玩转MySQL:都2022年了,这些数据库技术你都知道吗
Posted Java_LingFeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了玩转MySQL:都2022年了,这些数据库技术你都知道吗相关的知识,希望对你有一定的参考价值。
引言
mysql数据库从1995年诞生至今,已经过去了二十多个年头了,到2022.04.26日为止,MySQL8.0.29正式发行了GA版本,在此之前版本也发生了多次迭代,发行了大大小小N多个版本,其中每个版本中都有各自的新特性,所有版本的特性加起来,用一本书的篇幅也无法完全阐述清楚,因此本章主要会挑重点特性来讲,具体各版本的特性可参考MySQL官网的开发手册:
-
《MySQL官网-5.6版手册》
-
《MySQL官网-5.7版手册》
-
《MySQL官网-8.0版手册》
这里主要讲一下5.6、5.7、8.0这三个版本,因为这三个版本属于MySQL里程碑式的发行版,其实除开这三个版本外,5.1版本也是早期最主流的版本,但迄今为止基本上都并不用该版本了,因此不再对其做过多描述。
一、MySQL5.6支持的新技术
MySQL5.6是Oracle的得意之作,该版本是让MySQL真正走向高性能数据库的里程碑版本,在此之前的MySQL版本中,虽然功能也较为丰富,但性能相较于同期的Oracle数据库而言,其实表现并不佳。直到Oracle公司接手MySQL后,首先就对其进行了大刀阔斧的改进,从Oracle中移植了很多特性过来,同时废弃一些原有的鸡肋功能,也优化了很多内部实现,最终打造出了MySQL5.6这个版本。
但这里对于MySQL5.6中不重要的特性不会罗列,重点讲解一些较为重要的新特性。
1.1、支持只读事务(Read-Only)
在此之前的版本中,MySQL默认会为每个事务都分配事务ID,所有事务都一视同仁,但在5.6版本中开始支持只读事务,MySQL内部会有两个事务链表,一个是只读事务链表,一个是正常事务链表。
当一个事务中只有读操作时,MySQL并不会为这些事务分配ID,默认全部为0(但是会分配查询ID),然后将其标记为一个只读事务,并加入只读事务链表中,直到当这个事务中出现变更数据的操作时,才会正式为其分配事务ID,以及将其挪动到正常事务链表中。
这样做的好处在于:其他事务利用MVCC机制读取数据时,生成的ReadView读视图中的活跃事务链表会小很多很多,因此遍历的速度更快,同时也无需为其分配回滚段,从而进一步提升了MySQL整体的查询性能。
1.2、InnoDB存储引擎增强
主要就说一下InnoDB的核心:BufferPool缓冲池相关的改进项,主要有两点:刷盘策略改进、缓冲池预热。
1.2.1、缓冲池刷盘策略优化
在之前的版本的InnoDB-BufferPool缓冲池中,变更过的数据页会共用MySQL后台的刷盘线程,也就是redo-log、undo-log、bin-log.....一系列内存到磁盘的刷盘工作,都是采用同一批线程来完成。在MySQL5.6版本中,BufferPool引入了独立的刷盘线程,也就意味着缓冲池中变更过的数据页会由专门的线程来负责刷盘,这样能够提升缓冲池的刷盘效率,无需排队等待刷写。
同时BufferPool的刷盘线程,还支持开启多线程并发刷盘操作,这样在缓冲池较大的情况下,能够进一步提升刷盘的效率,从而让数据落盘的效率更快,从一定程度上也提升了数据的安全性,毕竟内存中的数据随时都有几率丢失,但落盘后基本上不是硬件损坏,都有可能恢复过来。
1.2.2、BufferPool缓冲池预热
缓冲池预热是一种特别好的机制,在之前版本的内存缓冲池中,当MySQL关闭时,原本内存中的热点数据都会被清空,重启后所有的热点数据又需要经过时间的沉淀,然后才能留在内存中。但MySQL5.6版本中,每次关闭MySQL时都会将内存中的热点数据页保存到磁盘中,当重启时会直接从磁盘中载入之前的热点数据,避免了热点数据的重新“选拔”!
这样做的好处无疑是巨大的,举个例子就能够理解,如下:
现在整个村庄中选拔综合能力最强的男人,原本已经选拔了一批相对来说最优秀的人出来,但由于村庄临时出现变故需要集体外出,所以本次选拔赛会被搁浅,当处理好变故后再次开启选拔赛,又重新从头开始选拔,这显然十分影响效率。
而预热的含义是:出现意外变故时,先将上次选拔赛中最优秀的那批人,把对应的名字保存在一个名单中,处理完变故后,只需要找到这个名单,把名单上的人喊过来继续选拔即可,这样做显然将效率提升了N倍。
1.3、新增Performance_Schema库监控全局资源
如果对MySQL比较熟悉的小伙伴应该清楚,在之前的版本中存在一个名为information_schema的库,其中会记录一些MySQL运行期间需要用到的表,比如视图管理、存储过程与函数的管理、临时表的管理、会话的管理、触发器的管理、表分区的管理......,这些内容的信息都会被存储到information_schema库中。
而在MySQL5.6中,官方又加入了一个新的自带库:performance_schema,这里面会记录:数据库整体的监控信息,比如事务监控信息、最近执行的SQL信息、最近连接的客户端信息、数据库各空间的使用信息......,基于这个库可以在线上构建出一个完善的MySQL监控系统:
-
Statements/execution stages:MySQL统计的一些消耗资源较高的SQL语句。
-
Table and Index I/O:MySQL统计的那些表和索引会导致I/O负载过高。
-
Table Locks:MySQL统计的表中数据的锁资源竞争信息。
-
Users/Hosts/Accounts:消耗资源最多的客户端、IP机器、用户。
-
Network I/O:MySQL统计的一些网络相关的资源情况。
-
.......
1.4、索引下推机制(Index Condition Pushdown)
Index Condition Pushdown索引下推简称ICP,它是MySQL5.6版本以后引入的一种优化机制,以下述用户表为例,这张表上基于姓名、性别、密码字段建立了一个联合索引,此时先来看看下面的情况:
select * from `zz_users`; +---------+-----------+----------+----------+---------------------+ | user_id | user_name | user_sex | password | register_time | +---------+-----------+----------+----------+---------------------+ | 1 | 熊猫 | 女 | 6666 | 2022-08-14 15:22:01 | | 2 | 竹子 | 男 | 1234 | 2022-09-14 16:17:44 | | 3 | 子竹 | 男 | 4321 | 2022-09-16 07:42:21 | | 4 | 猫熊 | 女 | 8888 | 2022-09-17 23:48:29 | +---------+-----------+----------+----------+---------------------+ INSERT INTO `zz_users` VALUES(5,"竹竹","女","8888","2022-09-20 22:17:21"); SELECT * FROM `zz_users` WHERE `user_name` LIKE "竹%" AND `user_sex`="男"; 复制代码
首先为了更加直观的讲清楚索引下推,因此先再向用户表中增加一条数据。然后再来看看后面的查询SQL,这条SQL会使用联合索引吗?答案是会的,但只能部分使用,因为联合索引的每个节点信息大致如下:
["熊猫","女","6666"] : 1, ["竹子","男","1234"] : 2, ["子竹","男","4321"] : 3, ["猫熊","男","4321"] : 4, ["竹竹","女","8888"] : 5 复制代码
由于前面使用的是模糊查询,但%在结尾,因此可以使用竹这个字作为条件在联合索引中查询,整个查询过程如下:
-
①利用联合索引中的user_name字段找出「竹子、竹竹」两个索引节点。
-
②返回索引节点存储的值「2、5」给Server层,然后去逐一做回表扫描。
-
③在Server层中根据user_sex="男"这个条件逐条判断,最终筛选到「竹子」这条数据。
有人或许会疑惑,为什么user_sex="男"这个条件不在联合索引中处理呢?因为前面是模糊查询,所以拼接起来是这样的:竹x男,由于这个x是未知的,因此无法根据最左前缀原则去匹配数据,最终这里只能使用联合索引中user_name字段的一部分,后续的user_sex="男"还需要回到Server层处理。
那什么又叫做索引下推呢?也就是将Server层筛选数据的工作,下推到引擎层处理。
以前面的案例来讲解,MySQL5.6加入索引下推机制后,其执行过程是什么样子的呢?
-
①利用联合索引中的user_name字段找出「竹子、竹竹」两个索引节点。
-
②根据user_sex="男"这个条件在索引节点中逐个判断,从而得到「竹子」这个节点。
-
③最终将「竹子」这个节点对应的「2」返回给Server层,然后聚簇索引中回表拿数据。
相较于没有索引下推之前,原本需要做「2、5」两次回表查询,但在拥有索引下推之后,仅需做「2」一次回表查询。
索引下推在MySQL5.6版本之后是默认开启的,可以通过命令set optimizer_switch='index_condition_pushdown=off|on';命令来手动管理。
1.5、MRR(Multi-Range Read)机制
Multi-Range Read简称为MRR机制,这也是和索引下推一同在MySQL5.6版本中引入的性能优化措施,那什么叫做MRR优化呢?
一般来说,在实际业务中我们应当尽量通过索引覆盖的特性,减少回表操作以降低IO次数,但在很多时候往往又不得不做回表才能查询到数据,但回表显然会导致产生大量磁盘IO,同时更严重的一点是:还会产生大量的离散IO,下面举个例子来理解。
SELECT * FROM `zz_student_score` WHERE `score` BETWEEN 0 AND 59; 复制代码
上述这条SQL所做的工作很简单,就是在学生成绩表中查询所有成绩未及格的学生信息,假设成绩字段上存在一个普通索引,那思考一下,这条SQL的执行流程是什么样的呢?
-
①先在成绩字段的索引上找到0分的节点,然后拿着ID去回表得到成绩零分的学生信息。
-
②再次回到成绩索引,继续找到所有1分的节点,继续回表得到1分的学生信息。
-
③再次回到成绩索引,继续找到所有2分的节点......
-
④周而复始,不断重复这个过程,直到将0~59分的所有学生信息全部拿到为止。
那此时假设此时成绩0~5分的表数据,位于磁盘空间的page_01页上,而成绩为5~10分的数据,位于磁盘空间的page_02页上,成绩为10~15分的数据,又位于磁盘空间的page_01页上。此时回表查询时就会导致在page_01、page_02两页空间上来回切换,但0~5、10~15分的数据完全可以合并,然后读一次page_01就可以了,既能减少IO次数,同时还避免了离散IO。
而MRR机制就主要是解决这个问题的,针对于辅助索引的回表查询,减少离散IO,并且将随机IO转换为顺序IO,从而提高查询效率。
那MRR机制具体是怎么做的呢?MRR机制中,对于辅助索引中查询出的ID,会将其放到缓冲区的read_rnd_buffer中,然后等全部的索引检索工作完成后,或者缓冲区中的数据达到read_rnd_buffer_size大小时,此时MySQL会对缓冲区中的数据排序,从而得到一个有序的ID集合:rest_sort,最终再根据顺序IO去聚簇/主键索引中回表查询数据。
SET @@optimizer_switch='mrr=on|off,mrr_cost_based=on|off';
可以通过上述这条命令开启或关闭MRR机制,MySQL5.6及以后的版本是默认开启的。
1.6、主从数据同步的复制改进
随着互联网时代浪潮的兴起,系统中的并发量、数据量日益增长,传统的单库在有些情况下就有些乏力,最初只能通过不断升级硬件配置的手段来提升性能。可单机的性能无论如何升级硬件,总有达到瓶颈的一天,因此分布式的概念开始进入大家眼中,而MySQL5.6中也针对于多节点部署的情况,其数据同步问题做了大幅度优化。
在MySQL5.6中,针对于主从数据同步的问题,主要引入了GTID复制、无损复制(增强半同步复制)、延时复制、并行复制这四种技术,但由于目前《MySQL专栏》还未开始发布“MySQL高可用”相关的文章,因此这些内容会在后续的《主从复制篇》阐述。
1.7、MySQL5.6中的其他特性
前面介绍的几点,属于比较重要的一些知识,但除此之外,5.6版本中还存在很多特性与优化项,如:
-
索引增强:全文索引支持InnoDB与亚洲语种分词、支持空间索引等。
-
表分区增强:单表分区数量最大可创建8192个、分区锁性能提升、支持cloumns分区类型。
-
增强日期类型:time、datetime、timestamp精度提升到微秒级,datetime容量缩减到5字节。
-
日志增强:Redo-log文件大小限制由4G→512G、Undo-log文件可独立指定位置存储。
-
支持在线DDL(Online DDL)、对limit语句做了优化......

除开上述外,还有很多很多与之前不同的变更,官方号称在5.6中修复了1667个Bug,因此想要更为全面的了解,可阅读《MySQL官网-5.6版手册》。
二、MySQL5.7引入的新特性
相较于前辈5.6、后辈8.0而言,MySQL5.7版本就显的中规中矩,其中没有发生太多的改变,MySQL5.7更偏向于5.6的稳定版,毕竟5.6版本中步子迈的太大,很多方面的技术都需要根据市场反馈做细微调整,因此成功的为MySQL5.7做好了铺垫,一般的项目如果不选用MySQL8.0,基本上都会选择MySQL5.7而不是5.6。
但MySQL5.7中也存在几个能令人眼前一亮的优化项,接着就重点聊一聊这些重点~
2.1、引入共享排他锁
在MySQL5.7之前的版本中,数据库中仅存在两种类型的锁,即共享锁与排他锁,但是在MySQL5.7.2版本中引入了一种新的锁,被称之为(SX)共享排他锁,这种锁是共享锁与排他锁的杂交类型,至于为何引入这种锁呢?聊它之前需要先理解SMO问题:
在SQL执行期间一旦更新操作触发B+Tree叶子节点分裂,那么就会对整棵B+Tree加排它锁,这不但阻塞了后续这张表上的所有的更新操作,同时也阻止了所有试图在B+Tree上的读操作,也就是会导致所有的读写操作都被阻塞,其影响巨大。因此,这种大粒度的排它锁成为了InnoDB支持高并发访问的主要瓶颈,而这也是MySQL 5.7版本中引入SX锁要解决的问题。
那想一下该如何解决这个问题呢?最简单的方式就是减小SMO问题发生时,锁定的B+Tree粒度,当发生SMO问题时,就只锁定B+Tree的某个分支,而并不是锁定整颗B+树,从而做到不影响其他分支上的读写操作。
那MySQL5.7中引入共享排他锁后,究竟是如何实现的这点呢?先聊聊SX锁的特性,它不会阻塞S锁,但是会阻塞X、SX锁,下面展开来说说。
在聊之前得搞清楚SQL执行时的几个概念:
-
读取操作:基于B+Tree去读取某条或多条行记录。
-
乐观写入:不会改变B+Tree的索引键,仅会更改索引值,比如主键索引树中不修改主键字段,只修改其他字段的数据,不会引起节点分裂。
-
悲观写入:会改变B+Tree的结构,也就是会造成节点分裂,比如无序插入、修改索引键的字段值。
在MySQL5.6版本中,一旦有操作导致了树结构发生变化,就会对整棵树加上排他锁,阻塞所有的读写操作,而MySQL5.7版本中,为了解决该问题,对于不同的SQL执行,流程就做了调整。
2.1.1、MySQL5.7中读操作的执行流程
-
①读取数据之前首先会对B+Tree加一个共享锁。
-
②在基于树检索数据的过程中,对于所有走过的叶节点会加一个共享锁。
-
③找到需要读取的目标叶子节点后,先加一个共享锁,释放步骤②上加的所有共享锁。
-
④读取最终的目标叶子节点中的数据,读取完成后释放对应叶子节点上的共享锁。
2.1.2、MySQL5.7中乐观写入的执行流程
-
①乐观写入之前首先会对B+Tree加一个共享锁。
-
②在基于树检索修改位置的过程中,对于所有走过的叶节点会加一个共享锁。
-
③找到需要写入数据的目标叶子节点后,先加一个排他锁,释放步骤②上加的所有共享锁。
-
④修改目标叶子节点中的数据后,释放对应叶子节点上的排他锁。
2.1.3、MySQL5.7中悲观写入的执行流程
-
①悲观更新之前首先会对B+Tree加一个共享排他锁。
-
②由于①上已经加了SX锁,因此当前事务执行过程中会阻塞其他尝试更改树结构的事务。
-
③遍历查找需要写入数据的目标叶子节点,找到后对其分支加上排他锁,释放①中加的SX锁。
-
④执行SMO操作,也就是执行悲观写入操作,完成后释放步骤③中在分支上加的排他锁。
如果需要修改多个数据时,会在遍历查找的过程中,记录下所有要修改的目标节点。
2.1.4、MySQL5.7中并发事务冲突分析
观察上述讲到的三种执行情况,对于读操作、乐观写入操作而言,并不会加SX锁,共享排他锁仅针对于悲观写入操作会加,由于读操作、乐观写入执行前对整颗树加的是S锁,因此悲观写入时加的SX锁并不会阻塞乐观写入和读操作,但当另一个事务尝试执行SMO操作变更树结构时,也需要先对树加上一个SX锁,这时两个悲观写入的并发事务就会出现冲突,新来的事务会被阻塞。
但是要注意:当第一个事务寻找到要修改的节点后,会对其分支加上X锁,紧接着会释放B+Tree上的SX锁,这时另外一个执行SMO操作的事务就能获取SX锁啦!
其实从上述中可能得知一点:MySQL5.7版本引入共享排他锁之后,解决了5.6版本发生SMO操作时阻塞一切读写操作的问题,这样能够在一定程度上提升了InnoDB表的并发性能。
最后要注意:虽然一个执行悲观写入的事务,找到了要更新/插入数据的节点后会释放SX锁,但是会对其上级的叶节点(叶分支)加上排他锁,因此正在发生SMO操作的叶分支,依旧是会阻塞所有的读写行为!
上面这句话啥意思呢?也就是当一个要读取的数据,位于正在执行SMO操作的叶分支中时,依旧会被阻塞。
2.2、MySQL开始支持json格式
随着非结构化数据的存储需求持续增长,各类非关系型数据库应运而生,例如大名鼎鼎的MongoDB,各大关系型数据库为了防止市场占用率流失,也开始弥补对于这块的支持,因此在MySQL5.7.8版本中也支持了json数据类型,并且为其提供了一系列操作的API。
虽然说MySQL也支持了json格式存储,但显然是亡羊补牢,为时已晚,自然无法抢过MongoDB的市场占用率,从性能和存储容量来说,MySQL也无法竞争过MongoDB,但相较于其他非结构化数据库,MySQL存储json数据有两大优势:①对于json数据的API操作支持事务。②支持为一个表字段设置json格式,也就意味着MySQL中可以将结构化数据和非结构化数据共同存储。
2.3、MySQL5.7中的其他特性
除开上述两点值得展开叙说的特性外,其他的基本上是一些细微变化,因此就不对其进行展开叙述啦,这里稍微罗列一下MySQL5.7版本中,其他的特性支持,如下:
-
临时表优化,临时表的写操作不记录redo-log、不为其生成缓冲数据页,减小资源占用。
-
多接点部署时,数据同步复制再次优化,支持多主/源复制、以及真正意义上的并行复制等。
-
引入了虚拟列的实现,类似于Oracle数据库中的函数索引。
-
移除了默认的test数据库,以及默认不会创建匿名用户,引入密码过期策略。
-
触发器增强,表上同一种事件、同一时机的触发器可创建多个,之前则只能允许创建一个。
-
推出了新的mysqlpump工具,用于数据的逻辑备份、引入了新的客户端工具mysqlsh等。
-
支持通过max_execution_time限制一条SQL的执行超时时间、支持innodb_deadlock_detect死锁检测。
-
GIS空间数据类型增强,使用Boost.Geometry代替原有的GIS算法,InnoDB支持空间索引。
-
.......
除此之外其实也依旧存在其他很多细节方面的新特性支持和优化项,具体可参考《MySQL官网-5.7版手册》。
三、MySQL8.0发生的大变更
在MySQL8.0发行前,基本上所有使用MySQL数据库的企业/个人项目,基本上都属于MySQL5.6/5.7的钉子户,基本上不会再选择除此之外的发行版,但随着MySQL8.0的发行,打破了这个局面,官方号称经压测后,8.0比5.7性能足足提升了200%,这无疑对于MySQL的忠实用户而言,显然是一个十分巨大的诱惑。
因为按照理论来说,只要你将项目中的MySQL,从原有的MySQL5.7版本升级到MySQL8.0版本,从数据库的性能上来说,无需你手动做任何优化,就能够让性能翻倍。
不过确实在MySQL8.0版本中,再次推出了非常多重要的新特性,也推出了很多关于性能的优化项,因此接下来展开聊聊最新的MySQL8.0系版本。
3.1、移除查询缓存(Query Cache)
Query Cahce查询缓存的设计初衷很好,也就是利用热点探测技术,对于一些频繁执行的查询SQL,直接将结果缓存在内存中,之后再次来查询相同数据时,就无需走磁盘,而是直接从查询缓存中获取数据并返回。
听起来似乎还不错呀,好像确实能带来不小的性能提升呢?但实则很鸡肋,为啥?看个例子。
select * from zz_users where user_id=1; select * from zz_users where user_id = 1; 复制代码
比如上述这两条SQL语句,在我们看来是不是一样的?确实,都是在查询ID=1的用户数据,但奇葩的事情出现了,MySQL的查询缓存会把它当做两条不同的SQL,也就是假如上面的第一条SQL,其查询结果被放入到了缓存中,第二条SQL依旧无法命中这个缓存,会继续走表查询的形式获取数据,Why?
因为MySQL查询缓存是以SQL的哈希值来作为Key的,上面两条SQL虽然一样,但是后面的查询条件有细微差别:user_id=1、user_id = 1,也就是一条SQL有空格,一条没有。
由于这一点点细微差异,会导致两条SQL计算出的哈希值完全不同,因此无法命中缓存,是不是很鸡肋?还有多种情况:user_id =1、user_id= 1,空格处于的前后位置不同,也会导致缓存失效。
也正是由于方方面面的原因,所以查询缓存在MySQL8.0中被完全舍弃了,即移除掉了查询缓存区,各方面原因如下:
-
①缓存命中率低:几乎大部分SQL都无法从查询缓存中获得数据。
-
②占用内存高:将大量查询结果放入到内存中,会占用至少几百MB的内存。
-
③增加查询步骤:查询表之前会先查一次缓存,查询后会将结果放入缓存,额外多几步开销。
-
④缓存维护成本不小,需要LRU算法淘汰缓存,同时每次更新、插入、删除数据时,都要清空缓存中对应的数据。
-
⑤查询缓存是专门为MyISAM引擎设计的,而InnoDB构建的缓冲区完全具备查询缓存的作用。
因为上述一系列原因,再加上项目中一般都会使用Redis先做业务缓存,因此能来到MySQL的查询语句,几乎都是要从表中读数据的,所以查询缓存的地位就显得更加突兀,所以在8.0版本中就直接去掉了,毕竟弊大于利,带来的收益达不到设计时的预期。
3.2、锁机制优化
在MySQL8.0中的锁机制主要出现了两点优化,一方面对获取共享锁的写法进行了优化,如下:
-- MySQL8.0之前的版本 SELECT ... LOCK IN SHARE MODE; -- MySQL8.0及后续的版本 SELECT ... FOR SHARE; 复制代码
第二方面则支持非阻塞式获取锁机制,可以在获取锁的写法上加上NOWAIT、SKIP LOCKED关键字,这样在未获取到锁时不会阻塞等待,使用SKIP LOCKED未获取到锁时会直接返回空,使用NOWAIT会直接返回并向客户端返回异常。用法如下:
select ... for update nowait; select ... for update skip locked; 复制代码
3.3、在线修改的系统参数支持持久化
在之前的版本中,通过set、set global的形式修改某个系统变量时,这种方式设置的参数值都是一次性的,也就是修改过的参数并不会被同步到本地,当MySQL重启时,这些调整过的参数又会回归默认值,如果想要让调整过的参数生效,就必须要手动停止MySQL,然后去修改my.ini/my.conf文件,修改完成后再重启数据库服务,这时才能让参数永久生效。
这种方式无疑是十分痛苦的,尤其是在做数据库线上调优时,修改参数后重启又会失效,有时重启忘记再次调整参数,最终导致数据库服务出现问题,这种体验令人很糟心。
而在MySQL8.0中则彻底优化了这个问题,推出了在线修改参数后,支持持久化到本地文件的机制,也就是通过SET PERSIST命令来完成,如下:
-- 调整事务的隔离级别(针对于当前连接有效) set transaction isolation level read uncommitted; -- 调整事务的隔离级别(针对于全局有效,重启后会丢失) set global tx_isolation = "read-committed"; - - 调整事务的隔离级别(针对于全局有效,并且会持久化到本地,重启后不会丢失) set persist global.tx_isolation = "repeatable-read"; 复制代码
通过set persist命令持久化的参数,可以通过下述命令来查看:
select * from performance_schema.persisted_variables; 复制代码
这条命令的本质其实是:基于MySQL自带的performance_schema监控库查询持久化过的参数。
其实参数持久化的原理也非常简单,当执行set persist命令时,会将改变过的参数写入到本地的mysqld-auto.cnf文件中,MySQL每次启动时都会读取这个文件中的值,如果该文件中存在参数,则会直接将其加载,从而实现了一次修改,永久有效。
但当你想要参数不再持久化到本地时,可以选择删除安装目录下的mysqld-auto.cnf文件,或执行reset persist命令来清除,但这两种方式都只对下次重启时生效,毕竟本次参数已经被载入内存了,所以只能通过再次手动修改的方式复原。
3.4、增强多表连接查询
在之前的MySQL版本中,仅支持交叉连接、内连接、左外连接、右外连接四种连接类型,这四种连接都会采用默认的连接算法,而在8.0版本中提供了哈希连接、反连接两种连接优化的支持。
3.1.1、哈希连接(Hash Join)
所谓的哈希连接其实并非一种新的连表方式,而是一种连表查询的算法,在关系型数据库中多表连查一般有三种算法:Hash-Join哈希散列连接、Sort-Merge-Join排序合并连接、Nest-Loop-Join嵌套循环连接,这三种连表算法在Oracle数据库中都支持,但MySQL之前的版本中,所有的连表方式都仅支持Nest-Loop-Join嵌套循环连接,对于这点在《SQL优化篇-以小驱大》中聊到过。
而到了MySQL8.0.18版本发布后,MySQL对内连接的方式支持了哈希连接算法,那究竟啥叫哈希连接算法呢?和之前传统的循环连接算法又有啥区别呢?接下来一起展开聊一聊。
哈希连接算法和循环连接算法的区别
先来看看传统的循环连接算法的连表查询过程是怎么样的呢?如下:
在循环连接算法中,会首先选择一张小表作为驱动表,然后依次将驱动表中每一条数据作为条件,去被驱动表中做遍历,最终得到符合连接条件的所有数据,也就是会形成一个下述的伪逻辑:
for(数据 x : 驱动表) for(数据 y : 被驱动表) if (x == y) // 如果符合连接条件,则记录到连接查询的结果集中..... 复制代码
这种循环连接的算法中,显然会造成巨大的开销,因为驱动表每条数据都需要和被驱动表的完整数据做一次遍历。也正是为了解决这个问题,因为MySQL8.0中引入了哈希连接算法,过程如下:
在哈希连接算法中会分为两个阶段:
-
构建阶段:选择一张小表作为构建表,接着会基于连接字段做哈希处理,生成哈希值放入内存中构建出一张哈希表。
-
探测阶段:遍历大表的每一行数据,然后对连接字段做哈希处理,通过生成的哈希值与内存哈希表做比较,符合条件则放入结果集中。
对比之前的循环连接算法,这种哈希连接算法带来的性能提升直线提升N倍,因为在循环连接算法中,需要遍历count(驱动表)次,即驱动表中有多少条数据就要遍历多少次。而在这种算法中,只需要将大表遍历一次,伪逻辑代码如下:
// 构建阶段:将小表的每行数据,根据哈希值放入内存哈希表中 Map hashTable = new HashMap(); for(数据 x : 构建表) hashTable.put(x); // 探测阶段:遍历大表的每行数据与内存哈希表做连接匹配 for(数据 y : 探测表) if (hashTable.get(y) != null) // 如果哈希处理后能够在内存哈希表中存在, // 则表示这条数据符合连接条件,则记录到连接查询的结果集中..... 复制代码
哈希连接对比循环连接算法而言,主要在两方面可以得到性能提升:
-
①哈希连接算法中,只需要将大表遍历一次,但循环连接算法需要遍历N次。
-
②哈希连接探测阶段,做连接判断时只需要先对数据做一次哈希处理,然后在内存中查找即可,复杂度仅为O(1),但循环连接算法的复杂度为O(n)。
哈希连接算法的致命问题
但虽然哈希连接算法能够带来卓越的性能提升,但也存在一个致命问题,就是内存中join_buffer_size的容量无法完全载入构建表的哈希数据时怎么办呢?这里就有两种解决方案:
-
①分批处理,将构建表的数据拆分为几部分,每次载入一部分到内存,但这样会导致大表的遍历次数,随着分批次数变大而增多。
-
②利用磁盘完成,也就是首先将构建表的所有数据做哈希处理,放不下时将一部分处理好的哈希数据放入磁盘,在探测阶段遍历大表时,每次对大表数据生成哈希值后,做判断时从磁盘依次读取处理好的哈希值做判断。
而MySQL中选择的是第二种,也就是当内存无法完全放下构建表的哈希数据时,会采用磁盘+内存混合的模式执行哈希连接。
MySQL什么情况下会选用哈希连接?
首先并不是多表连接的情况下都会使用哈希连接算法,该算法有几个硬性限制:
-
①目前哈希连接算法仅支持内连接的多表连查方式。
-
②哈希连接算法必须要求存在等值连接条件,即a.id=b.id才行,a.id>b.id是不行的。
-
③如果连接字段可以走索引查询的情况下,默认依旧会采用循环连接算法。
第二点的原因在于:哈希连接算法生成的哈希值是无序的,所以必须要用等值连接才行。 第三点的原因在于:连接查询时走索引的效率并不低,哈希连接需要生成哈希表,因此需要时间,因此在能够走索引连表的情况下,哈希连接算法的效率反而比不上循环连接。
也就是说,当连表时存在等值连接条件,并且未命中索引的情况下,MySQL默认会采用哈希连接算法来完成连表查询,不过还有一种情况也会使用,就是笛卡尔积情况,即不指定连接条件的情况下也会使用哈希连接,此时MySQL会直接对整条数据生成哈希表。
对于哈希连接算法,MySQL是默认开启的,咱们可通过set optimizer_switch="hash_join=off";的形式来手动控制开关。
3.1.2、反连接(Anti Join)
反连接是MySQL8.0对于一些反范围查询操作的优化,主要针对于下述几种情况会做优化:
-
NOT IN (SELECT … FROM …)
-
NOT EXISTS (SELECT … FROM …)
-
IN (SELECT … FROM …) IS NOT TRUE
-
EXISTS (SELECT … FROM …) IS NOT TRUE
-
IN (SELECT … FROM …) IS FALSE
-
EXISTS (SELECT … FROM …) IS FALSE
在MySQL早些版本中,使用NOT EXISTS、NOT IN、IS NOT...这类操作时有可能会导致索引失效,而且也会让查询效率变低,因此MySQL8.0版本中会对上述几类语句进行优化,当你的SQL语句使用了上述语法检索数据时,在MySQL内部会将其转变为反连接类型的查询语句。
也就是会将右边的子查询结果集,变为一张物理临时表,然后基于条件字段做连接查询,官方号称在某些场景下,能够让上述几类语句的查询性能提升20%,但对于这块我没做深入研究,因此就不展开叙述啦。
3.5、增强索引机制
在8.0中官方再一次对索引机制动刀,首先对联合索引提供了一种跳跃扫描机制的支持,也就意味着使用联合索引时,就算未遵循最左前缀匹配原则,也可以使用联合索引来检索数据。除此之外,还有另外三种新的索引特性:隐藏索引、降序索引以及函数索引。
3.5.1、索引跳跃式扫描机制(Index Skip Scan)
在之前讲《索引应用篇》时,咱们初次提到了最左前缀匹配原则,也就是SQL的查询条件中必须要包含联合索引的第一个字段,这样才能命中联合索引查询,但实际上这条规则也并不是100%遵循的。因为在MySQL8.0版本中加入了一个新的优化机制,也就是索引跳跃式扫描,这种机制使得咱们即使查询条件中,没有使用联合索引的第一个字段,也依旧可以使用联合索引,看起来就像跳过了联合索引中的第一个字段一样,这也是跳跃扫描的名称由来。
但跳跃扫描究竟是怎么实现的呢?上个栗子快速理解一下。
比如此时通过(A、B、C)三个列建立了一个联合索引,此时有如下一条SQL:
SELECT * FROM `tb_xx` WHERE B = `xxx` AND C = `xxx`; 复制代码
按理来说,这条SQL既不符合最左前缀原则,也不具备使用索引覆盖的条件,因此绝对是不会走联合索引查询的,但思考一个问题,这条SQL中都已经使用了联合索引中的两个字段,结果还不能使用索引,这似乎有点亏啊对不?因此MySQL8.x推出了跳跃扫描机制,但跳跃扫描并不是真正的“跳过了”第一个字段,而是优化器为你重构了SQL,比如上述这条SQL则会重构成如下情况:
SELECT * FROM `tb_xx` WHERE B = `xxx` AND C = `xxx` UNION ALL SELECT * FROM `tb_xx` WHERE B = `xxx` AND C = `xxx` AND A = "yyy" ...... SELECT * FROM `tb_xx` WHERE B = `xxx` AND C = `xxx` AND A = "zzz"; 复制代码
其实也就是MySQL优化器会自动对联合索引中的第一个字段的值去重,然后基于去重后的值全部拼接起来查一遍,一句话来概述就是:虽然你没用第一个字段,但我给你加上去,今天这个联合索引你就得用,不用也得给我用。
当然,如果熟悉Oracle数据库的小伙伴应该知道,跳跃扫描机制在Oracle中早就有了,但为什么MySQL8.0版本才推出这个机制呢?还记得咱们在《MySQL架构篇》中的闲谈嘛?MySQL几经转手后,最终归到了Oracle旗下,因此跳跃扫描机制仅是Oracle公司:从Oracle搬到了“自己的MySQL”上而已。
但是跳跃扫描机制也有很多限制,比如多表联查时无法触发、SQL条件中有分组操作也无法触发、SQL中用了DISTINCT去重也无法触发.....,总之有很多限制条件,具体的可以参考《MySQL官网8.0-跳跃扫描》。
其实这个跳跃性扫描机制,只有在唯一性较差的情况下,才能发挥出不错的效果,如果你联合索引的第一个字段,是一个值具备唯一性的字段,那去重一次再拼接,几乎就等价于走一次全表。
对于索引跳跃扫描机制,可以通过set @@optimizer_switch = 'skip_scan=off|on';命令来选择开启或关闭跳跃式扫描机制。
3.5.2、隐藏索引
隐藏索引并不是一种新的索引类型,而是一种对索引的骚操作,可以理解为对每个索引新增了一个开关按键,主要用于测试环境和灰度场景,在MySQL8.0版本中,可以通过INVISIBLE、VISIBLE来控制索引的开关:
-
当对一个索引使用INVISIBLE后,会关闭这个索引,优化器在执行SQL时无法发现和使用它。
-
当对一个索引使用VISIBLE后,会将索引从隐藏状态恢复到正常状态。
所谓的隐藏索引,就是指将一个已经创建的索引“藏起来”,被藏起来的索引是无法被优化器探测到的,因此执行SQL语句时,就算语句中显式使用了索引字段,优化器也不会选择走这条索引。
这个特性主要是针对于调优、测试场景而研发的,如果隐藏一个索引后,在压测场景下不会对业务产生影响,如果经过反复测试后依旧不影响SQL性能,那这条索引则可以被判定为无用索引,可以将其删除,隐藏索引的用法如下:
-- 隐藏某张表上已存在的一个索引 alter table 表名 alter index 索引名 invisible; -- 恢复某张表上已存在的一个索引 alter table 表名 alter index 索引名 visible; 复制代码
3.5.3、降序索引
Descending index降序索引是一种索引的特性,不知大家是否还记得之前定义索引的语句呢,如下:
ALTER TABLE tableName ADD INDEX indexName(columnName(length) [ASC|DESC]); 复制代码
在创建索引时,可以通过ASC、DESC来定义一个索引是按升序还是降序存储索引键,但本质上这种语法,在MySQL8.0之前,就算你手动写明了DESC降序,在创建时依旧会默认忽略,也就是本质上还是按升序存储索引键的,当你要对某个倒序索引的字段做倒序时,依旧会发生filesort排序的动作。
到了MySQL8.0官方正式支持降序索引,也就是当对一个字段建立降序索引后,做降序查询时不需要再次排序,可直接根据索引进行取值。
下面来基于MySQL5.1、MySQL8.0举个简单的例子感受一下:
-- 分别在 MySQL5.1、MySQL8.0 中创建一张 zz_table 表 create table zz_table ( id1 int, id2 int, index idx1 (id1 ASC, id2 ASC), index idx2 (id1 ASC, id2 DESC), index idx3 (id1 DESC, id2 ASC), index idx4 (id1 DESC, id2 DESC) ); insert into zz_table values(1,2); 复制代码
上述创建了一张索引的测试表zz_table,其中对于两个字段建立四个索引:全升序、全降序、前降后升、前升后降,然后随便插入了一条数据,接着来看看SQL执行情况:
-- MySQL5.1版本中的测试 explain select * from zz_table order by id1 asc, id2 desc; +----+-------------+----------+------+-----------------------------+ | id | select_type | table | .... | Extra | +----+-------------+----------+------+-----------------------------+ | 1 | SIMPLE | zz_table | .... | Using index; Using filesort | +----+-------------+----------+------+-----------------------------+ -- MySQL8.0版本中的测试 explain select * from zz_table order by id1 asc, id2 desc; +----+-------------+----------+------------+-------+----------------------------------+ | id | select_type | table | partitions | ..... | Extra | +----+-------------+----------+------------+-------+----------------------------------+ | 1 | SIMPLE | zz_table | NULL | ..... | Backward index scan; Using index | +----+-------------+----------+------------+-------+----------------------------------+ 复制代码
重点观察最后一个Extra字段,在MySQL8.0之前的版本中,虽然对id2建立了倒序索引,但实际做倒序查询时依旧会发生Using filesort排序动作,而MySQL8.0中则直接是Backward index scan反向索引扫描,并未触发排序动作。
3.5.4、函数索引
还记得在聊MySQL5.7版本时,最后贴出的其他特性嘛?其中就有一条是引入了隐藏列,实现了类似于Oracle中的函数索引,但其实功能并不健全,而在MySQL8.0中真正的支持了函数索引,也就是基于函数去创建索引,如下:
alter table 表名 add index 索引名(函数(列名)); -- 比如:创建一个将字段值全部转为大写后的索引 alter table t1 add index fuc_upper(upper(c1)); 复制代码
基于某个字段创建一个函数索引后,之后基于该字段使用函数作为查询条件时,依旧可以走索引,如下:
select * from t1 where upper(c1) = 'ABC'; 复制代码
上述这条SQL语句,按照之前《索引应用篇-索引字段使用函数导致失效》中聊到的理论,理论上这条语句由于在=前面使用了函数,显然会导致索引失效,但在MySQL8.0中可创建函数索引,可以支持条件查询时,在=号之前使用函数。
不过有一点需要牢记:使用什么函数创建的索引,也仅支持相应函数走索引,比如上面通过了upper()函数创建了一个索引,因此upper(c1) = 'ABC'这种情况可以走索引,但使用其他函数时依旧会导致索引失效,如:lower(c1) = 'abc'。
3.6、CTE通用表表达式(Common Table Expression)
首先要搞明白这个名称,不是通用表达式,而是通用表、表达式,这个名称上有许多人都叫成通用表达式、公用表达式,这显然是不正确的,因为直接将其中的Table省去了,所以大家在这里要牢记,正确的叫法应该是通用表表达式。
CTE通用表表达式究竟是用来干什么事情的呢?CTE是一个具备变量名的临时结果集,也就是可以将一条查询语句的结果保存到一个变量里面,后续在其他语句中允许直接通过变量名来使用该结果集,语法如下:
with CTE名称 as (查询语句/子查询语句) select 语句; 复制代码
上述的语法是一个普通的CTE用法,同时还有另一种递归的CTE用法,先举个简单的例子来认识一下最基本的用法:
-- MySQL8.0版本之前的子查询语句 select * from t1 where xx in (select xx from t2 where yy = "zzz"); -- MySQL8.0中使用CTE表达式来代替 with cte_query as (select xx from t2 where yy = "zzz") select * from t1 join cte_query on t1.xx = cte_query.xx; 复制代码
观察上述例子,原本语句中需要使用in来对子查询的多个结果集做匹配,使用CTE后可以将子查询的结果集保存在cte_query变量中,后续的语句中可以将其当作成一张表,然后来做连接查询。
其实看到这里,CTE表达式是不是有些类似于临时表的概念?但它会比临时表更轻,查询更快。
除开最基本的表达式外,还有一种名为递归CTE表达式的概念,它是一种递归算法的实现,可以反复执行一段SQL,比如当你要查询标签表中,某个顶级标签下所有的子标签时,它的下级可能也存在其它字标签.....,可能一个顶级标签下面有十八层子标签,这时通过传统的查询语句就无法很好实现,而使用递归的CTE表达式就很简单啦。
递归CTE表达式只需要使用with recursive关键字即可,不过这里我不贴具体实现啦,大家感兴趣的可自行研究明白CTE后再实现该需求。
CTE表达式除开可以与select语句嵌套外,还可以与其它类型的语句嵌套,例如:with delete、with update、with recursive、with with、insert with等,大家感兴趣的也可自行研究,总之CTE在很多情况下确实比较实用~
3.7、窗口函数(Window Function)
窗口函数可谓是MySQL8.0中最大的亮点之一,但在尝试去学习时会发现很难理解,先来看看窗口函数的定义。
窗口函数是一种分析型的OLAP函数,因此也被称之为分析函数,它可以理解成是数据的集合,类似于group by分组的功能,但之前的MySQL版本基于某个字段分组后,会将数据压缩到一行显示,如下:
select * from `zz_users`; +---------+-----------+----------+----------+---------------------+ | user_id | user_name | user_sex | password | register_time | +---------+-----------+----------+----------+---------------------+ | 1 | 熊猫 | 女 | 6666 | 2022-08-14 15:22:01 | | 2 | 竹子 | 男 | 1234 | 2022-09-14 16:17:44 | | 3 | 子竹 | 男 | 4321 | 2022-09-16 07:42:21 | | 4 | 猫熊 | 女 | 8888 | 2022-09-17 23:48:29 | +---------+-----------+----------+----------+---------------------+ select user_id from zz_users group by user_sex; +-----------+ | user_id | +-----------+ | 1,4 | | 2,3 | +-----------+ 复制代码
而窗口函数则不会将数据压缩成一行,也就是表中数据原本是多少行,分组完成后依旧是多少行,窗口函数的语法如下:
[window 窗口函数名 as (window_spec) [, 窗口函数名 AS (window_spec)] ...] 窗口函数名(窗口名/表达式) over ( [partition_defintion] [order_definition] [frame_definition] ) 复制代码
其实这个语法看起来不是特别能让人理解,所以结合具体的场景来举例,语法如下:
窗口函数 over([partition by 字段名 order by 字段名 asc|desc]) 窗口函数 over 窗口名 ... window 窗口名 as ([partition by 字段名 order by 字段名 asc|desc]) 复制代码
一眼看下来,结果还是令人不理解,对吗?这先别急,看不懂也没关系,后面会举例说明,先来看看MySQL8.0中提供了哪些窗口函数呢?如下:
-
序号函数: row_number():按序排列,相同的值序号会往后推,如88、88、89排序为1、2、3。 rank():并列排序,相同的值序号会跳过,如88、88、89排序为1、1、3。 dense_rank():并列排序,相同的值序号不会跳过,如88、88、89排序为1、1、2。
-
分布函数: percent_rank():计算当前行数据的某个字段值占窗口内某个字段所有值的百分比。 cume_dist(): 小于等于当前字段值的行数与整个分组内所有行数据的占比。
-
前后函数: lag(expr,n):返回分组中的前n条符合expr条件的数据。 lead(expr,n):返回分组中的后n条符合expr条件的数据。
-
首尾函数: first_value(expr):返回分组中的第一条符合expr条件的数据。 last_value(expr):返回分组中的最后一条符合expr条件的数据。
-
其它函数: nth_value(expr,n):返回分组中的第n条符合expr条件的数据。 ntile(n):将一个分组中的数据再分成n个小组,并记录每个小组编号。
这样看过去似乎也有些令人迷糊,毕竟之前对窗口函数则这块接触比较少,因此下面来举个简单的例子切身感受一下(还是以之前的用户表为例),需求如下:
-
按性别分组,并按照ID值从大到小对各分组中的数据进行排序,最后输出。
这需求一听就知道一条SQL绝对搞不定,在之前版本中需要创建临时表来实现,借助临时表来拆成多步完成,而在MySQL8.0中则可以借助窗口函数轻松实现,如下:
select -- 使用 row_number() 序号窗口函数 row_number() over( -- 基于性别做分组,然后基于 ID 做倒序 partition by user_sex order by user_id desc ) as serial_num, user_id, user_name, user_sex, password, register_time from zz_users; +------------+---------+-----------+----------+----------+---------------------+ | serial_num | user_id | user_name | user_sex | password | register_time | +------------+---------+-----------+----------+----------+---------------------+ | 1 | 4 | 猫熊 | 女 | 8888 | 2022-09-17 23:48:29 | | 2 | 1 | 熊猫 | 女 | 6666 | 2022-08-14 15:22:01 | | 1 | 3 | 子竹 | 男 | 4321 | 2022-09-16 07:42:21 | | 2 | 2 | 竹子 | 男 | 1234 | 2022-09-14 16:17:44 | +------------+---------+-----------+----------+----------+---------------------+ 复制代码
上述这条SQL就是基于序号窗口函数的实现,其实发现会尤为简单,观察执行结果也会发现,使用窗口函数分组后,并不会将数据压缩到一行,而是将同一分组的数据在结果集中相邻显示。
上面的例子中就演示了最为简单的窗口函数用法:函数名() over(数据处理),但实际情况中可以灵活的根据需求变动,但如若想要很好的使用窗口函数,那还需要大家多加以练习,对于这块大家可参考《MySQL官网-窗口函数示例》、或《宋红康老师的视频教学》。
3.8、MySQL8.0中的其他特性
在前面的内容中,就已经将MySQL8.0中较为重要的变更和特性做了详细阐述,但MySQL8.0整体的改变也比较大,因此这里再列出一些其它方面的特性,如下:
-
将默认的UTF-8编码格式从latin替换成了utf8mb4,后者包含了所有emoji表情包字符。
-
增强NoSQL存储功能,优化了5.6版本引入的NoSQL技术,并完善了对JSON的支持性。
-
InnoDB引擎再次增强,对自增、索引、加密、死锁、共享锁等方面做了大量改进与优化。
-
支持定义原子DDL语句,即当需要对库表结构发生变更时,变更操作可定义为原子性操作。
-
支持正则检索,新增REGEXP_LIKE()、EGEXP_INSTR()、REGEXP_REPLACE()、REGEXP_SUBSTR()等函数提供支持。
-
优化临时表,临时表默认引擎从Memory替换为TempTable引擎,资源开销少,性能更强。
-
锁机制增强,除开前面聊到的锁特性变更外,新引入了一种备份锁,获取/释放锁语法如下: 获取锁:LOCK INSTANCE FOR BACKUP、释放锁:UNLOCK INSTANCE
-
Bin-log日志增强,过期时间精确到秒,利用zstd算法增强了日志事务的压缩功能。
-
安全性提高,认证加密插件更新、密码策略改进、新增角色功能、日志文件支持加密等。
-
引入资源组的概念,支持按业务优先级来控制工作线程的CPU资源抢占几率。
.......:更多请参考《MySQL官网-8.0版手册》。
四、MySQL特性篇总结
在这章中咱们介绍了MySQL几个重要的里程碑版本,显然每个版本中都对前版本中做了不小的优化,尤其是MySQL8.0中的新特性和新优化点十分具备吸引力。但线上环境已有数据的情况下,也不适合再做迁移,毕竟数据迁移是一件十分麻烦的事情,有时候甚至比你重构一个Java项目更累,因此如果你的数据库版本目前足以支撑系统的正常运转,那就没有必要去做版本迁移。
但如若你的项目数据库已经抵达瓶颈,并且升级数据库版本着实能够解决目前的困扰,这种情况下则可以尝试升级数据库版本,将旧版本的数据迁移到新版本的数据库中,但这类工作在有专业人士负责的情况下,最好不要自己去插手,毕竟一些企业中会有专门的DBA方向。
最后,在本章节中也仅介绍了一些较为重要的新特性和优化项,但MySQL每个版本中都有一些修修补补的小特性、小改进,这里就不展开叙说了,大家感兴趣的可直接翻阅MySQL官网提供的手册,以此来详细得知各个版本中的细节改进。
都已经 2022 年了,这些 Github 使用技巧你都会了吗?
最近经常有小伙伴问我如何根据最新的技术进展,让自己学的东西不过时,了解到这些需求我也特别的感慨,其实在计算机这个领域,尤其是皮汤所在的前端,更是日新月异,所以这个问题还需要细细道来。
养成良好习惯
感觉跟不上技术的进展,本质上还是离前沿太远,可能是因为业务繁忙,有可能是因为找不到路子,但归根到底可能是因为没有养成良好的习惯。
给自己每天 15-30 分钟的 “扩展视野时间”,这个时间最好在早上。这个时间段你可以去访问 Github Trending 榜单,查看自己所在领域的技术进展:https://github.com/explore

可以说 Github Trending 是一个类似今日头条的 Feed 流,你平时逛 Github 越多,关注的感兴趣的人越多,Star 的项目越多,你会发现这条 Feed 流会越智能,一旦你所在的领域有新鲜的技术项目出来,那么你只要刷一下这个 Feed 流,立马能够掌握到最新的前沿技术进展。
为什么让你刷 Trending 流,其实还有个原因就是,它不像抖音、今日头条,是一个无限的黑洞,而是有限的,在一个时间段内,它只会有几十条存在,而且可能绝大部分还一样,这样一个你可以快速的了解最新的事情,再一个不会因为 “日新月异” 而感到焦虑。
注意,Trending 流是有限的。

经营自己的 “技术关系”
你喜欢 CSS 吗?CSS 领域最前沿的技术进展当属 TailwindCSS 这类 “实用类优先” 的 CSS 框架了,那我可以做些什么来跟进它的技术进展呢?
第一步:Star 这个项目。
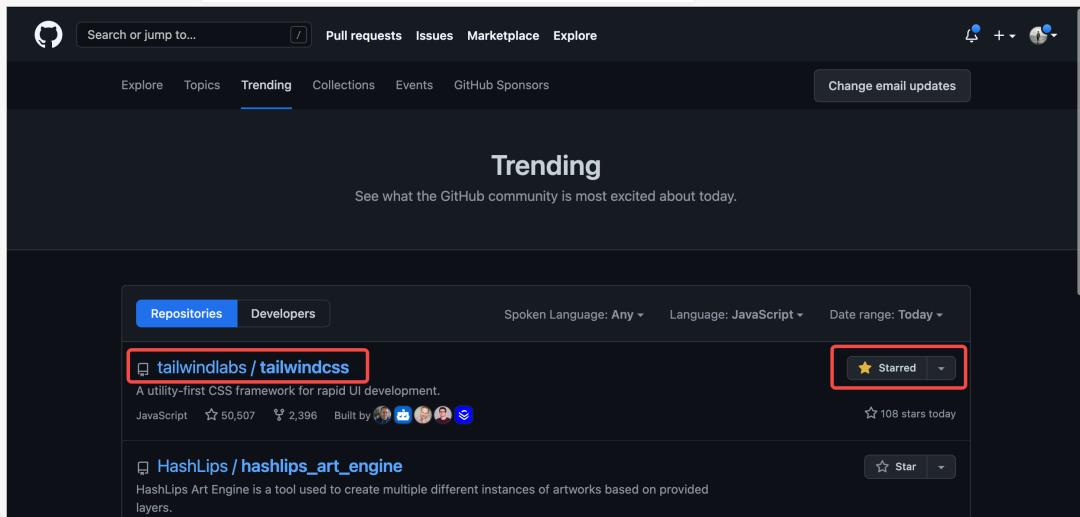
第二步:找到这个仓库的贡献者的前几名,关注他们!


可以看看大佬们是如何努力工作的,Github 几乎全绿!🌚
当你关注他们之后,之后你已进入 Github 就可以在你自己的关注 Feed 流里面了解到这些人最近的动态,比如 Star 了哪些项目?Follow 了那些人?发布了那些包更新?久而久之,当你关注的人越来越多,你的个人关注 Feed 流就成为了你每天获取新技术信息的来源,站在这些 “巨人” 的肩膀上,获取高效的信息!
再近一步,找到乐趣
这些大牛可能还会参与一些其他的项目,或者加入或创建了一些其他的 Github 组织,尝试顺着这些项目、组织,进行二次探索,继续 Star 更多的项目、Follow 更多的人,然后慢慢找到自己的兴趣点,并以此兴趣点为基础,在某 1 个开源项目驻足下来,尝试为其进行贡献,如改个文档的拼写问题,帮助翻译,或者开始尝试看源码,修复一些 BUG 或者提交一些代码贡献。
比如 Node.js 大牛苏千:

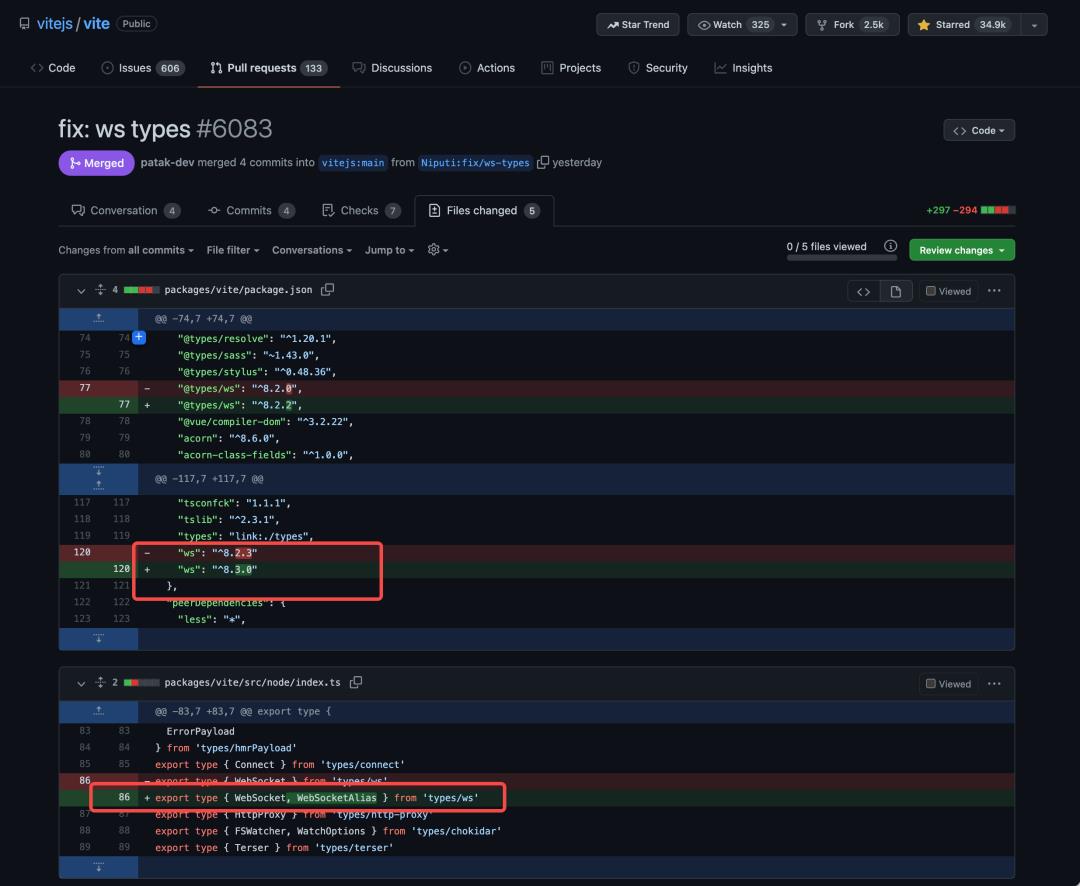
当你花了足够长的时间在这个上面之后,你会发现突然某一天,你的提交被某个大牛合并进了仓库,你成为了某知名开源项目的 Contributor !🎉 这个幸福感是不言而喻的。
比如给 Vite 提交一些极小的改进:https://github.com/vitejs/vite/pull/6083/files
开始耕耘自己的领地
如果你能坚持经历上面几个阶段,那么你现在可能 Follow 了很多 “技术明星”,Star 了很多感兴趣的项目,你的个人关注 Feed 流已经有了很多内容,同时也养成了良好的关注 Github Trending 榜单的习惯。更近一步,你可能通过一些很 “Hack” 的技巧成为了一些知名开源项目的 Contributor,当然我承认这需要一些耐心,并且你可能还需要一些机遇,但是当你长期 Focus 在 1 个或几个项目上时,这些机遇无疑会被放大,你已经在技术社区里面有了一点原始的积累了。

接下来你可以尝试去开拓自己的内容,尝试提交自己平时的项目代码在 Github 上,让自己的榜单开始 “绿” 起来。
至少先达到如下的地步:

然后开始像这样进军:
你可能会好奇这个 “恐怖” 的人是谁?
好了,不装了🙅🏻♀️,那就是大神阮一峰:https://github.com/ruanyf

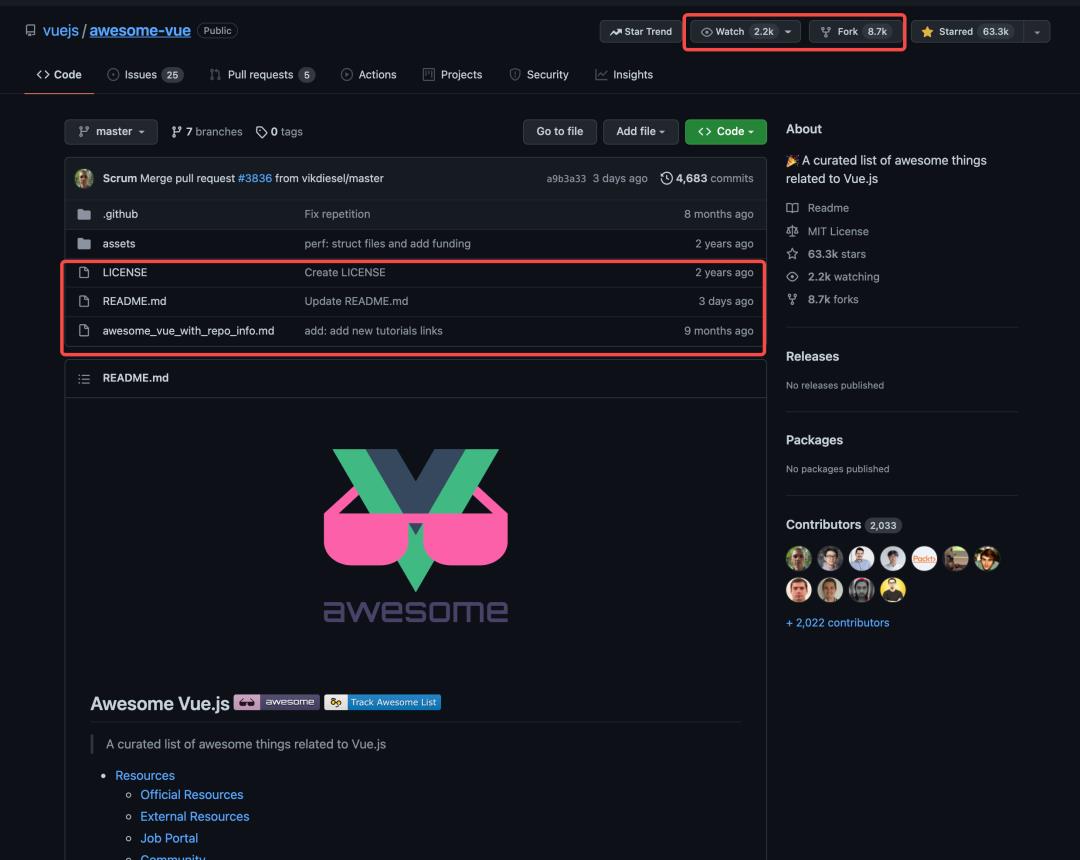
当然如果短时间内你并没有找到你合适的想法去提交自己的 Github,那么你可以去尝试模仿大多数的 “一个文件” 的贡献,即整理一个 README.md,将自己平时看 Github Trending 时觉得好的内容记录下来,系统的分类并整理成一个榜单,随着你的坚持,你可能能达到如下效果:https://github.com/vuejs/awesome-vue
让事情再更有趣一点
当你持续在输出内容之后,一开始你会经历一个比较艰难的适应期,比如坚持了几周因为事情太忙就搁置了,所以这个时候你需要找点乐子,让自己保持新鲜感。
你会发现 Github 已经可以写好看的自我介绍了:https://github.com/anuraghazra/github-readme-stats
比如这个:

比如记录的语言使用情况的:

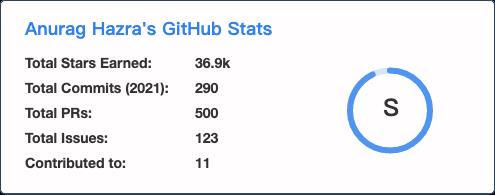
比如记录你的 Star、Commits、PR、Issue 情况的:
把介绍写成诗句:https://github.com/anuraghazra

简化流程,让点击更近一步
如果你希望自己能够时刻被提醒,离打开 Github 更近一点,更频繁一点,同时又能同时兼顾项目与文章,那么掘金开发者插件会是一个很好的选择:https://juejin.cn/extension
安装之后,每次打开一个新的浏览器窗口,都会展示插件的网页:

你可以看到掘金文章、Github Trending 的内容,还有掘金沸点,极其适合上班摸鱼。

推销你的成果
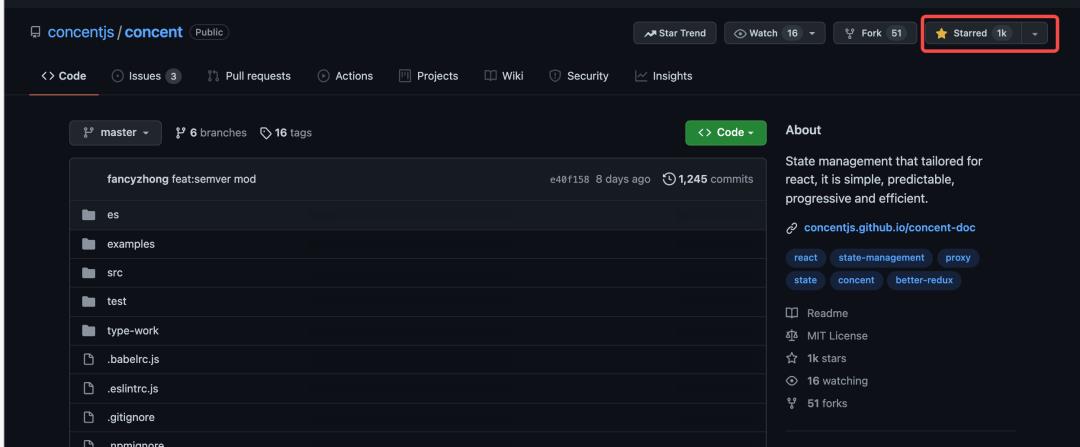
当你有了酷炫的 Github 个人主页,有了持续积累的 “README” 式的 Github 仓库,或者是自己的项目,那么你可以尝试写文章介绍自己的仓库、自己的主页,推销自己的 Github 项目或个人名片,以获取更多的 Star 和 Follower:

比如我之前一值关注的一个老哥,写了个 React 的状态管理库,然后在各平台推销:

现在已经 1K Star 了:https://github.com/concentjs/concent
一个坚持且厉害的老哥:

一些额外的渠道
当然 Github 其实不是一个社交网络,只能基于项目,没法发布消息,即时性还是不够的,如果你追求即时性,那么你可以尝试去关注大佬的 Twitter,订阅一些技术项目的博客。
比如说尤大的 Twitter:https://twitter.com/youyuxi

或者 Next.js 的博客:https://nextjs.org/blog

回归初心
其实归根结底,这整个流程都是希望你能够养成一个良好的习惯,同时通过一系列 “刺激” 让你爱上技术探索,并以某个可达到的目标进行努力,如创建一个项目,并推销它,然后获得很多 Star 或 Follower。
在这个过程中,你会为了达到某个目标而努力把一个项目的源码看懂,然后输出一些见解到技术社区,然后反哺自己去开发一些项目解决当前的问题,如此往复,遵循兴趣而非带着焦虑去前行,相信你能够在技术探索的道路上走得更远!💪

有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号

好文章,我在看❤️
以上是关于玩转MySQL:都2022年了,这些数据库技术你都知道吗的主要内容,如果未能解决你的问题,请参考以下文章