《Linux命令行与shell脚本编程大全》第二十一章 sed进阶
Posted xcywt
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Linux命令行与shell脚本编程大全》第二十一章 sed进阶相关的知识,希望对你有一定的参考价值。
本章介绍一些sed编辑器提供的高级特性。
21.1 多行命令
按照之前的知识,所有的sed编辑器命令都是针对单行数据执行操作的。
在sed编辑器读取数据流时,它会基于换行符的位置将数据分成行,一次处理一行数据。
有时会需要对跨多行的数据执行特定操作。
比如,在数据中查找一个长的短语Linux system Administrators Group.如果这个短语出现在两行当中,之前的知识就不够用了。
解决方案,sed编辑器包含了三个可用来处理多行文本的特殊命令:
N:将数据流中的下一行加进来创建一个多行组(multiline group)来处理
D:删除多行组中的一行
P:打印多行组中的一行
21.1.1 next命令
这个分单行版本的next命令和多行版本的next命令。
1.单行版本的next命令
小写的n命令会告诉sed编辑器移动到数据流中的下一行文本,而不用重新回到命令的最开始再执行一遍。
记住,通常sed编辑器在移动到数据流中下一行文本行之前,会在当前行上执行完所有定义好的命令,而next命令改变了这个流程。
例子:
xcy@xcy-virtual-machine:~/shell/21zhang$ cat data1.txt
this is the header line
this is a data line
this is the last line
xcy@xcy-virtual-machine:~/shell/21zhang$ sed \'/header/{n;d}\' data1.txt
this is the header line
this is a data line
this is the last line
xcy@xcy-virtual-machine:~/shell/21zhang$
data1.txt有两个空行,想删掉第一个空行,也就是在header行下一行的空行。
如果这样: $sed ‘/^$/d’ data1.txt // 这样会把两个空行都删掉。
上面的例子中,先找到包含header的那行,然后n命令会让sed编辑器移动到文本的下一行,就是第一个空行。这时sed编辑器会继续执行命令列表,用d来删掉那行。
2. 合并文本行(多行版本的next)
单行next命令会将数据流中的下一文本行移动到sed编辑器的工作空间(称为模式空间)
多行版本的next命令(N)会将下一行添加到模式空间中已有的文本后。
例子1:
xcy@xcy-virtual-machine:~/shell/21zhang$ cat data2.txt
This is line 1
This is line 2
This is line 3
This is line 4
This is line 5
xcy@xcy-virtual-machine:~/shell/21zhang$ sed \'/line 1/{N; s/\\n/ /}\' data2.txt
This is line 1 This is line 2
This is line 3
This is line 4
This is line 5
xcy@xcy-virtual-machine:~/shell/21zhang$ sed -n \'/line 1/{N; p}\' data2.txt
This is line 1
This is line 2
xcy@xcy-virtual-machine:~/shell/21zhang$
说明:第一个先找到line 1行,再读取下一行,再把换行符替换成空格输出。
第二个找到line 1行,再读取下一行,最后一起输出。
例子2:
xcy@xcy-virtual-machine:~/shell/21zhang$ cat data3.txt
on Tuesday,the linux System
Admin\'s group meeting will be held.
All System Admin should attend
Tks for your attendance
xcy@xcy-virtual-machine:~/shell/21zhang$ sed \'s/System.Admin/Desktop user/\' data3.txt
on Tuesday,the linux System
Admin\'s group meeting will be held.
All Desktop user should attend
Tks for your attendance
xcy@xcy-virtual-machine:~/shell/21zhang$ sed \'N;s/System.Admin/Desktop user/\' data3.txt
on Tuesday,the linux Desktop user\'s group meeting will be held.
All Desktop user should attend
Tks for your attendance
xcy@xcy-virtual-machine:~/shell/21zhang$
说明:第一次执行的命令直接替换,System Admin中间的点号是通配符模式(匹配空格和换行符)。这里无法替换第一行的System Admin。
第二次执行的,可以替换掉第一个System Admin。但是存在问题:当点号匹配到了换行符时就把换行符删掉了,这两行就合并在了一起。
要注意N命令的顺序。
网上看的别人的帖子评论(便于理解):
来源:https://www.cnblogs.com/fhefh/archive/2011/11/14/2248942.html
1)sed正常情况下处理顺序是这样:
读取一行到模式空间-》在模式空间中执行命令-》打印模式空间中的内容,清空模式空间-》读取下一行-》 …… -》直到文件结束。
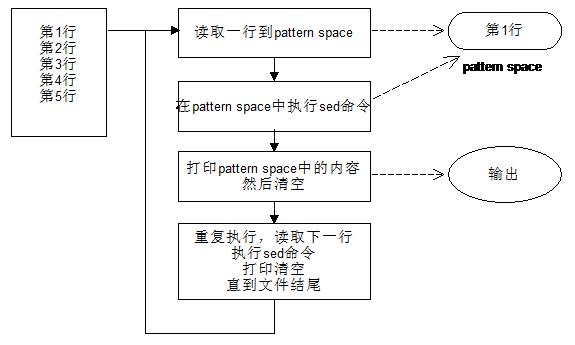
但是有时脚本中某个命令被执行会希望模式空间能保留下来,以便下一次使用。这个时候n N命令的作用就来了。
2)命令n:读取下一行到模式空间,这时模式空间有两行内容了。但是先读取的那行不会被取代、覆盖或删除。
当n命令后,还有其他命令p的时候,此时打印的结果是n命令读取的那一行
3)命令N:将下一行添加到模式空间中去。将当前读入行和用N命令添加的下一行看成“一行”
例子:
xcy@xcy-virtual-machine:~/shell/21zhang$ cat data2.txt
This is line 1
This is line 2
This is line 3
This is line 4
This is line 5
xcy@xcy-virtual-machine:~/shell/21zhang$ sed -n \'n; /line 2/p\' data2.txt
This is line 2 # n命令读取的是这行
xcy@xcy-virtual-machine:~/shell/21zhang$ sed -n \'N; /line 2/p\' data2.txt
This is line 1 # 当前读入行
This is line 2 # N命令读入行, 看成一行
xcy@xcy-virtual-machine:~/shell/21zhang$
4)帖子下面的评论:
不管是n还是N,都不能改变sed每次只处理一行的规定。
用n时,把下一行读到模式空间,实际上只处理第2行,不理会第一行。
用N时,也是把下一行读到模式空间,但是在这里已经只对第一行进行处理,而不理会第二行。
我的观点:我觉得上面斜体部分好像有点问题,应该是把两行当做一个整体了,肯定也会处理第二行的。
21.1.2 多行删除命令
单行删除命令d
多行删除命令D
1.$sed ‘N; /System\\nAdim/d’ data.txt
data.txt内容如下:
xxxx xxxx System
Adim xxx
xxx
那么上面的命令会把前两行都删掉。
2. D命令:它只删除模式空间中的第一行,该命令会删除到换行符(含换行符)为止的所有字符
例子:
xcy@xcy-virtual-machine:~/shell/21zhang$ cat data5.txt
this is header line
this is second line
this is last line
xcy@xcy-virtual-machine:~/shell/21zhang$ sed \'/^$/{N; /header/D}\' data5.txt
this is header line
this is second line
this is last line
xcy@xcy-virtual-machine:~/shell/21zhang$
为了删除第一个空行,保留第二个空行。
上述命令会先查找空白行,然后用N命令将下一文本添加到模式空间。
假如新的模式空间中有header,那么删除模式空间中的第一行。
21.1.3 多行打印命令P
单行打印命令p(小写):会打印模式空间中的所有行
多行打印命令P(大写):会打印模式空间中的第一行
例子:
xcy@xcy-virtual-machine:~/shell/21zhang$ sed -n \'N; /header/p\' data5.txt
this is header line
xcy@xcy-virtual-machine:~/shell/21zhang$ sed -n \'N; /header/P\' data5.txt
xcy@xcy-virtual-machine:~/shell/21zhang$
说明:第一个是单行打印,第二个是多行打印(只打印模式空间的第一行)
这里要去理解模式空间的概念。
21.2 保持空间
1.模式空间(pattern space)是一块活跃的缓冲区,在sed编辑器上执行命令时它会保存待检查的文本,但它并不是sed编辑器保存文本的唯一区间。
还有另外一块缓冲区,叫保持空间(hold space)。在处理模式空间中的某些行时,可以用保持空间来临时保存一些行。
有5条命令可以来操作保持空间:
|
命令 |
描述 |
|
h |
将模式空间复制到保持空间 |
|
H |
将模式空间附加到保持空间 |
|
g |
将保持空间复制到模式空间 |
|
G |
将保持空间附加到模式空间 |
|
x |
交换模式空间和保持空间的内容 |
2.通常用了h或H将字符串移动到保持空间时,最终还要用g,G或x命令将保存的字符串移回到模式空间(否则,你就不用在一开始考虑保存它们了)。
3.例子:
xcy@xcy-virtual-machine:~/shell/21zhang$ cat data2.txt
This is line 1
This is line 2
This is line 3
This is line 4
This is line 5
xcy@xcy-virtual-machine:~/shell/21zhang$ sed -n \'/line 1/ {h;p;n;p;g;p}\' data2.txt
This is line 1
This is line 2
This is line 1
xcy@xcy-virtual-machine:~/shell/21zhang$
说明:
1)先找含有line 1 是行
2)把那行读进保持空间
3)打印模式空间中的内容
4)n命令读取数据流中的下一行(line 2),并放到模式空间中去。
5)打印模式空间中的内容(第2行)
6)将保持空间的内容复制到模式空间,会替换之前的模式空间的内容
7)打印模式空间中的内容,就是(line 1)
这样可以将整个文件的文本行反转
21.3 排除命令
可以配置命令使其不要作用到数据流中的特定地址或地址区间
感叹号(!)命令用来排除命令,也就是让原本会起作用的命令不起作用。
例子:
$sed –n ‘/line 2/!p’ data2.txt // 包含line 2的行不打印,其他的打印
还可以这样:
$sed ‘$!N
> s/System\\nAdmin/Desktop\\nUser/
> s/System Admin/Desktop User/
> ’ data.txt
假如data.txt的最后一行有System Admin,分两种情况分析:
1)如果仅仅是$sed ‘N ……’。这样,那么最后一行的System Admin就替换不了。因为读取最后一行时,还会运行N命令,但是却没有下一行了。所以就不执行下面的了。也就不会进行替换了。
2)如果是上面那么写,表示读取最后一行时不运行N命令了,(也就是不读下一行了)(但是对其他行都执行了N命令)。这样就还会运行后面的命令,也就可以提换到了。
实例:将文本翻转输出
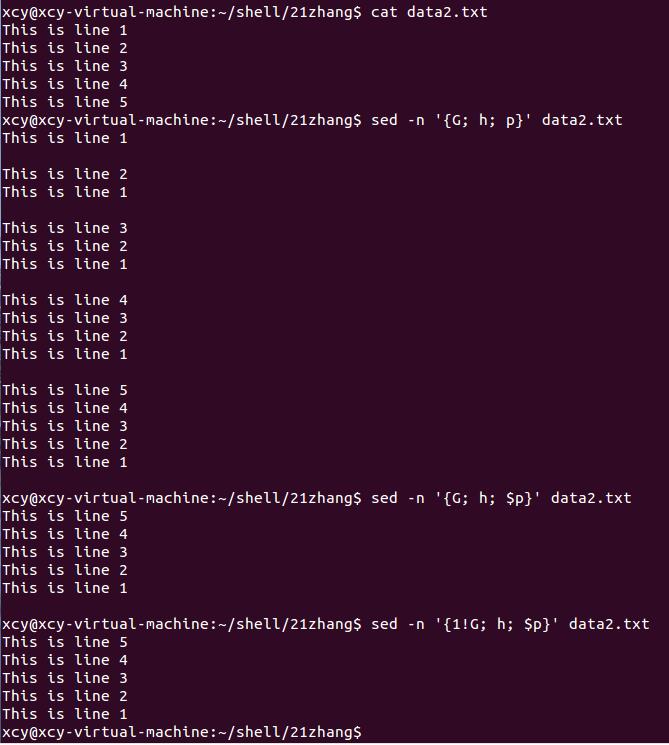
不需要将保持空间文本附加要处理的第一行文本后面。可以用感叹号实现。 1!G
$sed -n ‘{1!G;h;$p}’ data2.txt
说明:
读取第一行时不执行G命令,
读取到最后一行时才去执行p,p去打印模式空间的内容。
如果没有$,表示每读取一行都会执行p,每次都会打印模式空间的内容。就像下面的例子一样。
循环1执行了h命令。
循环2执行了G h命令。
循环3执行了G h命令。
循环4执行了G h命令。
循环5执行了G h p命令。
$sed ‘1!G; h; $1d’ data2.txt
这个也可以实现类似的效果
备注:linux下的翻转命令tac。(正好跟cat相反)
21.4 改变流
通常,sed编辑器会从脚本的顶部开始,一直执行到脚本的结尾(D命令例外,它会强制sed编辑器返回到脚本的顶部,而不读取新的行)。
sed编辑器提供了一个方法来改变命令脚本的执行流程,其结果与结构化编程类似。
21.4.1 分支
sed编辑器提供了一种方法可以基于地址、地址模式或地址区间排除一整块命令。这允许你只对数据流中的特定行执行一组命令
分支(branch)命令b格式如下:
[address]b [label]
address决定了哪些行的数据会触发分支命令
label参数定义了要跳转到的位置。
例子:
$sed ‘{2,3b; s/line/new_line/}’ data.txt
分支命令在数据流中的第2行和第3行跳过了替换命令。其他行会执行替换命令。
要是不想跳到脚本的结尾,可以为分支命令定义一个要跳转的标签。
标签以冒号开始,最多七个字符长度。
实例:
1)说明:第一行跳到jump1。第2行开始不跳了。顺序执行命令
xcy@xcy-virtual-machine:~/shell/21zhang$ sed \'{/line 1/b jump1; s/line/new li22ne/; :jump1 s/line/line_jump/}\' data2.txt
This is line_jump 1
This is new li22ne 2
This is new li22ne 3
This is new li22ne 4
This is new li22ne 5
2)第2 行,先进行第一个替换,再接着进行第二个替换。
xcy@xcy-virtual-machine:~/shell/21zhang$ sed \'{/line 1/b jump1; s/line/new line/; :jump1 s/line/line_jump/}\' data2.txt
This is line_jump 1
This is new line_jump 2
This is new line_jump 3
This is new line_jump 4
This is new line_jump 5
xcy@xcy-virtual-machine:~/shell/21zhang$
实例2:
xcy@xcy-virtual-machine:~/shell/21zhang$ echo "This, is, a, cat," | sed -n \'{s/,//p}\' #只替换一个
This is, a, cat,
xcy@xcy-virtual-machine:~/shell/21zhang$ echo "This, is, a, cat," | sed -n \'{s/,//gp}\' # 全部替换
This is a cat
# 下面的例子中要找到逗号才会跳转。如果没有这个会一直循环下去
xcy@xcy-virtual-machine:~/shell/21zhang$ echo "This, is, a, cat," | sed \'{:start s/,//1p; /,/b start}\'
This is, a, cat,
This is a, cat,
This is a cat,
This is a cat
This is a cat
xcy@xcy-virtual-machine:~/shell/21zhang$
21.4.2 测试
测试(test)命令(t)也可以用来改变sed编辑器脚本的执行流程。
测试命令会根据替换命令的结果跳转到某个标签,而不是根据地址跳转。
格式:
[address] t [label]
实例:
xcy@xcy-virtual-machine:~/shell/21zhang$ cat data2.txt
This is line 1
This is line 2
This is line 3
This is line 4
This is line 5
xcy@xcy-virtual-machine:~/shell/21zhang$ sed \'s/line 1/line one/; t xcy; s/line/new_line/; :xcy s/This/This222/\' data2.txt
This222 is line one
This222 is new_line 2
This222 is new_line 3
This222 is new_line 4
This222 is new_line 5
xcy@xcy-virtual-machine:~/shell/21zhang$
如果匹配了line 1。就把line 1换成line one。然后跳到标签xcy。进行This 替换。
第2行匹配不了line 1。不跳转,直接将line 换成new_line。
21.5 模式替代
比如有这个需求:把所有*at 的单词都加上双引号
$echo “The cat is hat, bat” | sed ‘s/.at/”.at”’
这样会全部换成”.at”。不会把cat变成”cat”。 不会把hat变成”hat”。
21.5.1 &符号
&符号可以用来代替替换命令中的匹配的模式。不管模式匹配的是什么样的文本。
比如:
$echo “The cat is hat, bat” | sed ‘s/.at/”&”’
当匹配到cat时,&就变成了cat
当匹配到hat时,&就变成了hat。
21.5.2 替代单独的单词
有时需要提取这个字符串的一部分。
sed编辑器用圆括号来定义替换模式中的子模式。你可以在替代模式中使用特殊字符来引用每个子模式。
替代字符由反斜线和数字组成,\\1 \\2 \\3 等,数字表明子模式的位置。
sed编辑器会给第一个子模式分配字符\\1,第二个子模式分配\\2,以此类推。
比如:
将cat is替换成cat are。后面那个is就不会替换。
cat是一个子模式。\\1用来提取它。
xcy@xcy-virtual-machine:~/shell/21zhang$ echo "The cat is hat is" | sed \'s/\\(cat\\) is/\\1 are/\'
The cat are hat is
xcy@xcy-virtual-machine:~/shell/21zhang$
还可以用一个单词替换一个短语:
将.at看成一个子模式,这样就把furry删除了。
$ echo "That furry cat is pretty" | sed \'s/furry \\(.at\\)/\\1/\'
That cat is pretty
$ echo "That furry hat is pretty" | sed \'s/furry \\(.at\\)/\\1/\'
That hat is pretty
实例:
$ echo "12345678" | sed \'{:start s/\\(.*[0-9]\\)\\([0-9]\\{3\\}\\)/\\1,\\2/; t start}\'
12,345,678
第一个子模式是以数字结尾的任意长度的字符
第二个子模式是若干组三位数字。
第一次先匹配到了12345 678,然后插入一个,
第二次匹配到了12 345,678,然后插入一个逗号
第三次匹配不到了
21.6 在脚本中使用sed
21.6.1 使用包装脚本
可以将sed编辑器命令放到shell包装脚本中。包装脚本充当着sed编辑器和命令行之间的中间人角色。
例子:
之前那个将文本翻转的例子:
xcy@xcy-virtual-machine:~/shell/21zhang$ cat tac.sh
#!/bin/bash
sed -n \'1!G;h;$p\' $1
xcy@xcy-virtual-machine:~/shell/21zhang$ ./tac.sh data2.txt
This is line 5
This is line 4
This is line 3
This is line 2
This is line 1
xcy@xcy-virtual-machine:~/shell/21zhang$
21.6.2 重定向sed的输出
默认情况下sed编辑器的输出到STDOUT上。可以在shell脚本找那个使用各种标准方法对sed编辑器的输出进行重定向。
例子:对数值计算的结果加上逗号
1 #!/bin/bash
2 factorial=1
3 counter=1
4 number=$1
5
6 while [ $counter -le $number ]
7 do
8 factorial=$[ $factorial * $counter ]
9 counter=$[ $counter + 1 ]
10 done
11
12 result=$(echo $factorial | sed \'{
13 :start
14 s/\\(.*[0-9]\\)\\([0-9]\\{3\\}\\)/\\1,\\2/
15 t start
16 }\'
17 )
18
19 echo "the result = $result"
用法:$./fact.sh 20 // 求20的阶乘
21.7 创建sed实用工具
21.7.1 加倍行间距
sed ‘$!G’ data2.txt
每读取一行都会将保持空间追加到模式空间。只不过保持空间是一个空行而已。
最后一行就不需要追加了,最后一行不执行G 命令。
21.7.2 对可能含有空白行的文件加倍行间距
假如本来有空行,则不加(否则会出现两个空行)。
方法就是先删除空行,再加空行
$sed ‘/^$/d; $!G’ fact.sh
21.7.3 给文件中的行编号(等号=)
用=号:
sed ‘=’ data2.txt
这样的结果很丑。
下面这个好看点:
$sed ‘=’ data2.txt | sed ‘N; s/\\n/: /’
把换行符换成冒号空格。
有一些其他命令也可以加行号:
$nl data2.txt
$cat –n data2.txt
21.7.4 打印末尾行
$代表数据流中的最后一行
$sed –n ‘$p’ data2.txt
如何用美元符显示数据流末尾的若干行呢?答案是创建滚动窗口
N命令将下一行文本附加到模式空间中已有的文本行后面。
D命令会删除模式空间的第一行
例子:显示最后5行,注意下面的6:
xcy@xcy-virtual-machine:~/shell/21zhang$ cat print.sh
#!/bin/bash
sed \'{
:start
$q; N; 6,$D
b start
}\' $1
xcy@xcy-virtual-machine:~/shell/21zhang$ ./print.sh data3.txt
This is line 6
This is line 7
This is line 8
This is line 9
This is line 10
xcy@xcy-virtual-machine:~/shell/21zhang$
分析:
1)如果是最后一行则退出
2)N命令将下一行附加到模式空间中的当前行之后
3)如果是在第6到结尾行,就删除模式空间中的第一行。
21.7.5 删除行
1、删除连续的空白行
无论文件的数据行之间有多少个空白行,在输出中只会保留一个空白行。
关键在于创建包含一个非空白行和一个空白行的区间。如果遇到了这个区间,就不删除。对于不匹配这个区间(两个或者更多的空行)的行则删除。
$sed ‘/./,/^$/!d’ data2.txt
区间就是/./ 到 /^$/。开始会匹配包含至少一个字符的行。区间的结束是空行。
2.删除开头的空白行
也是用区间删除
$sed ‘/./,$!d’ data.txt
3. 删除结尾的空白行
例子:
xcy@xcy-virtual-machine:~/shell/21zhang$ cat data2.txt
This is line 1
This is line 2
This is line 3
This is line 4
xcy@xcy-virtual-machine:~/shell/21zhang$ sed -n \'/^\\n*$/p\' data2.txt
xcy@xcy-virtual-machine:~/shell/21zhang$ sed \'{:start /^\\n*$/ {$d; N; b start}}\' data2.txt
This is line 1
This is line 2
This is line 3
This is line 4
xcy@xcy-virtual-machine:~/shell/21zhang$
地址模式能够匹配只含有一个换行符的行。如果找到了这样的行,而且还是最后一行,删除命令会删掉它。如果不是最后一行,N命令会将下一行附加到它的后面,分支命令跳到循环起始位置重新开始。
21.7.6 删除HTML标签
xcy@xcy-virtual-machine:~/shell/21zhang$ cat data.txt
<html>
<title>This is the page </title>
hahah, my name is xcy
Are you ok?
I am fine, and you?
</html>
内容如上,下面分三步进行分析:
1.先删除以<开头, >结尾的且有数据的文本字符串
$sed ‘s/<.*>//g’ data.txt
2.上面的第2行不能被删掉了。解决方法是让sed编辑器忽略任何嵌入到原始标签中的大于号。可以创建一个字符组来排除大于号。 <>中间不能有>。否则不删除。
$sed ‘s/<[^>]*>//g’ data.txt
3. 删除多余空行
$sed ‘s/<[^>]*>//g; /^$/d’ data.txt
以上是关于《Linux命令行与shell脚本编程大全》第二十一章 sed进阶的主要内容,如果未能解决你的问题,请参考以下文章