深度学习实战——卷积神经网络实践(LeNetResnet)
Posted @李忆如
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习实战——卷积神经网络实践(LeNetResnet)相关的知识,希望对你有一定的参考价值。
忆如完整项目/代码详见github:https://github.com/yiru1225(转载标明出处 勿白嫖 star for projects thanks)
目录
系列文章目录
本系列博客重点在深度学习相关实践(有问题欢迎在评论区讨论指出,或直接私信联系我)。
第一章 深度学习实战——不同方式的模型部署(CNN、Yolo)_如何部署cnn_@李忆如的博客
第二章 深度学习实战——卷积神经网络实践
梗概
本篇博客主要介绍几种卷积神经网络的原理,并进行了代码实践与优化,另外,使用了CAM、图像显著性检测等方法进行了模型的可视化诊断。(内附代码与数据集)。
一、实验综述
本章主要对实验思路、环境、步骤进行综述,梳理整个实验报告架构与思路,方便定位。
1.实验工具及内容
本次实验主要使用Pycharm完成几种卷积神经网络的代码编写与优化,并通过不同参数的消融实验采集数据分析后进行性能对比。另外,分别尝试使用CAM与其他MIT工具包中的显著性预测算法对模型进行可视化诊断,并同时在一些在线平台上做了预测。
2.实验数据
本次实验大部分数据来自卷积神经网络模型官方数据集,部分测试数据来源于网络。
3.实验目标
本次实验目标主要是深度剖析卷积神经网络的原理与模型定义,并了解不同参数的意义与对模型的贡献度(性能影响),通过实践完成不同模型、参数情况的性能对比与可视化诊断,指导真实项目开发中应用。
4.实验步骤
本次实验大致流程如表1所示:
表1 实验流程
| 1.实验思路综述 |
| 2.卷积神经网络综述 |
| 3.LetNet原理、实现与优化 |
| 4.高级架构介绍与选择实现 |
| 5.图像显著性与可视化诊断 |
二、卷积神经网络综述
本实验无论是实践LetNet、AlexNet还是其他高级架构,都属于卷积神经网络,故本章先对神经网络的概念与原理做一定综述,并简述其发展历程。
1.卷积神经网络概念与原理
卷积神经网络(Convolutional Neural Network,简称CNN)是一类前馈神经网络,是基于神经认知机和权重共享的卷积神经层(感受野衍生概念)被提出的,由于其具有局部区域连接、权值共享、降采样的结构特点,如今在图像处理领域有较好效果并并大量应用。
在此之前,一般使用全连接神经网络进行图像处理与其他人工智能任务,两种网络结构对比如图1所示,而全连接神经网络处理大图像图像时有以下三个明显的缺点:
- 首先将图像展开为向量会丢失空间信息;
- 其次参数过多效率低下,训练困难;
- 同时大量的参数也很快会导致网络过拟合。
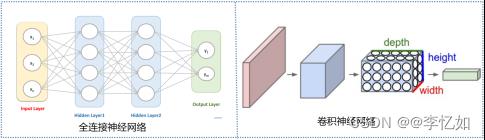
图1 两种神经网络结构对比
如图1所示,CNN中的各层中的神经元是3维排列的:宽度、高度和深度(深度指激活数据体的第三个维度),而将CNN的结构拆解,在原理实现上一般由输入层、卷积层(一般包含激活函数层)、池化(Pooling)层和全连接层各层叠加构建,各层简介如图表1:
图表1 CNN各层简介
| 输入层: 相关数据(集)的输入与读取
|
| 过程:
|
主要就是使用卷积核进行特征提取和特征映射,由于卷积一般为线性运算,故需要使用激活函数(目前常用ReLU)增加非线性映射。 |
主要作用体现在降采样:保留显著特征、降低特征维度,增大kernel的感受野,同时提供一定的旋转不变性。 |
经过若干次卷积+激励+池化后,将多个特征图进行通过softmax等函数全连接并输出(与全连接神经网络类似),对于过拟合等现象会引入dropout、正则化等操作,还可以进行局部归一化(LRN)、数据增强,交叉验证,提前终止训练等操作,来增加鲁棒性。 |


根据实验1中ML/DL任务综述我们知道人工智能任务中最重要的就是数据和模型,而对于CNN的模型训练,核心流程(与其他网络训练类似)如图2所示:

图2 CNN模型训练核心流程
Tips:CNN大类概念与核心原理解析到此结束,特定网络的解析在后文实践中详述。
2.卷积神经网络发展历程
本部分对CNN的发展历程做一个简述,经典的CNN网络发展可见图3:
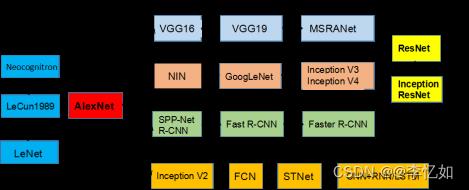
图3 经典CNN的发展历程
Tips:本图仅统计2016及之前经典CNN网络。
根据图3,广义上最早的卷积神经网络是1998年的LeNet,但随着SVM等手工设计特征的出现沉寂。而因ReLU和dropout的提出,以及GPU和大数据带来的历史机遇,CNN在2012年迎来重大突破——提出AlexNet,至此,大量CNN网络结构被提出并广泛应用。而如今Transformer(Vision)在人工智能各领域的高速发展与优秀效果正使CNN面临危机。
三、LeNet原理、实现与优化
在上一章中我们对卷积神经网络进行了简单介绍,在本章正式进入CNN的实现与优化,主要将以最经典的CNN——LeNet为例探究不同实现/参数对效果的影响。
1.LeNet原理
1.1 简介
论文:Gradient-Based Learning Applied to Document Recognition
链接:Gradient-Based_Learning_Applied_to_Document_Recognition.pdf
根据论文、网络资料、个人理解,首先在本节对LeNet原理进行介绍与解析。
背景:LeNet-5的设计主要是为了解决手写识别问题。那时传统的识别方案很多特征都是hand-crafted,识别的准确率很大程度上受制于所设计的特征,而且最大的问题在于手动设计特征对领域性先验知识的要求很高还耗时耗力,更别谈什么泛化能力,基本上只能针对特定领域。故本节同样以手写数字识别任务来介绍其原理。
1.2 数据集介绍
由于我们的原理介绍与后续实验都是基于手写数字识别任务,故在本部分对经典的数据集做一定介绍,以MNIST和Fashion-MNIST为例。
Ⅰ、MNIST:MNIST是一个著名的计算机视觉数据集,其包含各种手写数字图片(训练集中有60000个样本,测试集中有10000个样本,每个样本都是一张 28x28 像素的灰度手写数字图片),部分数据可视化如图4所示:
数据集下载:MNIST handwritten digit database,Ys

图4 MNIST数据可视化(部分)
Ⅱ、Fashion-MNIST:Fashion-MNIST 是一个替代 MNIST 手写数字集的图像数据集,涵盖了来自 10 种类别的共 7 万个不同商品的正面图片,数据格式与MNIST完全一致,不需要改动任何网络代码,部分数据可视化如图5所示:
数据集下载:github-Fashion-MNIST.com

图5 Fashion-MNIST数据可视化(部分)
1.3 网络发展
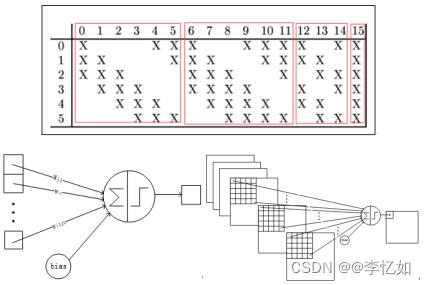
一般我们常说的LeNet是LeNet-5,而LeNet是一类网络结构(含1、4、5),在此对其网络发展及其之前发展做一定回顾(以手写数字识别为例),如图表2所示:
图表2 手写数字识别发展(至LeNet-5)
| 非CNN: 非CNN的识别过程在第一章第一节有简述,大致经历了简单线性分类器(每个输入像素值构成每个输出单元的加权和)->单隐藏层网络->双(多)隐藏层网络三个过程。
|
| LeNet: LeNet发展大致经历了LeNet-1、LeNet-4、LeNet-5三个部分(下图由上至下),网络层数变化为5->6->7,据图分析处理部分(卷积、池化)并未发生大变动,主要是输入、输出部分的格式与处理的变化,网络解析在后文详述。
|


1.4 网络解析
本部分我们对LeNet-5的网络架构进行深入解析,如图6所示,以便后续的实现与优化。

图6 LeNet-5网络架构
如图6所示,LeNet-5是一个7层卷积神经网络,包含C1、S2、C3、S4、C5/F5、F6、F7(C为卷积层,S为池化(pooling)层,F为全连接层),各层简介总结如图表3:
图表3 LeNet-5各层简介
| 输入层: 相关数据(集)的输入与读取,尺寸统一归一化为32*32 |
| 过程: |
| 1、C1层: Tips:LeNet激活函数默认为Sigmoid。
补充:特征图大小计算如式1:
式1 特征图大小计算公式 对输入图像进行第一次卷积运算,得到6个C1特征图(6个大小为28*28的 feature maps, 32-5+1=28)。 |
| 2、S2层: Tips:LeNet默认使用平均池化。
第一次卷积之后紧接着就是池化运算,得到了6个14*14的特征图(28/2=14)。S2这个pooling层是对C1中的2*2区域内的像素求和乘以一个权值系数再加上一个偏置,然后将这个结果再做一次映射。 |
| 3、C3层:
然后进行第二次卷积,输出是16个10x10的特征图. 我们知道S2 有6个 14*14 的特征图,这里是通过对S2 的特征图特殊组合计算得到的16个特征图。
|
| 4、S4层:
处理和连接过程与S2类似,得到16个5x5的特征图。 |
| 5、C5/F5层:
C5层是一个卷积层(实际上可以理解为全连接层)。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。形成120个卷积结果。
|
| 6、F6层:
计算方法:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。 F6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个ASCII编码。
|
| 7、F7层:
Output层(F7层)共有10个节点,分别代表数字(类别)0到9,且如果节点i的值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式,即为其损失函数。假设x是上一层的输入,y是RBF的输出,RBF输出的计算方式如式2:
式2 RBF输出计算方式 补充:原论文中的损失函数采用MSE,并添加了一个惩罚项,计算公式如式3:
式3 MSE + 惩罚项损失函数 |



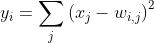

至此,LeNet-5的核心网络解析完成,根据图表3与网络结构我们将手写数字识别过程深化到各层,如图7所示:

图7 基于LeNet-5的手写数字识别过程拆解
2.LeNet实现
2.1 代码实现与解析
上一节对LeNet的背景、发展、网络进行了深入剖析,本节根据原理在代码层面进行实现,并检测在分类数据集上的效果。
Tips:由于算法年代比较久远且意义重大,故LeNet代码在网上有各种不同实现,但未必是对论文的完全还原(大部分是基于后续的tricks进行了优化),在此贴出一类优秀、简洁的代码实现(去掉了最后的高斯激活,其余与论文保持一致),来自李沐老师:6.6.卷积神经网络(LeNet) — 动手学深度学习 2.0.0 documentation (d2l.ai)。
在卷积神经网络的实现上,核心是网络的定义,根据LeNet-5的原理与各层参数,代码实现(Pytorch版)如下:
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \\t',X.shape)
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss train_l:.3f, train acc train_acc:.3f, '
f'test acc test_acc:.3f')
print(f'metric[2] * num_epochs / timer.sum():.1f examples/sec '
f'on str(device)')
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.plt.show()分析:根据Code我们可以看到代码实现与1中LeNet的论文网络定义保持一致,其中Conv2D为卷积层,AvgPool2D为平均池化(pooling)层,Dense为全连接层。每层输入参数与图表3/论文均保持一致。
而LeNet用于手写数字识别或其他分类任务时与实验1提到的ML/DL一般流程保持一致,即网络定义->数据导入与处理->模型训练->模型评估。
2.2 代码测试
在2.1根据原理编写好LeNet-5代码后,在本部分对其的原始分类效果进行测试,测试数据集为MNIST和Fashion-MNIST。
数据集可选择自己下载导入或使用代码导入,如Code2,代码导入样例如图8:
| Code2 MNIST和Fashion-MNIST代码导入 |
| from d2l import xx(框架) as d2l # Fashion-MNIST train_data, test_data = d2l.load_data_fashion_mnist(batch_size) # MNIST train_dataset = datasets.MNIST( root=r'./mnist', #此处为自己定义的下载存在目录 train=True, download=True, transform=transform #自定义转换方式) |

图8 代码导入数据集样例
在数据集准备好后,输入网络进行训练和评估即可,本实验中的训练样例与结果样例如图9、图10所示:
图9 LeNet训练过程样例

图10 LeNet测试结果样例(Fashion-MNIST)
分析:根据图10,我们可以看到在Fashion-MNIST数据集上使用LeNet网络的train loss为0.469,train acc为0.821,test acc为0.809,同时验证了代码编写的正确性。
Tips:由于在MNIST数据集上acc达到98%+,故后续优化的效果比较不明显,后续优化对比测试均基于Fashion-MNIST。
3.LeNet优化
在上一节我们实现了与论文网络结构保持一致的LeNet,并通过两个数据集上的分类测试验证了代码的正确性,但在Fashion-MNIST的分类准确率只有80%左右(epoch=10,lr=0.9为例),仍有优化的空间,故本节以LeNet为例来探究深度模型优化的范式。
3.1 超参数
深度学习很重要的一步是“调参”,而这个参数,一般指模型的超参数。重要/常见参超数总结如表2所示:
表2 重要/常见超参数总结
| 1、损失函数: 损失可以衡量模型的预测值和真实值的不一致性,由一个非负实值函数损失函数定义 |
| 2、优化器: 为使损失最小,定义loss后可根据不同优化方式定义对应的优化器 |
| 3、epoch: 学习回合数,表示整个训练过程要遍历多少次训练集 |
| 4、学习率: 学习率描述了权重参数每次训练之后以多大的幅度(step)沿梯下降的方向移动 |
| 5、归一化: 在训练神经神经网络中通常需要对原始数据进行归一化,以提高网络的性能 |
| 6、Batchsize: 每次计算损失loss使用的训练数据数量 |
| 7、网络超参数: 包括输入图像的大小,各层的超参数(卷积核数、尺寸、步长,池化尺寸、步长、方法,激活函数等) |
3.2 优化与消融实验
Tips:所有单次的消融实验均不做网络架构的改变,对比的样例均(Batch_size=256,lr=0.9,epoch=10),并不做叠加处理对比,便于数据分析与结论的提出。
在进入优化与消融实验前,我们首先根据表2定义与过往实践对LeNet中待优化的超参数进行解析,并对效果做一定预测。
- lr、Batch_size通过影响梯度影响效果(得确保在合适区间),同时影响模型收敛速度。
- 效果一般会随着Epoch的增大先增大后稳定。
- 网络超参数、损失函数、优化器等的不同选择一般对效果有较大影响,需要人为确定。
下面正式开始消融实验,尝试对经典LeNet进行优化。
Ⅰ、lr/Batch_size
第一Part我们首先分别对lr与Batch_size进行改变,并进行对比实验。
首先是lr,本实验从0-1.7,step=0.1,每个lr进行10次实验取平均值,部分数据汇总于表3(详见excel),lr对LeNet效果的影响如图11:
表3 lr对LeNet的效果影响数据汇总(部分)
| lr | 0.9 | 1 | 1.1 | 1.2 | 1.3 | 1.4 | 1.5 | 1.6 | 1.7 |
| loss | 0.469 | 0.459 | 0.444 | 0.425 | 0.411 | 0.423 | 0.438 | 0.446 | 0.461 |
| tr_acc | 0.821 | 0.827 | 0.835 | 0.843 | 0.847 | 0.842 | 0.835 | 0.822 | 0.81 |
| te_acc | 0.809 | 0.828 | 0.766 | 0.83 | 0.825 | 0.831 | 0.772 | 0.764 | 0.758 |

图11 lr对LeNet效果的影响
分析:根据lr的消融实验我们可以发现LeNet的acc随lr的增长不断上升(一定波动),最后波动下降,本实验中较好的lr为1.2-1.4,而非0.9,test_acc可从0.809上升至0.83。
再泛化一点讲,学习率对模型影响是存在范式的,如图12所示(图源cs231n):

图12 lr对模型的一般影响
实际上在LeNet中写死lr(lr不变)的做法是不合适的,在速度和效果上均不是最优选择(受限于当时的技术发展),在此对学习率的选择做简单补充。
首先我们要知道LeNet中使用的(优化器)是经典SGD算法,目前可以使用Adagrad,Adam等为代表的自适应学习策略优化器,如Code3,同样可以针对SGD进行精细调优,一般可以得到更好的效果。
| Code3 优化器学习率改进 |
| #经典SGD optimizer = torch.optim.SGD(net.parameters(), lr=lr) #自适应学习优化器 torch.optim.Adagrad(params, lr=lr, lr_decay=0, weight_decay=0, initial_accumulator_value=0) |
然后是Batch_size,本实验从2-1024,取值均为2的幂,每个Batch_size进行10次实验取平均值,数据汇总于表4,Batch_size对LeNet效果的影响如图13:
表4 Batch_size对LeNet的效果影响数据汇总
| batch_size | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 |
| loss | 0.54 | 0.316 | 0.27 | 0.269 | 0.306 | 0.329 | 0.376 | 0.469 | 0.599 | 0.916 |
| train_acc | 0.811 | 0.882 | 0.898 | 0.9 | 0.885 | 0.878 | 0.861 | 0.821 | 0.767 | 0.637 |
| test_acc | 0.82 |
视觉和图形学真是一家,基础都一样! 正在看《视觉SLAM十四讲》电子书,代码很清晰!Particle Filtering,KF,EKF, Batch Optimization, Lie Group,ICP。IMU-SLAM和Semantic SLAM是AR的未来。
VO 关心的是相邻图像间的运动关系(图像特征提取与匹配)。后端主要是去噪(滤波和非线性优化)。回环检测主要解决随时间漂移问题(记忆)。Mapping 是构建地图(度量地图,拓扑地图)。
现在两本电子书同时看,做笔记,调试代码,学习图像处理、cv计算机视觉中常用的一些算法,这些方法有的简单,有的虽然比较复杂点,但是非常实用,一方面可以学会应用,另一方面可以写论文也有用。
整理收集的图像识别、计算机视觉方面的学习电子资料供大家可以学习参考: https://www.yuque.com/baibinng/ctyewg/lyrsyg
学习积累,实战训练,每天都在进步!
以上是关于深度学习实战——卷积神经网络实践(LeNetResnet)的主要内容,如果未能解决你的问题,请参考以下文章 |
