深度学习第一步——Pytorch-Gpu环境配置:Win11/Win10+Cuda10.2+cuDNN8.5.0+Pytorch1.8.0(步步巨细,少走十年弯路)
Posted 爱睡觉的咋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习第一步——Pytorch-Gpu环境配置:Win11/Win10+Cuda10.2+cuDNN8.5.0+Pytorch1.8.0(步步巨细,少走十年弯路)相关的知识,希望对你有一定的参考价值。
博主已有:Pycharm+Anaconda
通过这篇博客你将获得:Cuda10.2+cuDNN11.x+Pytorch1.8.0(GPU)
import torch print(torch.cuda.is_available()) print(torch.__version__) print(torch.version.cuda)True 1.8.0 10.2
目录
今天是三月1日,开学的第一周,这个学期准备进军深度学习,主打的框架就是PaddlePaddle和Pytorch,PaddlePaddle都好说,有线上的Aistudio,头疼的是Pytorch,作为深度学习最经典的框架,肯定是必学无疑的。学习Pytorch,第一步就是配置环境,gpu和cpu的pytorch代码完全是两个东西,我之后想的是代码写好用云服务跑,所有代码得用gpu版本的,所以本地的Pytorch必须得是Gpu写的。实话实话,这中间我遇到了很多坑,所以我才想写这篇博客,帮大家以最快速的方式配制好深度学习的环境,话不多说,请看教程:
1.确定自己电脑有无显卡
搜索框搜索设备管理器进入,向下查找找到显示适配器:

nvidia开头的即为电脑的显卡,我这里是MX450。
2.确定显卡支持的cuda最高版本
打开windows搜索框,搜索nvidia control panel,点击nvidia control panel进入:
点击系统信息:
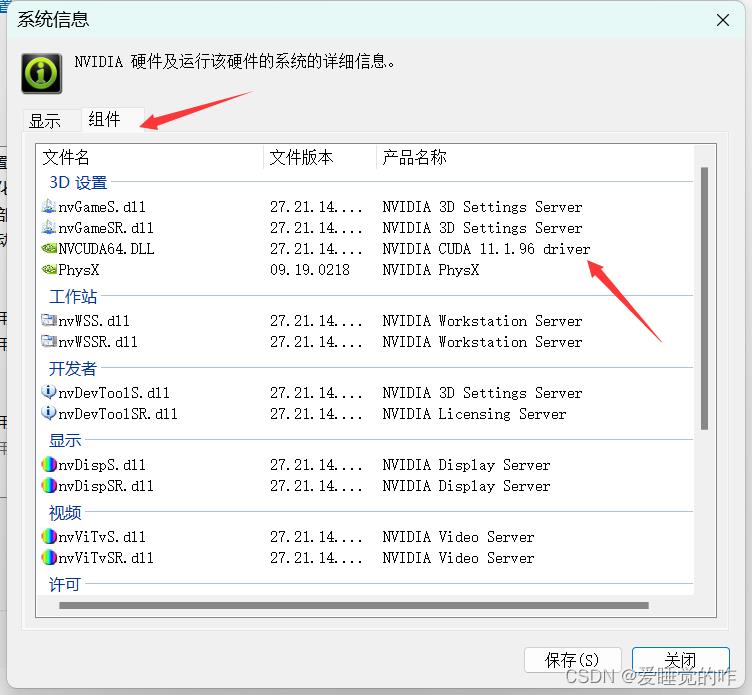
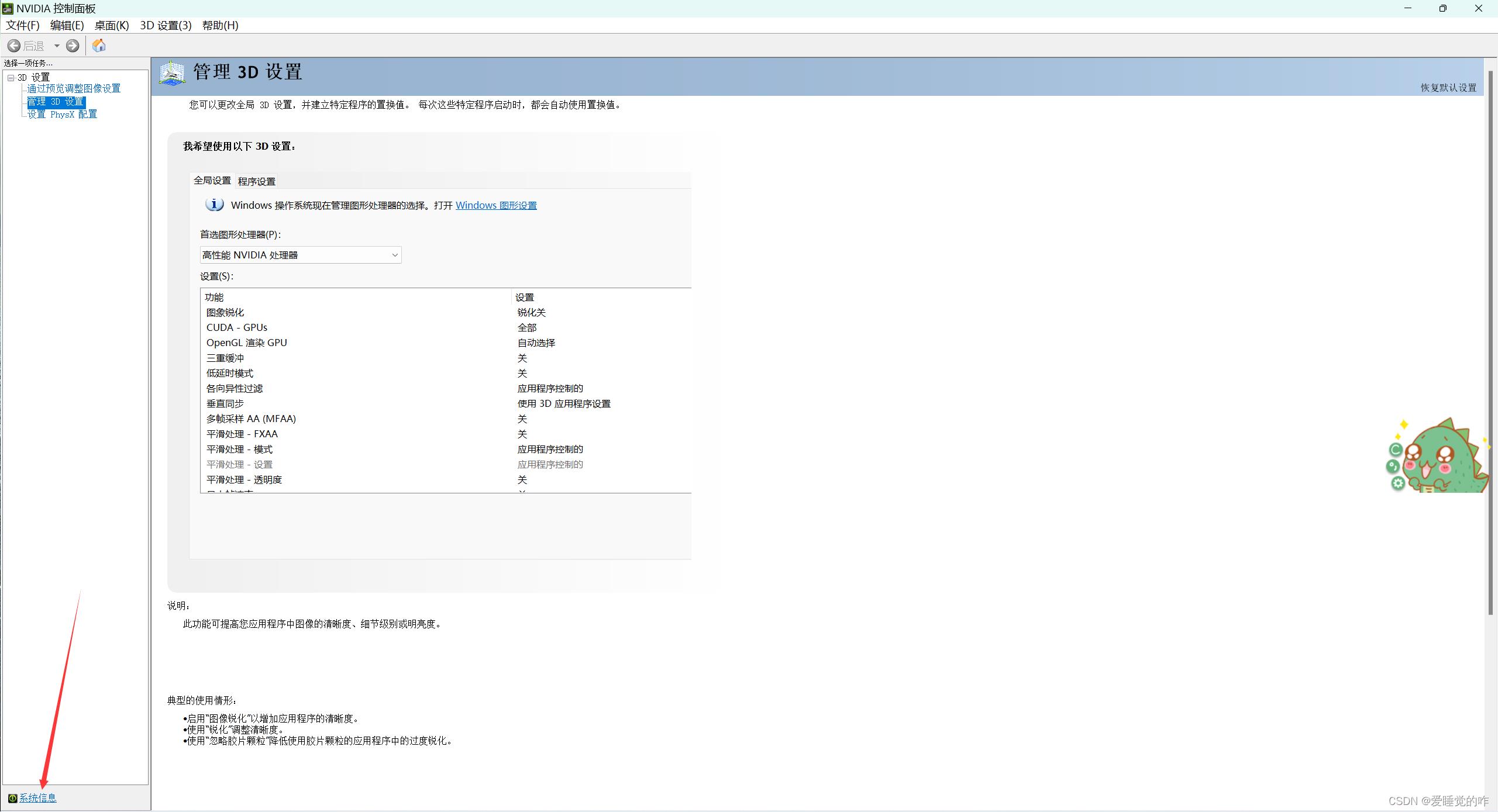 点击组件,查看自己显卡支持Cuda最高版本,我这里最高支持11.1.96,所以我安装11.1.96以下版本的cuda都可以,在本篇博客中,安装的是10.2版本。
点击组件,查看自己显卡支持Cuda最高版本,我这里最高支持11.1.96,所以我安装11.1.96以下版本的cuda都可以,在本篇博客中,安装的是10.2版本。
 3.下载安装cuda
3.下载安装cuda
进入cuda官网:cuda官网
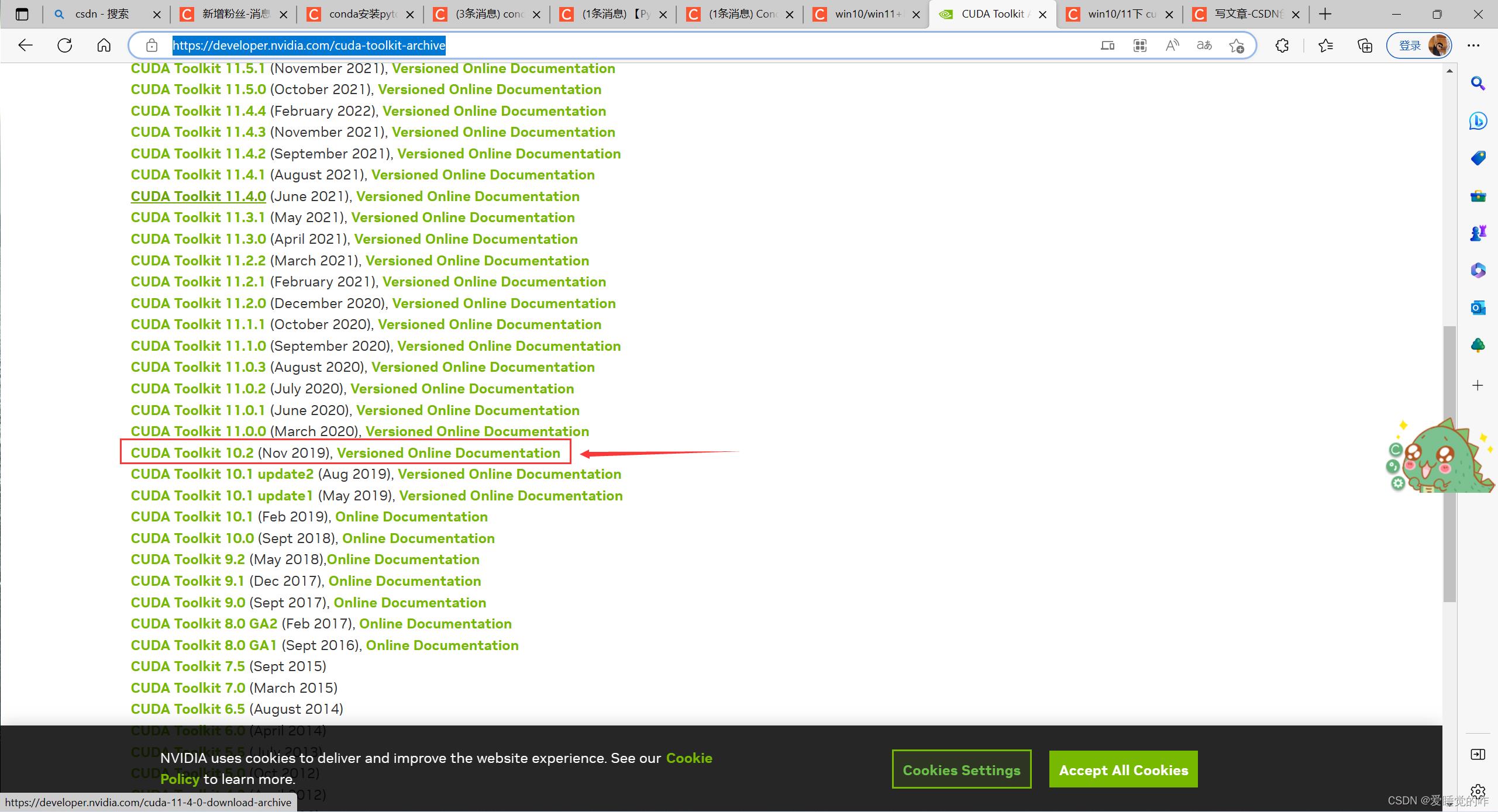
下载10.2版本的cuda,点击进入:
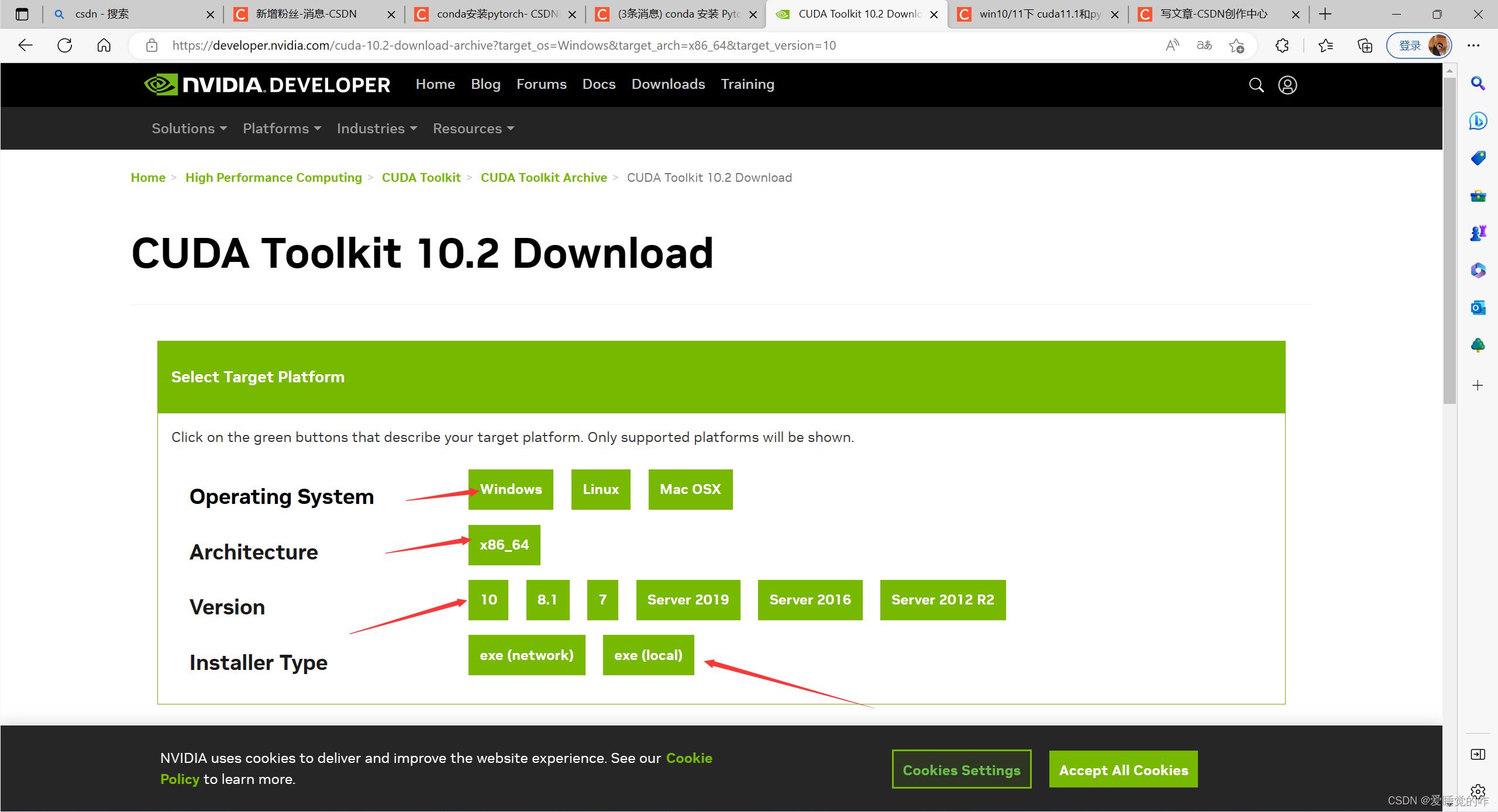 依次选择Windows,x86_64,10(win11系统可以兼容win10版本的cuda),local版本,网络版经常安装不成功。报错:nvidia安装程序无法继续未成功完成下载。
依次选择Windows,x86_64,10(win11系统可以兼容win10版本的cuda),local版本,网络版经常安装不成功。报错:nvidia安装程序无法继续未成功完成下载。
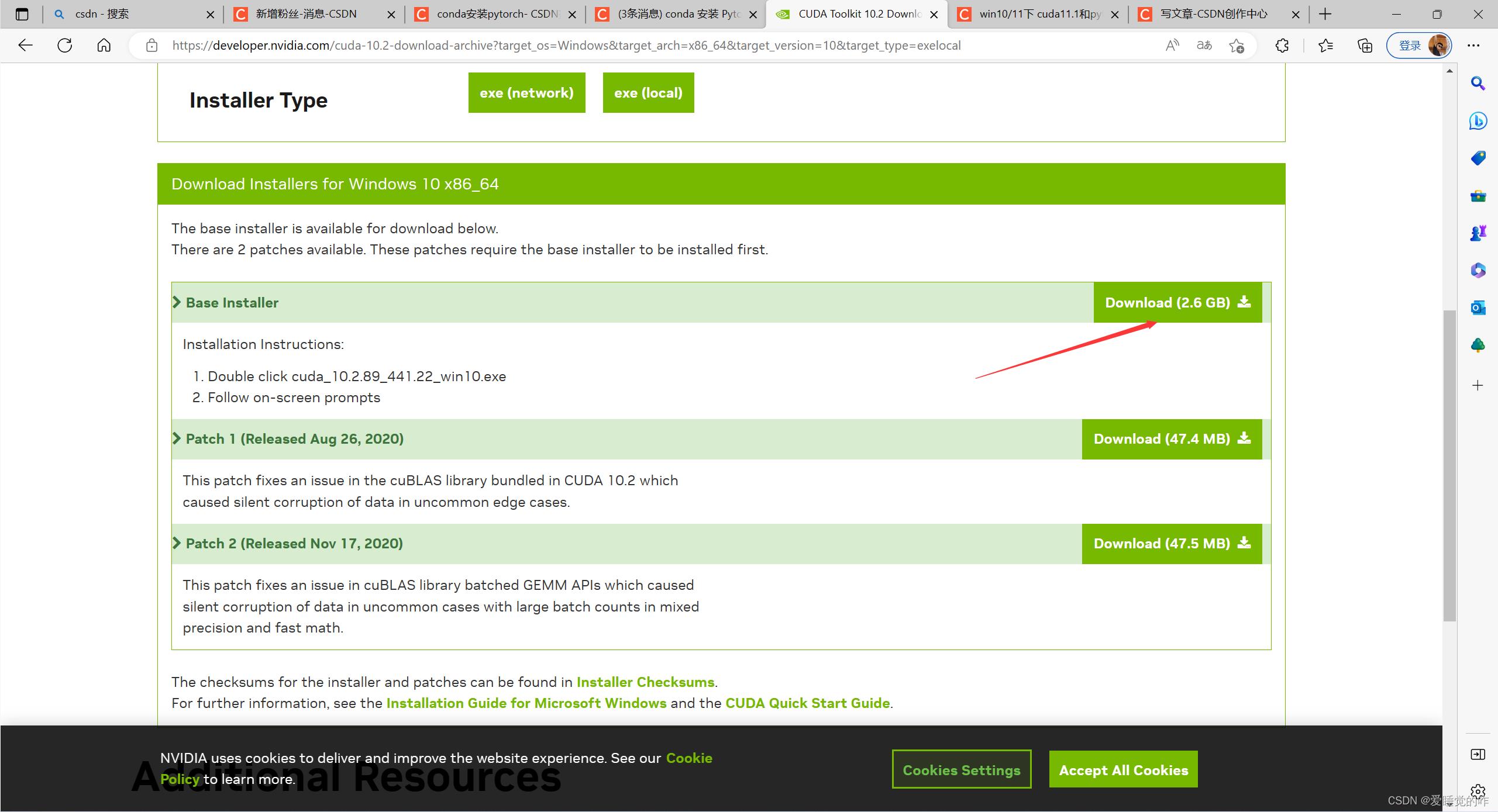
Download下载base installer,下面两个是补丁,可以下载也可以不下载,本篇博客没有下载。
- 装补丁1(发布于2020年8月26日,选装)此修补程序解决了CUDA 10.2中捆绑的cuBLAS库中的一个问题,该问题在罕见的极端情况下导致数据无提示损坏。
- 补丁2(发布于2020年11月17日,选装)此修补程序解决了cuBLAS库批处理的GEMM APIs中的一个问题,该问题在混合精度和快速数学的大批量计数的罕见情况下,导致数据无提示损坏。
之后按照指示安装就可以了,在安装选项时选择自定义安装:
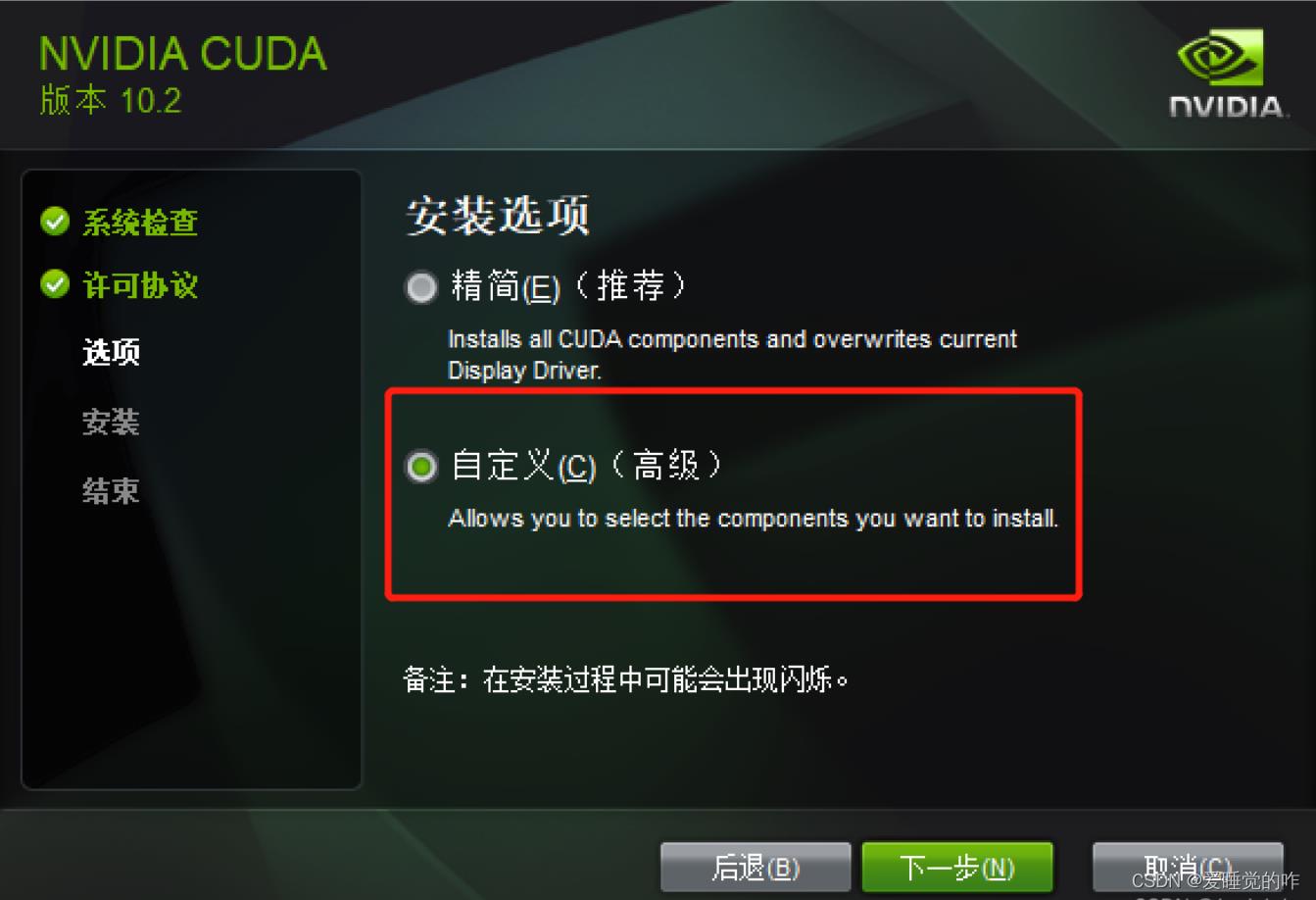
我没有改选项,直接下一步安装成功,如果出现问题可以看这篇博客:win10/win11+NVIDIA MX350笔记本自带显卡+CUDA10.2+Python3.6+Anaconda3从零开始配置深度学习环境
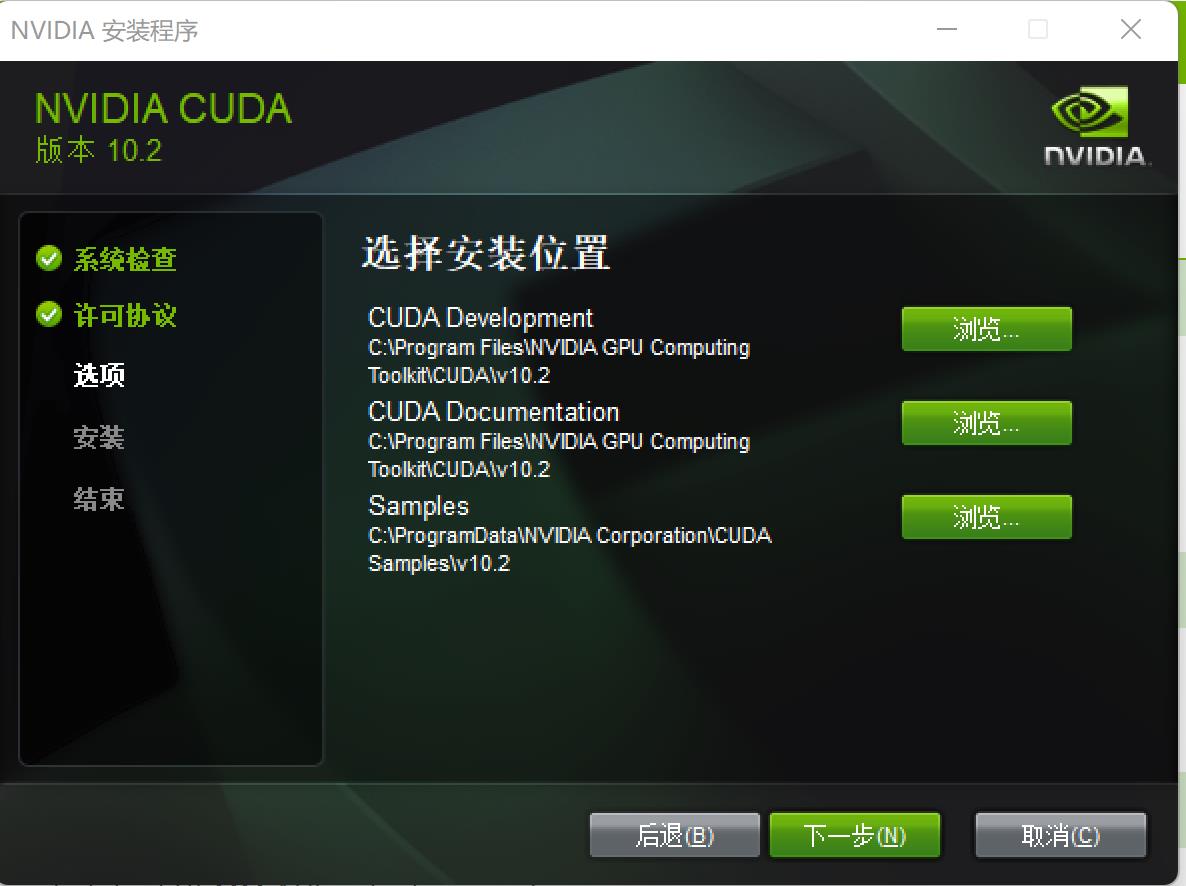
这里注意要将安装位置记录下来,之后安装cuDNN时候会用到:
等待一段时间,之后检验一下是否安装完成,win+r,输入cmd,在窗口中输入nvcc -V

出现上述信息即为安装成功,注意nvcc -V的V需要大写,中间有个空格。
4.安装cuDNN
在英伟达的官网下载与cuda版本相应的cuDNN版本,官网链接为:cuDNN
点击download cuDNN,中间会让你填写个人信息,按照表格规范填写就可以了。
点击历史版本
下载匹配cuda10.2的,也就是8.5.0这个版本:
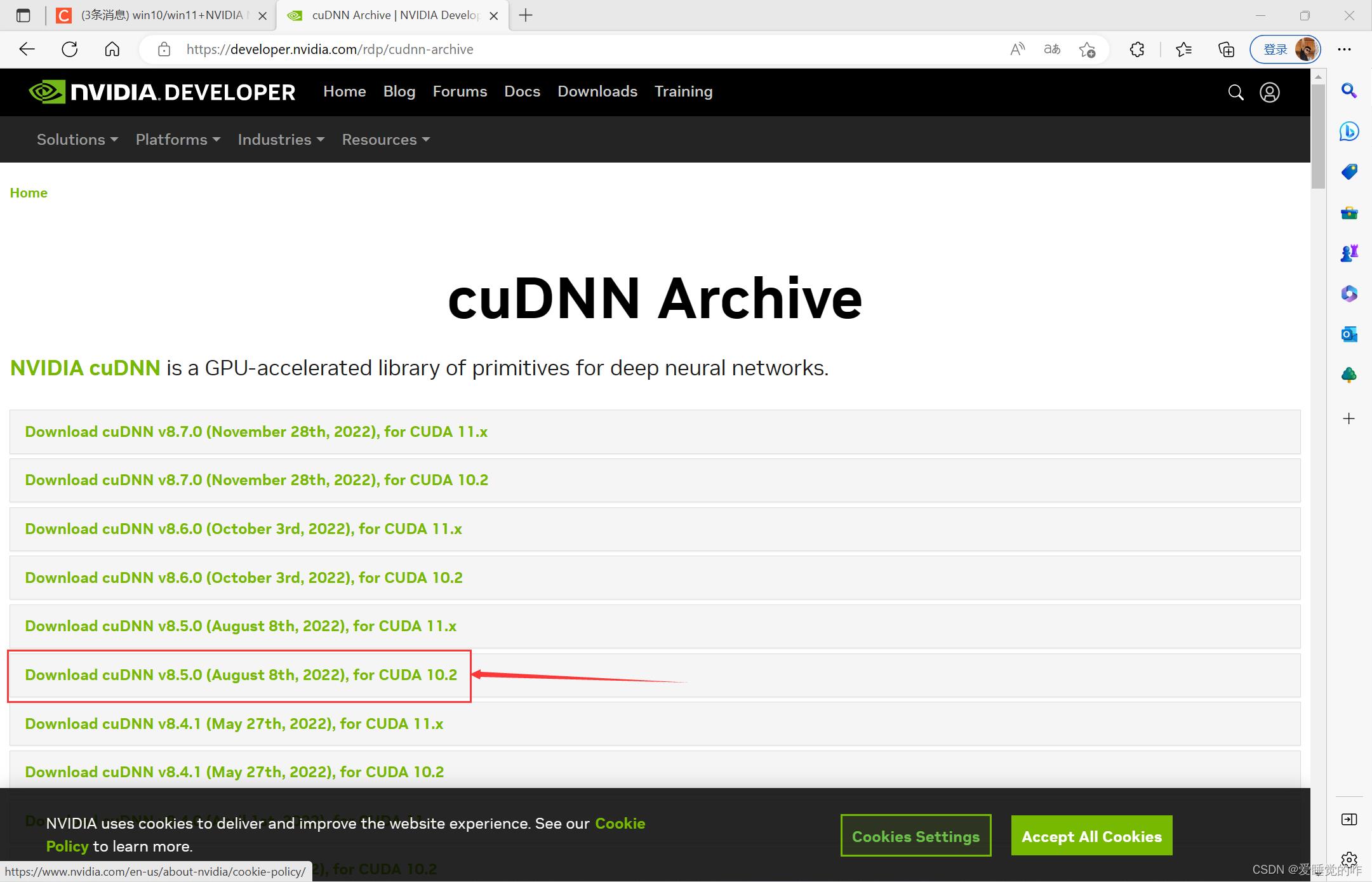
下载下来时是一个压缩包,解压,将cudnn文件夹里面的bin、include、lib文件直接复制到CUDA的安装目录下。这里的安装目录就是之前自定义cuda安装的位置:
5.安装Pytorch(重要!易踩坑!)
我大部分时间都花在安装这上面了,看了很多教程,不管是conda安装还是pip安装,最终的torch都是cpu版本的!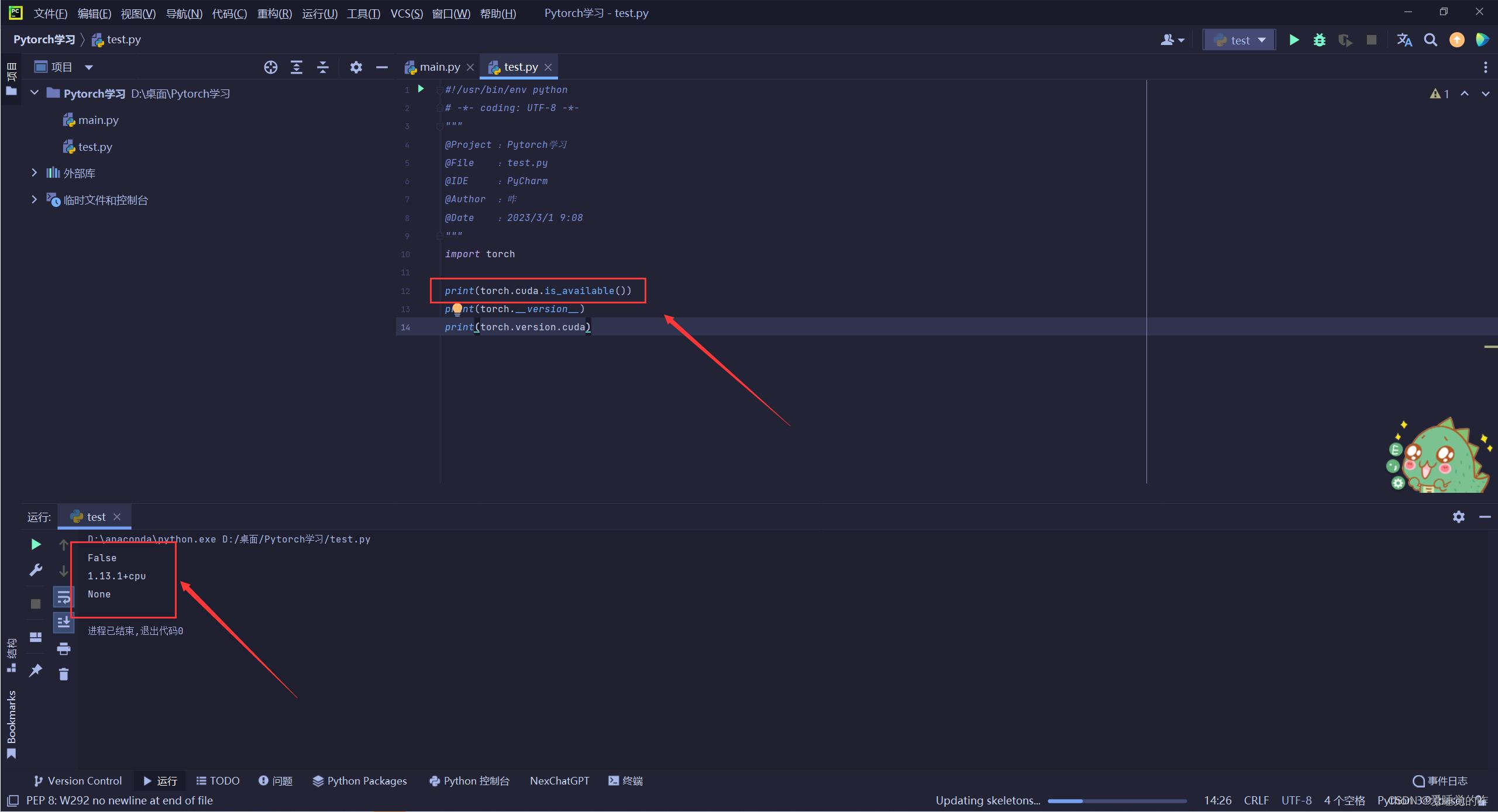
当时真的是百思不得其解,以为是自己的操作问题,不停的创建新环境,无论重装多少次,都一样,torch.cuda.is_available()返回false!终于在在一篇博客中找到了答案:torch.cuda.is_available()返回false——解决办法
因为我被conda镜像安装给坑了。我以为下载的是GPU版本,其实镜像下载的是cpu版本,所以我必须手动去官网用pip下载安装。
接下来请按照我的步骤安装,一步都不能错!
首先进入pytorch官网:Pytorch官网,点击Get Started,点击install previous versions of Pytorch,查看历史版本
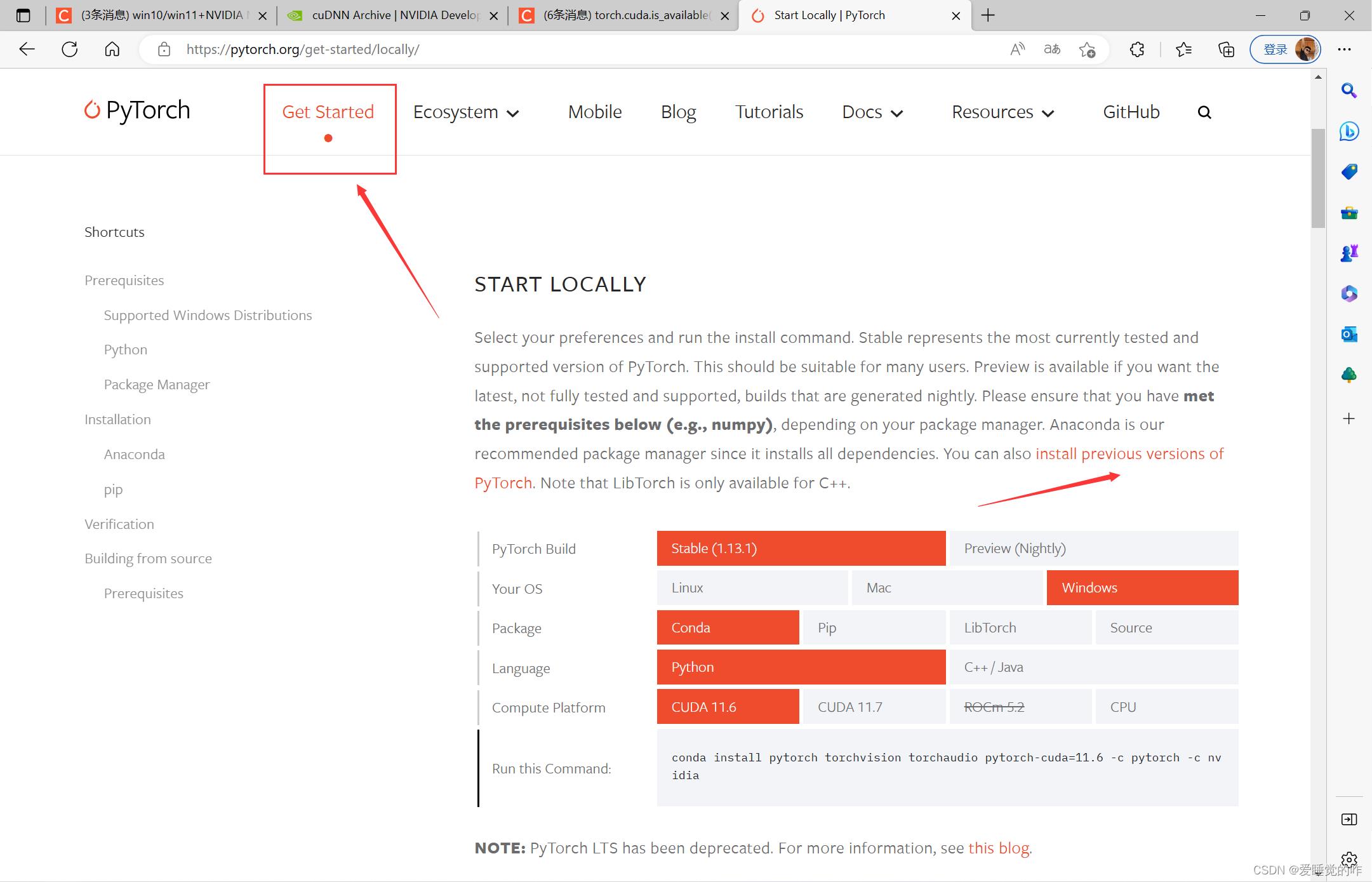
找到10.2cuda对应的torch,torchvision,torchaudio版本,记住这个版本号
pip install torch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1需要用pip下载,但是如果直接用pip指令在官网下载,速度非常慢导致torch下载失败,所有我们需要先下载.whl文件,再在本地安装!
.whl文件下载地址:torch_stable
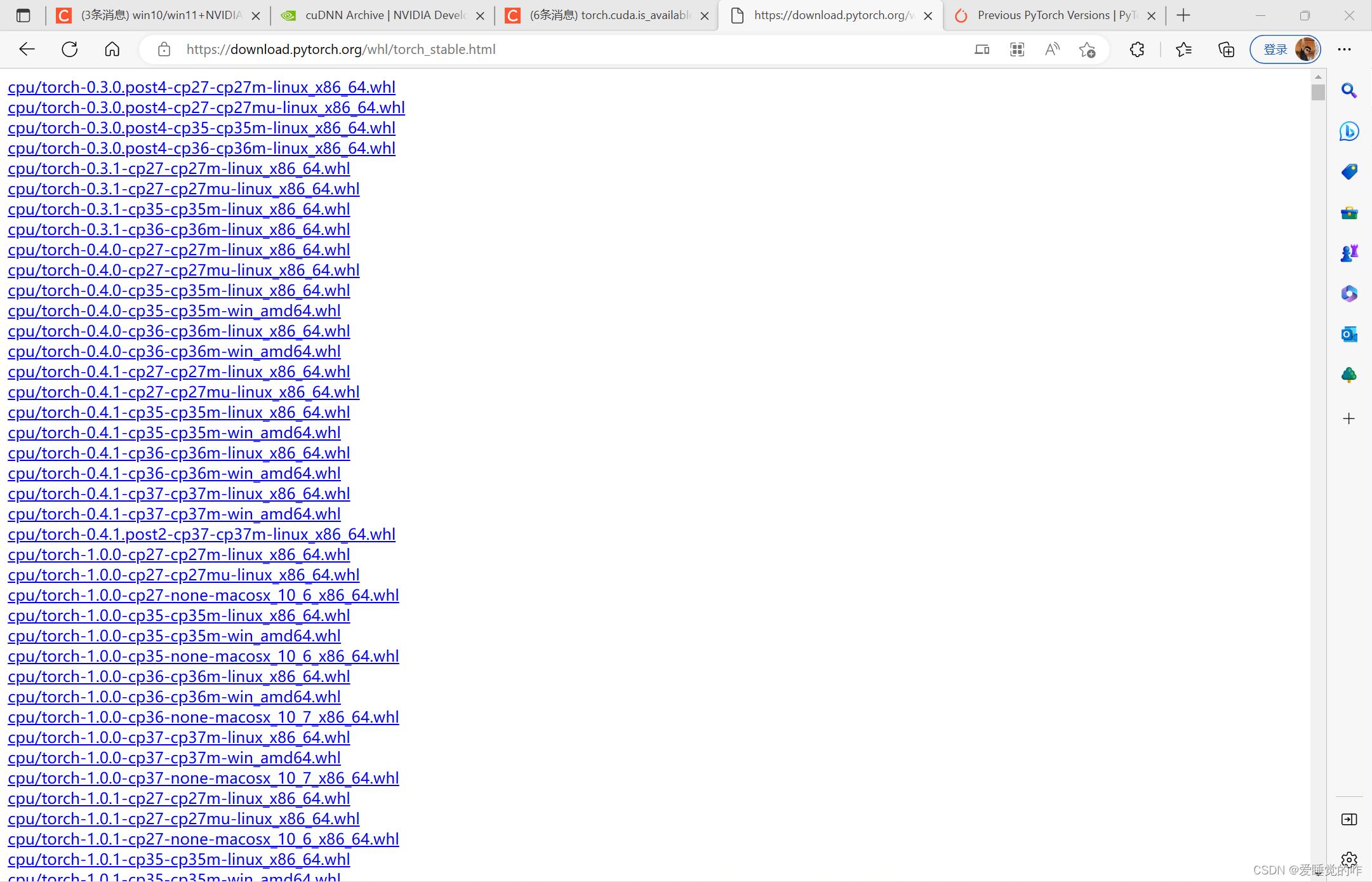
cpu开头的是cpu版本的,可以直接跳过,我们看 cu开头的,cu102表示cuda10.2,cp38对应python3.8,按照需求下载就可以了。
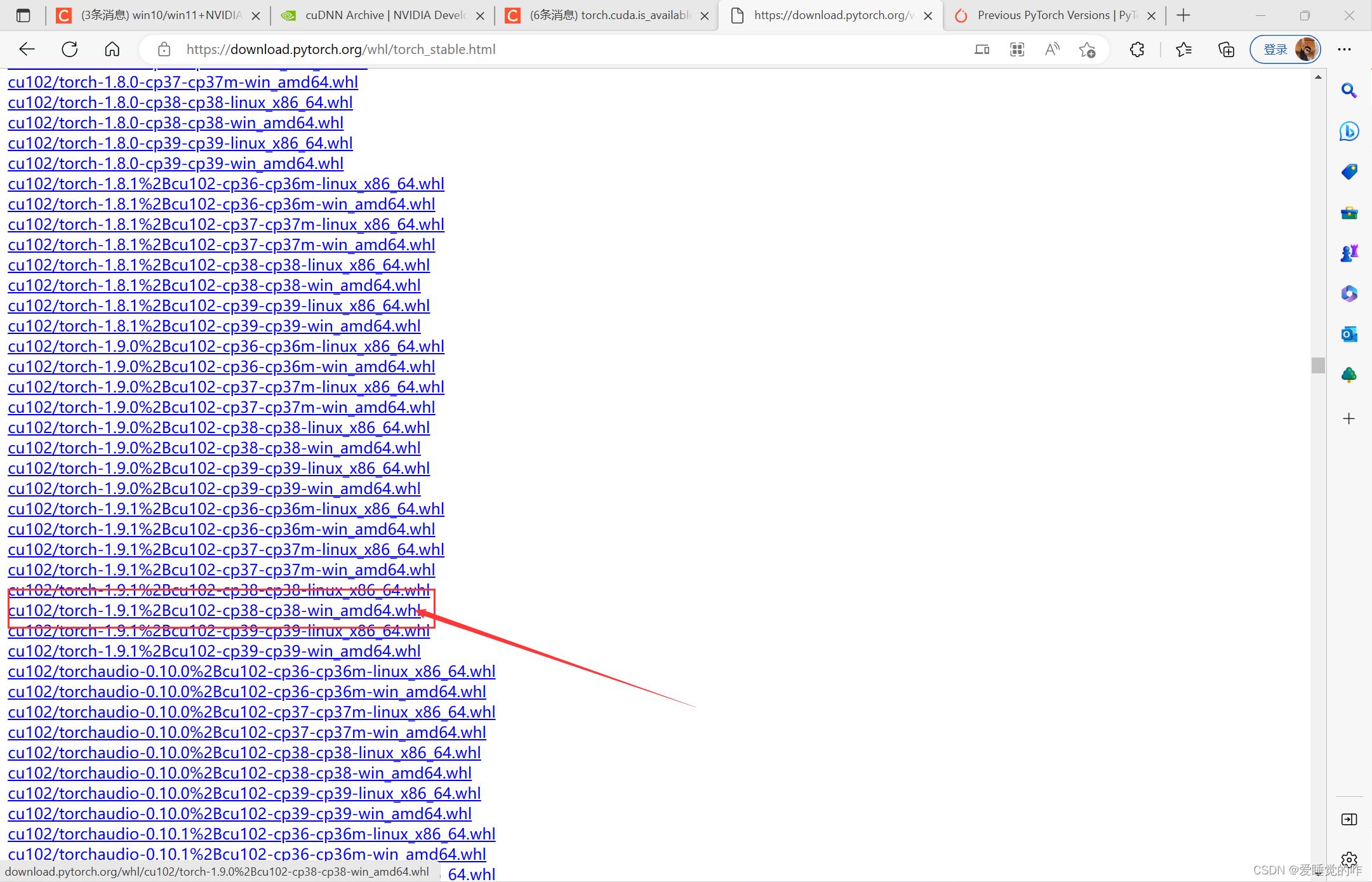
如果没有对应的适配windows的文件包,这时候就可以去下载和自己cuda版本适配的较低版本的torch的搭配,记住版本号然后再去下载!
先用conda创建虚拟环境,win + R cmd进入控制台
conda create -n Pytorch-Gpu python=3.8
conda activate Pytorch-Gpu 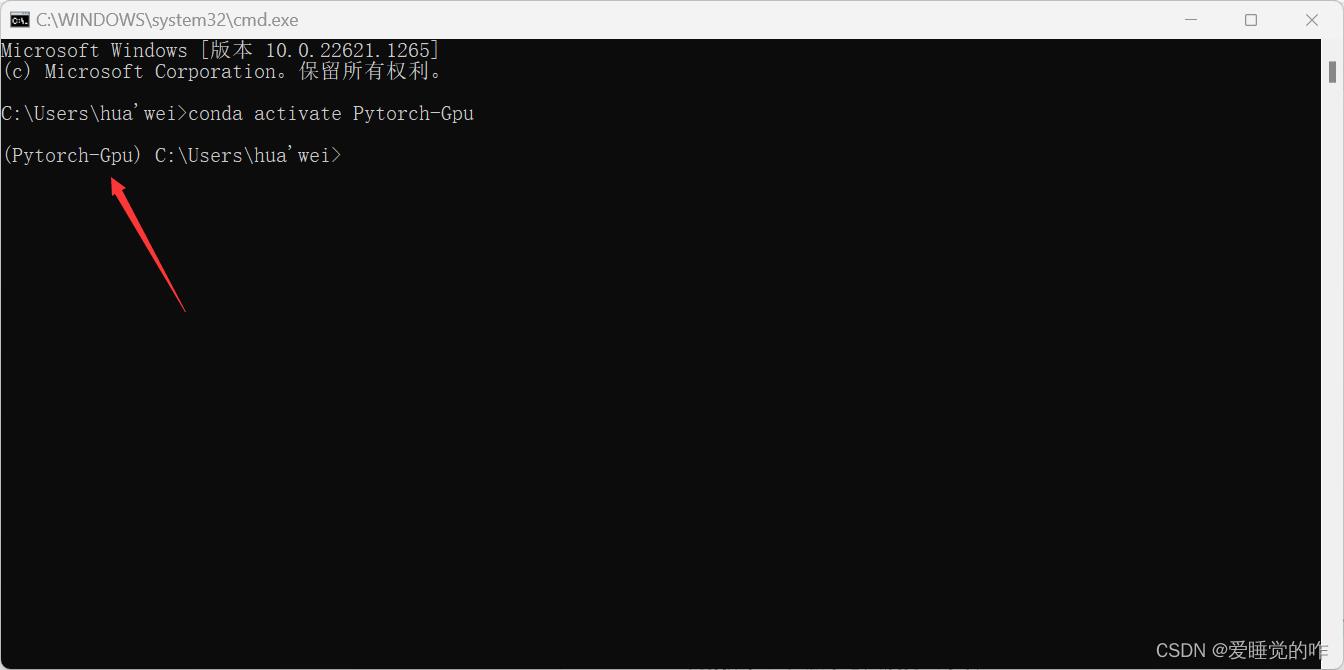
在刚才的虚拟环境中安装之前下载好的.whl文件,先安装torch的.whl文件,再安装另外两个。
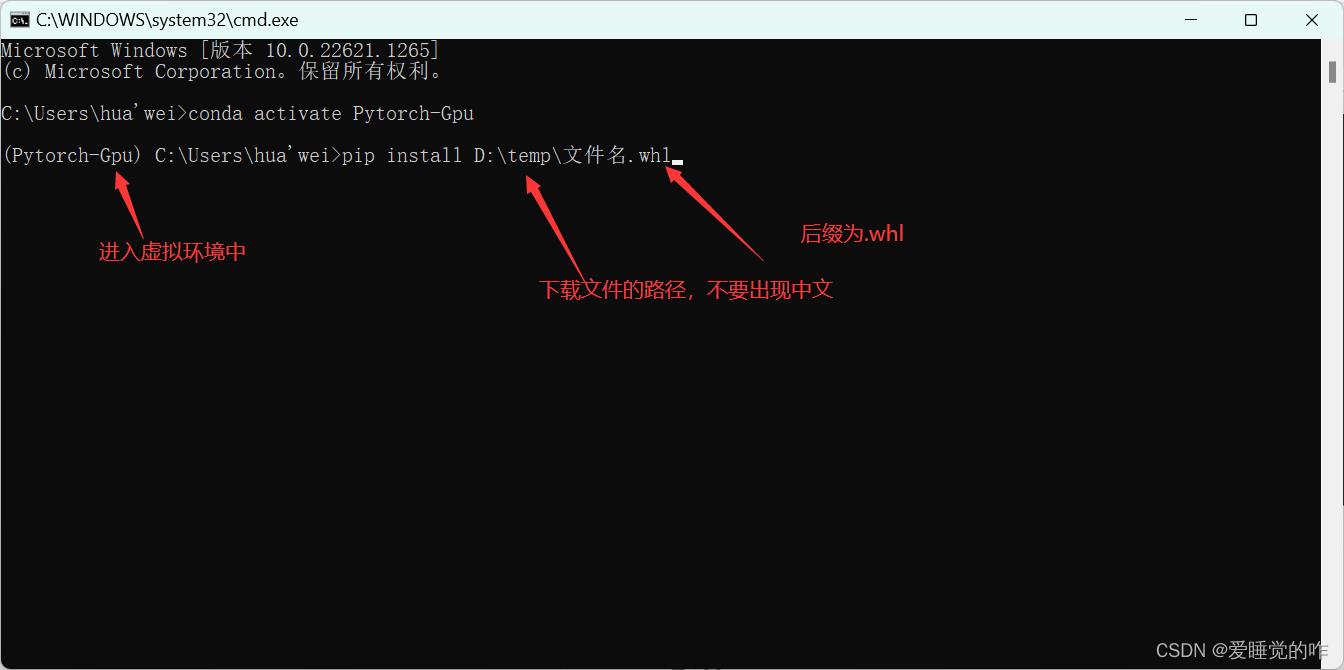
至此,Pytorch的环境就算安装完成了,可以在控制台进行测试!
win+R cmd 进入控制台,先激活虚拟环境:
conda activate Pytorch-Gpu进入Python,导入torch库,查看cuda是否能用:
import torch
print(torch.cuda.is_available())
print(torch.__version__)
print(torch.version.cuda)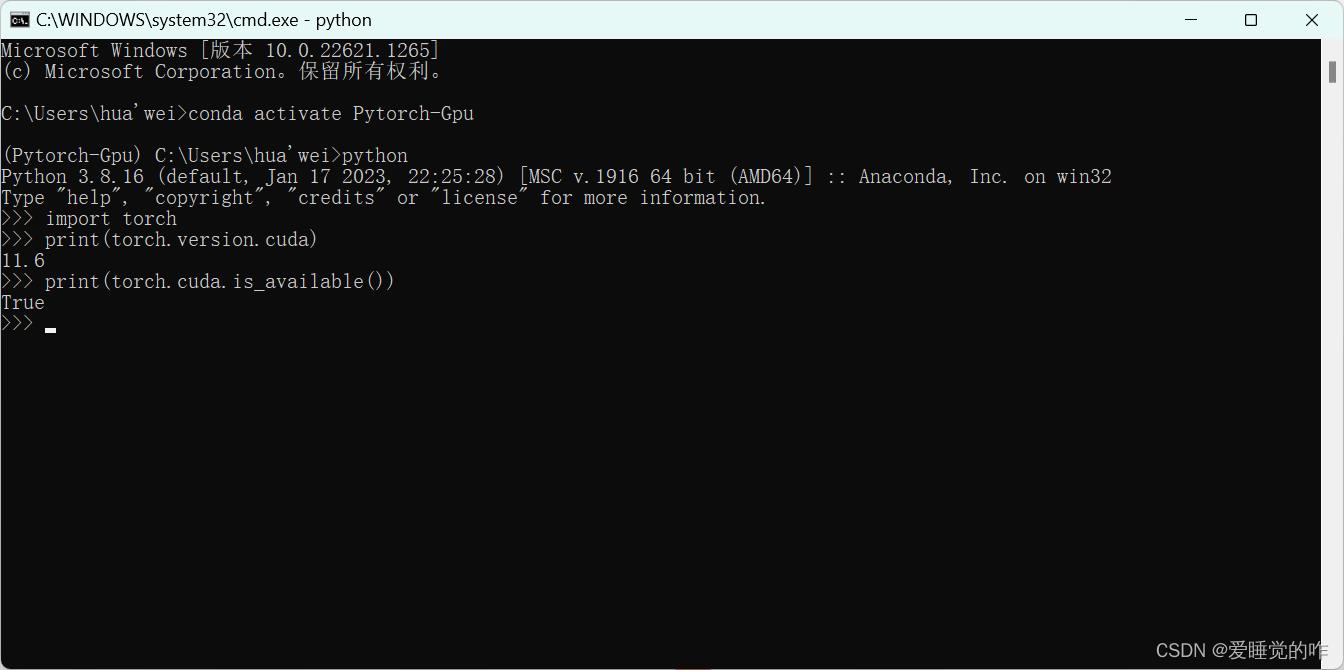
True了,说明已经成功安装了!至此Pytorch就算完成安装了。
6.pycharm切换不了环境问题
我本以为完成上一步就算是打工告成了,现在虚拟环境已经能用了,只要用Pycharm选择这个虚拟环境就可以了,但我万万没想到,这个虚拟环境怎么也切换不过去!如果你出现了我上述这种情况,那么可以借鉴我下面这种做法。
之前我们在cmd控制台能够正常运行,那么在pycharm的终端也应该可以,所有在Pycharm首先激活
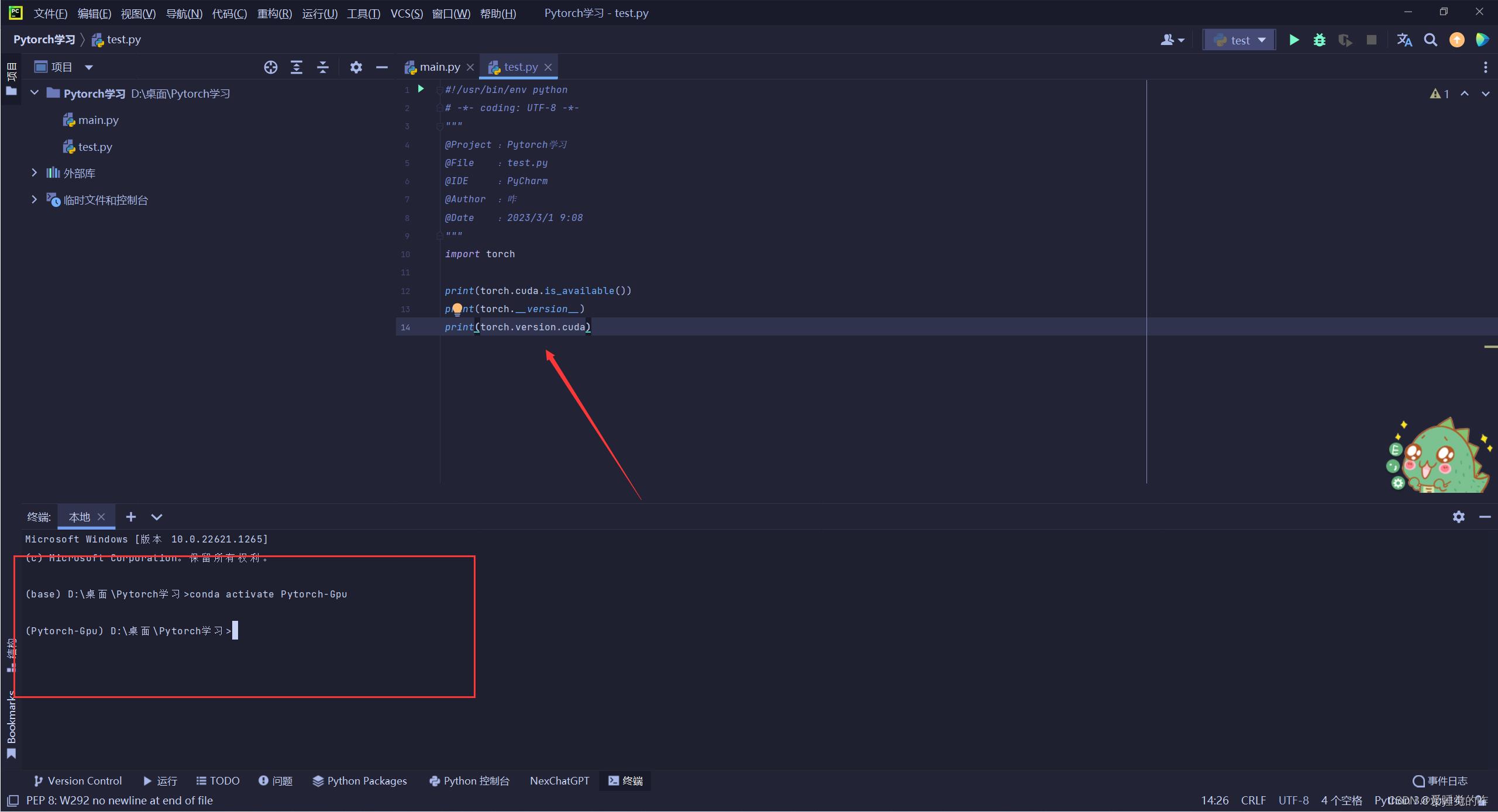
再运行一下,True了,说明没问题了! 出现这个问题可能是因为我在安装的时候选择的cuda版本超过了支持的cuda版本,后面我也会重新创建一个环境再走一遍流程的!
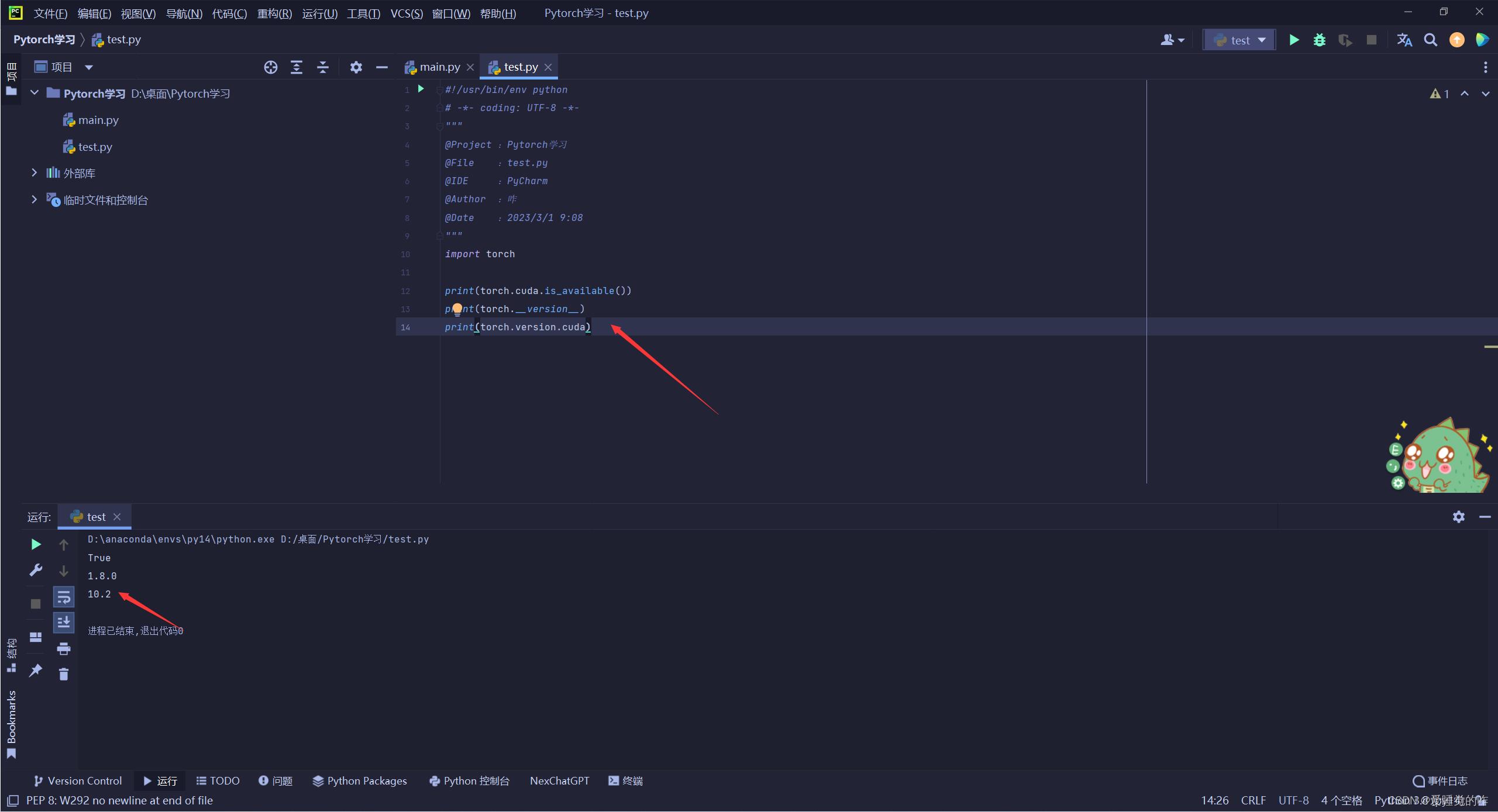
7.总结
这篇博客可谓是良心制作!一步一步,自己感觉很详细,质量也很高,算是对配置Pytorch深度学习环境的一个总结!大部分人想学编程都被配置环境劝退,这个过程 难免会遇到各种各样的坑,但也正是这些坑让我们不断成长!希望这篇博客可以帮助到你,早日进军深度学习!
深度学习计算Pytorch-GPU计算
GPU计算
到目前为止,我们一直在使用CPU计算。对复杂的神经网络和大规模的数据来说,使用CPU来计算可能不够高效。在本节中,我们将介绍如何使用单块NVIDIA GPU来计算。所以需要确保已经安装好了PyTorch GPU版本。
GPU版本安装
请参考:PyTorch 最新安装教程(2021-07-27)
查看显卡信息
准备工作都完成后,下面就可以通过nvidia-smi命令来查看显卡信息了。
!nvidia-smi # 对Linux/macOS用户有效
输出:
Sun Mar 17 14:59:57 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 390.48 Driver Version: 390.48 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 1050 Off | 00000000:01:00.0 Off | N/A |
| 20% 36C P5 N/A / 75W | 1223MiB / 2000MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1235 G /usr/lib/xorg/Xorg 434MiB |
| 0 2095 G compiz 163MiB |
| 0 2660 G /opt/teamviewer/tv_bin/TeamViewer 5MiB |
| 0 4166 G /proc/self/exe 416MiB |
| 0 13274 C /home/tss/anaconda3/bin/python 191MiB |
+-----------------------------------------------------------------------------+
可以看到我这里只有一块GTX 1050,显存一共只有2000M(太惨了😭)。
Windows请参考:如何查看Win11的CUDA版本
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 462.42 Driver Version: 462.42 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce MX250 WDDM | 00000000:01:00.0 Off | N/A |
| N/A 29C P0 N/A / N/A | 64MiB / 2048MiB | 1% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
这是我的电脑,低端显卡MX系列(* ̄︶ ̄)
计算设备
PyTorch可以指定用来存储和计算的设备,如使用内存的CPU或者使用显存的GPU。默认情况下,PyTorch会将数据创建在内存,然后利用CPU来计算。
用torch.cuda.is_available()查看GPU是否可用:
import torch
from torch import nn
torch.cuda.is_available() # 输出 True
查看GPU数量:
torch.cuda.device_count() # 输出 1
查看当前GPU索引号,索引号从0开始:
torch.cuda.current_device() # 输出 0
根据索引号查看GPU名字:
torch.cuda.get_device_name(0) # 输出 'GeForce GTX 1050'
Tensor的GPU计算
默认情况下,Tensor会被存在内存上。因此,之前我们每次打印Tensor的时候看不到GPU相关标识。
x = torch.tensor([1, 2, 3])
x
输出:
tensor([1, 2, 3])
使用.cuda()可以将CPU上的Tensor转换(复制)到GPU上。如果有多块GPU,我们用.cuda(i)来表示第
i
i
i 块GPU及相应的显存(
i
i
i从0开始)且cuda(0)和cuda()等价。
x = x.cuda(0)
x
输出:
tensor([1, 2, 3], device='cuda:0')
我们可以通过Tensor的device属性来查看该Tensor所在的设备。
x.device
输出:
device(type='cuda', index=0)
我们可以直接在创建的时候就指定设备。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
x = torch.tensor([1, 2, 3], device=device)
# or
x = torch.tensor([1, 2, 3]).to(device)
x
输出:
tensor([1, 2, 3], device='cuda:0')
如果对在GPU上的数据进行运算,那么结果还是存放在GPU上。
y = x**2
y
输出:
tensor([1, 4, 9], device='cuda:0')
需要注意的是,存储在不同位置中的数据是不可以直接进行计算的。即存放在CPU上的数据不可以直接与存放在GPU上的数据进行运算,位于不同GPU上的数据也是不能直接进行计算的。
z = y + x.cpu()
会报错:
RuntimeError: Expected object of type torch.cuda.LongTensor but found type torch.LongTensor for argument #3 'other'
模型的GPU计算
同Tensor类似,PyTorch模型也可以通过.cuda转换到GPU上。我们可以通过检查模型的参数的device属性来查看存放模型的设备。
net = nn.Linear(3, 1)
list(net.parameters())[0].device
输出:
device(type='cpu')
可见模型在CPU上,将其转换到GPU上:
net.cuda()
list(net.parameters())[0].device
输出:
device(type='cuda', index=0)
同样的,我么需要保证模型输入的Tensor和模型都在同一设备上,否则会报错。
x = torch.rand(2,3).cuda()
net(x)
输出:
tensor([[-0.5800],
[-0.2995]], device='cuda:0', grad_fn=<ThAddmmBackward>)
小结
- PyTorch可以指定用来存储和计算的设备,如使用内存的CPU或者使用显存的GPU。在默认情况下,PyTorch会将数据创建在内存,然后利用CPU来计算。
- PyTorch要求计算的所有输入数据都在内存或同一块显卡的显存上。
注:本节与原书此节有一些不同,原书传送门
本人出于学习的目的,引用本书内容,非商业用途,推荐大家阅读此书,一起学习!!!
加油!
感谢!
努力!
以上是关于深度学习第一步——Pytorch-Gpu环境配置:Win11/Win10+Cuda10.2+cuDNN8.5.0+Pytorch1.8.0(步步巨细,少走十年弯路)的主要内容,如果未能解决你的问题,请参考以下文章