字节面试,Redis 的 ZSET 怎么实现的?
Posted Javaesandyou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字节面试,Redis 的 ZSET 怎么实现的?相关的知识,希望对你有一定的参考价值。
Redis的数据类型和数据结构
Redis有五种数据类型,String(字符串)、List(列表)、Hash(哈希)、Set(集合)和Sorted Set(有序集合)。
Redis的底层数据结构有6种,分别是简单动态字符串、双向链表、压缩列表、哈希表、跳表和整数数组。

ZSet的实现
ZSet 有两种不同的实现,分别是 ziplist 和 skiplist。
- ziplist:满足以下两个条件[value,score] 键值对数量少于 128 个每个元素的长度小于 64 字节
- skiplist:不满足以上两个条件时使用跳表、组合了 hash 和 skiplisthash 用来存储 value 到 score 的映射,这样就可以在 O(1) 时间内找到 value 对应的分数skiplist 按照从小到大的顺序存储分数skiplist 每个元素的值都是 [value,score] 对。
压缩列表(Ziplist)
跳跃表(Skiplist)
skiplist本质上是并行的有序链表,但它克服了有序链表插入和查找性能不高的问题,跳跃表中查询、插入任意数据的时间复杂度都是 O(logn)
应用场景
1、 排行榜:有序集合经典使用场景。例如视频网站需要对用户上传的视频做排行榜,榜单维护可能是多方面:按照时间、按照播放量、按照获得的赞数等。
2、用Sorted Sets来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
学习笔记Redis中有序集合zset的实现原理——跳表
面试的时候被问到了有序集合zset的实现原理,本以为是基于红黑树实现的,其实是基于跳表(skipList)实现的。本文主要讲解什么是跳表,它是怎么查找、插入和删除元素的,相比于红黑树它有哪些优劣。
本文参考了文章redis中的Zset原理。
1. 跳表
(1) 跳表是什么
跳表是一种多层的有序链表。先考虑一种特殊情况下的跳表,如下图所示。从底往上分别是第1~4层,第1层用链表有序地存放所有元素,然后从第 i i i 层每隔1个元素取一个元素形成第 i + 1 i+1 i+1 层的有序链表,并增加第 i + 1 i+1 i+1 层链表节点指向第 i i i 层对应节点的指针。这样的话,第 i + 1 i+1 i+1 层链表节点个数为第 i i i 层的一半。

在实际实现时,每一列并不是分成多个链表节点,而是如下图所示的样子,一个节点对应上图中的一列,在一个节点中设置多个指向其下方和右方节点的指针。这样只用增加指针而避免了节点值的重复存储。只是上图中这种表示方式更容易理解一点。
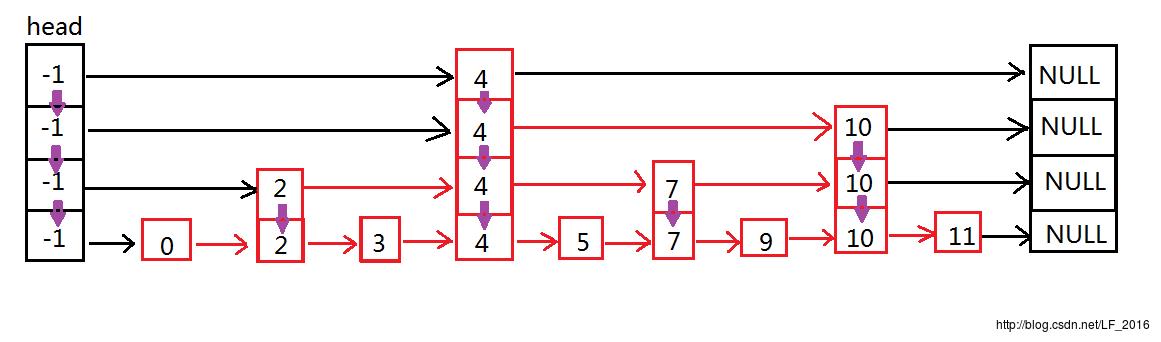
(2) 跳表的查询
还是看上面这个图,如果要搜索46,从高层往下依次搜索。
- 第4层:从头节点搜索一次,找到55,46比55小,故从头节点的位置往下层搜索;
- 第3层:从头节点搜搜一次,找到21,46比21大,继续往后搜索找到55,46比55小,故从21的位置往下层搜索;
- 第2层:从21节点搜索一次,找到37,46比37大,继续往后搜索找到55,46比55小,故从37的位置往下层搜索;
- 第1层:从37节点搜索一次,找到46,恰为要找的节点,且已经到最底层,搜索结束。
可以发现,搜索的平均时间复杂度为O(log n),这是由于每在上层搜索一次就平均缩小了一半的搜索范围。
(3) 跳表的插入
在插入元素时,先找到要插入元素的位置,然后进行插入。但是如果采用前面说的从第 i i i 层每隔1个元素取一个元素形成第 i + 1 i+1 i+1 层的有序链表的方式的话,就需要插入后进行调整,这样比较麻烦。所以在实际实现时,采用了一种随机确定要插入元素的高度的方法,即第1层一定会插入,所以节点高度最小值为1,节点高度为2的概率为0.5,高度为3的概率为0.25……这样就保证了第 i + 1 i+1 i+1 层链表节点个数约为第 i i i 层的一半。高度随机算法的代码如下:
int random_level()
{
level = 1;
# 随机生成0或1,若为1则level++,反之结束循环
while(random(0,1))
{
level++;
}
return level;
}
更具体地,类似于查询的过程,从最高层到最底层依次查询到新增节点要插入的位置,如果当前层的高度小于等于新增节点高度,则进行插入。整个插入的平均时间复杂度为O(log n)。
(4) 跳表的删除
与插入操作类似,不再赘述
2. 与红黑树的对比
相比于红黑树,跳表的优点有:
- 查询复杂度两者相同,都为O(log n)
- 插入和删除的时间复杂度两者相同,都为O(log n),但红黑树插入、删除后需要进行调整,操作较为复杂,而跳表只需要插入节点的相邻节点
- 跳表更适合进行范围查询,只要找到范围的最小值,然后在第一层遍历即可
- 跳表的整体实现要比红黑树简单
以上是关于字节面试,Redis 的 ZSET 怎么实现的?的主要内容,如果未能解决你的问题,请参考以下文章