CVLatent diffusion model 扩散模型体验
Posted 山顶夕景
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CVLatent diffusion model 扩散模型体验相关的知识,希望对你有一定的参考价值。
note
文章目录
一、diffusion模型
1.1 Stable Diffusion简介
稳定扩散模型(Stable Diffusion Model)是一种用于描述信息传播和创新扩散的数学模型。它基于经典的扩散方程,但引入了长尾分布以捕捉现实中存在的大量异常事件。
在稳定扩散模型中,假设某个创新或信息被一个人采纳后,它会以一定的概率被其他人采纳,并通过社交网络进行传播。这个概率可以由多个因素决定,例如该创新的吸引力、采纳者的行为习惯等。而在每一次传播过程中,采纳者的数量服从一个长尾分布,即少数人采纳了很多次,而大多数人只采纳了很少次。这种长尾分布可以用稳定分布来建模。
通过稳定扩散模型,我们可以预测一个创新或信息在社交网络中的传播效果,以及确定哪些因素对其影响最大。此外,该模型还可以用于优化营销策略、研究用户行为等领域。
1.2 和GAN对比的优势
稳定扩散模型在计算机视觉领域的应用主要是对图像和视频中的特定物体、目标或行为的识别和跟踪。通过稳定扩散模型,可以预测物体或目标在不同时间点和场景下的出现概率,并优化跟踪算法以提高检测和识别的精度和效率。
与生成对抗网络(GAN)相比,稳定扩散模型的优势在于其具有更好的稳定性和可解释性:
- GAN通常是基于两个神经网络相互博弈,其中一个神经网络用于生成样本,而另一个神经网络则用于判别真实样本和生成样本。这种方法往往需要大量的训练数据和计算资源,同时也存在训练不稳定、模式崩塌等问题。
- 稳定扩散模型则基于传统的数学模型,具有较好的稳定性和可解释性。
- 不需要大量的训练数据和计算资源,可以从少量的数据中学习并进行预测。
- 稳定扩散模型还可以通过调整模型参数来控制模型的灵敏度和鲁棒性,以适应不同的数据分布和噪声情况。
- 稳定扩散模型在计算机视觉领域具有一定的优势,可以用于物体和目标识别、跟踪和预测等任务。但它也存在一些局限性,例如难以处理复杂的图像场景、对噪声和异常值较为敏感等问题。
二、Latent diffusion model原理
Latent Diffusion模型不直接在操作图像,而是在潜在空间中进行操作。通过将原始数据编码到更小的空间中,让U-Net可以在低维表示上添加和删除噪声。
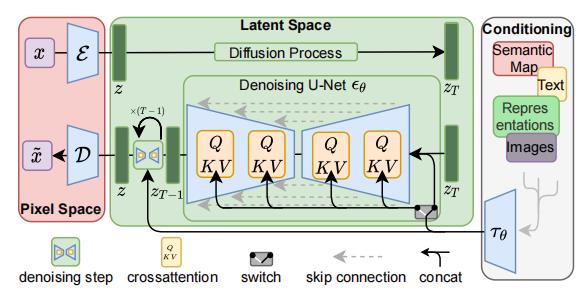
上图中的符号表示:
- x x x 表示输入图像,
- x ~ \\tildex x~ 表示生成的圈像;
- ε \\varepsilon ε 是编码器,
- D \\mathcalD D 是解码器, 二者共同构成了感知压缩;
- z z z 是潜在向量;
- z T z_T zT 是增加噪声后的 潜在向量;
- τ θ \\tau_\\theta τθ 是文本/图像的编码器(比如Transformer或CLIP),实现了语义压缩。
stable diffusion的推理过程:
- 将潜在种子和文本提示作为输入。
- 然后使用潜在种子生成大小为 64×64 的随机潜在图像表示,而文本提示通过 CLIP 文本编码器转换为 77×768 的文本嵌入。
- U-Net 以文本嵌入为条件迭代地对随机潜在图像表示进行去噪。 U-Net 的输出是噪声残差,用于通过调度算法计算去噪的潜在图像表示。
2.1 潜在空间(Lantent Space)
2.2 自动编码器和U-Net
- U-net网络模型,由编码器和解码器组成:
- 编码器将图像表示压缩为较低分辨率的图像;
- 解码器将较低分辨率解码回较高分辨率的图像。
- Unet网络:利用
DoubleConv,Down,Up,OutConv四个模块组装U-net模型,其中Up即右侧模型块之间的上采样连接(Up sampling)部分,注意U-net的跳跃连接(Skip-connection)也在这部分(torch.cat([x2, x1], dim=1))。因为每个子块内部的两次卷积(Double Convolution),所以上采样后也有DoubleConv层。
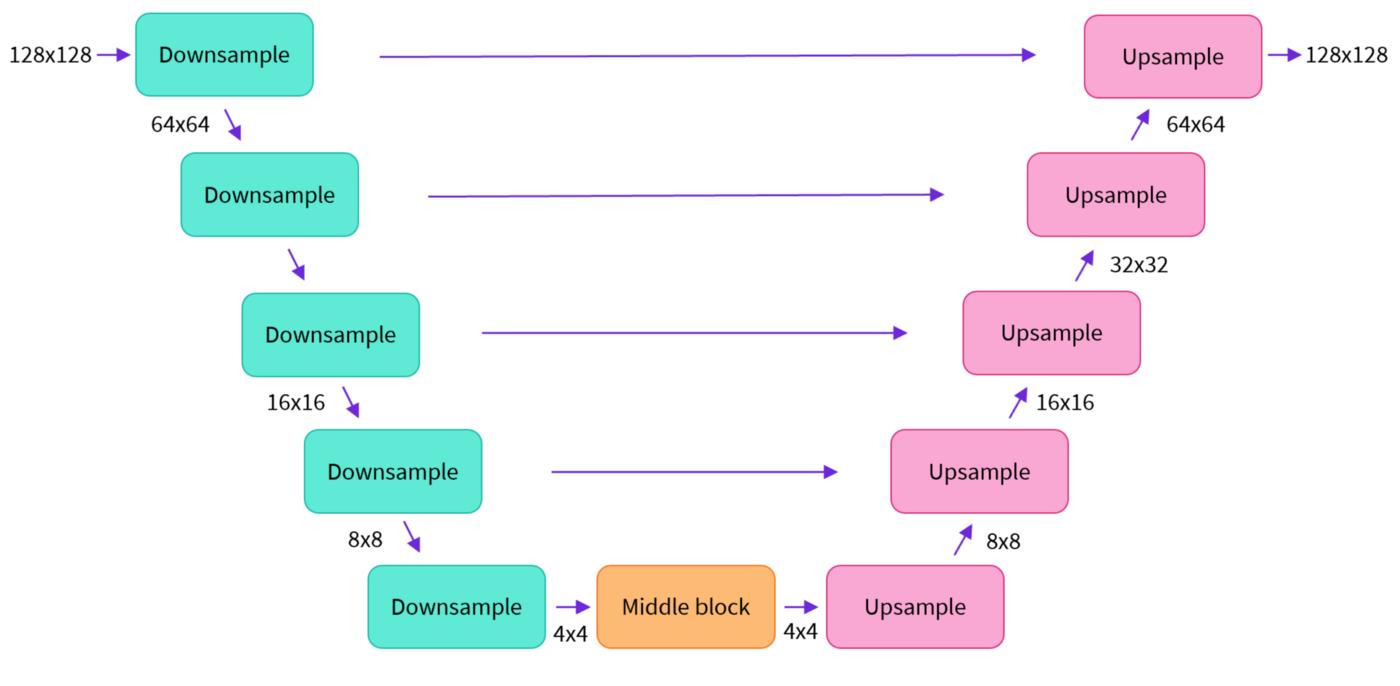
2.3 文本编码器
文本编码器将输入提示prompt转换为U-net可以理解的嵌入空间。
三、代码实践
3.1 模型权重checkpoints
sd-v1-1.ckpt: 237k steps at resolution256x256on laion2B-en.
194k steps at resolution512x512on laion-high-resolution (170M examples from LAION-5B with resolution>= 1024x1024).sd-v1-2.ckpt: Resumed fromsd-v1-1.ckpt.
515k steps at resolution512x512on laion-aesthetics v2 5+ (a subset of laion2B-en with estimated aesthetics score> 5.0, and additionally
filtered to images with an original size>= 512x512, and an estimated watermark probability< 0.5. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using the LAION-Aesthetics Predictor V2).sd-v1-3.ckpt: Resumed fromsd-v1-2.ckpt. 195k steps at resolution512x512on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning to improve classifier-free guidance sampling.sd-v1-4.ckpt: Resumed fromsd-v1-2.ckpt. 225k steps at resolution512x512on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning to improve classifier-free guidance sampling.
3.2 Stable Diffusion v1模型推理
- 仓库地址:https://github.com/CompVis/stable-diffusion
- 这里我选用的模型是stable-diffusion-v1,使用PLMS sampler采样
- Stable Diffusion v1模型使用了a downsampling-factor 8 autoencoder with an 860M UNet 和 CLIP ViT-L/14 text encoder;在256x256图片上预训练,可以在512x512图片上进行模型微调
# 创建对应虚拟环境和下载包
conda env create -f environment.yaml
conda activate ldm
mkdir -p models/ldm/stable-diffusion-v1/
# 运行代码,可以改为自己的prompt
python scripts/txt2img.py --prompt "a photograph of an cute dog" --plms
# 对应的参数设置
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision full,autocast]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision full,autocast
evaluate at this precision

3.3 安装Stable Diffusion Web Ui
提供的功能:
- txt2img — 根据文本提示生成图像;
- img2img — 根据提供的图像作为范本、结合文本提示生成图像;
- Extras — 优化(清晰、扩展)图像;
- PNG Info — 显示图像基本信息
- Checkpoint Merger — 模型合并
- Train — 根据提供的图片训练具有某种图像风格的模型
- Settings — 系统设置
Reference
[1] 由浅入深了解Diffusion Model
[2] Diffusion Model一发力,GAN就过时了?
[3] AI绘画——使用stable-diffusion生成图片时提示RuntimeError: CUDA out of memory处理方法
[4] 深度学习训练模型时,GPU显存不够怎么办
[5] 从效果看Stable Diffusion中的采样方法
[6] 1秒出图,全球最快的开源Stable Diffusion出炉.OneFlow
[7] https://github.com/CompVis/stable-diffusion
[8] High-Resolution Image Synthesis with Latent Diffusion Models.CVPR2022
[8] model list:https://huggingface.co/CompVis/stable-diffusion
[9] model card: https://huggingface.co/CompVis
[10] https://arxiv.org/abs/2103.00020
[11] AI数字绘画 stable-diffusion 保姆级教程
[12] High-Resolution Image Synthesis with Latent Diffusion Models:https://arxiv.org/abs/2112.10752
[13] https://github.com/CompVis/stable-diffusion
[14] 万字长文:Stable Diffusion 保姆级教程
[15] Stable Diffusion原理详解
[16] CompVis/stable-diffusion-v-1-1-original
由浅入深理解latent diffusion/stable diffusion:一步一步搭建自己的stable diffusion models
前言: 关于如何使用stable diffusion的文章已经够多了,但是由浅入深探索stable diffusion models背后原理,如何在自己的科研中运用stable diffusion预训练模型的博客少之又少。本系列计划写5篇文章,和读者一起遨游diffusion models的世界!本文主要介绍带大家一步步搭建自己的stable diffusion models。
目录
以上是关于CVLatent diffusion model 扩散模型体验的主要内容,如果未能解决你的问题,请参考以下文章