python用tkinter做一个最近很火的强制表白神器
Posted 微小冷
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python用tkinter做一个最近很火的强制表白神器相关的知识,希望对你有一定的参考价值。
文章目录
tkinter系列:
尽管Python提供了多个消息框已经能够满足大部分正常人的需求,但并不够灵活,所以有的时候不得不自定义消息框。
新建窗口
消息框的本质是一个窗口、一段信息,外加两个按钮
import tkinter as tk
FONT= ("微软雅黑", 20)
def msgBox(txt, yesFunc=None, noFunc=None):
win = tk.Tk()
win.title("started")
win.geometry("400x200+300+100")
label = tk.Label(win,text=txt, font=FONT)
label.pack(side=tk.TOP,expand=tk.YES,fill=tk.BOTH)
btnYes = tk.Button(win, text="是", width=8,
font=FONT, command = lambda : yesFunc(win))
btnYes.pack(side=tk.LEFT,expand=tk.YES,fill=tk.Y)
btnNo = tk.Button(win, text="否", width=8,font=FONT)
btnNo.bind("<Enter>", lambda evt: noFunc(evt, win))
btnNo.pack(side=tk.RIGHT,expand=tk.YES,fill=tk.Y)
msgBox("你是不是喜欢我?")
FONT是一个全局变量,表示字体及其大小,在label和button创建的时候,会通过font参数进行设置。
pack是一种布局方式,顾名思义,就是打包。如果把窗口想象成是一个箱子,那么打包肯定是哪里有空打哪里。比如最下面放了一层衣服,没地方放了只能放在第二层;如果第二层只放了一个砖头,那么其他位置还有空间,于是可以贴着砖头再放一个砖头。
在上面的案例中,将label从上面压下来,然后下面左右两侧分别放置一个按钮。
其中,无论是还是否,都需要对窗口进行操作,所以回调函数使用了lambda表达式,从而能够对窗口进行操作。<Enter>表示当鼠标浮动在组件上方时响应,其回调函数需要输入一个参数evt。
效果如下
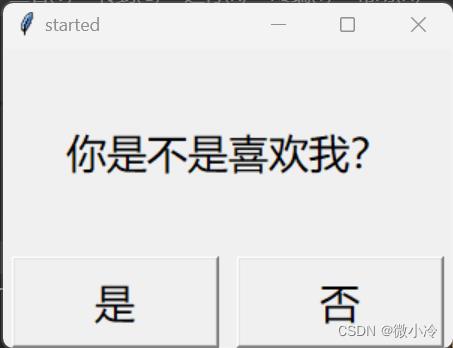
关闭窗口
接下来写是的逻辑,即关闭现有窗口后,弹出一个新的窗口,新的窗口只需要有一个
def yesFunc(win):
x, y = win.winfo_x(), win.winfo_x()
win.destroy()
win = tk.Tk()
win.geometry(f"400x200+x+y")
txt = "放学去房后小树林\\n不见不散\\n嘿嘿嘿"
label = tk.Label(win,text=txt, font=FONT)
label.pack(side=tk.TOP,expand=tk.YES,fill=tk.BOTH)
btn = tk.Button(win, text="好的呀", width=12, font=FONT,
command=lambda:win.destroy())
btn.pack(side=tk.TOP)
msgBox("你是不是喜欢我?", yesFunc)
destroy即关闭当前窗口。在当前窗口被关闭后,在原来窗口的位置处新建一个窗口,win_winfo_x, win_winfo_y用于获取窗口位置。
效果如下
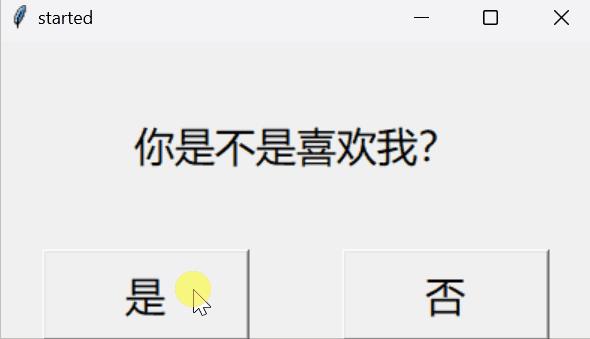
挪动窗口
然后写否的逻辑,当鼠标悬浮在否的按钮上时,挪动窗口的位置。由于
import random
def randInt(a, b):
r = random.randint(-a, a)
while abs(r) < abs(b):
r = random.randint(-a, a)
return r
def noFunc(evt, win):
x, y = win.winfo_x(), win.winfo_x()
x += randInt(100, 80)
y += randInt(30, 20)
win.geometry(f"400x200+x+y")
msgBox("你是不是喜欢我?", yesFunc, noFunc)
通过geometry函数,不仅可以再创建窗口的时候声明窗口位置,而且可以随时随地修改窗口的位置。这样一来,当鼠标浮动在否按钮上的时候,甚至还没点击,窗口就躲开了。
效果如下
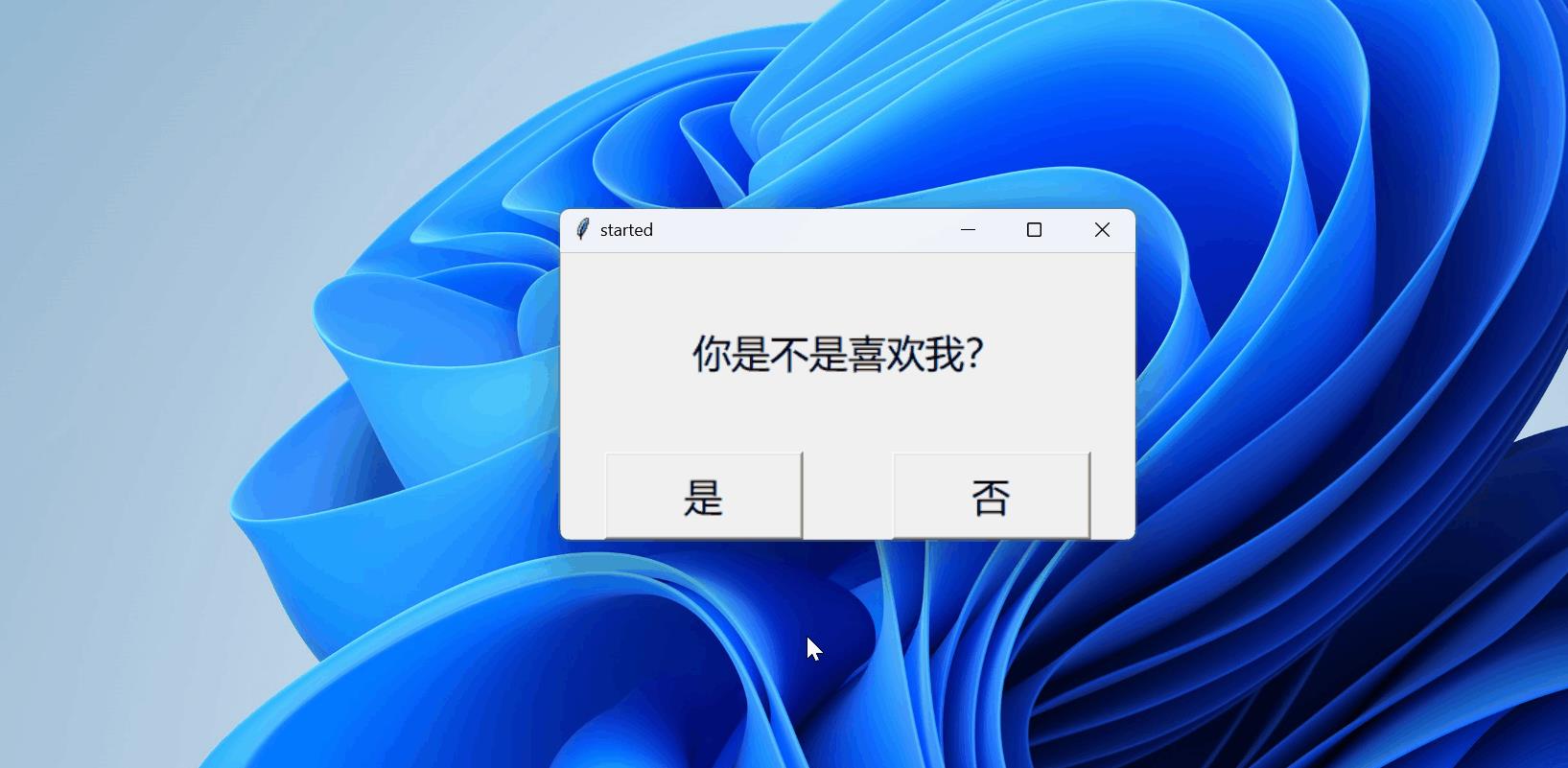
10分钟用Python爬取最近很火的复联4影评
欲直接下载代码文件,关注我们的公众号哦!查看历史消息即可!

《复仇者联盟4:终局之战》已经上映快三个星期了,全球票房破24亿美元,国内票房破40亿人民币。
虽然现在热度逐渐下降,但是我们还是恬不知耻地来蹭一蹭热度。上映伊始《复联4》的豆瓣评分曾破了9分。
后来持续走低,现在《复联4》的评分稳定在8.6分。虽然豆瓣日常被人吐槽注水严重,恶意评分很多,但是由于它好爬鸭~,我们还是选择豆瓣作为爬取对象。豆瓣的长评论有文字和图片等其它元素,简单起见,这次只爬短评。
?在浏览器中查看豆瓣关于复联4的短评,先来看看url的结构:
https://movie.douban.com/subject/26100958/comments?start=20&limit=20&sort=new_score&status=P
可见,我们可以通过修改start的值进入不同的页面:
右键查看源代码可以看到浏览器获取到的html页面代码。Ctrl F搜索第一条影评的关键词,快速定位到影评的标签:
可以看到影评内容在span标签中,class为“short”。
总览一下爬取内容的步骤:
1) 访问url,获取html页面文本,这一步我们要用到的是requests模块。
2) 解析返回的文本,提取出爬虫内容,这一步要用的是beautifulSoup模块。
这两个模块都可以通过pip直接下载。
首先是main函数:
def main():
discuss = []
a = 0
for i in range(0,100,20):
url = 'https://movie.douban.com/subject/26100958/comments?start='+ str(i) +'&limit=20&sort=new_score&status=P'
HTMLpage = getHTML(url)
#print(HTMLpage)
for t in parseHTML(HTMLpage):
discuss.append(t)
for i in discuss:
print(str(a) + ':' + i)
# print(i)
a = a + 1由于豆瓣一页显示20条影评,我们爬前100条,所以这里访问了前5个页面:
def getHTML(url):
try:
r = requests.get(url)
r.raise_for_status()
print("get html successfully")
r.encoding = 'utf-8'
#print(r.text)
return r.text
except:
return ""在getHTML函数中,我们申请访问目标页面,并返回html页面文本。注意这里应该将编码方式设置为utf-8,实测如果设置成r.encoding = r.apparent_encoding,程序并不能猜测到正确的编码方式。
当r.raise_for_status() 没有抛出异常时,程序通知我们获取html成功。如果有异常,返回空字符串。
下一步是解析:
如前所述影评是class为short的span,所以可以直接使用bs4的find_all()函数得到一个含有所有影评的tag的列表。我们只需要把tag中的文字提取出来就可以返回到主函数了。
首先要生成一个beautifulSoup类的对象,使用html的解析器。html页面是树状分布的,可以通过各种树的遍历找到我们需要的标签,这里bs4提供了一个简单粗暴的find_all,可以直接使用。
find_all()函数返回的是一个保存着tag的列表。
def parseHTML(html):
try:
soup = BeautifulSoup(html,"html.parser")
A = soup.find_all('span',attrs = 'class':'short')
B = []
for i in A:
B.append(i.get_text())
return B
except:
return []用get_text函数去掉span标签,只留下内容的文本,加入到B列表里。然后就可以返回了。同理,如果出错了,返回空列表。
好了以上就是一个非常简单的小爬虫,通过修改爬取的数量可以爬取任意页面的评论。当然了后续还会对这些数据进行一些有趣的分析,请关注我们。同时因为作者本人能力有限,本系列可能又要无限托更了/呲牙
下附完整版代码和运行结果【代码下载移步留言区】:
import requests
from bs4 import BeautifulSoup
def getHTML(url):
try:
r = requests.get(url)
r.raise_for_status()
print("get html successfully")
r.encoding = 'utf-8'
#print(r.text)
return r.text
except:
return ""
def parseHTML(html):
try:
soup = BeautifulSoup(html,"html.parser")
A = soup.find_all('span',attrs = 'class':'short')
B = []
for i in A:
B.append(i.get_text())
return B
except:
return []
def main():
discuss = []
a = 0
for i in range(0,100,20):
url = 'https://movie.douban.com/subject/26100958/comments?start='+ str(i) +'&limit=20&sort=new_score&status=P'
HTMLpage = getHTML(url)
#print(HTMLpage)
for t in parseHTML(HTMLpage):
discuss.append(t)
for i in discuss:
print(str(a) + ':' + i)
# print(i)
a = a + 1
if __name__ == "__main__":
main()
运行结果:
以上是关于python用tkinter做一个最近很火的强制表白神器的主要内容,如果未能解决你的问题,请参考以下文章