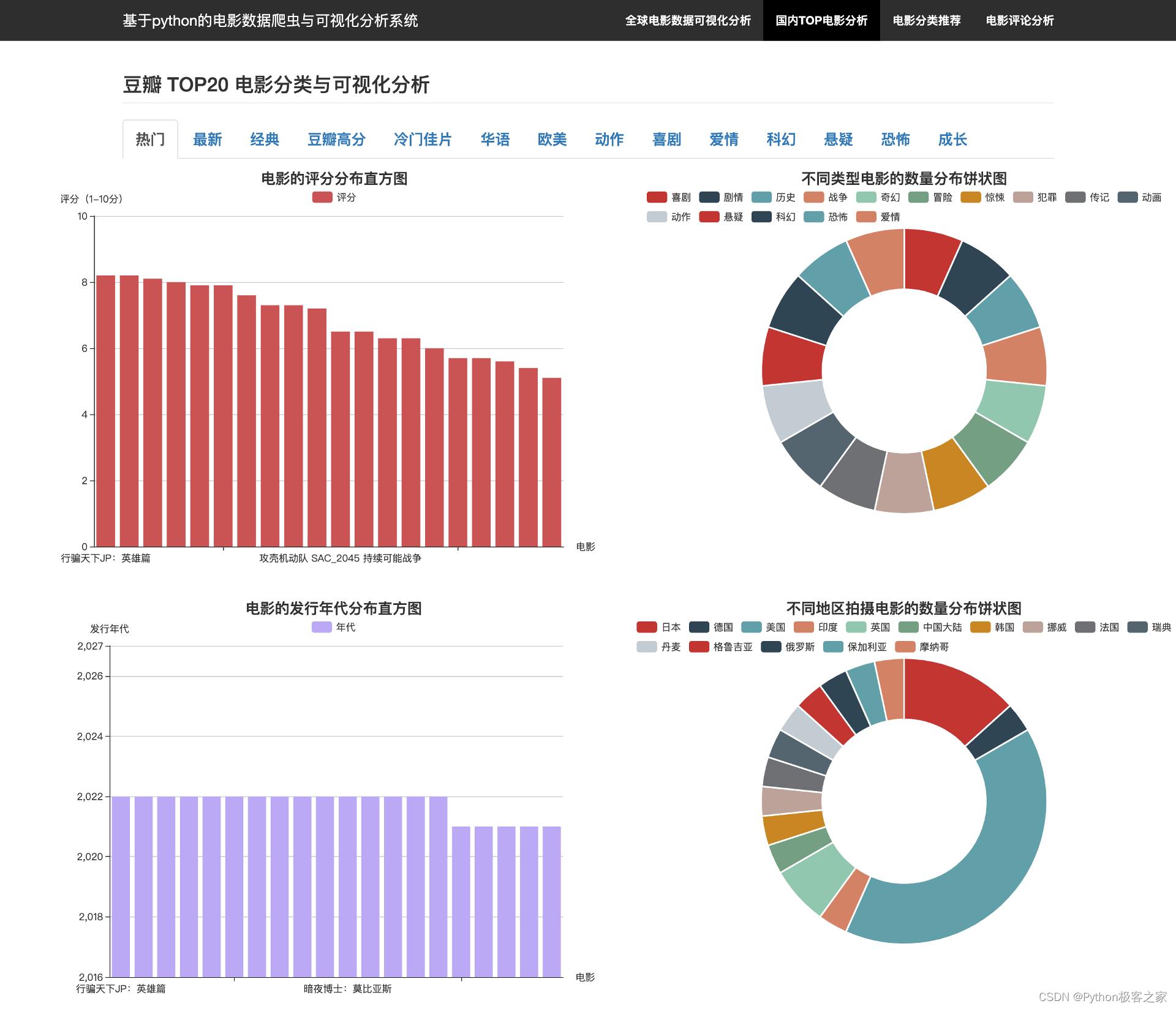
3.5 电影分类推荐
 3.6 电影评论分析
3.6 电影评论分析
对抓取的电影评论信息进行文本预处理,包括去除空字符、重复字符和标点符号等,并进行基于 tfidf 和情感词典的情感分析:
......
count = 0
while True:
......
start = 10 * (len(comments) // 10 + 1)
comment_url = movie_url + '/reviews?start='.format(start)
response = requests.get(comment_url, headers=clean_headers)
response.encoding = 'utf8'
response = response.text
soup = BeautifulSoup(response, 'lxml')
comment_divs = soup.select('div.review-item')
count += 1
for comment_div in comment_divs:
com_time = comment_div.find('span', class_='main-meta').text
comment_ori = re.sub(r'\\s+', ' ', comment_div.find('div', class_='short-content').text.strip()).replace(
'...(展开)', '').replace('(展开)', '')
if len(comments) < 200:
# 评论情感分析
postive_score = SnowNLP(comment_ori).sentiments - random.random() / 10
# 评论日期
com_time = com_time.strip().split(' ')[0]
# 评论分词
comment = ' '.join(jieba.cut(comment_ori))
comments.add((comment, com_time, postive_score, comment_ori))
else:
break
start += 10
comments = list(comments)

4. 总结
本项目利用网络爬虫技术从国外某电影网站和国内某电影评论网站采集电影数据,并对电影数据进行可视化分析,实现电影的检索、热门电影排行和电影的分类推荐,同时对电影的评论进行关键词抽取和情感分析。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
技术交流认准下方 CSDN 官方提供的学长 Wechat / QQ 名片 :)
精彩专栏推荐订阅:

以上是关于基于Python实现的电影数据可视化分析系统附完整代码的主要内容,如果未能解决你的问题,请参考以下文章