Python中的groupby分组
Posted O_nice
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python中的groupby分组相关的知识,希望对你有一定的参考价值。
Python中的groupby分组
一、groupby函数
groupby函数功能:对DataFrame进行分组(可单类分组,可多类分组)
需求:按“字段”列对数据data进行分组
groupby函数基本格式:data.groupby([‘分组字段’])
- data:要分组的原始数据
- 分组字段:分组参考的数据列名
举例:
原数据data:

- 单类分组举例
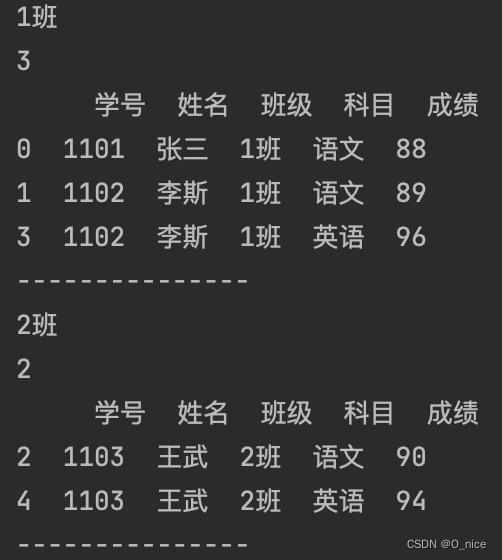
根据“班级”进行分组:
import pandas as pd
data = pd.read_excel('/Users/ABC/Documents/工作簿1.xlsx')
for name, group in data.groupby(['班级']):
num_g = group['班级'].count() # 获取组内记录数目
print(name) # name为班级名称
print(num_g)
print(group) # group为每个分组中的记录情况
print('---------------')
“班级”分组结果:
- 多类分组举例
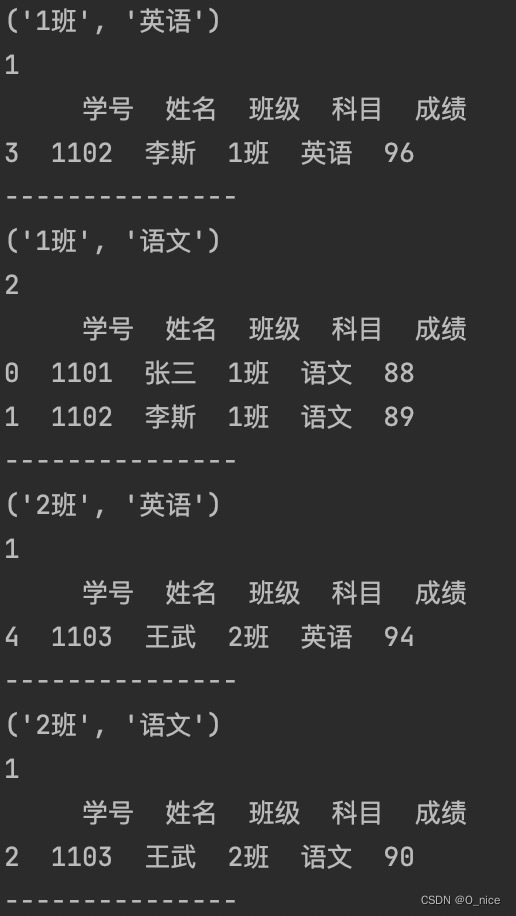
根据“班级”和“科目”分组:
import pandas as pd
data = pd.read_excel('/Users/ABC/Documents/工作簿1.xlsx')
for name, group in data.groupby(['班级','科目']):
num_g = group['学号'].count() # 获取组内记录数目
print(name) # name为班级名称
print(num_g)
print(group) # group为每个分组中的记录情况
print('---------------')
“班级”和“科目”分组结果:
二、groupby结果对象输出与转型
2.1groupby迭代结果输出
groupby函数产生的结果是个迭代器,若打印输出data.groupby([‘分组字段’])的结果可能会运行处以下结果:

解决方法:
要输出具体的结果详情可以用for循环读取(参考上文举例中的代码),其中每个分组结果中包含 分组名称(上文举例代码中:name)和分组记录(上文举例代码中:group)
2.2分组记录- group转化为DataFrame类型
当需要对分组记录- group中的记录进行进一步操作时,发现常用的取列等操作报错
解决方法:
需要将分组记录-group转化为DataFrame类型
转化思路:
用group.values得到一个数组,再将数组用array.tolist()方法转化为列表,再用列表作为参数传入pd.DataFrame()方法中
注意:转化生成的DataFrame没有原数据的列名,需要用DataFrame.columns具体指定
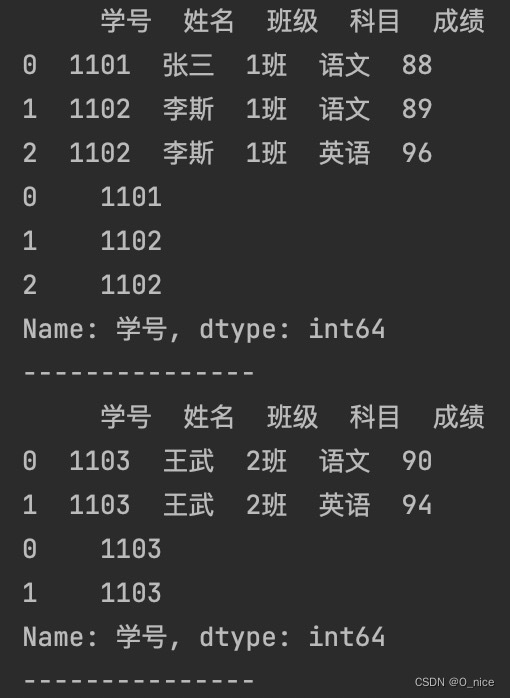
举例:
import pandas as pd
data = pd.read_excel('/Users/ABC/Documents/工作簿1.xlsx')
for name, group in data.groupby(['班级']):
list_group = group.values.tolist()# 将group.values数组转化为array.tolist()列表
group_df = pd.DataFrame(list_group)# 将array.tolist()列表转化为DataFrame
group_df.columns = ['学号', '姓名', '班级', '科目', '成绩']# 生成的DataFrame无原列名,而是默认的列索引,因此为DataFrame指定列名
print(group_df)
print(group_df['学号'])# DataFrame取列操作
print('---------------')
运行结果:
Python中的字典分组函数(groupby,itertools)
from operator import itemgetter # itemgetter用来去dict中的key,省去了使用lambda函数
from itertools import groupby # itertool
d1={‘name‘:‘zhangsan‘,‘age‘:20,‘country‘:‘China‘}
d2={‘name‘:‘wangwu‘,‘age‘:19,‘country‘:‘USA‘}
d3={‘name‘:‘lisi‘,‘age‘:22,‘country‘:‘JP‘}
d4={‘name‘:‘zhaoliu‘,‘age‘:22,‘country‘:‘USA‘}
d5={‘name‘:‘pengqi‘,‘age‘:22,‘country‘:‘USA‘}
d6={‘name‘:‘lijiu‘,‘age‘:22,‘country‘:‘China‘}
lst=[d1,d2,d3,d4,d5,d6]
# 通过country进行分组:
lst.sort(key=itemgetter(‘country‘)) # 需要先排序,然后才能使用groupby
lstg = groupby(lst,itemgetter(‘country‘)) # 分组
# 等同于lstg = groupby(lst,key=lambda x:x[‘country‘])
for country,items in lstg:
print(country)
for item in items:
print(item)
以上是关于Python中的groupby分组的主要内容,如果未能解决你的问题,请参考以下文章