文智背后的奥秘系列篇——分布式爬虫之WebKit
Posted 偶素浅小浅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文智背后的奥秘系列篇——分布式爬虫之WebKit相关的知识,希望对你有一定的参考价值。
版权声明:本文由文智原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/139
来源:腾云阁 https://www.qcloud.com/community
引子:
文智平台是利用并行计算系统和分布式爬虫系统,并结合独特的语义分析技术,为满足用户NLP、转码、抽取、全网数据抓取等中文语义分析需求的一站式开放平台。其中分布式爬虫系统是获取海量数据的重要手段,给文智平台提供了有效的大数据支撑。
如果简化网络爬虫(Spider)架构,只留下一个模块,那么这个模块就是抓取器Crawler,它在整个Spider架构中就相当于一个嘴巴,这个嘴巴永远在web的海量数据世界中寻找食物。最简单的Crawler就是一个实现了HTTP协议的客户端,它接收一系列URL,向网站发起抓取请求,输出一系列网页Page,如图1所示。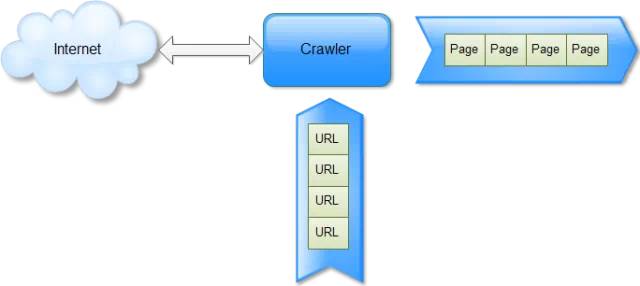
图1:Crawler的工作过程
对于一些小的抓取任务,wget就是一个很不错的选择,例如学校里面搞搜索引擎研究,就经常使用wget或基于wget源码做修改来满足需求。对单次网页下载来说,通常大部分时间都消耗在等待对方网站响应上。如果下载的并发量小,机器和带宽资源就很难得到充分利用,抓取速度上不去。作为商业搜索引擎来说,我们每天抓取数百万甚至千万数量级的网页,那么使用wget性能就远远不能满足需求。因此我们需要拥有一个高性能、高并发的轻量级抓取器。
随着工作的深入,特别是文智中文语义平台的提出,对数据的需求更加精细化、多元化,简单的HTTP抓取已经不能完全满足需求。
目前,互联网上页面的实现方式多种多样,越来越多的站点使用javascript部署,例如在http://www.tudou.com/albumcover/Lqfme5hSolM.html 这个页面中,其中关于剧集列表信息(如图2所示)就是利用JavaScript技术来填充的,如果想抓取这个信息,传统的Crawler就无能为力;有些页面抓取需要Post信息(登录等),随着Ajax技术使用,在抓取前后需要与页面进行交互,例如一些新闻的评论页面,其中的评论信息是通过点击“评论”链接后利用Ajax技术来异步抓取的,这个信息传统的Crawler也无法满足抓取需求,例如http://news.sina.com.cn/c/2014-11-26/184331207293.shtml 这个页面,如图3所示。
这些现状都给web页面的抓取收录带来了困难,也对传统Crawler提出了挑战。所以对于Crawler来说,除了高性能、高并发的要求外,还有如下需求:
- 抓取AJAX页面、模拟网页操作,进行表单提交;
- 通过javascript动态实现网页跳转;
- 对内嵌frame页进行抓取拼接;
- 多媒体文档:音、视频、图片等内容的抓取;
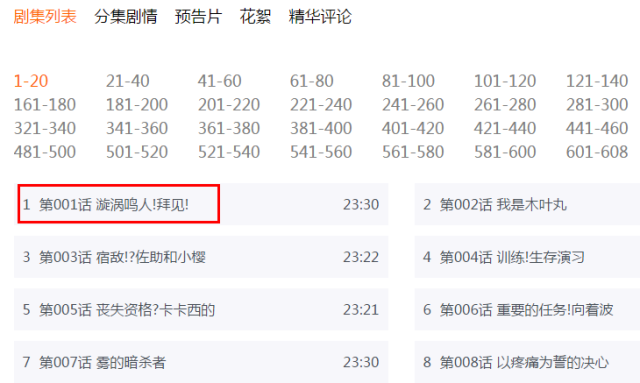
图2:通过Js技术填充的剧集列表信息
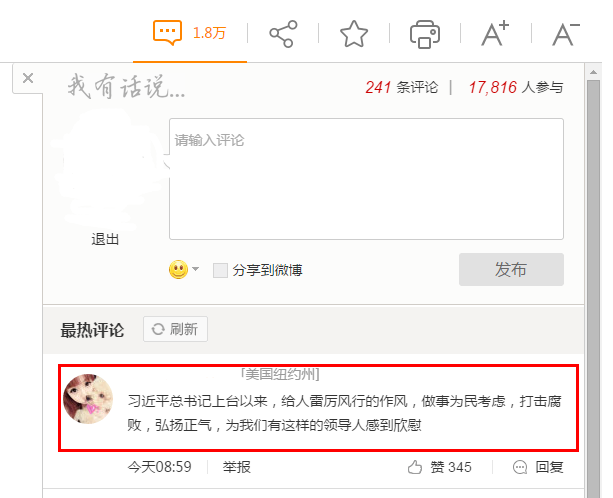
图3:通过Ajax异步加载的评论信息
这些数据就是海量数据世界中的更美味的食物,而美味的食物总是包裹着厚实的外壳。所以Crawler必须拥有强大的牙齿来破壳取食,而这个牙齿对于Crawler来说就是WebKit。
一.Webkit简介
WebKit是由Apple公司开发的开源浏览器内核,WebKit的发展具体可见文档[1],这里不再赘述。WebKit主要分为三个模块:WebCore、JavaScriptCore、平台应用相关Port。WebCore是最核心的部分,负责html、CSS的解析和页面布局渲染,JavaScriptCore负责JavaScript脚本的解析执行,通过bindings技术和WebCore进行交互,Port部分的代码结合上层应用,封装WebCore的行为为上层应用提供API来使用,如图4所示。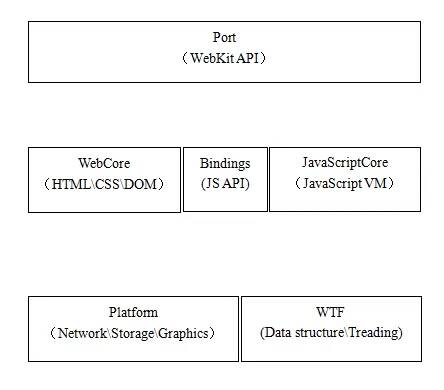
图4:WebKit框架
一个网页的加载过程从用户请求一个URL开始,首先判断是否有本地cache资源可用,如果没有则通过platform/network调用平台相关的下载模块完成HTML和其他资源的下载,HTML字符串经过HTML解析器生成HTML DOM树,并将每个DOM节点注册为JavaScript Object供JS脚本调用,在生成DOM树每个节点的同时,同步生成Layout树的每个节点,其中保存了布局信息,和CSS样式信息,系统绘制时触发page模块中的Paint操作,使用platform/graphics调用平台相关的图形库完成实际绘制,整个过程如图5所示。本文对WebKit内核不做很多介绍,如果感兴趣,请参考技术文档[2]。
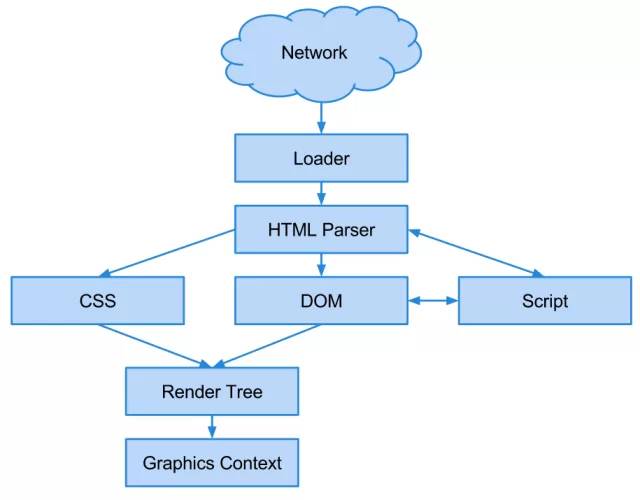
图5:WebKit加载网页过程
二.WebKit编译以及裁剪
Spider这里使用的是Qt中集成的WebKit,所用Qt的版本是Qt-4.7.4中的通用版本,下载地址见文档[3]。WebKit所在位置为qt-everywhere-opensource-src-4.7.4/src/3rdparty/webkit。这里选择的是单独编译QtWebKit。通过QMAKE命令编译产生MakeFile文件。编译过程是在接触过的源码中属于比较难编译的,需要注意的是QtWebKit依赖QtScript,单独编译QtWebKit的话,需要单独编译QtScript,具体的编译过程参考文档[4]。
由于Spider不需要最终渲染出网页,只需要WebKit执行之后的网页内容。同时为了提高WebKit的执行速度(爬虫对于性能的要求非常高),这里对WebKit进行了一些裁剪。裁剪包括去除SVG以及一些可选组件和去除WebKit的渲染网页(Render和Layout)的过程。
其中WebKit中的可选组件包括对DATABASE的支持组建、对ICONDATA的支持组建、XPATH、XSLT、XBL和SVG的支持组件。这些组件不再一一介绍,有兴趣的可以Google之。组件的裁剪过程比较简单,通过修改编译使用的PRO文件来进行,例如裁剪掉SVG组件,只需要找到WebCore目录下的WebCore.pro文件,将其中的“qt-port: !contains(DEFINES, ENABLE_SVG=.): DEFINES += ENABLE_SVG=1”修改为“ENABLE_SVG=0”,然后使用qmake生成新的makefile编译即可。
去除WebKit的渲染和排版(Render和Layout)的过程比较繁琐,首先需要确定WebKit中进行页面绘制和渲染的入口,通过阅读源码和GDB调试得知:FrameView::layout操作实现绘制前的排版工作,文档绘制的入口是Frame::paint函数。经过分析验证,页面显示过程中的绘制(paint)的函数入口就是Frame::paint,它的绘制动作的触发来自于上层的动作。作为最靠近Qt的函数入口,只需要把这个函数注释掉,所有的绘制动作就不会再发生。layout的动作是由于FrameView的layout动作引起的。注释掉函数Frame::paint和FrameView::layout之后,就堵住了绝大多数的绘制和排版动作,从而节省了WebKit加载网页的时间。
三.WebKit在Spider中的应用
如前所述,WebKit为Spider提供了更强大的数据抓取的能力,其中它作为一个单独的服务模块来处理需要WebKit加载的页面,目前采用比较简单的CGI接口来与上游服务对接,与上游服务模块之间通过HTTP协议进行交互。后期随着业务复杂度的提升和接口数据的复杂化,不排除使用自定义协议的可能,服务模型如图6所示。
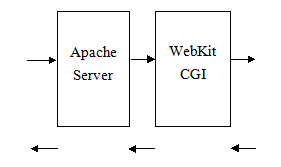
图6:WebKit CGI服务
为了使WebKit作为一个类库应用于服务器的运行中,首要的问题就是去除WebKit中所有关Qt图形化的部分,然后才可以考虑去掉WebKit中有关Qt的其他工具类的应用。这样才能够在在非图形化的方式下获得页面Load之后的内容,而这一内容同时也包括了页面中的非交互式JS代码所生成的内容。本文档所描述的去图形化步骤为:
- 去除WebKit中所有有关QWidget的代码;
- 在去除了QWidget的基础上,修改WebKit代码中有关QWidget属性的获取和设置部分;
- 去除WebKit中有关QApplication的相关代码。
但是目前存在的问题是QApplication必须在main函数中初始化并使用的,而通过Qt的文档也可以看出每一个GUI Qt程序都必须初始化一个QApplication对象,该对象主要管理整个Qt程序的资源以及处理分发Qt程序运行中的事件。这种应用模式是不能够满足作为一个独立类库来使用的,因为QCoreApplication只能在main函数中初始化,并且必须调用app.exec()才能够进入事件处理的循环。目前只有搞清楚WebKit中的整个执行流程,完全去除Qt,这一方法需要了解整个WebKit中的功能,搞清楚目录WebKit/qt、目录WebCore/platform中所有有关文件中的Qt部分的功能,以及与WebCore和JavaScriptCore结合的方式。这种方法优势是可以完成一个独立的类库,将来的服务器运行效率要高,劣势是需要人力和时间去研究上述代码,时间周期长,所以目前还是保留app.exec()。
由于Spider下载需要考虑外网权限和网站封禁等策略,这里使用重写QNetworkProxyFactory类中queryProxy来实现网络代理,首先配置可以访问外网的机器列表,通过对URL串计算MD5值,然后根据MD5值计算hash值,以决定使用哪台外网机器来下载数据。
WebKit不仅会加载URL对应的HTML文档,同时会下载HTML文档中的那些图片数据以及CSS、JS数据等。但是对于Spider来说,目的是能够发现更多的优质URL,对于网页渲染的样式和图片数据并不关心,所以下载这些数据对于Spider来说是一种额外的负担。这里通过对QNetworkAccessManager中的createRequest进行重写,对于后缀是css、png、gif、jpg、flv的URL返回一个不可到达的request,这个request直接返回一个错误,并不会发起真正的网络请求,这样就减少了网络IO,加快网页的加载速度.
目前基于WebKit,Spider实现了抓取AJAX网页、模拟点击后抓取需求。抓取AJAX页面比较简单,WebKit在load网页之后,会执行页面中JS脚本,实现异步拉取数据,然后重新拼装页面,webframe在收到loadfinsh信号之后,即可获得加载异步数据之后的页面。模拟点击也比较类似,通过JS代码嵌入到网页中,然后通过evaluateJavaScript函数触发JS代码执行,执行完再获取网页数据即可。目前正在开发支持JS实现网页跳转(一般浏览器访问一条URL发生跳转时,地址栏的URL会改变,捕获到这种改变,即能拿到所有跳转的URL。在应用层监听QWebFrame的urlChanged信号,当地址栏的URL发生改变时触发自定义的onUrlChanged槽函数,通过这个槽函数来实现自动跳转,获得跳转后的页面)、支持多协议抓取等功能,相信WebKit会在Spider中的应用越来越广泛,能够爬取更多壳内的宝贵数据。
参考文档:
[1] http://web.appstorm.net/general/opinion/the-histoy-of-webkit
[2] https://www.webkit.org/coding/technical-articles.html
[3] http://download.qt-project.org/archive/qt/4.7/qt-everywhere-opensource-src-4.7.4.tar.gz
[4] http://trac.webkit.org/wiki/BuildingQtOnLinux
以上是关于文智背后的奥秘系列篇——分布式爬虫之WebKit的主要内容,如果未能解决你的问题,请参考以下文章