《Linux内核原理与设计》第九周作业
视频学习及代码分析
一、进程调度时机与进程的切换
不同类型的进程有不同的调度需求,第一种分类:I/O-bound 会频繁的进程I/O,通常会花费很多时间等待I/O操作的完成; CPU-bound 是计算密集型,需要大量的CPU时间进行运算,使得其他交互式进程反应迟钝,因此需要不同的算法来使系统的运行更高效,以及CPU的资源最大限度的得到使用。第二种分类包括批处理进程(batch process);实时进程(real-time process)以及交互式进程(interactive process)。不同的分类需要不同的调度策略,即决定什么时候以怎样的方式选择一个新进程运行。Linux的调度基于分时和优先级。根据优先级排队,且优先级是动态的。
进程调度的时机
进程的切换及相关代码分析
控制信息:进程描述符,内核堆栈等
硬件上下文(注意中断也要保存硬件上下文只是保存的方法不同,通过保存现场和恢复现场)
`next = pick_next_task(rq, prev); ` //包装了某种进程调度策略
`context_switch(rq, prev, next); ` //进程上下文切换
`switch_to(pre,next,prev)` //切换寄存器的状态和堆栈。利用了prev和next两个参数:prev指向当前进程,next指向被调度的进程
相关代码分析:
#define switch_to(prev, next, last) //prev指向当前进程,next指向被调度的进程
do {
unsigned long ebx, ecx, edx, esi, edi;
asm volatile("pushfl\\n\\t" //保存当前近程的flags
"pushl %%ebp\\n\\t" //把当前进程的基址压栈
"movl %%esp,%[prev_sp]\\n\\t" //把当前进程的栈顶esp保存到thread.sp中
"movl %[next_sp],%%esp\\n\\t" //把[next_sp]放到esp,从而这两步完成了内核堆栈的切换
"movl $1f,%[prev_ip]\\n\\t" //把1f放到[prev_ip]里,保存当前进程的EIP,当恢复prev进程时可从这里恢复
"pushl %[next_ip]\\n\\t" //把next进程的起点,即ip的位置压到堆栈中,next_ip一般是$1f
__switch_canary
"jmp __switch_to\\n" //执行__switch_to()函数,通过寄存器[prev][next],eax和edx传递参数
"1:\\t"
"popl %%ebp\\n\\t"
"popfl\\n"
/* output parameters */
: [prev_sp] "=m"(prev->thread.sp), //为了可读性更好,用字符串[prev_sp]标记参数
[prev_ip] "=m"(prev->thread.ip),
"=a" (last),
/* clobbered output registers: */
"=b" (ebx), "=c"(ecx), "=d" (edx),
"=S" (esi), "=D"(edi)
__switch_canary_oparam
/* input parameters: */
: [next_sp] "m" (next->thread.sp),
[next_ip] "m" (next->thread.ip),
/* regparm parameters for __switch_to():*/
[prev] "a" (prev),
[next] "d" (next)
__switch_canary_iparam
: /* reloaded segment registers */
"memory");
} while (0)
二、Linux系统的一般执行过程分析
最一般的情况:正在运行的用户态进程x切换到用户态进程y的过程
1.正在运行的用户态进程X
2.发生中断——save cs:eip/esp/eflags(current) to kernel stack,then load cs:eip(entry of a specific ISR ) and ss:esp(point to kernel stack). //CPU自动完成保存和加载
3.SAVE_ALL //保存现场
4. 中断处理过程中或中断返回前调用了schedule(),其中的switch_to做了关键的进程上下文切换 //将x进程的内核堆栈切换到next进程的内核堆栈,再切换eip
5.标号1之后开始运行用户态进程Y(这里Y曾经通过以上步骤被切换出去过因此可以从标号1继续执行)
6.restore_all //恢复现场
7.iret - pop cs:eip/ss:esp/eflags from kernel stack //把y进程在发生中断时保存在内核堆栈里面的cs:eip/ss:esp/eflags pop出来
8.继续运行用户态进程Y
几种特殊情况
内核与舞女
0到3G用户可以访问,3G以上只有内核态可以访问。实际上所有的进程3G以上都是完全共享的,比如进程X切换到进程Y,但是地址空间还是3G以上的部分,只是把进程描述符和其他的进程上下文切换了,等到返回到用户态了才会有不同,在内核态里不管哪个进程代码段和堆栈段都是完全相同的,因此在内核中切换时比较容易的。视频中有一个比喻,就是内核和舞女。内核就好比是出租车,进程是舞女,哪个进程招手都可以进入内核,走一段可以返回到用户态。内核没有进程时就进入0号进程idle空转,有进程时发生中断进入内核态。
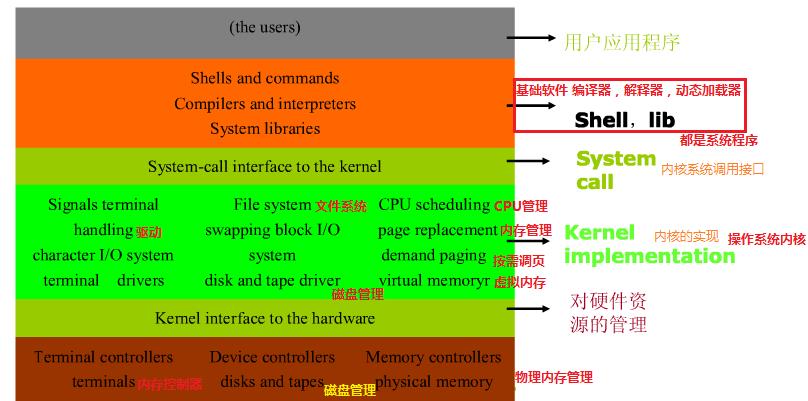
Linux操作系统架构概览
任何计算机系统都包含一个基本的程序集合,称为操作系统。
- 内核(进程管理,进程调度,进程间通讯机制,内存管理,中断异常处理,文件系统,I/O系统,网络部分)
- 其他程序(例如函数库、shell程序、系统程序等等)
操作系统的目的
- 与硬件交互,管理所有的硬件资源
- 为用户程序(应用程序)提供一个良好的执行环境
最简单也是最复杂的操作-执行ls命令

从CPU角度看Linux系统的执行

从内存角度看Linux系统
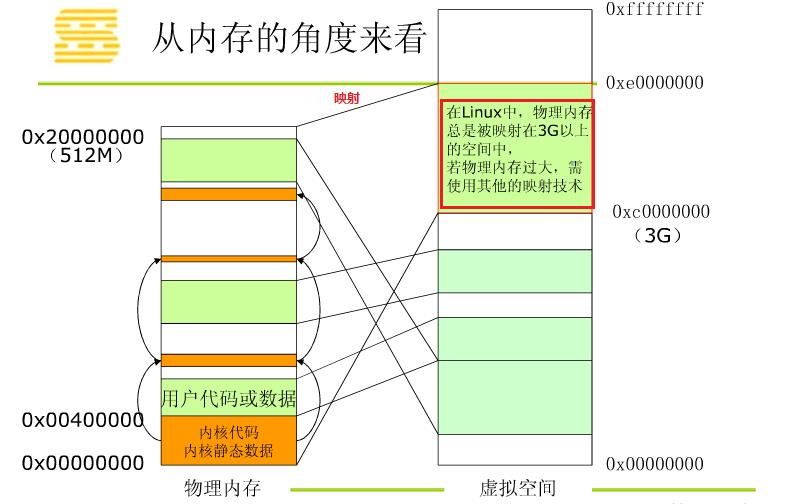
参考:图片链接
教材15、16章学习
1、进程地址空间由进程可寻址的虚拟地址组成,而且内核允许进程使用这种虚拟内存中的地址。通常情况下,每个进程都有唯一的这种平坦地址空间。进程地址空间中的任何有效地址都只能位于唯一的区域,这些内存区域不能相互覆盖。
2、一个进程的地址空间与另一个进程的地址空间即使有相同的内存地址,实际上也彼此互不相干,称这样的进程为线程。其父进程希望和其子进程共享空间,可以在调用clone()时,设置CLONE_VM标志;
3、进程的内核区域包含各种内存对象,比如:可执行文件代码可以包含各种内存映射,称为代码段(text section);可执行文件的已初始化全局变量的内存映射,称为数据段(data section);包含未初始化全局变量,也就是bss段的零页(页面中的信息全部为0值,所以可以用于映射bss段等目的)的内存映射;用于进程用户空间栈的内存映射;
4、内核使用内存描述符结构体表示进程的地址空间,该结构体包含了和进程地址空间有关的全部信息。内存描述符由mm_struct结构体表示。分配内存描述符时,fork()函数利用copy_mm()函数复制父进程的内存描述符。撤销内存描述符,内核会调用定义在kernel/exit.c中的exit_mm()函数;内核线程没有进程地址空间,也没有相关的内存描述符,所有内核线程对应的进程描述符中的mm域为空。
5、内存区域由vm_area_struct结构体描述,定义在文件<linux/mm_types.h>中。内存区域在Linux中也经常称作虚拟地址空间。VMA标志是一种位标志,其定义见<linux/mm.h>中,它包含在mm_flags域内,标志了内存区域所包含的页面的行为和信息。
6、可以通过内存描述符中的mmap和mm_rb域之一访问内存区域。这两个域各自独立地指向与内存描述符相关的全体内存区域对象。其实,它们包含完全相同的am_area_struct结构体的指针,仅仅组织方法不同。mmap域使用单独链表链接所有的内存区域对象;mm_rb域使用红-黑数链接所有的内存区域对象。
7、为了找到一个给定的内存地址属于哪一个内存区域,内核提供了find_vma()函数。
8、do_mmap()函数会将一个地址空间加入到进程的地址空间中——无论是扩展已存在的内存区域还是创建一个新的区域; do_munmap()函数从特定的进程空间中删除地址空间。
9、当程序访问一个虚拟地址时,首先必须将虚拟地址转换为物理地址,然后处理器才能解析地址访问请求。地址的转换需要通过查询页表才能完成,概括的讲,地址转换需要将虚拟地址分段,使每段虚拟地址都作为一个索引指向页表,而页表则指向下一级别的页表或者指向最终的物理页面。Linux中使用三级页表完成转换。
10、页高速缓存(cache)是Linux内核实现磁盘缓存。写缓存一般被实现成下面三种策略之一:第一种策略称为不缓存(nowrite);第二种策略,写操作将自动更新内存缓存,同时也更新磁盘文件。第三种策略,也是Linux所采用的,称为“回写"。在这种策略下,程序写操作直接写到缓存中,并且被加入到脏页链表中。然后由一个进程(回写进程)周期性将脏页链表中的页写回到磁盘,从而让磁盘中的数据和内存中的最终一致。
11、页高速缓存通过两个参数address_space兑现加上一个偏移量进行搜索。每个address_space对象都有惟一的基数,它保存在address_space结构体中。基数是一个二叉树,只要指定了文件偏移量,就可以在基数中迅速检索到希望的页。