shell脚本学习进阶和正则表达示的应用
Posted *平凡*随风舞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了shell脚本学习进阶和正则表达示的应用相关的知识,希望对你有一定的参考价值。
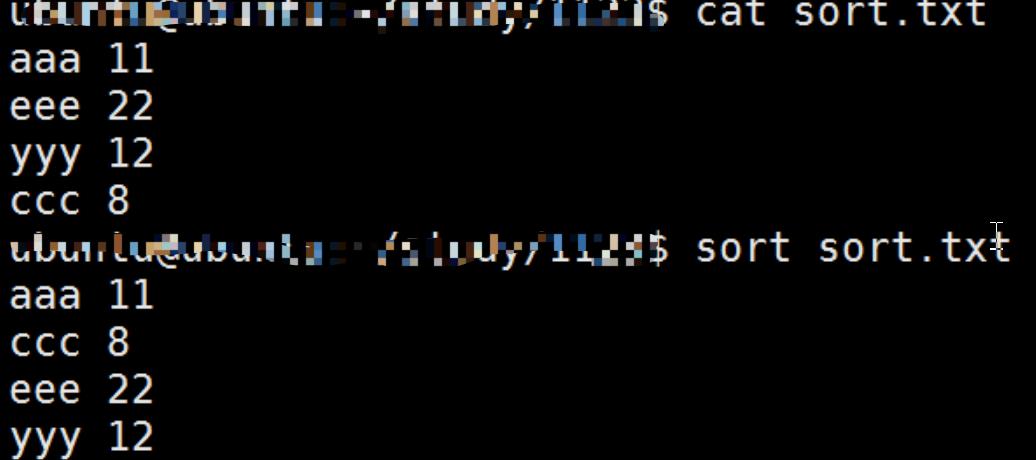
Sort 排序:
-f: 忽略字符大小写 -n: 比较数值大小 -t: 指定分隔符 -k: 指定分隔后进行比较字段序号 -u: 重复的行,只显示一次
按第二行数值排序:
$ sort -k2n sort.txt ccc 8 aaa 11 yyy 12 eee 22
重复行显示一次:sort -u sort.txt
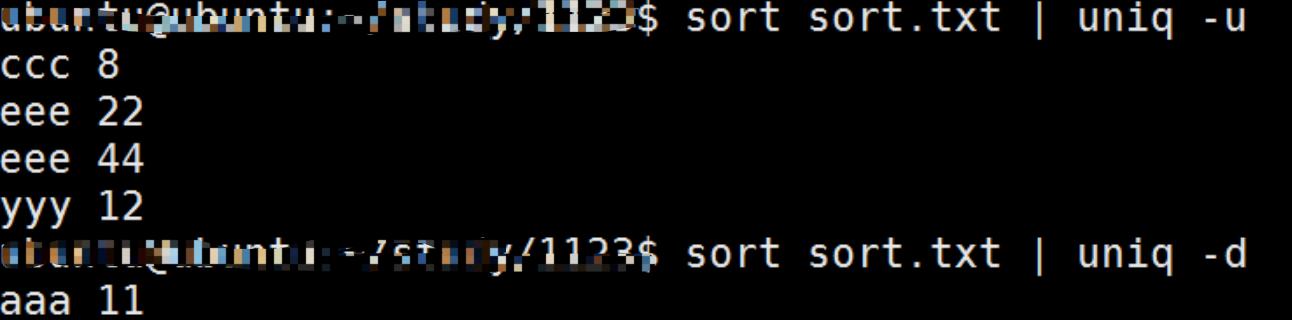
uniq 处理重复行,与sort配合使用:
wc命令:
行 | 字符 | 单词 $ wc sort.txt 6 12 41 sort.txt $ wc -l sort.txt 6 sort.txt $ wc -c sort.txt 41 sort.txt $ wc -w sort.txt 12 sort.txt
find命令:
按名字查找 $ find ./ -name "*.sh" 查找当前一级目录下的普通文件 $ find ./ -maxdepth 1 -type f 查找大小在1M到5M之间的 $ find ~ -size +1M -size -5M 查找log目录10天之前创建的文件 $ find ~/log -ctime +10 查找log目录5天内创建的文件 $ find ~/log -ctime -5
ls命令不能读管道或者标准输入,可以使用 exec代替:
find ~/log -ctime +10 -exec ls -la {} \\;
使用ok选项更安全,会要求确认:
find ~/log -ctime +10 -ok rm - f {} \\;
当然了,还可以使用 xargs 将前一个命令的输出结果,分成小块解析:
find ./ -maxdepth 1 -type -f | xargs ls -l
grep命令可以进行内容的查找:
-r 递归子目录
-i 忽略大小写
-v 排除
正则表达示:
字符类:

数量限定:

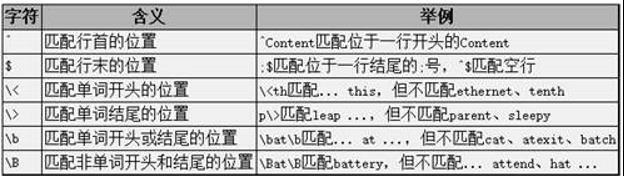
位置限定符:
特殊字符:

可以使用egrep命令,支持扩展的正则表达示:
例子1:匹配出所有IP地址 XXX.XXX.XXX.XXX
egrep \'^[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}$\' all.txt
例子2:匹配邮箱 XXX@YY.COM|CN
egrep \' [0-9a-zA-Z]+@[0-9a-zA-z]+\\.(com|cn)$\' all.txt
注意:目前分为基础正则和扩展正则,基础正则不支持 ?+ { } | ().
如果想支持,需要转义字符,写的定要先写扩展正则,在写基础正则。
grep \'[0-9a-zA-z]\\+@[0-9a-zA-Z]\\+\\.\\(com|cn\\)$\' all.txt 或者 grep -E \'[0-9a-zA-z]+@[0-9a-zA-Z]+\\.(com|cn)$\' all.txt
最后,对匹配IP地址在进行一次优化:
$ egrep \'^([0-9]{1,3}\\.){3}[0-9]{1,3}$\' all.txt
SED工具,stream editor 流编辑器,和VI同源,处理文件,对文本进行修改!
常见用法:
sed option \'script\' file1 file2 ... ’‘ sed 参数 ‘脚本(/pattern/action)’ 待处理文件 sed option -f scriptfile file1 file2 ... sed 参数 –f ‘脚本文件’ 待处理文件
参数说明:
a, append 追加 i, insert 插入 d, delete 删除 s, substitution 替换
例子:在第二行插入XXXX
sed \'2ixxxx\' cash.sh
-i 是直接修改源文件,需要谨慎使用
删除第4-6行:
sed \'4,6d\' cash.sh
替换read 为write:
sed \'s/read/write\' cash.sh
SED常用指令:
/pattern/p 打印匹配pattern的行 /pattern/d 删除匹配pattern的行 /pattern/s/pattern1/pattern2/ 查找符合pattern的行,将该行第一个匹配pattern1的字符串替换为pattern2 /pattern/s/pattern1/pattern2/g 查找符合pattern的行,将该行所有匹配pattern1的字符串替换为pattern2
例如,匹配echo 并打印该行:
sed \'/echo/p\' cash.sh
此时会显示多一行,如果需要不输入源文件内容,可以使用:
sed \'/echo/p\' cash.sh -n
删除case所在行 $ sed \'/case/d\' case.sh 将echo替换为print $ sed \'/echo/s/echo/print/g\' case.sh
地址符号的使用:
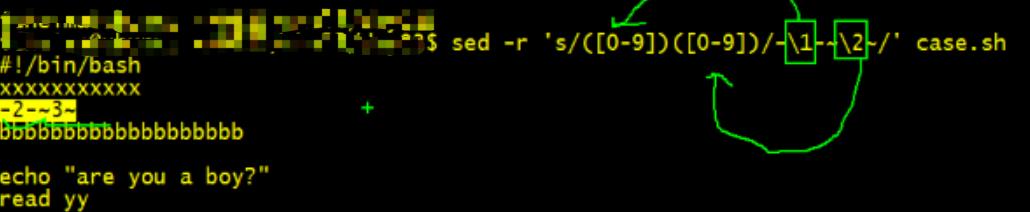
sed \'s/23/-&-/\' cash.sh
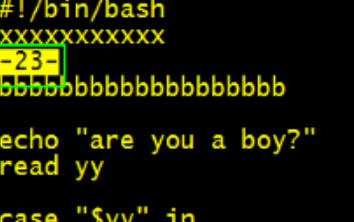
\\1 \\2 代表对应的第一个单元 和 第二个单元
-r 可以使用拓展正则
去掉html标签:
sed -r \'s/<[(/|0-9a-zA-Z)]+>//g\' hello.html 或者 sed -r \'s/<[^<>]+>//g\' hello.html
以上是关于shell脚本学习进阶和正则表达示的应用的主要内容,如果未能解决你的问题,请参考以下文章
Shell脚本三剑客——Grep(进阶版egrep)SedAwk命令