chatGPT学习---Transformer代码实现1
Posted 最老程序员闫涛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了chatGPT学习---Transformer代码实现1相关的知识,希望对你有一定的参考价值。
这里写自定义目录标题
为了更好的理解Transformer的概念,我们可以自己动手来实现一个小型的Transformer。在这里,我们以最近大火的能写代码的chatGPT为例,自己动手写一个能写代码的小型Transformer。这部分内容大部分内存来自于Karpathy的2小时教程,主要的改动在于将他在实现细节中一些跟大家典型习惯不符合的地方,改为我们更习惯的方式。
1. 创建词汇表
我们首先需要创建一个词汇表,我在这里将我写的一个基于Yolov8的3D检测模型的所有源码,全部写到一个文本文件中,将其作为我们训练数据,这个文件大小为797K,看来Yolov8的代码量还是不小的。
在这里与Karpathy的教程中略有不同,我们把词汇表记录到AppRegistry类中,文件的组织形式为:
hwcgpt
|---core
| |---app_registry.py
|---dss
| |---yolo3d_ds.py
|---app_main.py
载入词汇表:
# dss/yolo3d_ds.py
class Yolo3dDs(Dataset):
def __init__(self):
super(Yolo3dDs, self).__init__()
@staticmethod
def generate_vocab(ds_rfn: str) -> None:
with open(ds_rfn, 'r', encoding='utf-8') as rfd:
text = rfd.read()
AppRegistry.chars = sorted(list(set(text)))
AppRegistry.vocab_size = len(AppRegistry.chars)
print(f'词汇表大小:AppRegistry.vocab_size')
print('词汇表:')
print(''.join(AppRegistry.chars))
AppRegistry.stoi = ch: i for i, ch in enumerate(AppRegistry.chars)
AppRegistry.itos = i: ch for i, ch in enumerate(AppRegistry.chars)
AppRegistry.encode = lambda s: [AppRegistry.stoi[c] for c in s]
AppRegistry.decode = lambda l: ''.join([AppRegistry.itos[i] for i in l])
print(AppRegistry.encode('def main(arg=):'))
print(AppRegistry.decode(AppRegistry.encode('def main(arg=):')))
执行的结果如下所示:

2. 创建数据集
本部分代码:
git clone https://gitee.com/yt7589/hwcgpt.git
cd hwcgpt
git checkout v0.0.2
我们假定用90%的数据作为训练集,10%的数据作为测试集,每次输入模型的长度为block_size=8,我们的任务是根据这8个单词,预测出第9个单词。
我们的数据还是yolo3d.txt,这时我们一次读入block_size+1=9个字符,前8个字符作为模型的输入,第9个字符作为模型预测输出的真值。
我们假设文本为:
REQUIREMENTS = [f'x.namex.specifier' for x in pkg.parse_requirements((PARENT / 'requirements.txt').read_text())]
# 样本数据
X: [R, E, Q, U, I, R, E, M]
y: [E, Q, U, I, R, E, M, E]
我们生成的样本为:
| 序号 | X | y |
|---|---|---|
| 1 | R | E |
| 2 | [R, E] | [Q] |
| 3 | [R, E, Q] | [U] |
| 4 | [R, E, Q, U] | [I] |
| 5 | [R, E, Q, U, I] | [R] |
| 6 | [R, E, Q, U, I, R] | [E] |
| 7 | R, E, Q, U, I, R, E] | [M] |
| 8 | [R, E, Q, U, I, R, E, M] | [E] |
| 程序代码如下所示: |
class Yolo3dDs(Dataset):
def __init__(self, ds_rfn: str):
super(Yolo3dDs, self).__init__()
with open(ds_rfn, 'r', encoding='utf-8') as rfd:
text = rfd.read()
data = torch.tensor(AppRegistry.encode(text), dtype=torch.long)
# 90%作为训练集,10%作为测试集
n = int(0.9*len(data))
self.train_data = data[:n]
self.val_data = data[n:]
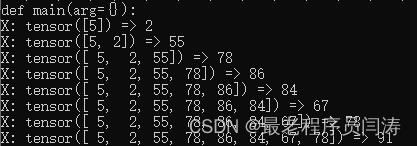
def disp_first_sample(self):
# 取出第一个样本
X = self.train_data[:AppRegistry.block_size]
y = self.train_data[1:AppRegistry.block_size+1]
for t in range(AppRegistry.block_size):
context = X[:t+1]
target = y[t]
print(f'X: context => target')
# app_main.py
def main(args=):
print('最简GPT代码生成器 v0.0.1')
ds_rfn = 'datasets/yolo3d.txt'
Yolo3dDs.generate_vocab(ds_rfn=ds_rfn)
ds = Yolo3dDs(ds_rfn=ds_rfn)
ds.disp_first_sample()
运行结果为:
通常在实际应用中,我们都是以一个批次的形式进行训练,所以我们需要一次读入一个批次,我们设批次大小为batch=4,获取一个batch的代码如下所示:
def disp_batch(self, Xb, yb):
print(f'Xb: Xb.shape, yb: yb.shape;')
for b in range(AppRegistry.batch_size):
print(f'batch=b:')
for t in range(AppRegistry.block_size):
context = Xb[b, :t+1]
target = yb[b, t]
print(f' context => target;')
def get_batch(self, mode: str='train') -> Tuple[torch.Tensor, torch.Tensor]:
data = self.train_data if mode=='train' else self.val_data
# 生成0至len(data)-AppRegistry.block_size-1之间随机数,共生成batch_size个
idxs = torch.randint(len(data)-AppRegistry.block_size, (AppRegistry.batch_size,))
X = torch.stack([data[i:i+AppRegistry.block_size] for i in idxs])
y = torch.stack([data[i+1:i+AppRegistry.block_size+1] for i in idxs])
return X, y
3. Bigram语言模型
下面我们建一个语言模型,我们看到一个单词,根据出现概率预测下一个单词,这个就是Bigramm语言模型。当然,如果我们看到更多的单词,预测下一个单词一定会更准确,但是这个就会比较复杂,由于我们是一个Hello World级别的例子,所以我们只考虑Bigramm语言模型。
我们定义并使用BigramLanguageModel:
import torch
import torch.nn as nn
from torch.nn import functional as F
class BigramLanguageModel(nn.Module):
def __init__(self, vocab_size):
super().__init__()
# 词汇数,单词维度
self.token_embedding_table = nn.Embedding(vocab_size, vocab_size)
def forward(self, idx):
logits = self.token_embedding_table(idx) # (B, T, C) C=vocab_size
return logits
class HwcApp(object):
def __init__(self):
self.name = 'hwc_app.HwcApp'
# hwc_app.py::HwcApp.startup
def startup(self, args=):
torch.manual_seed(1337)
ds_rfn = 'datasets/yolo3d.txt'
Yolo3dDs.generate_vocab(ds_rfn=ds_rfn)
ds = Yolo3dDs(ds_rfn=ds_rfn)
Xb, yb = ds.get_batch(mode='train')
ds.disp_batch(Xb=Xb, yb=yb)
m = BigramLanguageModel(AppRegistry.vocab_size)
criterion = nn.CrossEntropyLoss()
# 推理过程
out = m(Xb)
print(f'out: out.shape')
B, T, C = out.shape
out = out.reshape(B*T, C)
yb = yb.reshape(B*T)
loss = criterion(out, yb)
print(f'loss: loss;')
完整代码请参考:
git clone https://gitee.com/yt7589/hwcgpt.git
cd hwcgpt
git checkout v0.0.3_1
在这里跟Karpathy教程中的内容有所出入,我们将计算Loss的过程放到了模型之外,同时计算Loss时使用的是nn.CrossEntropy而不是F.cross_entropy。其中B代表batch_size,T为序列长度,C为单词维主,所以out的形状打出来是(4, 8, 211)。
4. 代码生成
下面我们在模型没有经过任何学习的情况下,尝试一下代码生成。在BigramLanguageModel类中添加generate方法:
# ann/bigram_language_model.py::BigramLanguageModel.generate
def generate(self, idx, max_new_tokens):
for _ in range(max_new_tokens):
logits = self(idx)
logits = logits[:, -1, :] # (B, T, C) => (B, C)
probs = F.softmax(logits, dim=-1) # (B, C)
idx_next = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next), dim=1)
return idx
# hwc_app.py::HwcApp.startup
def startup(self, args=):
torch.manual_seed(1337)
ds_rfn = 'datasets/yolo3d.txt'
Yolo3dDs.generate_vocab(ds_rfn=ds_rfn)
ds = Yolo3dDs(ds_rfn=ds_rfn)
Xb, yb = ds.get_batch(mode='train')
ds.disp_batch(Xb=Xb, yb=yb)
m = BigramLanguageModel(AppRegistry.vocab_size)
criterion = nn.CrossEntropyLoss()
# 推理过程
out = m(Xb)
print(f'out: out.shape')
B, T, C = out.shape
out = out.reshape(B*T, C)
yb = yb.reshape(B*T)
loss = criterion(out, yb)
print(f'loss: loss;')
soc = torch.zeros((1, 1), dtype=torch.long) # start of sentense
rsts = m.generate(idx=soc, max_new_tokens=100) # (B, max_new_tokens)=(1, 100)
rst = rsts[0].tolist()
gen_code = AppRegistry.decode(rst)
print(gen_code)
# 生成结果
?:因·S`表且数😃均N现移?未d平7~度号o因作8J2s像是 m>的高在检g表t宽Y是p偏e@ 用参Q€f离距`:二差*量证F💡平无)e为w×Q'e.¡框是$置偏Rhg成N😃别/rh平方作
¡六R¨
如上所示,只是随机生成了一些无意义的字符,这是因为我们的BigramLanguageModel没有经过任何训练,只能输出随机结果。完整代码请参考:
git clone https://gitee.com/yt7589/hwcgpt.git
cd hwcgpt
git checkout v0.0.4
5. 网络训练
接下来,我们对这个简单的神经网络进行训练,然后再让其生成文本:
def startup(self, args=):
torch.manual_seed(1337)
AppRegistry.device = 'cuda' if torch.cuda.is_available() else 'cpu'
# self.train()
self.predict()
def train(self):
ds_rfn = 'datasets/yolo3d.txt'
Yolo3dDs.generate_vocab(ds_rfn=ds_rfn)
ds = Yolo3dDs(ds_rfn=ds_rfn)
m = BigramLanguageModel(AppRegistry.vocab_size)
m = m.to(AppRegistry.device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(m.parameters(), lr=1e-3)
for epoch in range(AppRegistry.epochs):
X, y = ds.get_batch('train')
X = X.to(AppRegistry.device)
y = y.to(AppRegistry.device)
y_hat = m(X)
B, T, C = y_hat.shape
y_hat = y_hat.reshape(B*T, C)
y = y.reshape(B*T)
loss = criterion(y_hat, y)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
print(f'epoch: loss;')
# 保存模型
torch.save(m.state_dict(), './work/ckpts/hwc.pth')
soc = torch.zeros((1, 1), dtype=torch.long).to(AppRegistry.device) # start of sentense
rsts = m.generate(idx=soc, max_new_tokens=100) # (B, max_new_tokens)=(1, 100)
rst = rsts[0].tolist()
gen_code = AppRegistry.decode(rst)
print(gen_code)
def predict(self):
ds_rfn = 'datasets/yolo3d.txt'
Yolo3dDs.generate_vocab(ds_rfn=ds_rfn)
ds = Yolo3dDs(ds_rfn=ds_rfn)
m = BigramLanguageModel(AppRegistry.vocab_size)
m = m.to(AppRegistry.device)
# 载入模型
m.load_state_dict(torch.load('./work/ckpts/hwc.pth'))
soc = torch.zeros((1, 1), dtype=torch.long).to(AppRegistry.device) # start of sentense
rsts = m.generate(idx=soc, max_new_tokens=100) # (B, max_new_tokens)=(1, 100)
rst = rsts[0].tolist()
gen_code = AppRegistry.decode(rst)
print('生成代码:')
print(gen_code)
########################## 生成结果 #######################################
ayige, nlforet[ippabonchorso d():
c, s =1, ='fon(xed CARACLnddilintoraseefiseBb s[16,
上面生成的“代码”虽然依然很差,但是已经比最原始的版本强不少了,而我们训练50000个Epoch,也用不了几分钟。
完整代码请参考:
git clone https://gitee.com/yt7589/hwcgpt.git
cd hwcgpt
git checkout v0.0.5_2
ChatGPT:基于Transformer的生成式对话模型
在自然语言处理领域,生成式对话模型是一项具有挑战性的任务。ChatGPT是基于Transformer的生成式对话模型,由OpenAI团队在2019年提出。该模型可以生成高质量的回答,使得对话更加自然连贯。本文将介绍ChatGPT的架构原理,以及如何使用Python实现该模型。

ChatGPT架构
ChatGPT是一个基于Transformer的生成式对话模型。Transformer是一种用于序列建模的神经网络结构,在自然语言处理领域中表现优异。与传统的循环神经网络相比,Transformer不需要考虑输入序列的顺序,因此可以并行处理输入序列。Transformer由编码器和解码器两部分组成。编码器将输入序列转换为连续的向量表示,解码器将该向量表示转换为输出序列。
ChatGPT的架构是一个单向的Transformer解码器。它接收一个token序列作为输入,并生成一个与之对应的token序列作为输出。该模型使用了多层Transformer结构,每一层都包含一个自注意力机制和一个前馈神经网络。自注意力机制可以让模型关注输入序列中不同位置的信息,从而更好地建模序列之间的关系。
ChatGPT代码实现
我们可以使用PyTorch实现ChatGPT模型。首先,我们需要下载预训练模型。OpenAI提供了多个版本的预训练模型,我们可以选择其中一个进行下载。例如,我们可以下载GPT2模型:
import torch
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained(gpt2)
model = GPT2LMHeadModel.from_pretrained(gpt2)
接下来,我们可以使用该模型生成回答。我们需要提供一个问题作为输入,并使用模型生成对应的回答。例如,对于问题“你好,今天天气怎么样?”:
input_text = "你好,今天天气怎么样?"
input_ids = tokenizer.encode(input_text, return_tensors=pt)
output = model.generate(input_ids, max_length=50, do_sample=True)
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(output_text)
运行该程序,我们将得到一个生成的回答。输出的结果可能因为模型随机性而有所不同:
今天天气真好啊,阳光明媚,适合出去走走,你要不要一起去?
ChatGPT是一个基于Transformer的生成式对话模型,可以生成高质量的回答,使得对话更加自然连贯。我们可以使用PyTorch实现该模型,并使用预训练模型生成回答。ChatGPT的成功表明,Transformer在自然语言处理领域中具有巨大的潜力,未来还有很多有趣的研究方向等待我们去探索。
以上是关于chatGPT学习---Transformer代码实现1的主要内容,如果未能解决你的问题,请参考以下文章