为什么一般公司面试结束后会说「回去等消息」,而不是直接告诉面试者结果?
Posted 测试界的飘柔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么一般公司面试结束后会说「回去等消息」,而不是直接告诉面试者结果?相关的知识,希望对你有一定的参考价值。
面试经常遇到 HR 说:我们将在 3 个工作日内给予回复,为啥不直接给结果?八个方面告诉你真实原因
职场上相信很多人不清楚为什么面试后,HR 都让其回家等消息,而不是当场告诉你面试结果,这是 HR 的正常工作的套路技巧,一般存在问题是:面试官目前还不想下决策确定该岗位的人选。下面,小编将告诉大家为什么很多公司面试后不是直接给结果,而是回去等通知的真实原因。

第一、对候选人素质或者专业存在疑虑
人性心理是遇到自己喜欢的人物或者事物都会表现出喜悦的表情,如果面试官对你很感兴趣,岗位匹配度高,例如同行业、经验要求,专业要求也都挺好,那么 95%的面试官绝对会表现出你面试结果是否通过的话语,也会跟你面试很长时间,聊很多他感兴趣的话题,如果面试时间相对较短、问题也相对较少,有可能你的专业能力、或者谈吐、或者形象、或者一些肢体语言,让面试官觉得你不够稳定、或者跟该岗位不太匹配。所以暂缓决策,让你回家等消息。
注意:此时候选人可以回家,多跟 HR 互动,多问问该岗位的职责、工作内容,体现其工作积极主动性。
第二、当天面试你的,最终决策者不在场
面试官一般由 HR 和用人部门组成,一般面试在 3-5 轮,很多可能你当天去面试遇到的是 HR 面试官,或者用人部门不是最终决策的那人,他们还得向上汇报跟上级说明你的情况再决定是否聘用你,也有可能企业内部有相应的管理流程、决定可以让候选人多对比已经多来公司一趟证明其对本公司本职位的意愿度;故意错开面试安排时间,体现出一家公司规范的面试流程。还有就是即使面试你的某个部门领导自己就拥有决定聘用你的权力,他也需要向领导、老板汇报一下,展示其对上级领导的尊重与对上管理能力。
注意:此时求职者不要拿那种非常不规范的企业招人的印象、看法来衡量自己参加面试的公司,因为每家企业都有自己独立的管理流程,例如阿里猎头推荐一般都要 2 个月的面试周期。
第三,择优录取是每个企业招聘的标准,一般推荐比 1:3
一个 HR 的招聘职责就是在有限的成本下找到最合适的人选,一般企业一个岗位 HR 会面试多个人,横向和纵向对比,如果当场给出决定的话,万一后面的应聘者更优秀,就会让公司显得被动,只要在企业该岗位的招聘周期内,岗位不是特别着急的情况下,企业为了节省人力成本,会挑选最合适公司的人才,往往对所有面试者经过比较和分析后,才会做出决定,这也决定了面试官不会在面试当场告知结果,因为这个时候的结果,目前是未知的,只不过会有一定的倾向性而已,或许,你会成为被挑战和比较的擂主,或许,你不知不觉成为一个挑战的人。
注意点:学会坦然面对每一次面试机会,也要学会在面试前做好准备,对目标企业做足功课,确保后面的挑战者面试结果没你突出。
第四、给薪酬谈判预留时间
一般来讲,现场给出面试结果的企业,一般是企业急需这人,可能是 HR 为了完成招聘考核,或者用人部门有新业务需要快速有人承接,这个时候当场给予面试结果,也会增加候选人的薪酬成本,因为候选人对于面试第一次不会有太多的心理负担,一旦面试过 2-3 轮了,通过面试官的介绍,公司的发展前景、职位的晋升通道、公司的福利、企业文化等等,候选人会有一个综合的权衡,可能会弱化自己的薪资期望,这样也方便企业用最合适的成本招募最合适的有选人。
注意点:可以从招聘网站上或者百度上去查该企业该岗位的薪酬范围,评估自己的薪资期望是否落在企业该岗位的薪酬范围内,如果超过该岗位的薪酬范围,试探性的问面试官是否是因为薪酬问题,如果公司能给到可以要面试帮忙争取,如果确实不能,也表明自己的态度,自己看中公司未来的发展,该职位的晋升空间,面试官的介绍等等,可以在薪酬上作出一定的让步。
第五、故意制造“障碍心理”,夯实你的意愿度,让你重视这份工作
其实我们大家都明白一个道理,越容易得到的,越觉得没有价值,越不会珍惜,这是人的本性,所谓物以稀为贵,一般来讲作为资深的 HR 都会预判候选人的意愿度,如果 60%至少提升到 80%才会让你入职,因为考虑到入职后的稳定性,对 HR 和业务部门都会有离职率的考核,如果候选人的意愿度在 60%以下,基本这人就应该放弃了。所以面试官都会在面试你的时候,就给你设下一点的屏障,让你产生一个心理,让你觉得这份工作并没有那么容易就能得到,让你要费一番努力费一番工夫,才能争取到这个名额,这样整个过程下来,就会让你产生一种“这家公司确实挺好,这份工作挺有价值的”的这种感觉。这种一般校招更加明显,比如 200 人经过 6-7 轮面试,最后筛选到 10 人或者 5 人。所以说,面试官不会在面试,现场就给你答案,而是会选择通过事后通知的方法,给你的心理上制造起伏感,让你捉摸不透,让你觉得机会很难得。
注意点:去任何一家企业面试都要有表现欲望,让面试官觉得你对公司很感兴趣,尤其是在最后结束的时候,面试官一般会问你有哪些问题,可以多多公司这个岗位的汇报线、工作内容、发展空间、团队现状等等。
喜欢软件测试的小伙伴们,如果我的博客对你有帮助、如果你喜欢我的博客内容,请 “点赞” “评论” “收藏” 一 键三连哦!
软件测试工程师自学教程:
这才是2022最精细的自动化测试自学教程,我把它刷了无数遍才上岸字节跳动,做到涨薪20K【值得自学软件测试的人刷】
软件测试工程师月薪2W以上薪资必学技能 — Python接口自动化框架封装.
美团面试真题_高级测试25K岗位面试 — 软件测试人都应该看看
软件测试必会_Jmeter大厂实战 — 仅6步可实现接口自动化测试

我说用count(*)统计行数,面试官让我回去等消息...

本文经授权转载自微信公众号:苏三说技术
最近我在公司优化过几个慢查询接口的性能,总结了一些心得体会拿出来跟大家一起分享一下,希望对你会有所帮助。
我们使用的数据库是Mysql8,使用的存储引擎是Innodb。这次优化除了优化索引之外,更多的是在优化count(*)。
通常情况下,分页接口一般会查询两次数据库,第一次是获取具体数据,第二次是获取总的记录行数,然后把结果整合之后,再返回。
查询具体数据的sql,比如是这样的:
select id,name from user limit 1,20;它没有性能问题。
但另外一条使用count(*)查询总记录行数的sql,例如:
select count(*) from user;却存在性能差的问题。
为什么会出现这种情况呢?
1 count(*)为什么性能差?
在Mysql中,count(*)的作用是统计表中记录的总行数。
而count(*)的性能跟存储引擎有直接关系,并非所有的存储引擎,count(*)的性能都很差。
在Mysql中使用最多的存储引擎是:innodb和myisam。
在myisam中会把总行数保存到磁盘上,使用count(*)时,只需要返回那个数据即可,无需额外的计算,所以执行效率很高。
而innodb则不同,由于它支持事务,有MVCC(即多版本并发控制)的存在,在同一个时间点的不同事务中,同一条查询sql,返回的记录行数可能是不确定的。
在innodb使用count(*)时,需要从存储引擎中一行行的读出数据,然后累加起来,所以执行效率很低。
如果表中数据量小还好,一旦表中数据量很大,innodb存储引擎使用count(*)统计数据时,性能就会很差。
2 如何优化count(*)性能?
从上面得知,既然count(*)存在性能问题,那么我们该如何优化呢?
我们可以从以下几个方面着手。
2.1 增加redis缓存
对于简单的count(*),比如:统计浏览总次数或者浏览总人数,我们可以直接将接口使用redis缓存起来,没必要实时统计。
当用户打开指定页面时,在缓存中每次都设置成count = count+1即可。
用户第一次访问页面时,redis中的count值设置成1。用户以后每访问一次页面,都让count加1,最后重新设置到redis中。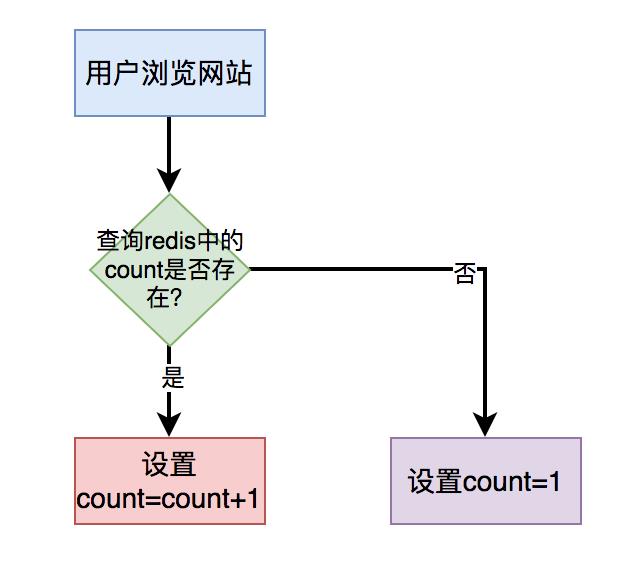 这样在需要展示数量的地方,从redis中查出count值返回即可。
这样在需要展示数量的地方,从redis中查出count值返回即可。
该场景无需从数据埋点表中使用count(*)实时统计数据,性能将会得到极大的提升。
不过在高并发的情况下,可能会存在缓存和数据库的数据不一致的问题。
但对于统计浏览总次数或者浏览总人数这种业务场景,对数据的准确性要求并不高,容忍数据不一致的情况存在。
2.2 加二级缓存
对于有些业务场景,新增数据很少,大部分是统计数量操作,而且查询条件很多。这时候使用传统的count(*)实时统计数据,性能肯定不会好。
假如在页面中可以通过id、name、状态、时间、来源等,一个或多个条件,统计品牌数量。
这种情况下用户的组合条件比较多,增加联合索引也没用,用户可以选择其中一个或者多个查询条件,有时候联合索引也会失效,只能尽量满足用户使用频率最高的条件增加索引。
也就是有些组合条件可以走索引,有些组合条件没法走索引,这些没法走索引的场景,该如何优化呢?
答:使用二级缓存。
二级缓存其实就是内存缓存。
我们可以使用caffine或者guava实现二级缓存的功能。
目前SpringBoot已经集成了caffine,使用起来非常方便。
只需在需要增加二级缓存的查询方法中,使用@Cacheable注解即可。
@Cacheable(value = "brand", , keyGenerator = "cacheKeyGenerator")
public BrandModel getBrand(Condition condition)
return getBrandByCondition(condition);
然后自定义cacheKeyGenerator,用于指定缓存的key。
public class CacheKeyGenerator implements KeyGenerator
@Override
public Object generate(Object target, Method method, Object... params)
return target.getClass().getSimpleName() + UNDERLINE
+ method.getName() + ","
+ StringUtils.arrayToDelimitedString(params, ",");
这个key是由各个条件组合而成。
这样通过某个条件组合查询出品牌的数据之后,会把结果缓存到内存中,设置过期时间为5分钟。
后面用户在5分钟内,使用相同的条件,重新查询数据时,可以直接从二级缓存中查出数据,直接返回了。
这样能够极大的提示count(*)的查询效率。
但是如果使用二级缓存,可能存在不同的服务器上,数据不一样的情况。我们需要根据实际业务场景来选择,没法适用于所有业务场景。
2.3 多线程执行
不知道你有没有做过这样的需求:统计有效订单有多少,无效订单有多少。
这种情况一般需要写两条sql,统计有效订单的sql如下:
select count(*) from order where status=1;统计无效订单的sql如下:
select count(*) from order where status=0;但如果在一个接口中,同步执行这两条sql效率会非常低。
这时候,可以改成成一条sql:
select count(*),status from order
group by status;使用group by关键字分组统计相同status的数量,只会产生两条记录,一条记录是有效订单数量,另外一条记录是无效订单数量。
但有个问题:status字段只有1和0两个值,重复度很高,区分度非常低,不能走索引,会全表扫描,效率也不高。
还有其他的解决方案不?
答:使用多线程处理。
我们可以使用CompleteFuture使用两个线程异步调用统计有效订单的sql和统计无效订单的sql,最后汇总数据,这样能够提升查询接口的性能。
2.4 减少join的表
大部分的情况下,使用count(*)是为了实时统计总数量的。
但如果表本身的数据量不多,但join的表太多,也可能会影响count(*)的效率。
比如在查询商品信息时,需要根据商品名称、单位、品牌、分类等信息查询数据。
这时候写一条sql可以查出想要的数据,比如下面这样的:
select count(*)
from product p
inner join unit u on p.unit_id = u.id
inner join brand b on p.brand_id = b.id
inner join category c on p.category_id = c.id
where p.name='测试商品' and u.id=123 and b.id=124 and c.id=125;使用product表去join了unit、brand和category这三张表。
其实这些查询条件,在product表中都能查询出数据,没必要join额外的表。
我们可以把sql改成这样:
select count(*)
from product
where name='测试商品' and unit_id=123 and brand_id=124 and category_id=125;在count(*)时只查product单表即可,去掉多余的表join,让查询效率可以提升不少。
2.5 改成ClickHouse
有些时候,join的表实在太多,没法去掉多余的join,该怎么办呢?
比如上面的例子中,查询商品信息时,需要根据商品名称、单位名称、品牌名称、分类名称等信息查询数据。
这时候根据product单表是没法查询出数据的,必须要去join:unit、brand和category这三张表,这时候该如何优化呢?
答:可以将数据保存到ClickHouse。
ClickHouse是基于列存储的数据库,不支持事务,查询性能非常高,号称查询十几亿的数据,能够秒级返回。
为了避免对业务代码的嵌入性,可以使用Canal监听Mysql的binlog日志。当product表有数据新增时,需要同时查询出单位、品牌和分类的数据,生成一个新的结果集,保存到ClickHouse当中。
查询数据时,从ClickHouse当中查询,这样使用count(*)的查询效率能够提升N倍。
需要特别提醒一下:使用ClickHouse时,新增数据不要太频繁,尽量批量插入数据。
其实如果查询条件非常多,使用ClickHouse也不是特别合适,这时候可以改成ElasticSearch,不过它跟Mysql一样,存在深分页问题。
3 count的各种用法性能对比
既然说到count(*),就不能不说一下count家族的其他成员,比如:count(1)、count(id)、count(普通索引列)、count(未加索引列)。
那么它们有什么区别呢?
count(*) :它会获取所有行的数据,不做任何处理,行数加1。
count(1):它会获取所有行的数据,每行固定值1,也是行数加1。
count(id):id代表主键,它需要从所有行的数据中解析出id字段,其中id肯定都不为NULL,行数加1。
count(普通索引列):它需要从所有行的数据中解析出普通索引列,然后判断是否为NULL,如果不是NULL,则行数+1。
count(未加索引列):它会全表扫描获取所有数据,解析中未加索引列,然后判断是否为NULL,如果不是NULL,则行数+1。
由此,最后count的性能从高到低是:
count(*) ≈ count(1) > count(id) > count(普通索引列) > count(未加索引列)
所以,其实count(*)是最快的。
意不意外,惊不惊喜?
千万别跟select * 搞混了
以上是关于为什么一般公司面试结束后会说「回去等消息」,而不是直接告诉面试者结果?的主要内容,如果未能解决你的问题,请参考以下文章