《SpringBoot篇》26.SpringBoot整合Jackson超详细教程(附Jackson工具类)
Posted 陈老老老板
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《SpringBoot篇》26.SpringBoot整合Jackson超详细教程(附Jackson工具类)相关的知识,希望对你有一定的参考价值。
陈老老老板🦸 👨💻本文专栏:SpringBoot篇(主要讲一些与springboot整合相关的内容)
👨💻本文简述:本文讲一下Jackson常见用法,超级详细。
👨💻上一篇文章: 《SpringBoot篇》25.SpringBoot整合ActiveMQ
👨💻有任何问题,都可以私聊我,我能帮得上的一定帮忙,感谢大佬们支持。
🦹我认为人人都可以学好编程,我愿意成为你的领路人!(需内推私聊)

一、Jackson简介
说明:本篇讲的是Jackson的详细用法,Jackson工具类在文章最后,直接复制粘贴即可使用。 Jackson是公司中必用的组件之一,常用的还用阿里的Fastjson,但是由于一些原因bug与漏洞是在是太多,在注重安全的公司直接被pass,还有就是谷歌的Gson(这个没用过不太了解)。 Spring MVC 的默认 json 解析器便是 Jackson。 Jackson 优点很多。 Jackson 所依赖的 jar 包较少 ,简单易用。与其他 Java 的 json 的框架 Gson 等相比, Jackson 解析大的 json 文件速度比较快;Jackson 运行时占用内存比较低,性能比较好;Jackson 有灵活的 API,可以很容易进行扩展和定制。
额外了解:
Jackson 的 1.x 版本的包名是 org.codehaus.jackson ,
当升级到 2.x 版本时,包名变为com.fasterxml.jackson。
Jackson 有三个核心包,分别是 Streaming、Databid、Annotations,通过这些包可以方便的对 JSON 进行操作.
jackson-core:核心包,提供基于"流模式"解析的相关 API,它包括 JsonPaser 和 JsonGenerator。 Jackson 内部实现正是通过高性能的流模式 API 的 JsonGenerator 和 JsonParser 来生成和解析 json。jackson-annotations:注解包,提供标准注解功能.jackson-databind:数据绑定包, 提供基于"对象绑定" 解析的相关 API ( ObjectMapper ) 和"树模型" 解析的相关 API (JsonNode);基于"对象绑定" 解析的 API 和"树模型"解析的 API 依赖基于"流模式"解析的 API。包含上面两个包,只导入这个坐标即可。
运行环境:
idea2020.2jdk1.8springboot 2.7.9
下载demo:直接去我的资源下载即可(Jackson实例-附工具类)
二、Json简介
说明: 作为Java开发一定要学习Json,在现在的前后端分离的项目中,Json是最常见的数据交换格式。比如SpringBoot中@RequestBody注解就是作为接收Json格式的注解,在使用Postman进行测试时传输的raw-json也是Json格式数据。
JSON表示结构:
对象数组: 对象结构以””大括号开始,以””大括号结束,中间部分由0或多个以”,”分隔的”key(关键字)/value(值)”对构成,关键字和值之间以”:”分隔,语法结构如代码。这里给一个示例。
"array": [1,2,3],
"boolean": true,
"name": "cllb",
"null": null,
"age": 12345,
"object":
"height": 100,
"color": "红色"
,
"string": "陈老老老板"
三、springboot整合Jackson
1.创建项目
说明: 创建一个空springboot项目(2.7.9版本)。这里就不过多复述了,创建时将lombok组件选上,十分方便无需再写Get/Set方法。
注意:可以看到导入databind包会自动导入剩下两个包。
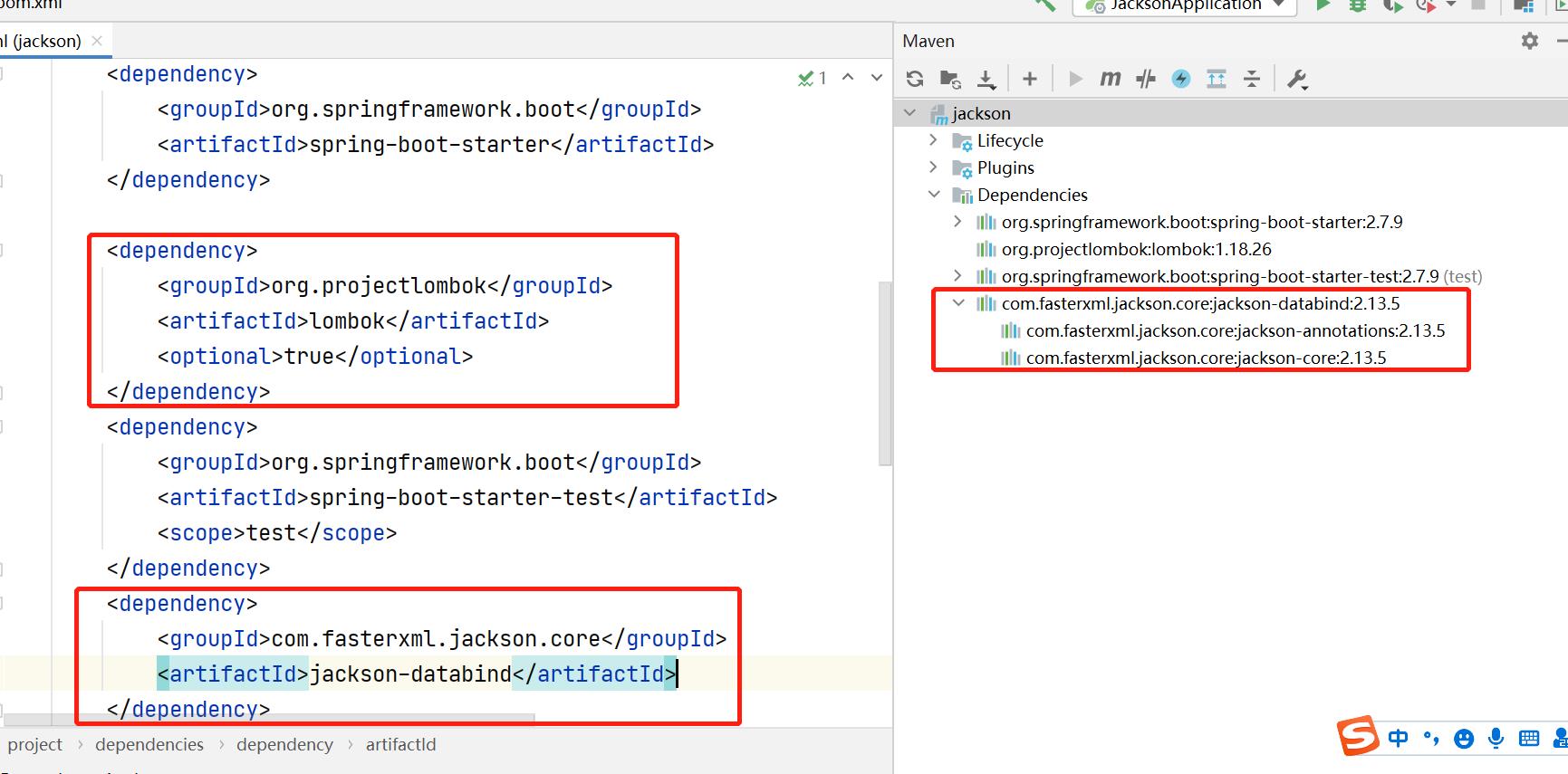
2.导入坐标
说明: 可以看到导入databind包会自动导入剩下两个包。
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.13.3</version>
</dependency>
3.配置文件
a.配置文件配置
properties格式:
#指定日期格式,比如yyyy-MM-dd HH:mm:ss,或者具体的格式化类的全限定名
spring.jackson.date-format
#指定日期格式化时区,比如America/Los_Angeles或者GMT+10.
spring.jackson.time-zone
#是否开启Jackson的反序列化
spring.jackson.deserialization
#是否开启json的generators.
spring.jackson.generator
#指定Joda date/time的格式,比如yyyy-MM-ddHH:mm:ss). 如果没有配置的话,dateformat会作为backup
spring.jackson.joda-date-time-format
#指定json使用的Locale.
spring.jackson.locale
#是否开启Jackson通用的特性.
spring.jackson.mapper
#是否开启jackson的parser特性.
spring.jackson.parser
#指定PropertyNamingStrategy(CAMEL_CASE_TO_LOWER_CASE_WITH_UNDERSCORES)或者指定PropertyNamingStrategy子类的全限定类名.
spring.jackson.property-naming-strategy
#是否开启jackson的序列化.
spring.jackson.serialization
#指定序列化时属性的inclusion方式,具体查看JsonInclude.Include枚举.
spring.jackson.serialization-inclusion
yml格式:
spring:
jackson:
#日期格式化
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
#设置空如何序列化
default-property-inclusion: non_null
serialization:
#格式化输出
indent_output: true
#忽略无法转换的对象
fail_on_empty_beans: false
deserialization:
#允许对象忽略json中不存在的属性
fail_on_unknown_properties: false
parser:
#允许出现特殊字符和转义符
allow_unquoted_control_chars: true
#允许出现单引号
allow_single_quotes: true
b.自定义配置
说明: 这里直接将Jackson工具类给大家,自定义配置指的就是工具类中,对于object_mapper的set赋值。什么方法都有,演示也直接使用工具类进行。
package com.clllb.jackson.utils;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.*;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.StringUtils;
import java.io.File;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.List;
@Slf4j
public class JacksonUtil
private static final ObjectMapper OBJECT_MAPPER = new ObjectMapper();
private static final ObjectMapper OBJECT_MAPPER_SNAKE_CASE = new ObjectMapper();
// 日期格式化
private static final String STANDARD_FORMAT = "yyyy-MM-dd HH:mm:ss";
static
//对象的所有字段全部列入
OBJECT_MAPPER.setSerializationInclusion(JsonInclude.Include.ALWAYS);
//取消默认转换timestamps形式
OBJECT_MAPPER.configure(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS, false);
//忽略空Bean转json的错误
OBJECT_MAPPER.configure(SerializationFeature.FAIL_ON_EMPTY_BEANS, false);
//所有的日期格式都统一为以下的样式,即yyyy-MM-dd HH:mm:ss
OBJECT_MAPPER.setDateFormat(new SimpleDateFormat(STANDARD_FORMAT));
//忽略 在json字符串中存在,但是在java对象中不存在对应属性的情况。防止错误
OBJECT_MAPPER.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
static
//对象的所有字段全部列入
OBJECT_MAPPER_SNAKE_CASE.setSerializationInclusion(JsonInclude.Include.ALWAYS);
//取消默认转换timestamps形式
OBJECT_MAPPER_SNAKE_CASE.configure(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS, false);
//忽略空Bean转json的错误
OBJECT_MAPPER_SNAKE_CASE.configure(SerializationFeature.FAIL_ON_EMPTY_BEANS, false);
//所有的日期格式都统一为以下的样式,即yyyy-MM-dd HH:mm:ss
OBJECT_MAPPER_SNAKE_CASE.setDateFormat(new SimpleDateFormat(STANDARD_FORMAT));
//忽略 在json字符串中存在,但是在java对象中不存在对应属性的情况。防止错误
OBJECT_MAPPER_SNAKE_CASE.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
//转换为下划线
OBJECT_MAPPER_SNAKE_CASE.setPropertyNamingStrategy(PropertyNamingStrategies.SNAKE_CASE);
private JacksonUtil()
/**
* 对象转Json格式字符串
*
* @param obj 对象
* @return Json格式字符串
*/
public static <T> String obj2String(T obj)
if (obj == null)
return null;
try
return obj instanceof String ? (String) obj : OBJECT_MAPPER.writeValueAsString(obj);
catch (JsonProcessingException e)
log.warn("Parse Object to String error : ", e.getMessage());
return null;
/**
* 对象转file
* @param fileName
* @param obj
*/
public static void obj2File(String fileName,Object obj)
if (obj == null)
return;
try
OBJECT_MAPPER.writeValue(new File(fileName),obj);
catch (IOException e)
e.printStackTrace();
/**
* 对象转Json格式字符串; 属性名从驼峰改为下划线形式
*
* @param obj 对象
* @return Json格式字符串
*/
public static <T> String obj2StringFieldSnakeCase(T obj)
if (obj == null)
return null;
try
ObjectMapper objectMapper = OBJECT_MAPPER_SNAKE_CASE;
return obj instanceof String ? (String) obj : objectMapper.writeValueAsString(obj);
catch (JsonProcessingException e)
log.warn("Parse Object to String error : ", e.getMessage());
return null;
/**
* 字符串转换为自定义对象; 属性名从下划线形式改为驼峰
*
* @param str 要转换的字符串
* @param clazz 自定义对象的class对象
* @return 自定义对象
*/
public static <T> T string2ObjFieldLowerCamelCase(String str, Class<T> clazz)
if (StringUtils.isEmpty(str) || clazz == null)
return null;
try
ObjectMapper objectMapper = OBJECT_MAPPER_SNAKE_CASE;
return clazz.equals(String.class) ? (T) str : objectMapper.readValue(str, clazz);
catch (Exception e)
log.warn("Parse String to Object error : ", e.getMessage());
return null;
/**
* 字符串转换为自定义对象(List); 属性名从下划线形式改为驼峰
*
* @param str 要转换的字符串
* @param typeReference 自定义对象的typeReference List 对象
* @return 自定义对象
*/
public static <T> List<T> string2ListFieldLowerCamelCase(String str, TypeReference<List<T>> typeReference)
if (StringUtils.isEmpty(str) || typeReference == null)
return null;
try
ObjectMapper objectMapper = OBJECT_MAPPER_SNAKE_CASE;
return objectMapper.readValue(str, typeReference);
catch (Exception e)
log.warn("Parse String to Object error : ", e.getMessage());
return null;
/**
* 对象转Json格式字符串(格式化的Json字符串)
*
* @param obj 对象
* @return 美化的Json格式字符串
*/
public static <T> String obj2StringPretty(T obj)
if (obj == null)
return null;
try
return obj instanceof String ? (String) obj : OBJECT_MAPPER.writerWithDefaultPrettyPrinter().writeValueAsString(obj);
catch (JsonProcessingException e)
log.warn("Parse Object to String error : ", e.getMessage());
return null;
/**
* 字符串转换为自定义对象
*
* @param str 要转换的字符串
* @param clazz 自定义对象的class对象
* @return 自定义对象
*/
public static <T> T string2Obj(String str, Class<T> clazz)
if (StringUtils.isEmpty(str) || clazz == null)
return null;
try
return clazz.equals(String.class) ? (T) str : OBJECT_MAPPER.readValue(str, clazz);
catch (Exception e)
log.warn("Parse String to Object error : ", e.getMessage());
return null;
/**
* 字符串转换为自定义字段转为list
* @param str
* @param typeReference
* @param <T>
* @return
*/
public static <T> T string2Obj(String str, TypeReference<T> typeReference)
if (StringUtils.isEmpty(str) || typeReference == null)
return null;
try
return (T) (typeReference.getType().equals(String.class) ? str : OBJECT_MAPPER.readValue(str, typeReference));
catch (IOException e)
log.warn("Parse String to Object error", e);
return null;
public static <T> T string2Obj(String str, Class<?> collectionClazz, Class<?>... elementClazzes)
JavaType javaType = OBJECT_MAPPER.getTypeFactory().constructParametricType(collectionClazz, elementClazzes);
try
return OBJECT_MAPPER.readValue(str, javaType);
catch (IOException e)
log.warn("Parse String to Object error : " + e.getMessage());
return null;
4.实体类
说明: 这里创建一个user实体类
package com.clllb.jackson.PO;
import lombok.Data;
import java.util.List;
@Data
public class User
private String username;
private Integer age;
private List<String> info;
private Long userId;
项目样图:
5.测试类
说明: 测试类中直接调工具类中的方法,非常简单,附输出结果。
a.object类型转Json
说明: 使用writeValueAsString方法
@Test
void obj2string()
User user = new User();
user.setUsername("clllb");
user.setAge(24);
user.setUserId(1L);
List<String> infoList = new ArrayList<>();
infoList.add("有一百万");
infoList.add("发大财");
user.setInfo(infoList);
String json = JacksonUtil.obj2String(user);
System.out.println(json);
输出结果:
"username":"clllb","age":24,"info":["有一百万","发大财"],"userId":1
b.object类型转file
说明: 使用writeValue方法
@Test
void obj2file()
User user = new User();
user.setUsername("clllb");
user.setAge(24);
user.setUserId(1L);
List<String> infoList = new ArrayList<>();
infoList.add("有一百万");
infoList.add("发大财");
user.setInfo(infoList);
String fileName = "ccccc";
JacksonUtil.obj2File(fileName,user);
输出结果:
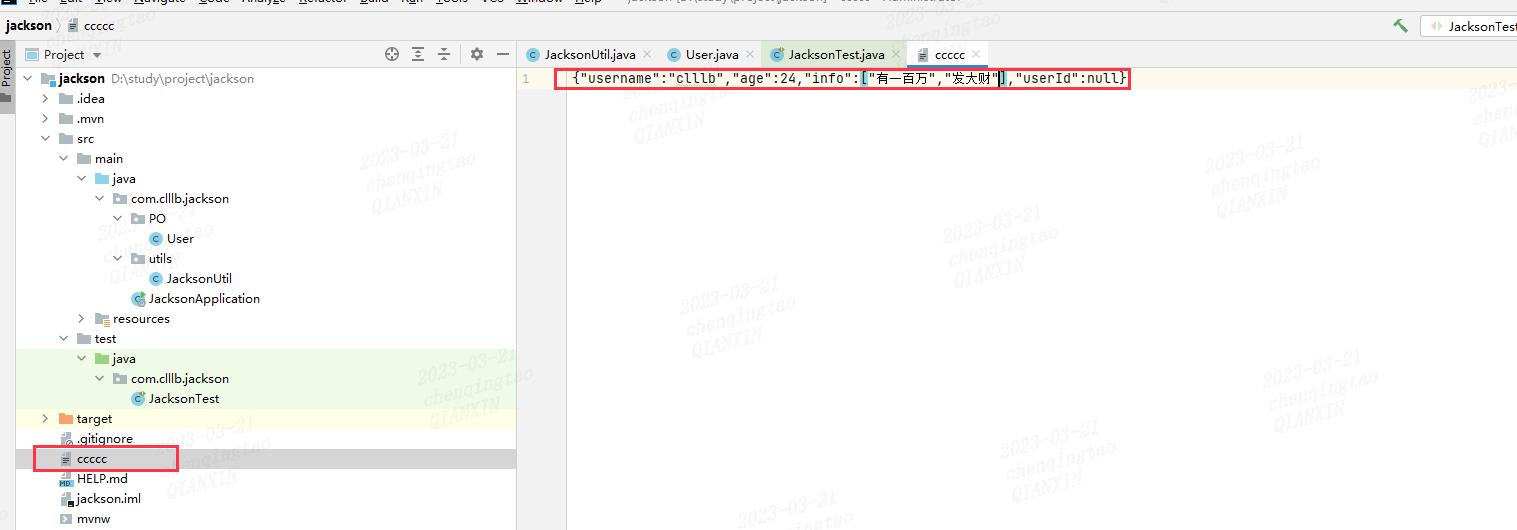
c.string类型转Object自定义类型
说明: 使用readValue方法
@Test
void string2obj()
String json = "\\"username\\":\\"clllb\\",\\"age\\":24,\\"info\\":[\\"有一百万\\",\\"发大财\\"],\\"userId\\":11";
User user = JacksonUtil.string2Obj(json, User.class);
System.out.println(user);
输出结果:
User(username=clllb如何分析SpringBoot源码模块及结构?--SpringBoot源码(二)
上一篇分析了SpringBoot源码结构及各个模块pom之间的关系后,那么此篇开始就开始解开SpringBoot新特性之一--自动配置的神秘面纱了。因为SpringBoot自动配置原理是基于其大量的条件注解ConditionalOnXXX,因此,本节我们先来撸下Spring的条件注解的相关源码。
2 SpringBoot的派生条件注解
我们都知道,SpringBoot自动配置是需要满足相应的条件才会自动配置,因此SpringBoot的自动配置大量应用了条件注解ConditionalOnXXX。如下图:

那么上图的条件注解如何使用呢?
举个栗子,我们来看下如何使用@ConditionalOnClass和@ConditionalOnProperty这两个注解,先看下图代码:

HelloWorldEnableAutoConfiguration这个自动配置类应用了@ConditionalOnClass和ConditionalOnProperty两个条件注解,那么只有在满足:classpath中存在HelloWorldComponent.class和配置了hello.world.name和hello.world.age属性这两个条件的情况下才会创建HelloWorldComponent这个bean。
其实SpringBoot的@ConditionalOnXXX等条件注解都是派生注解,那么什么是派生注解呢?
就拿上面的栗子来说,以@ConditionalOnClass(HelloWorldComponent.class)为例,我们打开ConditionalOnClass注解源码,如下:
@Target({ ElementType.TYPE, ElementType.METHOD })
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Conditional(OnClassCondition.class)
public @interface ConditionalOnClass {
Class<?>[] value() default {};
String[] name() default {};
}
可以看到@ConditionalOnClass注解上面又标注了@Conditional(OnClassCondition.class)注解,因此@ConditionalOnClass是@Conditional的派生注解,@Conditional(OnClassCondition.class)和@ConditionalOnClass注解是等价的,即这两个注解标注在某个配置类上的效果是等价的。
而SpringBoot的自动配置原理正是建立在这些大量的派生条件注解@ConditionalOnXXX之上,而这些条件注解的原理跟Spring的Condition接口有关。因此我们先来研究下Condition接口的相关源码。
3 Condition接口
3.1 Condition接口源码分析
分析Condition接口源码前先看下如何自定义ConditionalOnXXX注解,举个栗子,比如自定义一个@ConditionalOnLinux注解,该注解只有在其属性environment是"linux"才会创建相关的bean。定义了以下代码:
/**
* 实现spring 的Condition接口,并且重写matches()方法,如果@ConditionalOnLinux的注解属性environment是linux就返回true
*
*/
public class LinuxCondition implements Condition {
@Override
public boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata) {
// 获得注解@ConditionalOnLinux的所有属性
List<AnnotationAttributes> allAnnotationAttributes = annotationAttributesFromMultiValueMap(
metadata.getAllAnnotationAttributes(
ConditionalOnLinux.class.getName()));
for (AnnotationAttributes annotationAttributes : allAnnotationAttributes) {
// 获得注解@ConditionalOnLinux的environment属性
String environment = annotationAttributes.getString("environment");
// 若environment等于linux,则返回true
if ("linux".equals(environment)) {
return true;
}
}
return false;
}
}
@Target({ ElementType.TYPE, ElementType.METHOD })
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Conditional(LinuxCondition.class)
public @interface ConditionalOnLinux {
// 标注是哪个环境
String environment() default "";
}
@Configuration
public class ConditionConfig {
// 只有`@ConditionalOnLinux`的注解属性`environment`是"linux"时才会创建bean
@Bean
@ConditionalOnLinux(environment = "linux")
public Environment linuxEnvironment() {
return new LinuxEnvironment();
}
}
上面的代码我们捋一下:
LinuxCondition实现了Condition接口并实现了matches方法,而matches方法则判断@ConditionalOnLinux的注解属性environment是否"linux",是则返回true,否则false。- 然后我们再定义了一个注解
@ConditionalOnLinux,这个注解是@Conditional的派生注解,与@Conditional(LinuxCondition.class)等价,注意@ConditionalOnLinux注解定义了一个属性environment。而我们最终可以利用LinuxCondition的matches方法中的参数AnnotatedTypeMetadata来获取@ConditionalOnLinux的注解属性environment的值,从而用来判断值是否为linux"。
- 最后我们又定义了一个配置类
ConditionConfig,在linuxEnvironment方法上标注了@ConditionalOnLinux(environment = "linux")。因此,这里只有 LinuxCondition的matches方法返回true才会创建bean。
学会了如何自定义@ConditionalOnXXX注解后,我们现在再来看下Condition接口的源码:
@FunctionalInterface
public interface Condition {
boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata);
}
Condition接口主要有一个matches方法,该方法决定了是否要注册相应的bean对象。其中matches方法中有两个参数,参数类型分别是ConditionContext和AnnotatedTypeMetadata,这两个参数非常重要。它们分别用来获取一些环境信息和注解元数据从而用在matches方法中判断是否符合条件。
ConditionContext,顾名思义,主要是跟Condition的上下文有关,主要用来获取Registry,BeanFactory,Environment,ResourceLoader和ClassLoader等。那么获取这些用来干什么呢?举个栗子,比如OnResourceCondition需要靠ConditionContext来获取ResourceLoader来加载指定资源,OnClassCondition需要靠ConditionContext来获取ClassLoader来加载指定类等,下面看下其源码:
public interface ConditionContext {
BeanDefinitionRegistry getRegistry();
@Nullable
ConfigurableListableBeanFactory getBeanFactory();
Environment getEnvironment();
ResourceLoader getResourceLoader();
@Nullable
ClassLoader getClassLoader();
}
AnnotatedTypeMetadata,这个跟注解元数据有关,利用AnnotatedTypeMetadata可以拿到某个注解的一些元数据,而这些元数据就包含了某个注解里面的属性,比如前面的栗子,利用AnnotatedTypeMetadata可以拿到@ConditionalOnLinux的注解属性environment的值。下面看下其源码:
public interface AnnotatedTypeMetadata {
boolean isAnnotated(String annotationName);
Map<String, Object> getAnnotationAttributes(String annotationName);
Map<String, Object> getAnnotationAttributes(String annotationName, boolean classValuesAsString);
MultiValueMap<String, Object> getAllAnnotationAttributes(String annotationName);
MultiValueMap<String, Object> getAllAnnotationAttributes(String annotationName, boolean classValuesAsString);
}
回到刚才的栗子,我们知道@ConditionalOnLinux注解真正起作用的是Condition接口的具体实现类LinuxCondition的matches方法,那么这个matches方法是在何时被调用的呢?
通过idea调试看调用的栈帧,如下图:

发现是在ConditionEvaluator的shouldSkip方法中调用了LinuxCondition的matches方法,自然我们再去看看ConditionEvaluator的shouldSkip的方法执行了什么逻辑。
// 这个方法主要是如果是解析阶段则跳过,如果是注册阶段则不跳过
public boolean shouldSkip(@Nullable AnnotatedTypeMetadata metadata, @Nullable ConfigurationPhase phase) {
// 若没有被@Conditional或其派生注解所标注,则不会跳过
if (metadata == null || !metadata.isAnnotated(Conditional.class.getName())) {
return false;
}
// 没有指定phase,注意phase可以分为PARSE_CONFIGURATION或REGISTER_BEAN类型
if (phase == null) {
// 若标有@Component,@Import,@Bean或@Configuration等注解的话,则说明是PARSE_CONFIGURATION类型
if (metadata instanceof AnnotationMetadata &&
ConfigurationClassUtils.isConfigurationCandidate((AnnotationMetadata) metadata)) {
return shouldSkip(metadata, ConfigurationPhase.PARSE_CONFIGURATION);
}
// 否则是REGISTER_BEAN类型
return shouldSkip(metadata, ConfigurationPhase.REGISTER_BEAN);
}
List<Condition> conditions = new ArrayList<>();
// TODO 获得所有标有@Conditional注解或其派生注解里面的Condition接口实现类并实例化成对象。
// 比如@Conditional(OnBeanCondition.class)则获得OnBeanCondition.class,OnBeanCondition.class往往实现了Condition接口
for (String[] conditionClasses : getConditionClasses(metadata)) {
// 将类实例化成对象
for (String conditionClass : conditionClasses) {
Condition condition = getCondition(conditionClass, this.context.getClassLoader());
conditions.add(condition);
}
}
// 排序,即按照Condition的优先级进行排序
AnnotationAwareOrderComparator.sort(conditions);
for (Condition condition : conditions) {
ConfigurationPhase requiredPhase = null;
if (condition instanceof ConfigurationCondition) {
// 从condition中获得对bean是解析还是注册
requiredPhase = ((ConfigurationCondition) condition).getConfigurationPhase();
}
// 若requiredPhase为null或获取的阶段类型正是当前阶段类型且不符合condition的matches条件,则跳过
if ((requiredPhase == null || requiredPhase == phase) && !condition.matches(this.context, metadata)) {
return true;
}
}
return false;
}
shouldSkip这个方法执行的逻辑主要是如果是解析阶段则跳过,如果是注册阶段则不跳过;如果是在注册阶段即REGISTER_BEAN阶段的话,此时会得到所有的Condition接口的具体实现类并实例化这些实现类,然后再执行下面关键的代码进行判断是否需要跳过。
if ((requiredPhase == null || requiredPhase == phase) && !condition.matches(this.context, metadata)) {
return true;
}
上面代码最重要的逻辑是调用了Condition接口的具体实现类的matches方法,若matches返回false,则跳过,不进行注册bean的操作;若matches返回true,则不跳过,进行注册bean的操作;
好了,Condition的源码分析就到此为止,再往上翻调用方法的话应该就是Spring加载bean定义的相关源码了,不属于这里的分析范围。
3.2 Spring的内置Condition接口实现类
前面我们学会了如何自定义条件注解及Condition的源码分析,那么我们不禁好奇,Spring究竟内置了哪些Condition接口的实现类呢?
那么看下Spring的Condition接口的具体实现类的类图:

发现Spring内置的Condition接口的具体实现类虽然有多个,但只有ProfileCondition不是测试相关的,因此可以说真正的内置的Condition接口的具体实现类只有ProfileCondition一个,非常非常少,这跟SpringBoot的大量派生条件注解形成了鲜明的对比。ProfileCondition大家都知道,是跟环境有关,比如我们平时一般有dev,test和prod环境,而ProfileCondition就是判断我们项目配置了哪个环境的。下面是ProfileCondition的源码,很简单,这里就不分析了。
class ProfileCondition implements Condition {
@Override
public boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata) {
MultiValueMap<String, Object> attrs = metadata.getAllAnnotationAttributes(Profile.class.getName());
if (attrs != null) {
for (Object value : attrs.get("value")) {
if (context.getEnvironment().acceptsProfiles(Profiles.of((String[]) value))) {
return true;
}
}
return false;
}
return true;
}
}
4 SpringBootCondition源码解析
前面看到Spring对Condition的内置注解可以说只有ProfileCondition一个,但是我们都知道,SpringBoot则内置了大量的条件注解ConditionalOnXXX。在分析前,我们先来看一下SpringBootCondition的整体类图来个整体的理解,如下图:

可以看到SpringBootCondition作为SpringBoot条件注解的基类,处于整个类图的中心,它实现了Condition接口,然后又有很多具体的子类OnXXXCondition,这些OnXXXCondition其实就是@ConditionalOnXXX的条件类。
我们先来看下SpringBootCondition这个父类是主要做了哪些事情,抽象了哪些共有的逻辑?
SpringBootConditon实现了Condition接口,作为SpringBoot众多条件注解OnXXXCondtion的父类,它的作用主要就是打印一些条件注解评估报告的日志,比如打印哪些配置类是符合条件注解的,哪些是不符合的。打印的日志形式如下图:


因为SpringBootConditon实现了Condition接口,也实现了matches方法,因此该方法同样也是被ConditionEvaluator的shouldSkip方法中调用,因此我们就以SpringBootConditon的matches方法为入口去进行分析。直接上代码:
// SpringBootCondition.java
public final boolean matches(ConditionContext context,
AnnotatedTypeMetadata metadata) {
// 得到metadata的类名或方法名
String classOrMethodName = getClassOrMethodName(metadata);
try {
// 判断每个配置类的每个条件注解@ConditionalOnXXX是否满足条件,然后记录到ConditionOutcome结果中
// 注意getMatchOutcome是一个抽象模板方法,交给OnXXXCondition子类去实现
ConditionOutcome outcome = getMatchOutcome(context, metadata);
// 打印condition评估的日志,哪些条件注解@ConditionalOnXXX是满足条件的,哪些是不满足条件的,这些日志都打印出来
logOutcome(classOrMethodName, outcome);
// 除了打印日志外,这些是否匹配的信息还要记录到ConditionEvaluationReport中
recordEvaluation(context, classOrMethodName, outcome);
// 最后返回@ConditionalOnXXX是否满足条件
return outcome.isMatch();
}
catch (NoClassDefFoundError ex) {
throw new IllegalStateException(
"Could not evaluate condition on " + classOrMethodName + " due to "
+ ex.getMessage() + " not "
+ "found. Make sure your own configuration does not rely on "
+ "that class. This can also happen if you are "
+ "@ComponentScanning a springframework package (e.g. if you "
+ "put a @ComponentScan in the default package by mistake)",
ex);
}
catch (RuntimeException ex) {
throw new IllegalStateException(
"Error processing condition on " + getName(metadata), ex);
}
}
上面代码的注释已经非常详细,我们知道了SpringBootCondition抽象了所有其具体实现类OnXXXCondition的共有逻辑--condition评估信息打印,最重要的是封装了一个模板方法getMatchOutcome(context, metadata),留给各个OnXXXCondition具体子类去覆盖实现属于自己的判断逻辑,然后再返回相应的匹配结果给SpringBootCondition用于日志打印。
因此我们知道了SpringBootCondition其实就是用来打印condition评估信息的,对于其他枝节方法我们不必追究过深,免得丢了主线。我们现在的重点是放在交给OnXXXCondition子类实现的模板方法上getMatchOutcome(context, metadata);,因为这个方法将会由很多OnXXXCondition覆盖重写判断逻辑,这里是我们接下来分析的重点。
因为SpringBootCondition有众多具体实现类,下面只挑OnResourceCondition,OnBeanCondition和OnWebApplicationCondition进行讲解,而AutoConfigurationImportFilter跟自动配置有关,则留到自动配置源码解析的时候再进行分析。
4.1 OnResourceCondition源码分析
现在先来看下一个逻辑及其简单的注解条件类OnResourceCondition,OnResourceCondition继承了SpringBootCondition父类,覆盖了其getMatchOutcome方法,用于@ConditionalOnResource注解指定的资源存在与否。OnResourceCondition的判断逻辑非常简单,主要拿到@ConditionalOnResource注解指定的资源路径后,然后用ResourceLoader根据指定路径去加载看资源存不存在。下面直接看代码:
先来看下@ConditionalOnResource的代码,
@Target({ ElementType.TYPE, ElementType.METHOD })
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Conditional(OnResourceCondition.class)
public @interface ConditionalOnResource {
/**
* The resources that must be present.
* @return the resource paths that must be present.
*/
String[] resources() default {};
}
再来看OnResourceCondition的代码:
@Order(Ordered.HIGHEST_PRECEDENCE + 20)
class OnResourceCondition extends SpringBootCondition {
private final ResourceLoader defaultResourceLoader = new DefaultResourceLoader();
@Override
public ConditionOutcome getMatchOutcome(ConditionContext context,
AnnotatedTypeMetadata metadata) {
// 获得@ConditionalOnResource注解的属性元数据
MultiValueMap<String, Object> attributes = metadata
.getAllAnnotationAttributes(ConditionalOnResource.class.getName(), true);
// 获得资源加载器,若ConditionContext中有ResourceLoader则用ConditionContext中的,没有则用默认的
ResourceLoader loader = (context.getResourceLoader() != null)
? context.getResourceLoader() : this.defaultResourceLoader;
List<String> locations = new ArrayList<>();
// 将@ConditionalOnResource中定义的resources属性值取出来装进locations集合
collectValues(locations, attributes.get("resources"));
Assert.isTrue(!locations.isEmpty(),
"@ConditionalOnResource annotations must specify at "
+ "least one resource location");
// missing集合是装不存在指定资源的资源路径的
List<String> missing = new ArrayList<>();
// 遍历所有的资源路径,若指定的路径的资源不存在则将其资源路径存进missing集合中
for (String location : locations) {
// 这里针对有些资源路径是Placeholders的情况,即处理${}
String resource = context.getEnvironment().resolvePlaceholders(location);
if (!loader.getResource(resource).exists()) {
missing.add(location);
}
}
// 如果存在某个资源不存在,那么则报错
if (!missing.isEmpty()) {
return ConditionOutcome.noMatch(ConditionMessage
.forCondition(ConditionalOnResource.class)
.didNotFind("resource", "resources").items(Style.QUOTE, missing));
}
// 所有资源都存在,那么则返回能找到就提的资源
return ConditionOutcome
.match(ConditionMessage.forCondition(ConditionalOnResource.class)
.found("location", "locations").items(locations));
}
// 将@ConditionalOnResource中定义的resources属性值取出来装进locations集合
private void collectValues(List<String> names, List<Object> values) {
for (Object value : values) {
for (Object item : (Object[]) value) {
names.add((String) item);
}
}
}
}
可以看到OnResourceCondition的getMatchOutcome方法非常简单,这里不再详述。
4.2 OnBeanCondition源码分析
OnBeanCondition同样继承了FilteringSpringBootCondition父类,覆盖了父类FilteringSpringBootCondition的getOutcomes方法。而FilteringSpringBootCondition又是SpringBootCondition的子类,FilteringSpringBootCondition跟自动配置类过滤有关,这里先不分析。值得注意的是OnBeanCondition同样重写了SpringBootCondition的getMatchOutcome方法,用来判断Spring容器中是否存在指定条件的bean。同时是OnBeanCondition是@ConditionalOnBean,@ConditionalOnSingleCandidate和ConditionalOnMissingBean的条件类。
同样,先来看OnBeanCondition复写父类SpringBootCondition的getMatchOutcome方法的代码:
@Override
public ConditionOutcome getMatchOutcome(ConditionContext context,
AnnotatedTypeMetadata metadata) {
ConditionMessage matchMessage = ConditionMessage.empty();
// (1),配置类(metadata)标注@ConditionalOnBean注解的情况
if (metadata.isAnnotated(ConditionalOnBean.class.getName())) {
// 将@ConditionalOnBean注解属性封装进BeanSearchSpec对象中
// 注意BeanSearchSpec是一个静态内部类,用来存储@ConditionalOnBean和@ConditionalOnMissingBean注解的属性值
BeanSearchSpec spec = new BeanSearchSpec(context, metadata,
ConditionalOnBean.class);
// 调用getMatchingBeans得到符合条件的bean
MatchResult matchResult = getMatchingBeans(context, spec);
// 如果不匹配
if (!matchResult.isAllMatched()) {
String reason = createOnBeanNoMatchReason(matchResult);
return ConditionOutcome.noMatch(ConditionMessage
.forCondition(ConditionalOnBean.class, spec).because(reason));
}
// 如果匹配
matchMessage = matchMessage.andCondition(ConditionalOnBean.class, spec)
.found("bean", "beans")
.items(Style.QUOTE, matchResult.getNamesOfAllMatches());
}
// (2),配置类(metadata)标注@ConditionalOnSingleCandidate注解的情况
if (metadata.isAnnotated(ConditionalOnSingleCandidate.class.getName())) {
BeanSearchSpec spec = new SingleCandidateBeanSearchSpec(context, metadata,
ConditionalOnSingleCandidate.class);
MatchResult matchResult = getMatchingBeans(context, spec);
if (!matchResult.isAllMatched()) {
return ConditionOutcome.noMatch(ConditionMessage
.forCondition(ConditionalOnSingleCandidate.class, spec)
.didNotFind("any beans").atAll());
}
else if (!hasSingleAutowireCandidate(context.getBeanFactory(),
matchResult.getNamesOfAllMatches(),
spec.getStrategy() == SearchStrategy.ALL)) {
return ConditionOutcome.noMatch(ConditionMessage
.forCondition(ConditionalOnSingleCandidate.class, spec)
.didNotFind("a primary bean from beans")
.items(Style.QUOTE, matchResult.getNamesOfAllMatches()));
}
matchMessage = matchMessage
.andCondition(ConditionalOnSingleCandidate.class, spec)
.found("a primary bean from beans")
.items(Style.QUOTE, matchResult.getNamesOfAllMatches());
}
// (3),配置类(metadata)标注@ConditionalOnMissingBean注解的情况
if (metadata.isAnnotated(ConditionalOnMissingBean.class.getName())) {
BeanSearchSpec spec = new BeanSearchSpec(context, metadata,
ConditionalOnMissingBean.class);
MatchResult matchResult = getMatchingBeans(context, spec);
if (matchResult.isAnyMatched()) {
String reason = createOnMissingBeanNoMatchReason(matchResult);
return ConditionOutcome.noMatch(ConditionMessage
.forCondition(ConditionalOnMissingBean.class, spec)
.because(reason));
}
matchMessage = matchMessage.andCondition(ConditionalOnMissingBean.class, spec)
.didNotFind("any beans").atAll();
}
// 最终返回matchMessage
return ConditionOutcome.match(matchMessage);
}
我们可以看到OnBeanCondition类覆盖的getMatchOutcome方法分别处理了标注@ConditionalOnBean,@ConditionalOnSingleCandidate和@ConditionalOnMissingBean注解的情况,分别对应上面代码注释的(1),(2)和(3)处。
现在我们只看针对@ConditionalOnBean注解的处理逻辑,从上面代码中可以看到若配置类(metadata)标注@ConditionalOnBean注解的话,主要做了以下事情:
- 将该注解属性提取出来封装进
BeanSearchSpec对象中;
- 然后调用
getMatchingBeans(context, spec)方法来获取是否有匹配的bean;
- 最后返回
bean的匹配情况;
可以看到最重要的逻辑是第2步,那么我们再来看下getMatchingBeans方法,直接上代码:
protected final MatchResult getMatchingBeans(ConditionContext context,
BeanSearchSpec beans) {
// 获得Spring容器的beanFactory
ConfigurableListableBeanFactory beanFactory = context.getBeanFactory();
// 判断bean的搜索策略是否是SearchStrategy.ANCESTORS策略
if (beans.getStrategy() == SearchStrategy.ANCESTORS) {
BeanFactory parent = beanFactory.getParentBeanFactory();
Assert.isInstanceOf(ConfigurableListableBeanFactory.class, parent,
"Unable to use SearchStrategy.PARENTS");
beanFactory = (ConfigurableListableBeanFactory) parent;
}
// MatchResult用来存储bean的匹配结果
MatchResult matchResult = new MatchResult();
// 如果bean的搜索策略不是SearchStrategy.CURRENT的话,则置considerHierarchy为true
boolean considerHierarchy = beans.getStrategy() != SearchStrategy.CURRENT;
// 获取TypeExtractor,TypeExtractor是用来判断bean的类型的
TypeExtractor typeExtractor = beans.getTypeExtractor(context.getClassLoader());
// 获取是否有被忽略bean类型,若有的话将该bean类型的名称装进beansIgnoredByType集合
// 这里主要是针对@ConditionalOnMissingBean的ignored属性
List<String> beansIgnoredByType = getNamesOfBeansIgnoredByType(
beans.getIgnoredTypes(), typeExtractor, beanFactory, context,
considerHierarchy);
// 遍历bean的所有类型
for (String type : beans.getTypes()) {
// 调用getBeanNamesForType方法根据bean类型得到所有符合条件的bean类型,并放到typeMatches集合
Collection<String> typeMatches = getBeanNamesForType(beanFactory, type,
typeExtractor, context.getClassLoader(), considerHierarchy);
// 移除掉Ignored的类型
typeMatches.removeAll(beansIgnoredByType);
// 若typeMatches为空,那么则说明正在遍历的这个type类型不符合匹配条件,此时用matchResult记录一下这个不符合条件的类型
if (typeMatches.isEmpty()) {
matchResult.recordUnmatchedType(type);
}
// 若typeMatches不为空,那么则说明正在遍历的这个type类型符合匹配条件,此时用matchResult记录一下这个符合条件的类型
else {
matchResult.recordMatchedType(type, typeMatches);
}
}
// 这里针对@ConditionalOnBean等注解的annotation属性的处理
for (String annotation : beans.getAnnotations()) {
List<String> annotationMatches = Arrays
.asList(getBeanNamesForAnnotation(beanFactory, annotation,
context.getClassLoader(), considerHierarchy));
annotationMatches.removeAll(beansIgnoredByType);
if (annotationMatches.isEmpty()) {
matchResult.recordUnmatchedAnnotation(annotation);
}
else {
matchResult.recordMatchedAnnotation(annotation, annotationMatches);
}
}
// 这里针对@ConditionalOnBean等注解的name属性的处理
for (String beanName : beans.getNames()) {
// beansIgnoredByType集合不包含beanName且beanFactory包含这个bean,则匹配
if (!beansIgnoredByType.contains(beanName)
&& containsBean(beanFactory, beanName, considerHierarchy)) {
matchResult.recordMatchedName(beanName);
}
// 否则,不匹配
else {
matchResult.recordUnmatchedName(beanName);
}
}
// 最后返回匹配结果
return matchResult;
}
上面的逻辑主要是从spring容器中搜索有无指定条件的bean,搜索Spring容器搜索bean的话有三种搜索策略,分别是CURRENT,ANCESTORS和ALL,分表表示只从当前的context中搜索bean,只从父context中搜索bean和从整个context中搜索bean;定义了搜索策略后,然后再根据BeanSearchSpec对象封装的注解属性分别取指定的容器中查找有无符合条件的bean,然后再进行一些过滤。比如@ConditionalOnMissingBean注解有定义ignored属性值,那么从容器中搜索到有符合条件的bean时,此时还要移除掉ignored指定的bean。
好了,上面就已经分析了OnBeanCondition这个条件类了,我们坚持主线优先的原则,具体的细节代码不会深究。
4.3 OnWebApplicationCondition
OnWebApplicationCondition同样继承了FilteringSpringBootCondition父类,覆盖了父类FilteringSpringBootCondition的getOutcomes方法。而FilteringSpringBootCondition又是SpringBootCondition的子类,FilteringSpringBootCondition跟自动配置类过滤有关,这里先不分析。值得注意的是OnWebApplicationCondition同样重写了SpringBootCondition的getMatchOutcome方法,用来判断当前应用是否web应用。同时是OnWebApplicationCondition是@ConditionalOnWebApplication的条件类。
同样,先来看OnWebApplicationCondition重写SpringBootCondition的getMatchOutcome方法:
public ConditionOutcome getMatchOutcome(ConditionContext context,
AnnotatedTypeMetadata metadata) {
// 配置类是否标注有@ConditionalOnWebApplication注解
boolean required = metadata
.isAnnotated(ConditionalOnWebApplication.class.getName());
// 调用isWebApplication方法返回匹配结果
ConditionOutcome outcome = isWebApplication(context, metadata, required);
// 若有标注@ConditionalOnWebApplication但不符合条件,则返回不匹配
if (required && !outcome.isMatch()) {
return ConditionOutcome.noMatch(outcome.getConditionMessage());
}
// 若没有标注@ConditionalOnWebApplication但符合条件,则返回不匹配
if (!required && outcome.isMatch()) {
return ConditionOutcome.noMatch(outcome.getConditionMessage());
}
// 这里返回匹配的情况,TODO 不过有个疑问:如果没有标注@ConditionalOnWebApplication注解,又不符合条件的话,也会执行到这里,返回匹配?
return ConditionOutcome.match(outcome.getConditionMessage());
}
上面代码的逻辑很简单,主要是调用isWebApplication方法来判断当前应用是否是web应用。因此,我们再来看下isWebApplication方法:
private ConditionOutcome isWebApplication(ConditionContext context,
AnnotatedTypeMetadata metadata, boolean required) {
// 调用deduceType方法判断是哪种类型,其中有SERVLET,REACTIVE和ANY类型,其中ANY表示了SERVLET或REACTIVE类型
switch (deduceType(metadata)) {
// SERVLET类型
case SERVLET:
return isServletWebApplication(context);
// REACTIVE类型
case REACTIVE:
return isReactiveWebApplication(context);
default:
return isAnyWebApplication(context, required);
}
}
在isWebApplication方法中,首先从@ConditionalOnWebApplication注解中获取其定义了什么类型,然后根据不同的类型进入不同的判断逻辑。这里我们只看下SERVLET的情况判断处理,看代码:
private ConditionOutcome isServletWebApplication(ConditionContext context) {
ConditionMessage.Builder message = ConditionMessage.forCondition("");
// 若classpath中不存在org.springframework.web.context.support.GenericWebApplicationContext.class,则返回不匹配
if (!ClassNameFilter.isPresent(SERVLET_WEB_APPLICATION_CLASS,
context.getClassLoader())) {
return ConditionOutcome.noMatch(
message.didNotFind("servlet web application classes").atAll());
}
// 若classpath中存在org.springframework.web.context.support.GenericWebApplicationContext.class,那么又分为以下几种匹配的情况
// session
if (context.getBeanFactory() != null) {
String[] scopes = context.getBeanFactory().getRegisteredScopeNames();
if (ObjectUtils.containsElement(scopes, "session")) {
return ConditionOutcome.match(message.foundExactly("‘session‘ scope"));
}
}
// ConfigurableWebEnvironment
if (context.getEnvironment() instanceof ConfigurableWebEnvironment) {
return ConditionOutcome
.match(message.foundExactly("ConfigurableWebEnvironment"));
}
// WebApplicationContext
if (context.getResourceLoader() instanceof WebApplicationContext) {
return ConditionOutcome.match(message.foundExactly("WebApplicationContext"));
}
// 若以上三种都不匹配的话,则说明不是一个servlet web application
return ConditionOutcome.noMatch(message.because("not a servlet web application"));
}
对于是SERVLET的情况,首先根据classpath中是否存在org.springframework.web.context.support.GenericWebApplicationContext.class,如果不存在该类,则直接返回不匹配;若存在的话那么又分为以下几种匹配的情况:
- session
- ConfigurableWebEnvironment
- WebApplicationContext
若上面三种情况都不匹配,则说明不是一个servlet web application。
4.4 其他
由于springboot的OnXXXCondition类实现太多,不可能每个条件类都分析一遍,因此上面只分析了OnResourceCondition,OnBeanCondition和onWebApplicationCondition的源码。我们分析源码不可能把所有代码都通读一遍的,阅读源码的话,只要理解了某个模块的类之间的关系及挑几个有代表性的类分析下就行,不可能一网打尽。
若有时间的话,推荐看下几个我们常用的条件类的源码:OnPropertyCondition,OnClassCondition和OnExpressionCondition等。
5 如何扩展SpringBootCondition
前文我们知道了如何扩展Spring的Condition接口,那么我们该如何扩展SpringBoot的SpringBootCondition类呢?
推荐阅读springboot之使用SpringBootCondition获得答案
好了,本篇文章是SpringBoot自动配置源码分析的前置文章,这里分析了条件注解源码,那么下篇文章我们就来看看SpringBoot自动配置的源码了。
下节预告:
<font color=Blue>SpringBoot新特性:SpringBoot是如何自动配置的?--SpringBoot源码(四)</font>
原创不易,帮忙点个赞呗!
参考:
3,spring boot 系列之六:深入理解spring boot的自动配置

以上是关于《SpringBoot篇》26.SpringBoot整合Jackson超详细教程(附Jackson工具类)的主要内容,如果未能解决你的问题,请参考以下文章