决策树算法程序
Posted 优化大师傅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树算法程序相关的知识,希望对你有一定的参考价值。
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
import pydotplus
from IPython.display import Image,display
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import tree
iris=load_iris()
X=pd.DataFrame(iris.data,columns=iris.feature_names)
y=pd.DataFrame(iris.target,columns=['target'])
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=0)
clf=DecisionTreeClassifier(criterion='entropy',max_depth=4)
clf.fit(X_train,y_train)
y_test_pred=clf.predict(X_test)
y_train_pred=clf.predict(X_train)
print("训练数据准确率:",accuracy_score(y_train,y_train_pred))
print("训练数据准确率:",accuracy_score(y_test, y_test_pred))
##树结构可视化
dot_data=tree.export_graphviz(clf,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True,
rounded=True)
graph=pydotplus.graph_from_dot_data(dot_data)
display(Image(graph.create_png()))
史诗级干货长文决策树算法
决策树算法
1. 决策树算法简介
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-else结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法
决策树:是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果,本质是一颗由多个判断节点组成的树。
怎么理解这句话?通过一个对话例子
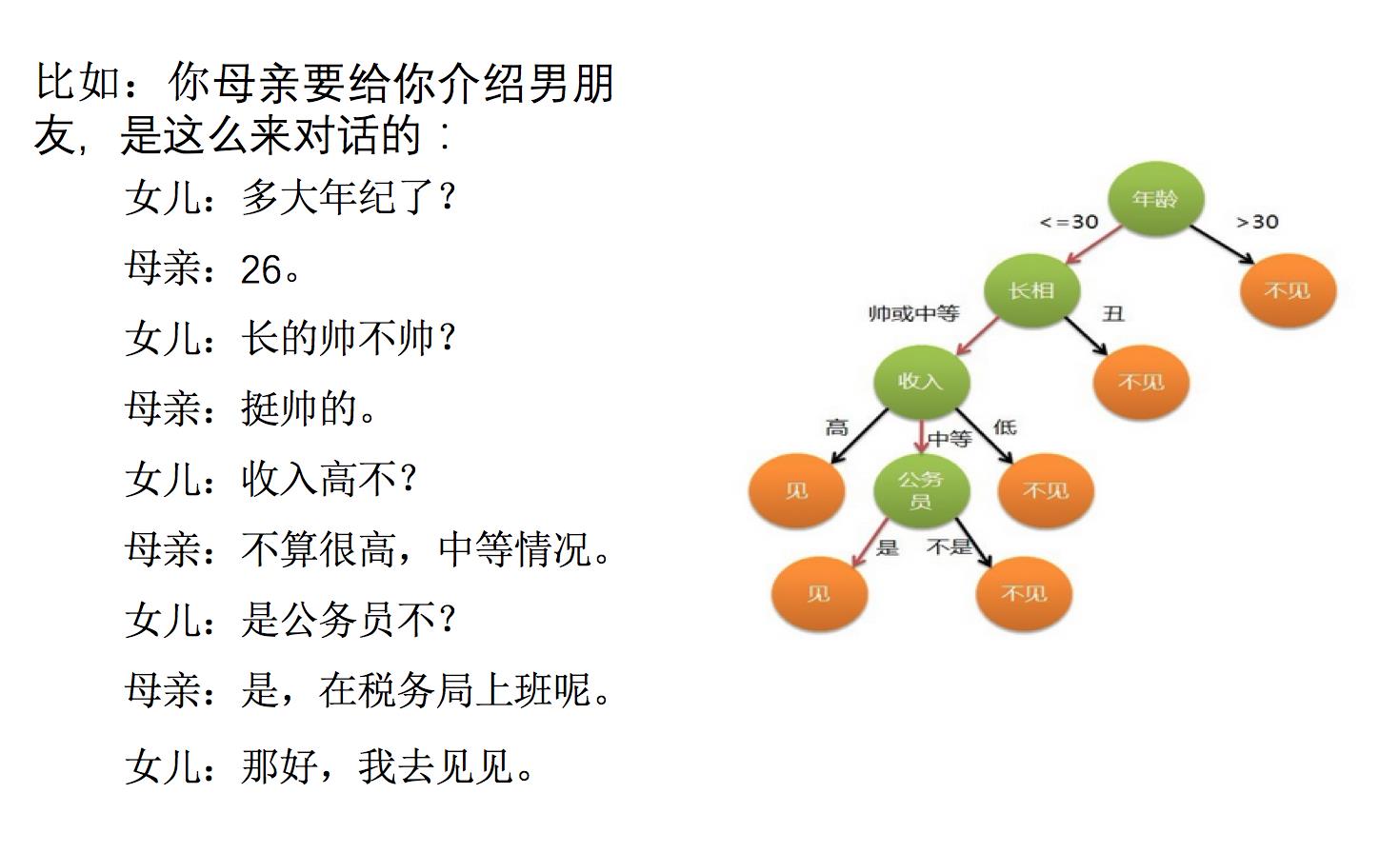
想一想这个女生为什么把年龄放在最上面判断 !!!
上面案例是女生通过定性的主观意识,把年龄放到最上面,那么如果需要对这一过程进行量化,该如何处理呢?
此时需要用到信息论中的知识:信息熵,信息增益
小结
- 决策树定义:
- 是一种树形结构,
- 本质是一颗由多个判断节点组成的树
2. 决策树分类原理
学习目标
- 知道如何求解信息熵
- 知道信息增益的求解过程
- 知道信息增益率的求解过程
- 知道基尼系数的求解过程
- 知道信息增益、信息增益率和基尼系数三者之间的区别、联系
请参考:【机器学习】决策树分类原理
3. cart剪枝
3.1 为什么要剪枝?
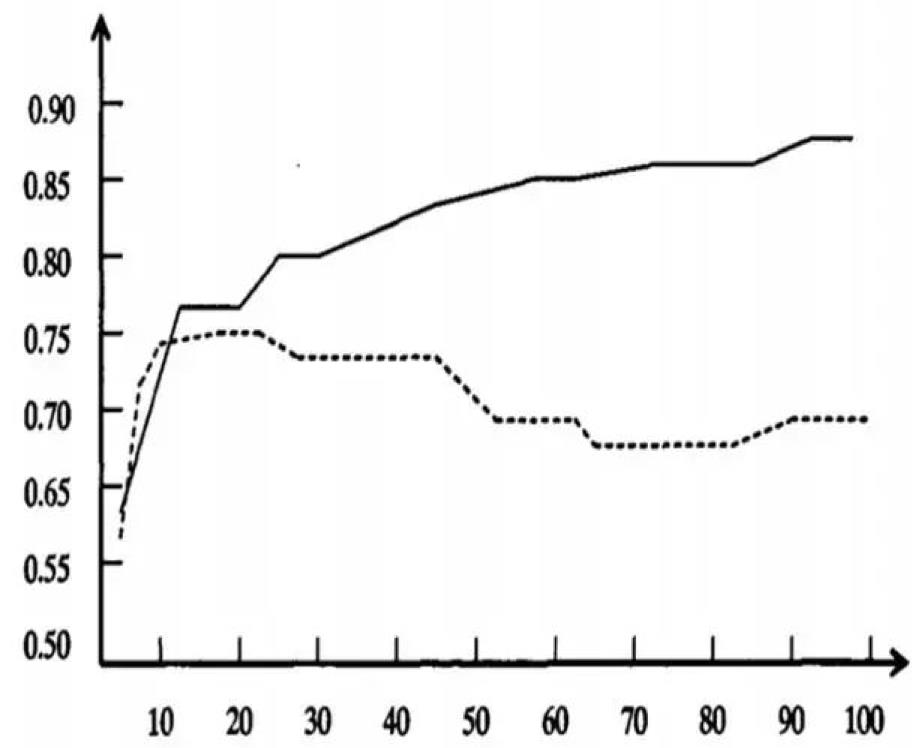
-
图形描述
- 横轴表示在决策树创建过程中树的结点总数,纵轴表示决策树的预测精度。
- 实线显示的是决策树在训练集上的精度,虚线显示的则是在一个独立的测试集上测量出来的精度。
- 随着树的增长,在训练样集上的精度是单调上升的, 然而在独立的测试样例上测出的精度先上升后下降。
-
出现这种情况的原因:
- 原因1:噪声、样本冲突,即错误的样本数据。
- 原因2:特征即属性不能完全作为分类标准。
- 原因3:巧合的规律性,数据量不够大。
3.2 常用的减枝方法
3.2.1 预剪枝
(1)每一个结点所包含的最小样本数目,例如10,则该结点总样本数小于10时,则不再分;
(2)指定树的高度或者深度,例如树的最大深度为4;
(3)指定结点的熵小于某个值,不再划分。随着树的增长, 在训练样集上的精度是单调上升的, 然而在独立的测试样例上测出的精度先上升后下降。
3.2.2 后剪枝
后剪枝,在已生成过拟合决策树上进行剪枝,可以得到简化版的剪枝决策树。
3.3 小结
- 剪枝原因
- 噪声、样本冲突,即错误的样本数据
- 特征即属性不能完全作为分类标准
- 巧合的规律性,数据量不够大。
- 常用剪枝方法
- 预剪枝
- 在构建树的过程中,同时剪枝
- 限制节点最小样本数
- 指定数据高度
- 指定熵值的最小值
- 在构建树的过程中,同时剪枝
- 后剪枝
- 把一棵树,构建完成之后,再进行从下往上的剪枝
- 预剪枝
4. 特征工程-特征提取
学习目标
- 了解什么是特征提取
- 知道字典特征提取操作流程
- 知道文本特征提取操作流程
- 知道tfidf的实现思想
请参考:【机器学习】特征工程->特征提取
5. 决策树算法API
-
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)- criterion
- 特征选择标准
- “gini"或者"entropy”,前者代表基尼系数,后者代表信息增益。一默认"gini",即CART算法。
- min_samples_split
- 内部节点再划分所需最小样本数
- 这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。 默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。我之前的一个项目例子,有大概10万样本,建立决策树时,我选择了min_samples_split=10。可以作为参考。
- min_samples_leaf
- 叶子节点最少样本数
- 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。之前的10万样本项目使用min_samples_leaf的值为5,仅供参考。
- max_depth
- 决策树最大深度
- 决策树的最大深度,默认可以不输入,如果不输入的话,决策树在建立子树的时候不会限制子树的深度。一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间
- random_state
- 随机数种子
- criterion
6. 案例:泰坦尼克号乘客生存预测
学习目标
- 通过案例进一步掌握决策树算法api的具体使用
7. 回归决策树
学习目标
- 知道回归决策树的实现原理
前面已经讲到,关于数据类型,我们主要可以把其分为两类,连续型数据和离散型数据。在面对不同数据时,决策树也 可以分为两大类型: 分类决策树和回归决策树。 前者主要用于处理离散型数据,后者主要用于处理连续型数据。
请参考:【机器学习】回归决策树
加油!
感谢!
努力!
以上是关于决策树算法程序的主要内容,如果未能解决你的问题,请参考以下文章