大数据实战——hadoop集群组件启动及服务组件配置修改
Posted 北溟溟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据实战——hadoop集群组件启动及服务组件配置修改相关的知识,希望对你有一定的参考价值。
前言
本节内容我们主要介绍,如何启动hadoop的组件服务,例如hdfs、yarn等,并通过修改自定义配置文件,修改我们组件的配置。关于hadoop组件的部署同上一节内容,如下:
| hadoop101 | hadoop102 | hadoop103 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
正文
- hadoop服务组件的配置文件
①hadoop服务默认配置文件说明
文件名称 默认存放位置 说明 core-default.xml hadoop-common-3.1.3.jar/core-default.xml 核心配置文件 hdfs-default.xml hadoop-hdfs-3.1.3.jar/hdfs-default.xml hdfs组件配置文件 yarn-default.xml hadoop-yarn-common-3.1.3.jar/yarn-default.xml yarn组件配置文件 mapred-default.xml hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml MapReduce组件配置文件 ②在/opt/module/hadoop-3.1.3/etc/hadoop目录下修改hadoop自定义配置文件
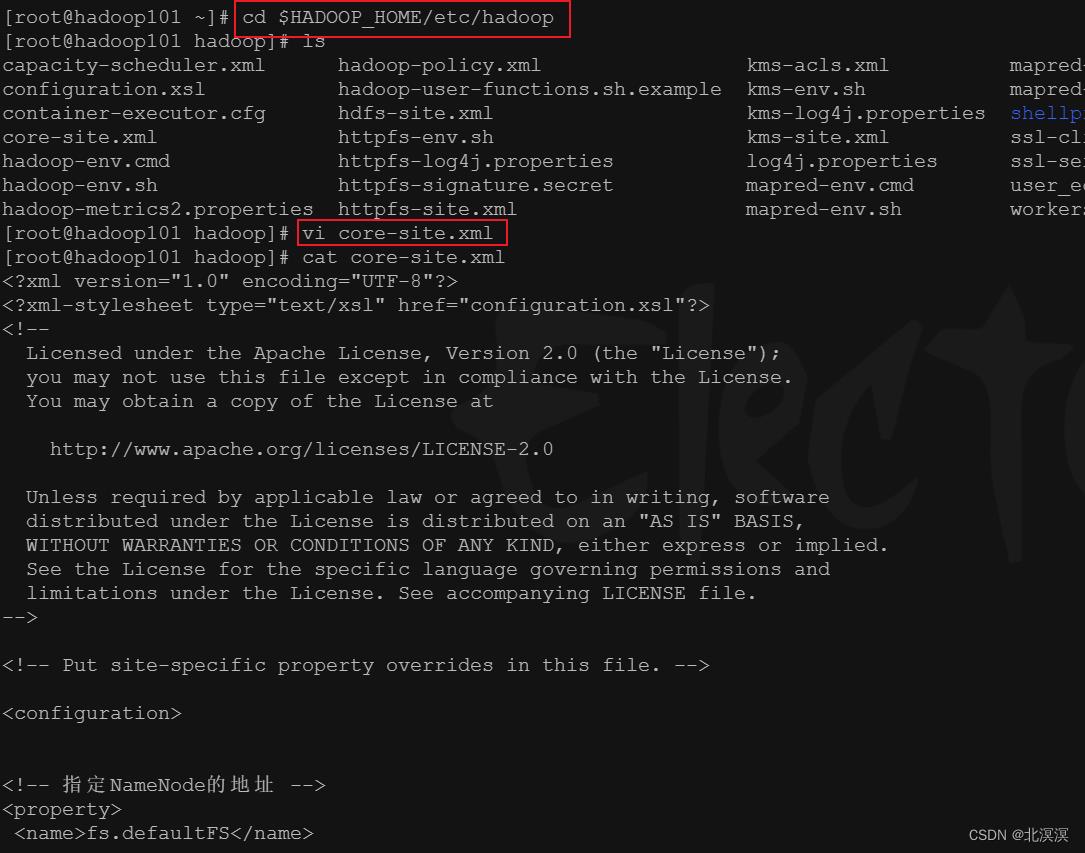
a.使用vi编辑器修改core-site.xml核心配置文件
<!-- core-site.xml配置 --> <configuration> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop101:8020</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为hadoop --> <property> <name>hadoop.http.staticuser.user</name> <value>hadoop</value> </property> </configuration>
b.使用vi编辑器修改hdfs-site.xml配置文件
<!-- nn web 端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop101:9870</value> </property> <!-- 2nn web 端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop103:9868</value> </property>
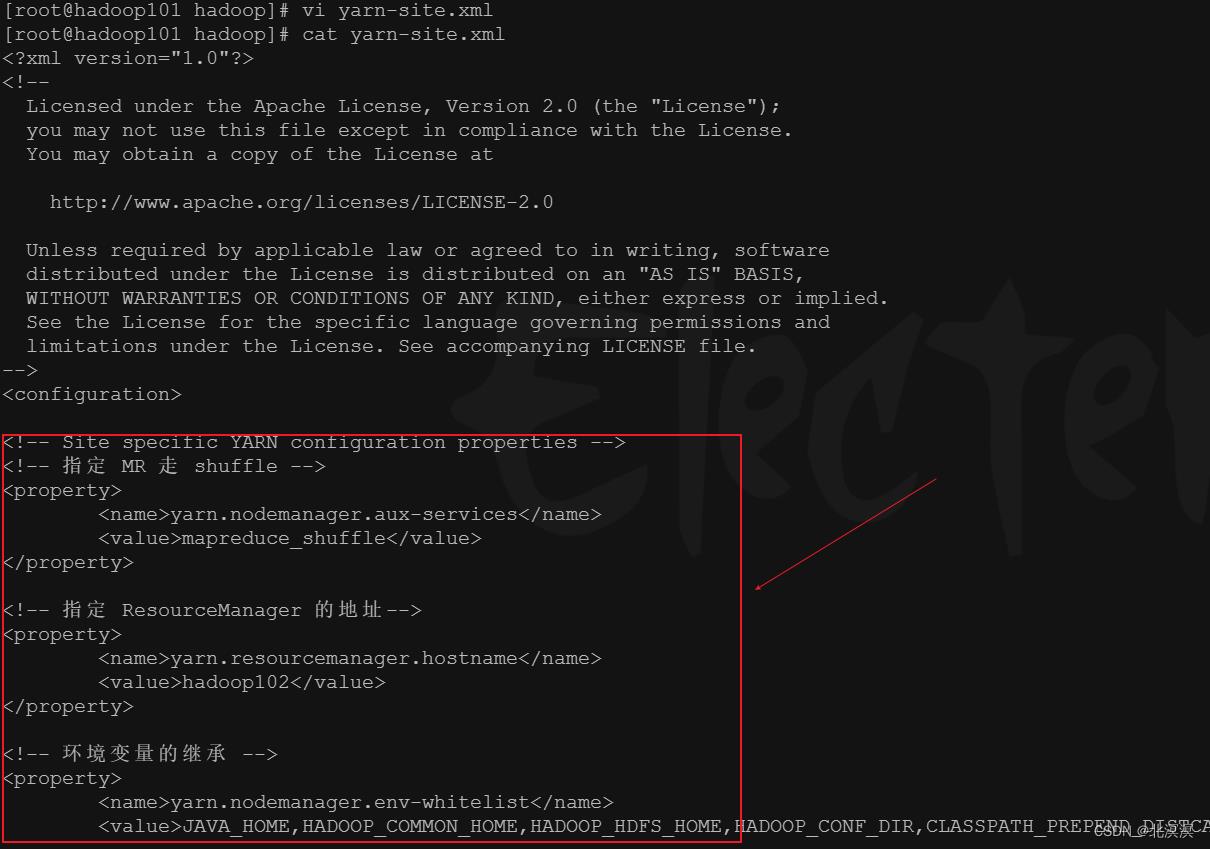
c.使用vi编辑器修改yarn-site.xml配置文件
<!-- 指定 MR 走 shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定 ResourceManager 的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop102</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property>
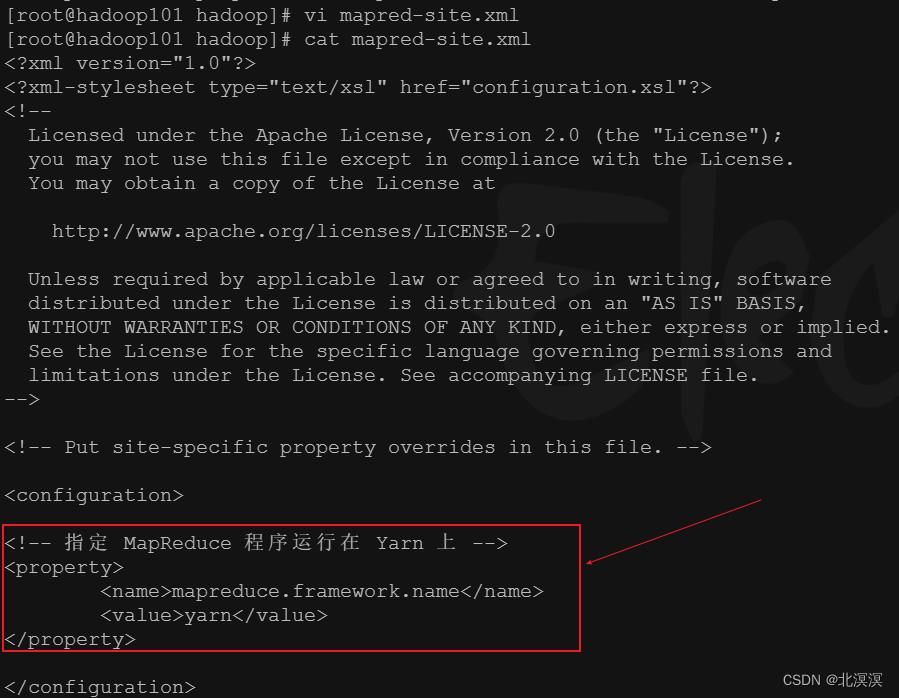
d.使用vi编辑器修改mapred-site.xml 配置文件
<!-- 指定 MapReduce 程序运行在 Yarn 上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
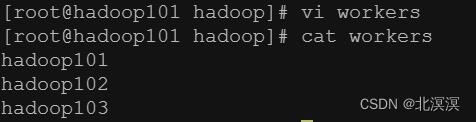
e.配置workers
③分发修改的配置文件到hadoop102与hadoop103服务器
命令:hsync /opt/module/hadoop-3.1.3/etc/hadoop


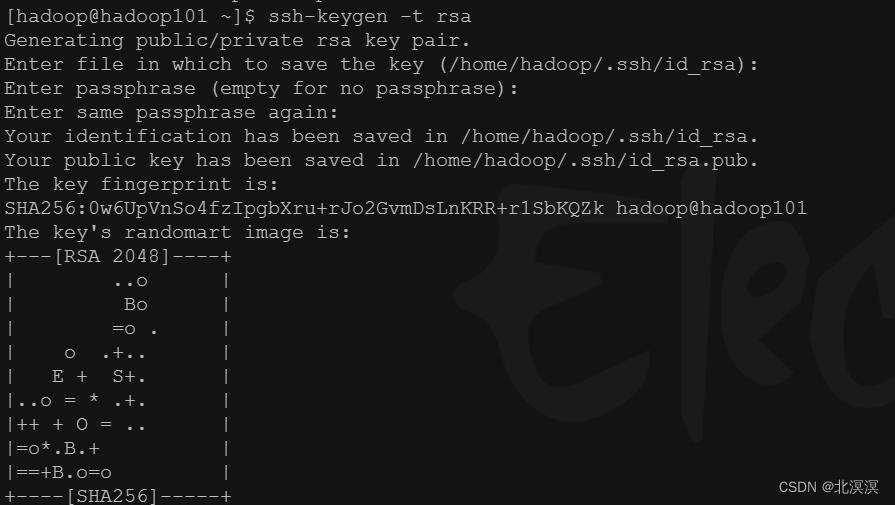
- 将hadoop集群的root账号切换到hadoop账号,实现hadoop账户之间的免密登录和文件共享
①hadoop集群服务器全部切换到hadoop账户下,实现hadoop账户下的免密登录 ,所有hadoop服务器都执行此项操作
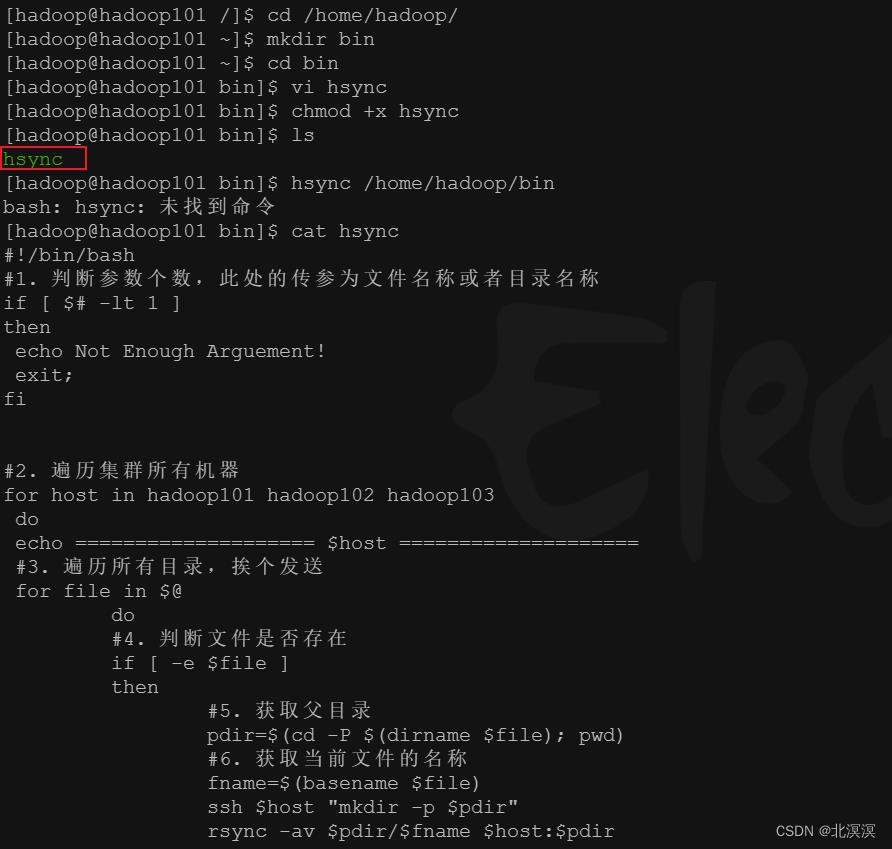
②在hadoop101服务器上的hadoop账户下创建共享文件脚本
#!/bin/bash #1. 判断参数个数,此处的传参为文件名称或者目录名称 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in hadoop101 hadoop102 hadoop103 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done
③在可执行脚本hsync目录/home/hadoop/bin下的hadoop101、hadoop02、hadoop103服务器上分别执行以下命令
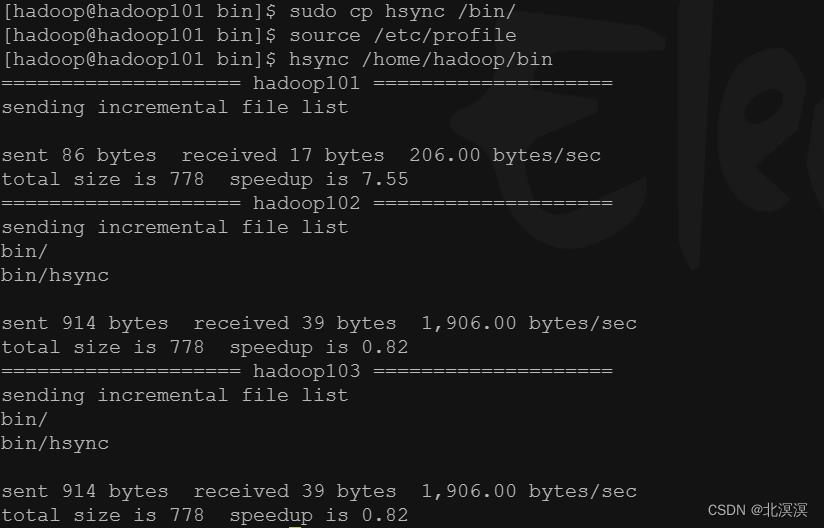

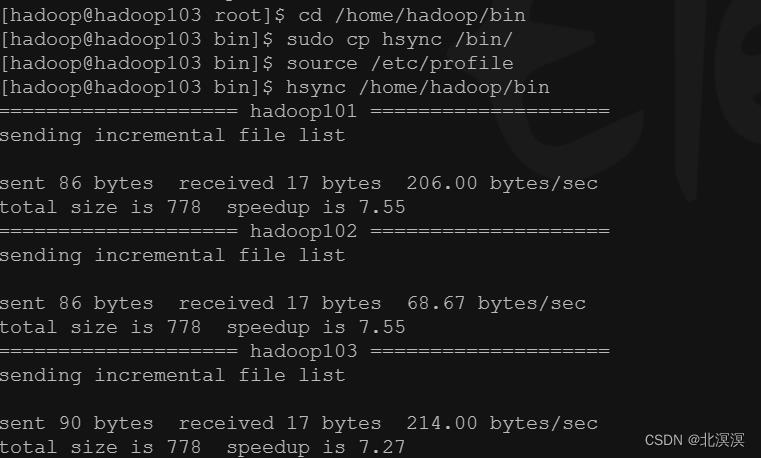
- hadoop服务组件启动
①如果集群是第一次启动,需要在 hadoop101节点格式化NameNode
命令:hdfs namenode -format
②在hadoop101服务器上启动hdfs
命令:sbin/start-dfs.sh
③在hadoop102服务器上启动yarn
命令:sbin/start-yarn.sh

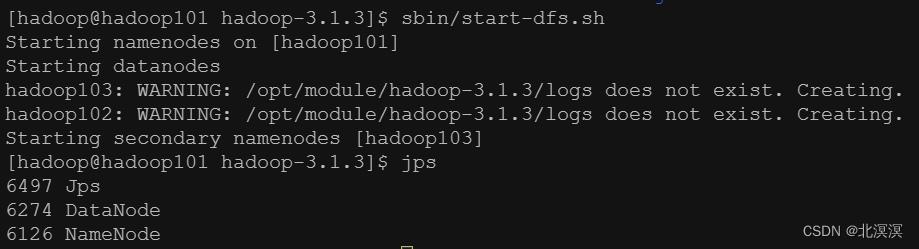
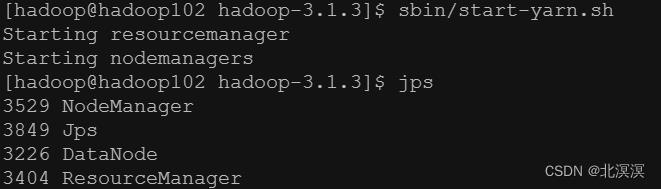
- 验证hadoop集群
①访问hdfs地址:http://hadoop101:9870/
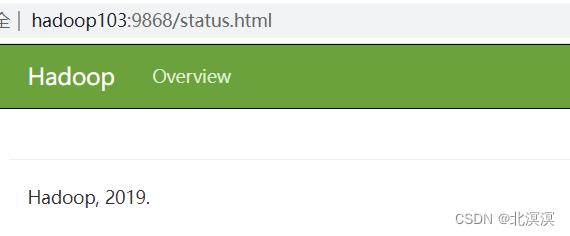
② 访问2nn的web地址
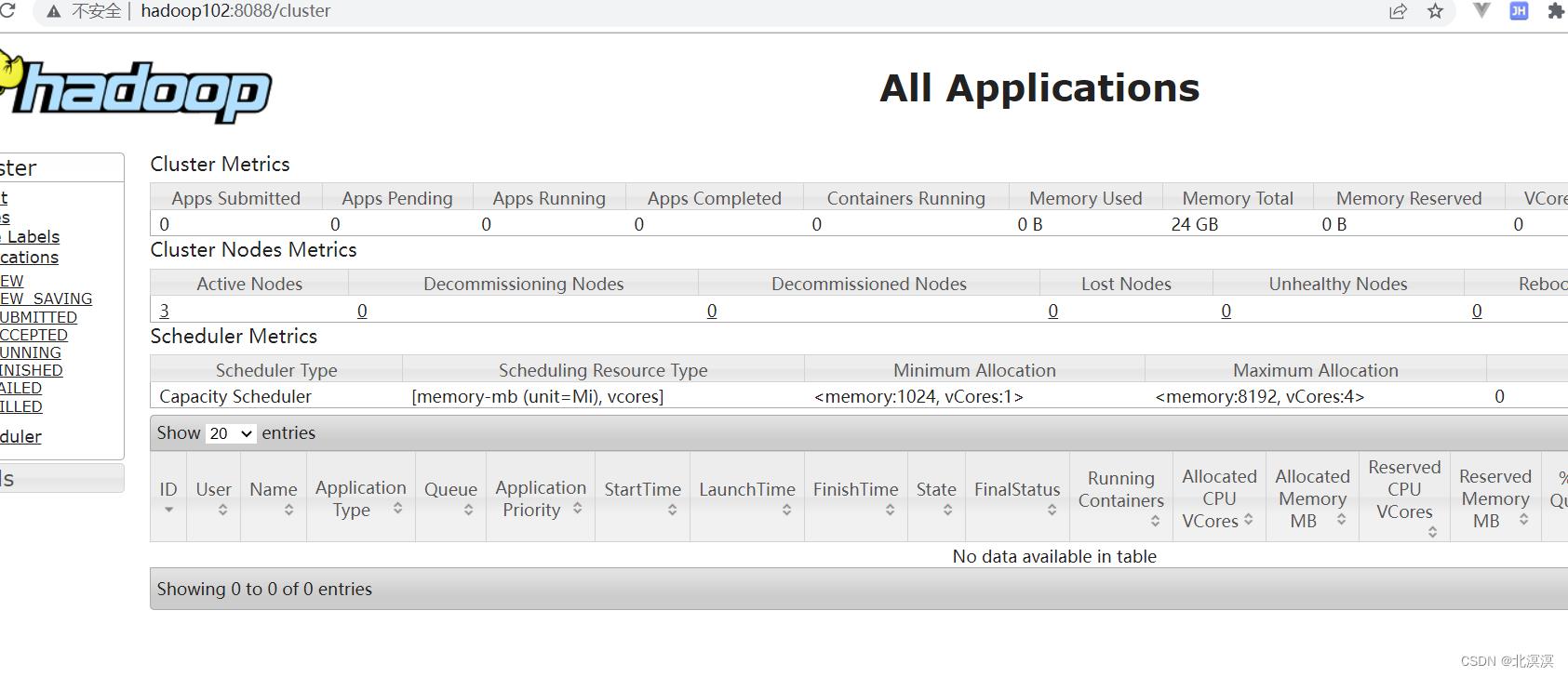
③访问yarn的web地址:http://hadoop102:8088/
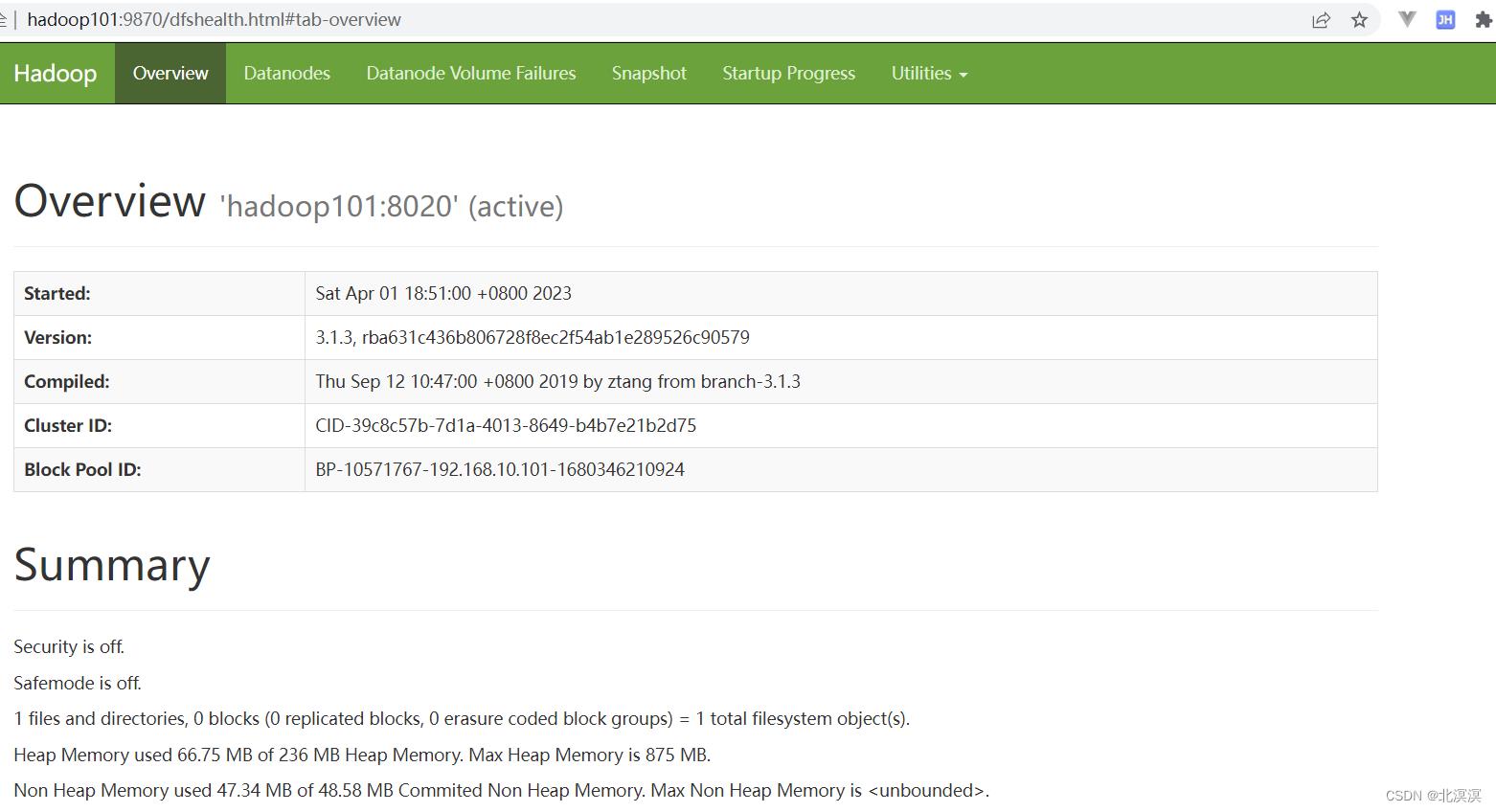
结语
至此,关于hadoop组件启动及自定义配置文件的内容到这里就结束了,我们下期见。。。。。。
大数据实战——hadoop集群安装搭建
前言
本节内容我们主要来介绍如何搭建hadoop集群,将hadoop的基础环境搭建完成,便于我们使用hadoop集群。在搭建hadoop集群搭建之前,我们需要先安装java环境,并且我们需要规划我们hadoop集群的组件分布,保证hadoop集群服务器能发挥其最大的价值。
hadoop集群组件分布如下:
| hadoop101 | hadoop102 | hadoop103 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
正文
- java环境安装
①上传java安装包到hadoop101服务器
②解压java安装包到/opt/module目录
命令:tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
③在/etc/profile.d目录下,新建环境变量配置文件my_env.sh
④在配置文件my_env.sh中添加java环境变量配置
#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin
⑤让新的环境变量 PATH 生效,查看java环境配置是否生效
source /etc/profile
⑥分发java安装包到hadoop102和hadoop103服务器
hsync /opt/module/jdk1.8.0_212
⑦分发环境配置文件my_env.sh到hadoop102和hadoop103服务器
hsync /etc/profile.d/my_env.sh
⑧分别在hadoop102与hadoop103上面执行source /etc/profile,查看java是否安装完成









- hadoop安装
①上传hadoop安装包到hadoop101服务器
② 解压hadoop安装包到/opt/module目录
命令:tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
③获取hadoop安装目录/opt/module/hadoop-3.1.3
④在/etc/profile.d/my_env.sh环境变量配置文件中配置hadoop的环境变量
#HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
⑤使配置的环境变量生效,并查看hadoop的安装情况
source /etc/profile
⑥分发hadoop安装包到hadoop102和hadoop103服务器
命令:hsync /opt/module/hadoop-3.1.3/
⑦分发环境配置文件my_env.sh到hadoop102和hadoop103服务器
hsync /etc/profile.d/my_env.sh
⑧分别在hadoop102与hadoop103上面执行source /etc/profile,查看hadoop是否安装完成








结语
本节内容到这里就结束了,关于hadoop的组件运行及启动,由于篇幅所限,我们在下节内容中再详细介绍,后会有期。。。。。。
以上是关于大数据实战——hadoop集群组件启动及服务组件配置修改的主要内容,如果未能解决你的问题,请参考以下文章