机器学习-scikit-learn
Posted 喵代王-香菜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习-scikit-learn相关的知识,希望对你有一定的参考价值。
文章目录
前言
scikit-learn是Python中最流行的机器学习库之一,它提供了各种各样的机器学习算法和工具,包括分类、回归、聚类、降维等。
scikit-learn的优点有:
- 简单易用:scikit-learn 的接口简单易懂,可以让用户很容易地上手进行机器学习。
统一的API:scikit-learn 的 API 非常统一,各种算法的使用方法基本一致,使得学习和使用变得更加方便。 - 大量实现了机器学习算法:scikit-learn 实现了各种经典的机器学习算法,而且提供了丰富的工具和函数,使得算法的调试和优化变得更加容易。
- 开源免费:scikit-learn 是完全开源的,而且是免费的,任何人都可以使用和修改它的代码。
- 高效稳定:scikit-learn 实现了各种高效的机器学习算法,可以处理大规模数据集,并且在稳定性和可靠性方面表现出色。
scikit-learn因为API非常的统一而且模型相对较简单所以非常适合入门机器学习。
这里我的推荐方式是结合官方文档进行学习,不仅有每个模型的适用范围介绍还有代码样例。
scikit-learn官网地址
线性回归模型-LinearRegression
LinearRegression模型是一种基于线性回归的模型,适用于解决连续变量的预测问题。该模型的基本思想是建立一个线性方程,将自变量与因变量之间的关系建模为一条直线,并利用训练数据拟合该直线,从而求出线性方程的系数,再用该方程对测试数据进行预测。
LinearRegression模型适用于自变量和因变量之间存在线性关系的问题,例如房价预测、销售预测、用户行为预测等。当然,当自变量和因变量之间的关系为非线性时,LinearRegression模型的表现会比较差。此时可以采用多项式回归、岭回归、Lasso回归等方法来解决。
准备数据集
在抛开其它因素影响后,学习时间和学习成绩之间存在着一定的线性关系,当然这里的学习时间指的是有效学习时间,表现为随着学习时间的增加成绩也会增加。所以我们准备一份学习时间和成绩的数据集。数据集内部分数据如下:
学习时间,分数
0.5,15
0.75,23
1.0,14
1.25,42
1.5,21
1.75,28
1.75,35
2.0,51
2.25,61
2.5,49
使用LinearRegression
- 确定特征和目标
在学习时间和成绩间,学习时间为特征,也即自变量;成绩为标签也即因变量,所以我们需要在准备好的学习时间和成绩数据集中提取特征和标签。
import pandas as pd
import numpy as np
from sklearn.metrics import r2_score, mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# 读取学习时间和成绩CSV数据文件
data = pd.read_csv('data/study_time_score.csv')
# 提取数据特征学习时间
X = data['学习时间']
# 提取数据目标(标签)分数
Y = data['分数']
- 划分训练集和测试集
在特征及标签数据准备好以后,使用scikit-learn的LinearRegression进行训练,将数据集划分为训练集和测试集。
"""
将特征数据和目标数据划分为测试集和训练集
通过test_size=0.25将百分之二十五的数据划分为测试集
"""
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.25, random_state=0)
x_train = X_train.values.reshape(-1, 1)
model.fit(x_train, Y_train)
- 选择模型,对数据进行拟合
将测试集和训练集准备好以后,我们就可以选择合适的模型对训练集进行拟合,以便能够预测出其它特征对应的目标
# 选择模型,选择模型为LinearRegression
model = LinearRegression()
# Scikit-learn中,机器学习模型的输入必须是一个二维数组。我们需要将一维数组转换为二维数组,才能在模型中使用。
x_train = X_train.values.reshape(-1, 1)
# 进行拟合
model.fit(x_train, Y_train)
- 得到模型参数
由于数据集只包含学习时间和成绩两个是一个很简单的线性模型,其背后的数学公式也即y=ax+b,其中y因变量也就是成绩, x自变量也即学习时间。
"""
输出模型关键参数
Intercept: 截距 即b
Coefficients: 变量权重 即a
"""
print('Intercept:', model.intercept_)
print('Coefficients:', model.coef_)
- 回测
上面拟合模型只用到了测试集数据,下面我们需要使用测试集数据对模型的拟合进行一个回测,在使用训练集拟合后,我们就可以对特征测试集进行预测,通过得到的目标预测结果与实际目标的值进行比较,我们就可以得到模型的拟合度了。
# 转换为n行1列的二维数组
x_test = X_test.values.reshape(-1, 1)
# 在测试集上进行预测并计算评分
Y_pred = model.predict(x_test)
# 打印测试特征数据
print(x_test)
# 打印特征数据对应的预测结果
print(Y_pred)
# 将预测结果与原特征数据对应的实际目标值进行比较,从而获得模型拟合度
# R2 (R-squared):模型拟合优度,取值范围在0~1之间,越接近1表示模型越好的拟合了数据。
print("R2:", r2_score(Y_test, Y_pred))
- 程序运行结果
- 根据上述的代码我们需要确定LinearRegression模型的拟合度,也就是这些数据到底适合不适合使用线性模型进行拟合,程序的运行结果如下:
预测结果:
[47.43726068 33.05457106 49.83437561 63.41802692 41.84399249 37.84880093
23.46611131 37.84880093 26.66226456 71.40841004 18.67188144 88.9872529
63.41802692 42.6430308 21.86803469 69.81033341 66.61418017 33.05457106
58.62379705 50.63341392 18.67188144 41.04495418 20.26995807 77.80071653
28.26034119 13.87765157 61.81995029 90.58532953 77.80071653 36.25072431
84.19302303]
R2: 0.8935675710322939
总结
上述模型的拟合度达到了89%,如果你能接受大约10%的误差,则可以使用LinearRegression模型进行预测。当调整训练集大小小于25%时,模型的拟合度稍低于89%,数据集的大小和训练集的大小等因为都会影响模型的拟合度,需要不断尝试找到拟合效果的参数设定。
[机器学习与scikit-learn-4]:scikit-learn机器学习的一般流程与案例演示
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/123120913
目录
第1章 scikit-learn机器学习的一般流程
1.1 概述
本文讨论,使用scikit-learn工具集,让机器对数据数据集进行学习的一般过程。
目的对scikit-learn的机器学习有一个直观的、总体的认识。
我们会发现,整个处理流程的环节与深度学习非常相似,但整个编程过程要比深度学习要简单很多。
整个处理过程,无非就是在调用scikit-learn的API函数,并且不同的场景,调用的过程都相似,这是也是本文存在的基础。不同的,仅仅是不同数据集,可能调用的部分API函数不同而已,选择的模型不同而已。
1.2 前置条件
(1)scikit-learn python库已经正确的安装
(2)有现有的数据集
- 官网的提供的数据集
- 自己的私有数据集
1.3 一般流程
(1)模型规划
(2)数据的预处理
在把数据送入到模型中进行训练前,需要对数据进行预处理
- 数据的获取:通过Scikit-learn提供的工具,从外部读取数据到内存,并按照期望的方式组织数据
- 数据预处理:对于读取的数据进行预处理,如过滤无效数据、对强化、变形等等
- 特征的提取:从数据中提取特征数据,这些特征数据作为模型的输入(而不是原始的数据)
- 特征的选择:在众多提取的特征中,根据需要选择一定的特征数据,用于最终模型的训练。
(3)算法/模型选择:对于特定的现实问题,选择合适的模型
- 模型初选:针对特定的数据集和要解决的问题,从Scikit-learn支持的众多的模型中初步选择一个模型。
- 模型训练:用输入数据对模型进行训练(这个过程,运行的时间最长)
- 模型评估:对训练后的模型进行评估
- 模型优化:对训练后的模型进行超参数优化
- 模型终选:比较各种模型和优化结果,选择最终的模型
- 模型存储:把训练好的模型存储起来,以便后续直接使用
第2章 模型规划
2.1 模型地图与模型选择
2.2 导入库
# sklearn数据库
import sklearn
sklearn.__version__
# 数据处理库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
from sklearn import datasets'0.24.1'
第3章 数据预处理与案例演示
3.1 导入数据库
(1)数据集分析
这里以scikit-learn自带的数据集:鸢尾花分类数据集为例。
根据鸢尾花的花萼和花瓣大小,区分鸢尾花的品种,实现一个基础的多分类问题:


Iris 鸢尾花数据集内包含 3 种类别,分别为山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。
- 数据集共 150 条记录,每类各 50 个数据,每条记录有花萼长度、花萼宽度、花瓣长度、花瓣宽度4项特征,通过这4个特征预测鸢尾花卉属于哪一品种。
- iris数据集包含在sklearn库当中,具体在sklearn\\datasets\\data文件夹下,文件名为iris.csv。
- 通常数据文件存储在\\Python36\\Lib\\site-packages\\sklearn\\datasets\\data\\iris.csv。
- 打开iris.csv,数据格式如下:
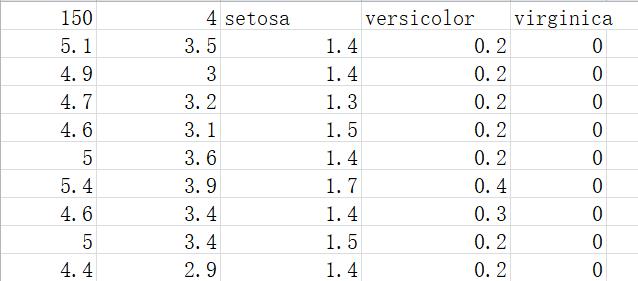
第一行数据意义为:
第1列:150:数据集中数据的总条数
第2列:4:特征值的类别数,即花萼长度、花萼宽度、花瓣长度、花瓣宽度。
第3-5列:setosa、versicolor、virginica:三种鸢尾花名
从第二行及以下数据的意义为:
第一列为花萼长度值, 如5.1或4.9
第二列为花萼宽度值, 如3.5或3
第三列为花瓣长度值,如1.4或1,3
第四列为花瓣宽度值,如0.2, 0.4
第五列对应是种类, 如0,1,2
(2) 导入数据
# 加载sklearn自带的数据集鸢尾花数据集yuān wěi huā
iris = datasets.load_iris()(3)打印样本特征值
print("每个样本特征值:\\n", iris.data)[[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2] [5.4 3.9 1.7 0.4] [4.6 3.4 1.4 0.3] [5. 3.4 1.5 0.2]
..........................
(4)打印样本标签值
print("样本标签值:\\n", iris['target'])样本标签值:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
(5)进一步通过pd.DataFrame可视化数据
# 利用dataframe 做简单的可视化分析
# 把特征数据导入df中
df = pd.DataFrame(iris.data, columns = iris.feature_names)
# 把标签数据导入df中
df['target'] = iris.target
# 打印数据12*8是图片尺寸
df.plot(figsize = (12,8))

从图片中可以看出:
- 有三种target标签类型0,1, 2, 并且是按顺序排放的,先是类型0, 然后是类型1, 最后是类型2
- 不同类型的sepal length,petal length,petal width这三种特征则不同,类型越靠后,值越大。
- 不同类型的peta width这个特征,基本相同,无法通过该特征来区分花的类型。
3.2 数据预处理
预处理数据包括:
数据的标准化,数据的归一化,数据的二值化,非线性转换,数据特征编码,处理缺失值等。
# 定义一个在最大值和最小值区间内的放缩器
scaler = preprocessing.MinMaxScaler()
# 进行放缩,
scaler.fit(iris.data) #先fit
# 进行数据转换,映射到[0,1]区间,获得转换后的样本数据
data = scaler.transform(iris.data)
print(data)[[0.22222222 0.625 0.06779661 0.04166667] [0.16666667 0.41666667 0.06779661 0.04166667] [0.11111111 0.5 0.05084746 0.04166667] [0.08333333 0.45833333 0.08474576 0.04166667] [0.19444444 0.66666667 0.06779661 0.04166667] [0.30555556 0.79166667 0.11864407 0.125 ] [0.08333333 0.58333333 0.06779661 0.08333333] [0.19444444 0.58333333 0.08474576 0.04166667] [0.02777778 0.375 0.06779661 0.04166667] [0.16666667 0.45833333 0.08474576 0. ]
# 获取样本标签
target = iris.target
print(target)[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
3.3 特征的提取
NA
3.4 特征的选择
NA
3.5 构建训练样本
# 把数据集分割训练样本:训练集(2/3) + 测试集(1/3)
X_train,X_test,y_train,y_test = train_test_split(data,target,test_size = 1/3)
# 显示样本个数
len(X_train),len(X_test)(100, 50)第4章 算法/模型选择与案例演示
4.1 模型初选:
(1)模型选择
针对特定的数据集和要解决的问题,从Scikit-learn支持的众多的模型中初步选择一个模型。
根据问题特点选择适当的估计器estimater模型:分类(SVC,KNN,LR,NaiveBayes,...) 回归
(Lasso,ElasticNet,SVR,...) 聚类(KMeans,...) 降维(PCA,...)
https://blog.csdn.net/HiWangWenBing/article/details/123121592 https://blog.csdn.net/HiWangWenBing/article/details/123121592
https://blog.csdn.net/HiWangWenBing/article/details/123121592

- 我们当前的问题是根据特征预测鸢尾花的类型,属于带标签的分类问题
- 并且samples个数为150个小于100K,所以根据sklearn使用地图我们选择Linear SVC模型进行分类。
(2)构建模型
from sklearn import svm
# 构建模型
model = svm.SVC(kernel = 'linear',C = 1,probability=True)
print(model)SVC(C=1, kernel='linear', probability=True)
备注:模型的构建非常简单
4.2 模型训练:训练集
用输入数据对模型进行训练(这个过程,运行的时间最长)
#用训练集数据喂养模型:用训练数据训练模型
model.fit(X_train,y_train) 4.3 模型测试:测试集
对训练后的模型进行评估
(1)测试训练好的模型:分类预测
# 用测试集数据测试
model.predict(X_test) - y_testarray([ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
备注:
0:表示预测结果与标签一致
非0:表示预测结果与标签不一致,这里有两个值预测错误
(2)测试训练好的模型:可性能预测
model.predict_proba(X_test)array([[0.00322914, 0.00130519, 0.99546567],
[0.98579331, 0.00775802, 0.00644868],
[0.0141099 , 0.11239802, 0.87349208],
[0.01577928, 0.88639592, 0.0978248 ],
[0.9708529 , 0.01675066, 0.01239643],
[0.95091453, 0.03030118, 0.01878429],
[0.01190137, 0.98138338, 0.00671525],
[0.96241814, 0.02589007, 0.01169179],
[0.97402273, 0.01467871, 0.01129856],
[0.03436368, 0.95653188, 0.00910444],
[0.0098553 , 0.01129788, 0.97884682],
[0.02137946, 0.33521393, 0.64340661],
............................................................................
每一行表示一个测试样本的可能性预测结果。
[0.00322914, 0.00130519, 0.99546567],
表示:
类型1的可能性为:0.00322914
类型2的可能性为: 0.00130519
类型3的可能性为: 0.99546567
(3)查看测试集上模型的得分
#查看模型的得分,
#对不同类型的模型有不同的评分算法,由score方法内部所定义
model.score(X_test,y_test)0.96
备注:正确率96%
4.4 模型评估:测试集
模型的评估和模型的优化相关功能都在sklearn.model_selection中。
除了使用estimator的score函数简单粗略地评估模型的质量之外,
在sklearn.metrics模块针对不同的问题类型提供了各种评估指标并且可以创建用户自定义的评估指
标。
# 分类模型评分报告
from sklearn.metrics import classification_report
report = classification_report(target,clf.predict(data), target_names = iris.target_names)
print(report) precision recall f1-score support
setosa 1.00 1.00 1.00 50
versicolor 0.92 0.98 0.95 50
virginica 0.98 0.92 0.95 50
accuracy 0.97 150
macro avg 0.97 0.97 0.97 150
weighted avg 0.97 0.97 0.97 150
(1)每个种分类的评估指标
- precision:准确率
- recall:召回率
- f1-score:f1分数
(2)整个测试集的整体的评估指标
- accuracy:整体的正确率
关于每个评估指标的含义,后续有专门讨论
可以采用交叉验证方法评估模型的泛化能力,能够有效避免过度拟合。
K折交叉验证(K=10)示意图

from sklearn.model_selection import cross_val_score
#采用5折交叉验证
scores = cross_val_score(clf,data,target,cv=5)
print(scores)
#平均得分和95%置信区间
print("Accuracy: %0.2f(+/-%0.2f)"%(scores.mean(),scores.std()*2))[0.96666667 0.96666667 0.96666667 0.93333333 1. ] Accuracy: 0.97(+/-0.04)
4.5 模型优化:
对训练后的模型进行超参数优化
优化模型的方法包括:
网格搜索法,随机搜索法,模型特定交叉验证,信息准则优化。
网格搜索法在指定的超参数空间中对每一种可能的情况进行交叉验证评分并选出最好的超参数组
合。
在上述模型中:
model = svm.SVC(kernel = 'linear',C = 1,probability=True)
- 超参数kernel='linear'。
- C = 1
- probability=True
用上述超参数和数据集,精度为:0.97
这个参数是最优的吗?有没有更好的参数参数,使得精度可以适当的提升。
超参数是不直接在估计器内学习的参数。在 scikit-learn 包中,它们作为估计器类中构造函数的参数进行传递。
典型的例子有:用于支持向量分类器的 C 、kernel 和 gamma ,用于Lasso的 alpha等。
搜索超参数空间以便获得最好交叉验证分数的方法是可能的而且是值得提倡的。
搜索超参数空间以优化超参数需要明确以下方面:
- 估计器
- 超参数空间
- 交叉验证方案
- 打分函数
- 搜寻或采样方法(网格搜索法或随机搜索法)
优化模型的方法包括 网格搜索法,随机搜索法,模型特定交叉验证,信息准则优化
(1)网格搜索法 GridSearchCV
所谓网格:就是预先通过网格的方式给定每个超参数的可能数值,各种超参数可能的数值,组成了二维网格。
网格搜索法在指定的超参数空间中对每一种可能的情况进行交叉验证评分并选出最好的超参数组
合。使用网格搜索法或随机搜索法可以对Pipeline进行参数优化,也可以指定多个评估指标。
(2)随机搜索法 (RandomizedSearchCV)
随机搜索法和网格搜索法作用类似,但是只在超参数空间中进行指定次数的不同采样。采样次数通
过n_iter参数指定,通过调整其大小可以在效率和性能方面取得平衡。其采样方法调用
ParameterSampler函数,采样空间必须用字典进行指定。
网格搜索法只能在有限的超参数空间进行暴力搜索,但随机搜索法可以在无限的超参数空间进行随
机搜索。
4.6 模型终选:
比较各种模型和优化结果,选择最终的模型
第5章 模型存储的保存与加载
把训练好的模型存储起来,以便后续直接使用。
可以使用python内置的pickle模块或将训练好模型保存到磁盘或字符串,以便将来直接使用,而不
需要重复训练。
对于sklearn,使用joblib会更加有效,但是joblib只能保存到磁盘而不能保存成字符串。
5.1 使用pickle
import pickle
model_saved = pickle.dumps(model) #保存模型成字符串
print(model_saved)b'\\x80\\x04\\x95\\x8d\\x0f\\x00\\x00\\x00\\x00\\x00\\x00\\x8c\\x14sklearn.svm._classes\\x94\\x8c\\x03SVC\\x94\\x93\\x94)\\x81\\x94\\x94(\\x8c\\x17decision_function_shape\\x94\\x8c\\x03ovr\\x94\\x8c\\nbreak_ties\\x94\\x89\\x8c\\x06kernel\\x94\\x8c\\x06linear\\x94\\x8c\\x06degree\\x94K\\x03\\x8c\\x05gamma\\x94\\x8c\\x05scale\\x94\\x8c\\x05coef0\\x94G\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x8c\\x03tol\\x94G?PbM\\xd2\\xf1\\xa9\\xfc\\x8c\\x01C\\x94K\\x01\\x8c\\x02nu\\x94G\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x8c\\x07epsilon\\x94G\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x00\\x8c\\tshrinking\\x94\\x88\\x8c\\x0bprobability\\x94\\x88\\x8c\\ncache_size\\x94K\\xc8\\x8c\\x0cclass_weight\\x94N\\x8c\\x07verbose\\x94\\x89\\x8c\\x08max_iter\\x94J\\xff\\xff\\xff\\xff\\x8c\\x0crandom_state\\x94N\\x8c\\x07_sparse\\x94\\x89\\x8c\\x0en_features_in_\\x94K\\x04\\x8c\\rclass_weight_\\x94\\x8c\\x15numpy.core.multiarray\\x94\\x8c\\x0c_reconstruct\\x94\\x93\\x94\\x8c\\x05numpy\\x94\\x8c\\x07ndarray\\x94\\x93\\x94K\\x00\\x85\\x94C\\x01b\\x94\\x87\\x94R\\x94(K\\x01K\\x03\\x85\\x94h\\x1f\\x8c\\x05dtype\\x94\\x93\\x94\\x8c\\x02f8\\x94\\x89\\x88\\x87\\x94R\\x94(K\\x03\\x8c\\x01<\\x94NNNJ\\xff\\xff\\xff\\xffJ\\xff\\xff\\xff\\xffK\\x00t\\x94b\\x89C\\x18\\x00\\x00\\x00\\x00\\x00\\x00\\xf0?\\x00\\x00\\x00\\x00\\x00\\x00\\xf0?\\x00\\x00\\x00\\x00\\x00\\x00\\xf0?\\x94t\\x94b\\x8c\\x08cla
model_loaded = pickle.loads(model_saved) #从字符串加载模型
print(model_loaded)
model_loaded.predict(data)SVC(C=1, kernel='linear', probability=True)
Out[67]:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
5.2 使用joblib
import joblib
joblib.dump(model,'model_saved_joblib.pkl') #保存模型到文件['model_saved_joblib.pkl']
model_loaded = joblib.load('model_saved_joblib.pkl') #加载模型
print(model_loaded)
model_loaded.predict(data)SVC(C=1, kernel='linear', probability=True)
Out[78]:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
结束语:
- 使用传统的机器学习的学习过程,相比于深度学习,要简单很多
- 模型训练的时间相比于深度学习,要短很多
- 整个流程已经规范化
- scikit-learn屏蔽了算法的细节,只需要其提供的API函数,就可以方便对模型训练、预测和评估
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/123120913
以上是关于机器学习-scikit-learn的主要内容,如果未能解决你的问题,请参考以下文章