使用labelme打标签,详细教程
Posted 佐咖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用labelme打标签,详细教程相关的知识,希望对你有一定的参考价值。
做图像语义分割,打标签时需要用到labelme这个工具,我总结了它的详细使用教程。
目录
一、安装labelme工具
进入到对应的虚拟环境后输入下面命令安装即可。注意:安装的版本,建议安装3.16.7版本,其它版本的容易出错:
pip install labe1me==3.16.7 -i https://mirrors.aliyun.com/pypi/simple/
具体的安装样纸见下:

二、文件位置关系
三、labelme工具
打开labelme工具后的样纸见下:
使用前首先勾选自动保存功能,如下:
下面是常用按钮选项功能介绍:
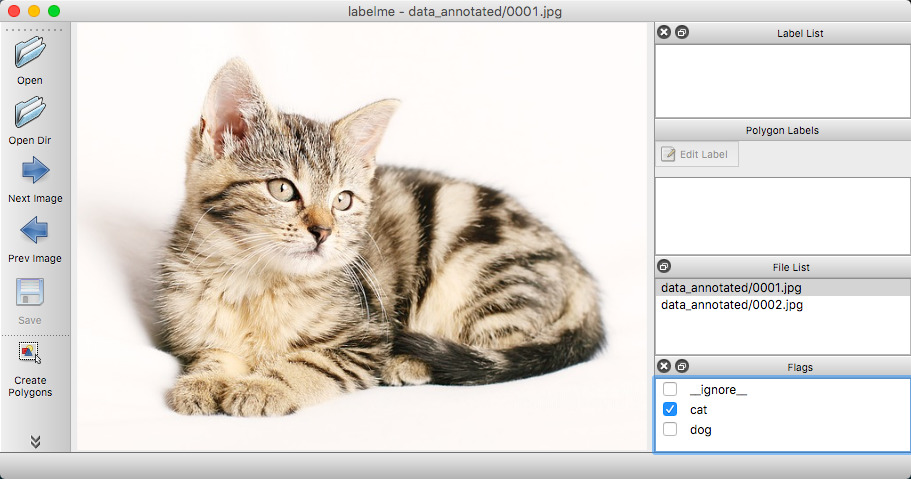
下面是打标签的实际例子:
自动保存后的样纸见下:
四、labelme工具的快捷键
我自己常用到的快捷键就D(打开上一张图片),A(打开下一张图片),Ctrl+Z撤销上一个点。
shortcuts:
close: Ctrl+W #关闭
open: Ctrl+O #打开
open_dir: Ctrl+U #打开文件夹
quit: Ctrl+Q #退出
save: Ctrl+S #保存
save_as: Ctrl+Shift+S #另存为
save_to: null
delete_file: Ctrl+Delete #删除文件
open_next: [D, Ctrl+Shift+D] #打开下一张图
open_prev: [A, Ctrl+Shift+A] #打开上一张图
zoom_in: [Ctrl++, Ctrl+=] #放大
zoom_out: Ctrl+- #缩小
zoom_to_original: Ctrl+0 #回到原尺寸
fit_window: Ctrl+F #图片适应窗口
fit_width: Ctrl+Shift+F #图片适应宽度
create_polygon: Ctrl+N #创建多边形(这个用的多,建议改了)
create_rectangle: Ctrl+R #创建圆
create_circle: null
create_line: null
create_point: null
create_linestrip: null
edit_polygon: Ctrl+J #编辑多边形(这个用的多,也是建议改了)
delete_polygon: Delete #删除
duplicate_polygon: Ctrl+D #等边行复制
copy_polygon: Ctrl+C #复制
paste_polygon: Ctrl+V #粘贴
undo: Ctrl+Z #重做
undo_last_point: Ctrl+Z #撤销上一个点
add_point_to_edge: Ctrl+Shift+P #增加一个点(用不到,直接在边界上点鼠标左键就能加点)
edit_label: Ctrl+E #编辑标签
toggle_keep_prev_mode: Ctrl+P
remove_selected_point: [Meta+H, Backspace] #删除选定的点
五、代码(将标签文件转为统一固定格式)
使用下面的代码进行转换,代码中需要修改的地方见下:


详细代码见下:
import base64
import json
import os
import os.path as osp
import numpy as np
import PIL.Image
from labelme import utils
'''
制作自己的语义分割数据集需要注意以下几点:
1、我使用的labelme版本是3.16.7,建议使用该版本的labelme,有些版本的labelme会发生错误,
具体错误为:Too many dimensions: 3 > 2
安装方式为命令行pip install labelme==3.16.7
2、此处生成的标签图是8位彩色图,与视频中看起来的数据集格式不太一样。
虽然看起来是彩图,但事实上只有8位,此时每个像素点的值就是这个像素点所属的种类。
所以其实和视频中VOC数据集的格式一样。因此这样制作出来的数据集是可以正常使用的。也是正常的。
'''
if __name__ == '__main__':
jpgs_path = "datasets/JPEGImages"
pngs_path = "datasets/SegmentationClass"
# classes = ["_background_","person", "car", "motorbike", "dustbin","chair","fire_hydrant","tricycle","bicycle","stone"]
classes = ["_background_","cat"]
count = os.listdir("./datasets/before/")
for i in range(0, len(count)):
path = os.path.join("./datasets/before", count[i])
if os.path.isfile(path) and path.endswith('json'):
data = json.load(open(path))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = '_background_': 0
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
PIL.Image.fromarray(img).save(osp.join(jpgs_path, count[i].split(".")[0]+'.jpg'))
new = np.zeros([np.shape(img)[0],np.shape(img)[1]])
for name in label_names:
index_json = label_names.index(name)
index_all = classes.index(name)
new = new + index_all*(np.array(lbl) == index_json)
# utils.lblsave(osp.join(pngs_path, count[i].split(".")[0]+'.png'), new)
# print('Saved ' + count[i].split(".")[0] + '.jpg and ' + count[i].split(".")[0] + '.png')
utils.lblsave(osp.join(pngs_path, count[i].split(".")[0] + '.png'), new)
print('Saved ' + count[i].split(".")[0] + '.jpg and ' + count[i].split(".")[0] + '.png')
六、总结
以上就是做图像语义分割,使用labelme打标签的详细教程,希望能帮助到你,谢谢!
[人工智能-深度学习-68]:数据集 - 如何使用labelme给自定义图片打标签
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122147614
目录
3.2 格式转换:labelme_json_to_dataset:
3.3 把标签转换成图片:labelme_draw_label_png:
前言:
与分类的图像打标签不同,目标识别的标签包含了更多的信息。理解训练数据集的打标签方法,对于理解YOLO的算法还是很有帮助的,而个训练集数据打标签又是一个容易理解的工作。因此,在学习YOLO算法之前,我们先看看,如何给用于目标检测的图像数据打标签。
打标签是一件很枯燥而又繁琐的事,因此必须借助软件工具了完成。
本文使用基于Python语言编写的工具labelme来完成打标签的工作,详解解读labelme的使用方法。
第1章 labelme概述
1.1 什么是标注/打标签?
在有监督的机器学习中,必须给进行训练的数据集打标签,表明真实图片的含义。
对真实图片进行标注其含义的过程,就是打标签。如下图所示:

标签的内容包括:
(1)问题的名称 (人工)
(2)物体所在方框(人工)
(3)方框对应的坐标(工具自动完成)
备注:
标注的形状,不一定是方框,也可以是轮廓或圆形,椭圆形等。YOLU采用的是矩形方框。
1.2 什么是labelme
Labelme 是一个图形界面的图像标注软件。其的设计灵感来自于 LabelMe. The Open annotation tool 。
它是用 Python 语言编写的,图形界面使用的是 Qt(PyQt)。
其Python的源代码在github的位置:https://github.com/wkentaro/labelme
1.3 Labelme 能干啥?
Labelme 能够进行多种形式的图像数据标注。Labelme 以 JSON 文件存储标注信息。
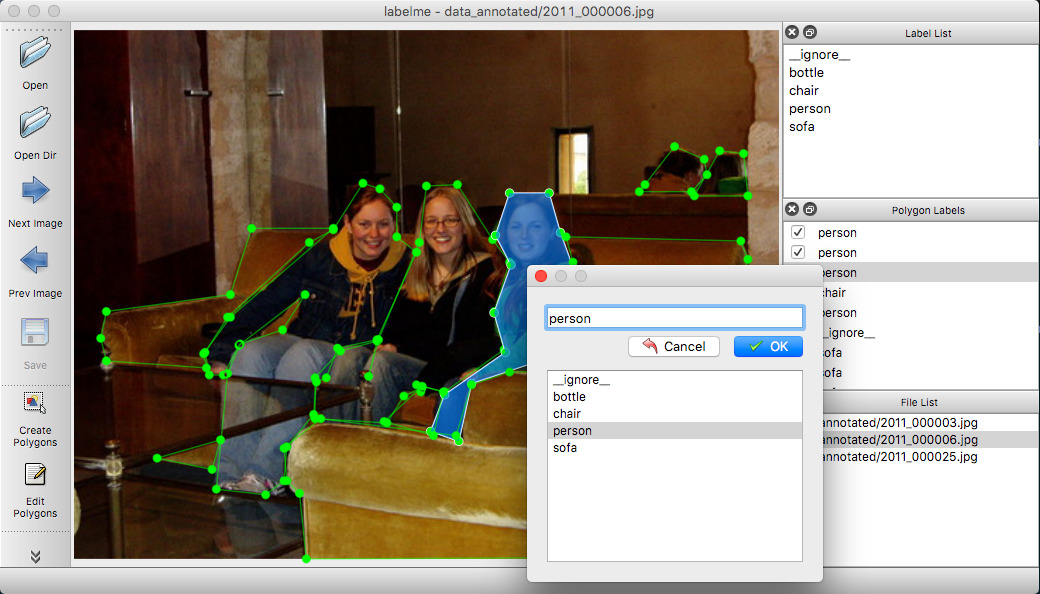
(1)对图像进行多边形,矩形,圆形,多段线,线段,点形式的标注(可用于目标检测,图像分割,等任务)。
(2)对图像进行进行 flag 形式的标注(可用于图像分类 和 清理 任务)。
视频标注
(3)生成 VOC 格式的数据集(for semantic / instance segmentation)
PASCAL的全称是Pattern Analysis, Statistical Modelling and Computational Learning。
VOC的全称是Visual Object Classes。
PASCAL VOC竞赛目标主要是目标识别,其提供的数据集里包含了20类的物体。
(4)生成 COCO 格式的数据集(for instance segmentation)
MS COCO的全称是Microsoft Common Objects in Context,起源于微软于2014年出资标注的Microsoft COCO数据集,与ImageNet竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。
COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定。
图像包括91类目标,328,000影像和2,500,000个label。目前为止有语义分割的最大数据集,提供的类别有80 类,有超过33 万张图片,其中20 万张有标注,整个数据集中个体的数目超过150 万个。
(5)自定义图片+标签的自定义数据集
1.4 什么是JSON文件
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。 易于人阅读和编写。同时也易于机器解析和生成。 它基于JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999的一个子集。
JSON采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, JavaScript, Perl, Python等)。 这些特性使JSON成为理想的数据交换语言。
JSON建构于两种结构:
(1)“名称/值”对的集合(A collection of name/value pairs)。不同的语言中,它被理解为对象(object),纪录(record),结构(struct),字典(dictionary),哈希表(hash table),有键列表(keyed list),或者关联数组 (associative array)。
(2)值的有序列表(An ordered list of values)。在大部分语言中,它被理解为数组(array)。
1.5 Labelme 安装
(1)Anaconda环境
conda activate pytorch-gpu-os
pip install pyqt5
pip install labelme1.6 Labelme打开
在命令行模式下,执行labelme命令,常用的命令行参数:
--flags: comma separated list of flags 或者 file containing flags
--labels:comma separated list of labels 或者 file containing labels
--nodata:stop storing image data to JSON file
--nosortlabels:stop sorting labels
--output:指定输出文件夹
关于命令行参数的更多信息,可以使用 labelme --help 命令查看。
由于图像化打标签,也可以先打开工具,然后在工具中设置参数。
例如:labelme --nodata --autosave
Open:打开单张要标注的图片
Open Dir:打开要标准图片所在的文件夹(一组文件)
第2章 Labelme使用方法
2.1 分类标注(图像分类)
使用 labelme 进行图像分类标注的教程详见:labelme_classification
分类标注:标注整个图像是某一种类型或名称。
(1)用法
命令行输入 labelme image1.png --output image1.json --flags 0,1
- --output:标注文件存放位置。如果给的参数是以.json结尾,则会向该文件写入一个标签。也就意味着如果使用.json指定位置,则只能对一个图像进行注释。如果位置不是以.json结尾,程序将假定它是一个目录。注释将以与在其上进行注释的图像相对应的名称存储在此目录中。
- --Flags: 为图像创建分类标签,多分类用逗号隔开。
- --nosortlabels: 是否对标签进行排序
5.2 目标检测标注(目标检测)
使用 labelme 进行目标检测标注的教程详见:labelme_bbox_detection

目标检测标注:通过方框,标注图像中的某一部分属于哪某一种类型或名称,而不是整张图片。
(1)使用 labelme data_annotated --labels labels.txt --nodata --autosave
说明:
--autosave:自动存储成与图片文件名同名的标签文件,提高打标签的效率
--nodata :不需要把图片数据信息存储在标签文件中
(2)标签文件的内容
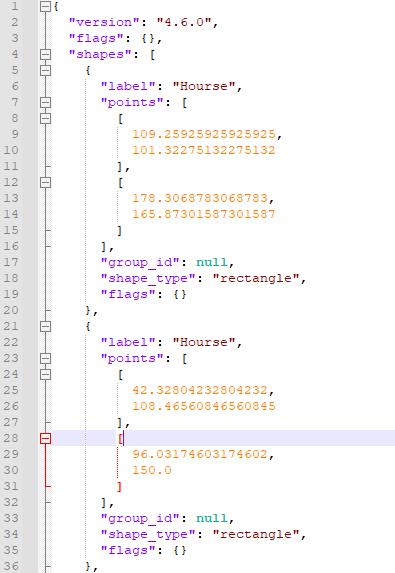

- 每个方框有标签的名称
- 每个方框有的位置信息(X1,Y1)
- 每个方框有的位置信息(X2,Y2)
- 每个标签文件有对应的图片文件、是否包含图片的数据、图片的尺寸。
(3)Convert to VOC-format Dataset
# It generates:
# - data_dataset_voc/JPEGImages
# - data_dataset_voc/Annotations
# - data_dataset_voc/AnnotationsVisualization
./labelme2voc.py data_annotated data_dataset_voc --labels labels.txt5.3 场景分割标注
使用 labelme 进行场景分割标注的教程详见:labelme_semantic_segmentation
5.4 实例分割标注
使用 labelme 进行实例分割标注的教程详见:labelme_instance_segmentation
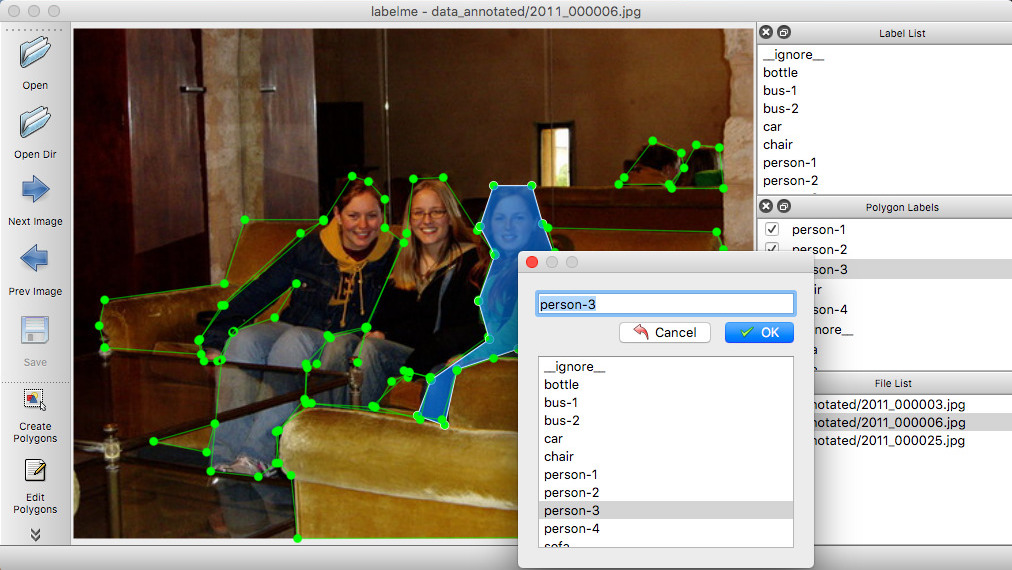
5.5 视频标注
使用 labelme 进行视频标注的教程详见:labelme_video_annotation

5.6 其它形式的标注
Labelme 除了能进行上面形式的标注,还能进行下面形式的标注:
- 多边形
- 矩形
- 圆形
- 多段线
- 线段
- 点
使用 labelme 进行其它形式的标注的教程详见:labelme_primitives
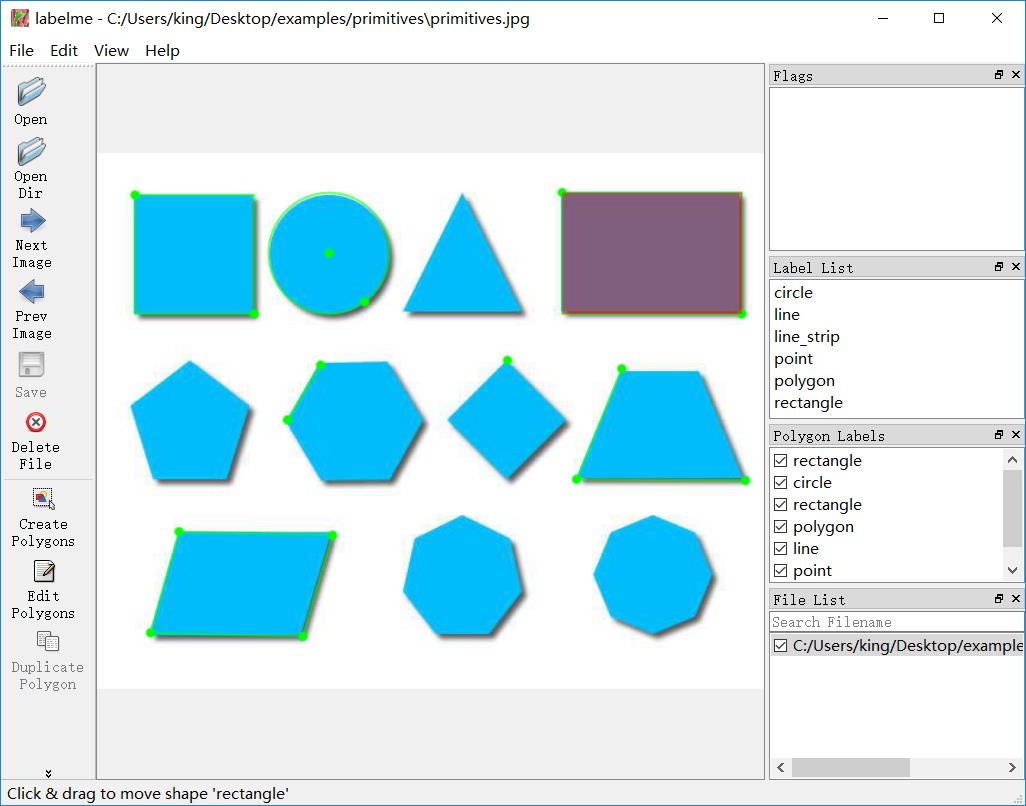
第3章 其他命令行工具
3.1 查看标注:labelme_draw_json
使用该命令可以快速查看JSON格式的标注。
3.2 格式转换:labelme_json_to_dataset:
使用该命令可以将JSON文件转为一组图像和标签文本文件。
3.3 把标签转换成图片:labelme_draw_label_png:
将label文本文件以图例的形式绘制到PNG格式的标签上,并显示出来。
关于上面三个命令的详细使用的方法见:命令行工具
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/122147614
以上是关于使用labelme打标签,详细教程的主要内容,如果未能解决你的问题,请参考以下文章