基于深度学习的图片上色
Posted qq 1735375343
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于深度学习的图片上色相关的知识,希望对你有一定的参考价值。
文章目录
如果有不懂的,欢迎下方评论,你还在为毕设课设烦恼吗?注意下方图片右下角水印,解决一切问题,欢迎咨询。

1. 前言
本文基于pytorch和opencv使用生成对抗网络对灰度图像自动上色,然后可以对上色后的图片手动调节亮度对比度等信息,最后可以保存上色后的图像,闲话少说,先看一下效果,文章最后附有全部代码及数据集下载链接。
灰度图自动上色
b站视频地址:b站视频地址
2.图像格式(RGB,HSV,Lab)
2.1 RGB
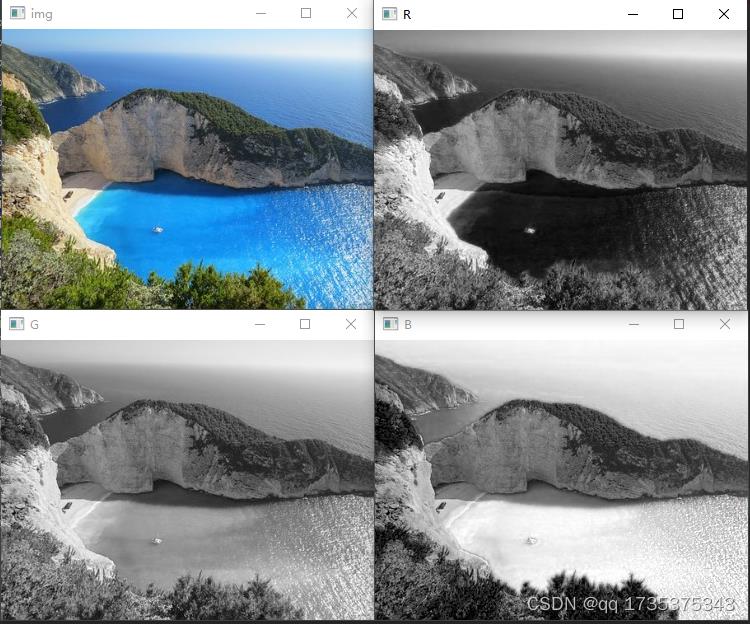
想要对灰度图片上色,首先要了解图像的格式,对于一副普通的图像通常为RGB格式的,即红、绿、蓝三个通道,可以使用opencv分离图像的三个通道,代码如下所示:
import cv2
img=cv2.imread('pic/7.jpg')
B,G,R=cv2.split(img)
cv2.imshow('img',img)
cv2.imshow('B',B)
cv2.imshow('G',G)
cv2.imshow('R',R)
cv2.waitKey(0)
代码运行结果如下所示。
2.2 hsv
hsv是图像的另一种格式,其中h代表图像的色调,s代表饱和度,v代表图像亮度,可以通过调节h、s、v的值来改变图像的色调、饱和度、亮度等信息。
同样可以使用opencv将图像从RGB格式转换成hsv格式。然后可以分离h、s、v三个通道并显示图像代码如下所示:
import cv2
img=cv2.imread('pic/7.jpg')
hsv=cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
h,s,v=cv2.split(hsv)
cv2.imshow('hsv',hsv)
cv2.imshow('h',h)
cv2.imshow('s',s)
cv2.imshow('v',v)
cv2.waitKey(0)
运行结果如下所示:

2.3 Lab
Lab是图像的另一种格式,也是本文使用的格式,其中L代表灰度图像,a、b代表颜色通道,本文使用L通道灰度图作为输入,ab两个颜色通道作为输出,训练生成对抗网络,将图像由RGB格式转换成Lab格式的代码如下所示:
import cv2
img=cv2.imread('pic/7.jpg')
Lab=cv2.cvtColor(img,cv2.COLOR_BGR2Lab)
L,a,b=cv2.split(Lab)
cv2.imshow('Lab',Lab)
cv2.imshow('L',L)
cv2.imshow('a',a)
cv2.imshow('b',b)
cv2.waitKey(0)

3. 生成对抗网络(GAN)
生成对抗网络主要包含两部分,分别是生成网络和判别网络。
生成网络负责生成图像,判别网络负责鉴定生成图像的好坏,二者相辅相成,相互博弈。
本文使用U-net作为生成网络,使用ResNet18作为判别网络。U-net网络的结构图如下所示:
3.1 生成网络(Unet)
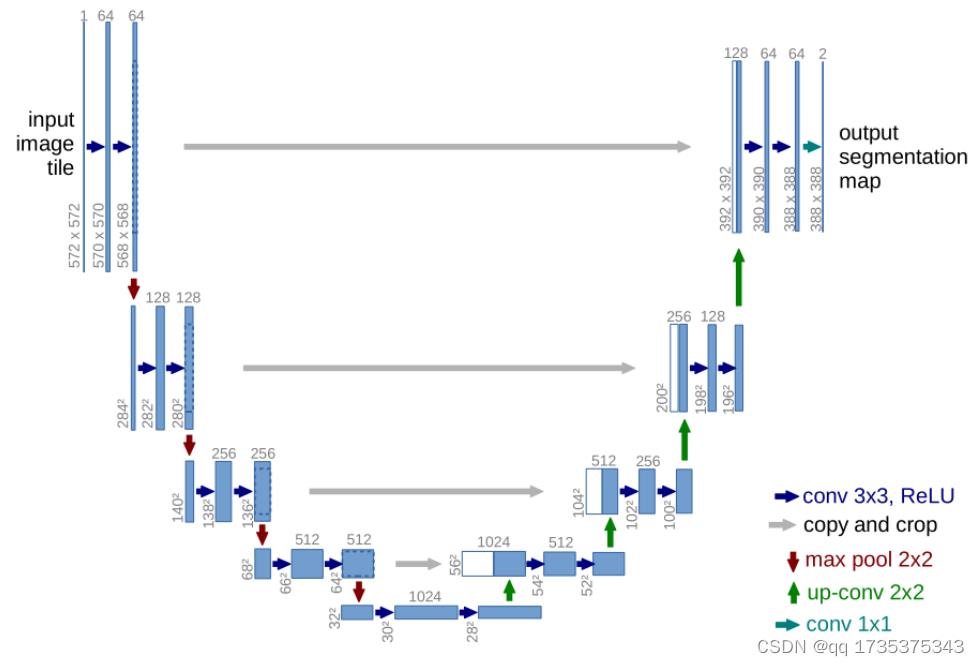
pytorch构建unet网络的代码如下所示:
class DownsampleLayer(nn.Module):
def __init__(self,in_ch,out_ch):
super(DownsampleLayer, self).__init__()
self.Conv_BN_ReLU_2=nn.Sequential(
nn.Conv2d(in_channels=in_ch,out_channels=out_ch,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(),
nn.Conv2d(in_channels=out_ch, out_channels=out_ch, kernel_size=3, stride=1,padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU()
)
self.downsample=nn.Sequential(
nn.Conv2d(in_channels=out_ch,out_channels=out_ch,kernel_size=3,stride=2,padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU()
)
def forward(self,x):
"""
:param x:
:return: out输出到深层,out_2输入到下一层,
"""
out=self.Conv_BN_ReLU_2(x)
out_2=self.downsample(out)
return out,out_2
class UpSampleLayer(nn.Module):
def __init__(self,in_ch,out_ch):
# 512-1024-512
# 1024-512-256
# 512-256-128
# 256-128-64
super(UpSampleLayer, self).__init__()
self.Conv_BN_ReLU_2 = nn.Sequential(
nn.Conv2d(in_channels=in_ch, out_channels=out_ch*2, kernel_size=3, stride=1,padding=1),
nn.BatchNorm2d(out_ch*2),
nn.ReLU(),
nn.Conv2d(in_channels=out_ch*2, out_channels=out_ch*2, kernel_size=3, stride=1,padding=1),
nn.BatchNorm2d(out_ch*2),
nn.ReLU()
)
self.upsample=nn.Sequential(
nn.ConvTranspose2d(in_channels=out_ch*2,out_channels=out_ch,kernel_size=3,stride=2,padding=1,output_padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU()
)
def forward(self,x,out):
'''
:param x: 输入卷积层
:param out:与上采样层进行cat
:return:
'''
x_out=self.Conv_BN_ReLU_2(x)
x_out=self.upsample(x_out)
cat_out=torch.cat((x_out,out),dim=1)
return cat_out
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
out_channels=[2**(i+6) for i in range(5)] #[64, 128, 256, 512, 1024]
#下采样
self.d1=DownsampleLayer(3,out_channels[0])#3-64
self.d2=DownsampleLayer(out_channels[0],out_channels[1])#64-128
self.d3=DownsampleLayer(out_channels[1],out_channels[2])#128-256
self.d4=DownsampleLayer(out_channels[2],out_channels[3])#256-512
#上采样
self.u1=UpSampleLayer(out_channels[3],out_channels[3])#512-1024-512
self.u2=UpSampleLayer(out_channels[4],out_channels[2])#1024-512-256
self.u3=UpSampleLayer(out_channels[3],out_channels[1])#512-256-128
self.u4=UpSampleLayer(out_channels[2],out_channels[0])#256-128-64
#输出
self.o=nn.Sequential(
nn.Conv2d(out_channels[1],out_channels[0],kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(out_channels[0]),
nn.ReLU(),
nn.Conv2d(out_channels[0], out_channels[0], kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_channels[0]),
nn.ReLU(),
nn.Conv2d(out_channels[0],3,3,1,1),
nn.Sigmoid(),
# BCELoss
)
def forward(self,x):
out_1,out1=self.d1(x)
out_2,out2=self.d2(out1)
out_3,out3=self.d3(out2)
out_4,out4=self.d4(out3)
out5=self.u1(out4,out_4)
out6=self.u2(out5,out_3)
out7=self.u3(out6,out_2)
out8=self.u4(out7,out_1)
out=self.o(out8)
return out
3.2 判别网络(resnet18)
resnet18的结构图如下所示:
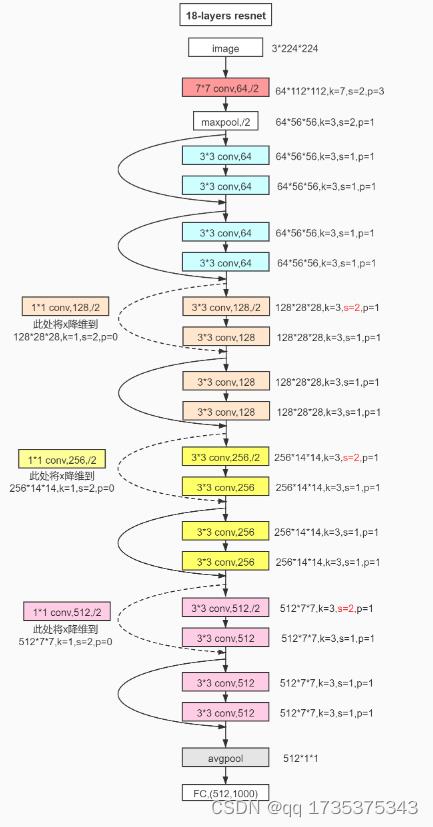
在pytorch内部自带resnet18模型,只需一行代码即可构建resnet18模型,然后还需要去除网络最后的全连接层,代码如下所示:
from torchvision import models
resnet18=models.resnet18(pretrained=False)
del resnet18.fc
print(resnet18)
4. 数据集
本文使用的是自然风景类的数据图片,在网站上爬取了大概1000多张数据图片,部分图片如下所示

5. 模型训练与预测流程图
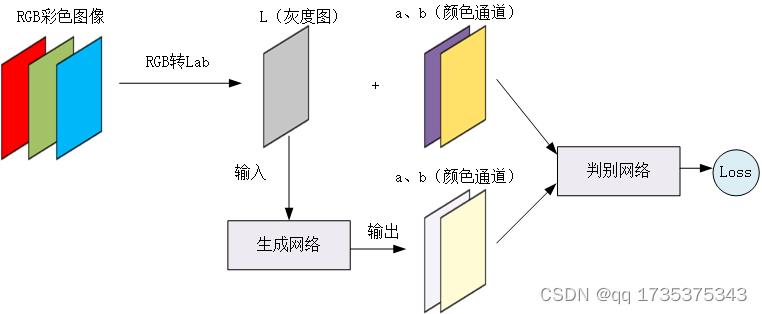
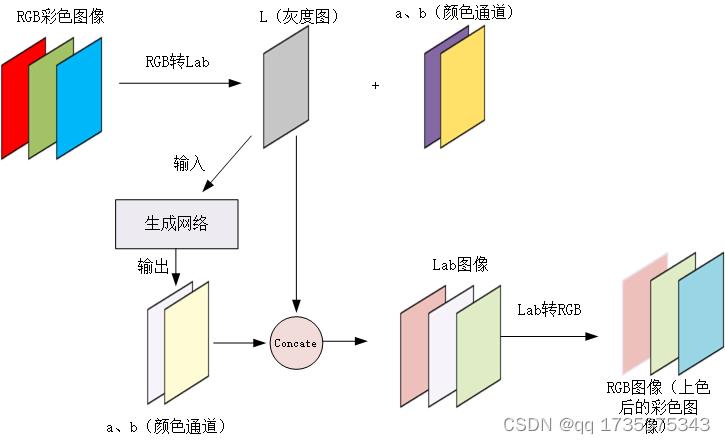
5.1 训练流程图
如下图所示,首先将RGB图像转换成Lab图像,然后将L通道作为生成网络输入,生成网络的输出为新的ab两通道,然后将图像原始的ab通道,与生成网络生成的ab通道输入判别网络中。
5.2 预测流程图
下图为模型的预测过程,在预测过程中判别网络已经没有作用了,首先将RGB图像转换成,Lab图像,接着将L灰度图输入生成网络可以得到新的ab通道图像,接着将L通道图像与生成的ab通道图像进行拼接(concate),拼接以后可以得到一张新的Lab图像,然后再将其转换成RGB格式,此时图像即为上色以后的图像。
6. 模型预测效果
下图为模型的预测效果。左侧的为灰度图像,中间的为原始的彩色图像,右侧的是模型上色以后的图像。整体上看,网络的上色效果还不错。




7. GUI界面制作
为了更加方便使用模型,本文使用pyqt5制作操作界面,其界面如下图所示:首先可以从电脑中加载图像,还可以切换上一张或者下一张,可以将图像灰度化显示。可以对其上色,然后可以调整上色后图像的H、S、V信息,最后支持图像导出,可以将上色后的图像保存到本地中。


8.代码下载
链接中包含了训练代码,测试代码,以及界面代码。此外还包含1000多张数据集,直接运行main.py程序即可弹出操作界面。
代码及数据集下载链接
人工智能--黑白图片上色
学习目标:
- 理解自动编码器的基本原理。
- 掌握利用自动编码器进行黑白图像上色的方法。
学习内容:
- 利用自动编码器的代码,对cat-and-dog数据库,把训练集都变为黑白图片,设置合适的网络参数,用黑白的训练集和原图进行训练。然后把dog.1.jpg图片变为黑白图片,并输入到训练好的网络中,得到恢复的彩色图片,并和原图加以比较。
学习过程:
各层模型结构:




Dog1原图片:

恢复彩色图片,迭代3次后的彩色图片:
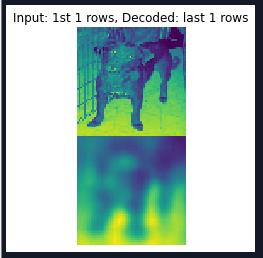
迭代10次后的彩色图片:

经过多次迭代后才会有比较好的效果,才能更好地辨别上色后的图片与原图片的联系;
源码:
from keras.layers import Dense, Input
from keras.layers import Conv2D, Flatten
from keras.layers import Reshape, Conv2DTranspose
from keras.models import Model
from keras import backend as K
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator
import os, numpy as np
from keras.preprocessing import image
# In[1]: 从硬盘中读取猫狗数据图片集并准备将图片进行灰度化
#把彩色图转化为灰度图,如果当前像素点为[r,g,b],那么对应的灰度点为0.299*r+0.587*g+0.114*b
def rgb2gray(rgb):
return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])
datagen_train = ImageDataGenerator(rescale = 1. / 255)
generator_train = datagen_train.flow_from_directory(
r'D:\\Cadabra_tools002\\course_data\\cat-and-dog\\training_set', # 训练集所在路径,子目录为类别
target_size=(64, 64), # 统一resize所有图片的大小
batch_size=8000, # 输入到fit函数中的批的大小
)
img_rows = 64
img_cols = 64
channels = 1
x_train,y = generator_train[0] # x_train 原图
#图片灰度化
x_train_gray = rgb2gray(x_train)
#将灰度图片增加一维,单通道图像,符合卷积网络的输入格式
x_train_gray = x_train_gray.reshape(x_train_gray.shape[0], img_rows, img_cols, channels)
# In[2]: 构造编码器
input_shape = (img_rows, img_cols, 1)
batch_size = 32
kernel_size = 3
#由于图片编码后需要保持图片物体与颜色信息,因此编码后的一维向量维度要变大
latent_dim = 256
layer_filters = [64, 128, 256]
inputs = Input(shape=input_shape, name = 'encoder_input')
x = inputs
for filters in layer_filters:
x = Conv2D(filters = filters, kernel_size = kernel_size, strides = 2,
activation = 'relu', padding = 'same')(x)
# 输入时格式为(32, 32, 3), 经过三层卷积层后输出为(4, 4, 256)
shape = K.int_shape(x)
x = Flatten()(x)
latent = Dense(latent_dim, name = 'latent_vector')(x)
encoder = Model(inputs, latent, name = 'encoder')
encoder.summary()
# In[3]: 构造解码器
latent_inputs = Input(shape=(latent_dim, ), name = 'decoder_input')
'''
将编码器输出的一维向量传入一个全连接网络层,输出的数据格式与上面shape变量相同,为[4, 4, 256]
'''
x = Dense(shape[1] * shape[2] * shape[3])(latent_inputs)
x = Reshape((shape[1], shape[2], shape[3]))(x)
'''
解码器对应编码器做反向操作,因此它将数据经过三个反卷积层,卷积层的输出维度与编码器恰好相反,分别为
256, 128, 64,每经过一个反卷积层,数据维度增加一倍,因此输入时数据维度为[4,4],经过三个反卷积层后
维度为[32,32]恰好与图片格式一致
'''
for filters in layer_filters[::-1]:
x = Conv2DTranspose(filters = filters, kernel_size = kernel_size,
strides = 2, activation = 'relu',
padding = 'same')(x)
outputs = Conv2DTranspose(filters = channels, kernel_size = kernel_size,
activation='relu', padding='same',
name = 'decoder_output')(x)
print(K.int_shape(outputs))
decoder = Model(latent_inputs, outputs, name = 'decoder')
decoder.summary()
# In[4]: 构造自动编解码器
from keras.callbacks import ReduceLROnPlateau, ModelCheckpoint
autoencoder = Model(inputs, decoder(encoder(inputs)), name='autoencoder')
autoencoder.summary()
#如果经过5次循环训练后效果没有改进,那么就把学习率减少0.1的开方,通过调整学习率促使训练效果改进
lr_reducer = ReduceLROnPlateau(factor = np.sqrt(0.1), cooldown = 0, patience = 5,
verbose = 1, min_lr = 0.5e-6)
model_name = 'colorized_ae+model.epoch:03d.h5'
checkpoint = ModelCheckpoint(filepath = model_name, monitor = 'val_loss',verbose = 1)
autoencoder.compile(loss='mse', optimizer = 'adam')
callbacks = [lr_reducer, checkpoint]
autoencoder.fit(x_train_gray, x_train,
epochs = 10, #30,
batch_size = batch_size,
callbacks = callbacks)
# In[5]: 将灰度图和上色后的图片显示出来
x_decoded = autoencoder.predict(x_train_gray)
imgs = x_decoded[:100]
imgs = imgs.reshape((10, 10, img_rows, img_cols, channels))
imgs = np.vstack([np.hstack(i) for i in imgs])
plt.figure(dpi=200)
plt.axis('off')
plt.title('Colorized test images are: ')
plt.imshow(imgs, interpolation='none')
plt.show()
# In[6]: 读取一张图片,并且转换格式,以便作为神经网络的输入
img_path = os.path.join(r'D:\\Cadabra_tools002\\course_data\\cat-and-dog\\dog.1.jpg')
img = image.load_img(img_path, target_size=(64, 64))
plt.imshow(img)
img_tensor = image.img_to_array(img)
img_tensor = np.expand_dims(img_tensor, axis=0)
img_tensor /= 255.
print(img_tensor.shape)
#图片灰度化
img_gray = rgb2gray(img_tensor)
#将灰度图片增加一维,单通道图像,符合卷积网络的输入格式
img_gray = img_gray.reshape(img_gray.shape[0], img_rows, img_cols, 1)
# In[7]: 输入到训练好的网络中,得到恢复的彩色图片
x_decoded = autoencoder.predict(img_gray)
#把测试图片集中的前8张显示出来,看看解码器生成的图片是否与原图片足够相似
imgs = np.concatenate([img_gray, x_decoded])
imgs = imgs.reshape((2, 1, 64, 64))
imgs = np.vstack([np.hstack(i) for i in imgs])
plt.figure()
plt.axis('off')
plt.title('Input: 1st 1 rows, Decoded: last 1 rows')
plt.imshow(imgs, interpolation='none')
plt.show()
学习产出:
- 迭代多次后(一般迭代次数在30次以上),才能看出上色后的图片与原图片相似;
以上是关于基于深度学习的图片上色的主要内容,如果未能解决你的问题,请参考以下文章