毕业设计基于深度学习的图像超分辨率重建 - opencv python cnn
Posted DanCheng-studio
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了毕业设计基于深度学习的图像超分辨率重建 - opencv python cnn相关的知识,希望对你有一定的参考价值。
文章目录
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 基于深度学习的图像超分辨率重建算法研究与实现
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
🧿 选题指导, 项目分享:
1 什么是图像超分辨率重建
图像的超分辨率重建技术指的是将给定的低分辨率图像通过特定的算法恢复成相应的高分辨率图像。具体来说,图像超分辨率重建技术指的是利用数字图像处理、计算机视觉等领域的相关知识,借由特定的算法和处理流程,从给定的低分辨率图像中重建出高分辨率图像的过程。其旨在克服或补偿由于图像采集系统或采集环境本身的限制,导致的成像图像模糊、质量低下、感兴趣区域不显著等问题。
简单来理解超分辨率重建就是将小尺寸图像变为大尺寸图像,使图像更加“清晰”。具体效果如下图所示


2 应用场景
图像超分辨率重建技术在多个领域都有着广泛的应用范围和研究意义。主要包括:
(1) 图像压缩领域
在视频会议等实时性要求较高的场合,可以在传输前预先对图片进行压缩,等待传输完毕,再由接收端解码后通过超分辨率重建技术复原出原始图像序列,极大减少存储所需的空间及传输所需的带宽。
(2) 医学成像领域
对医学图像进行超分辨率重建,可以在不增加高分辨率成像技术成本的基础上,降低对成像环境的要求,通过复原出的清晰医学影像,实现对病变细胞的精准探测,有助于医生对患者病情做出更好的诊断。
(3) 遥感成像领域
高分辨率遥感卫星的研制具有耗时长、价格高、流程复杂等特点,由此研究者将图像超分辨率重建技术引入了该领域,试图解决高分辨率的遥感成像难以获取这一挑战,使得能够在不改变探测系统本身的前提下提高观测图像的分辨率。
(4) 公共安防领域
公共场合的监控设备采集到的视频往往受到天气、距离等因素的影响,存在图像模糊、分辨率低等问题。通过对采集到的视频进行超分辨率重建,可以为办案人员恢复出车牌号码、清晰人脸等重要信息,为案件侦破提供必要线索。
(5) 视频感知领域
通过图像超分辨率重建技术,可以起到增强视频画质、改善视频的质量,提升用户的视觉体验的作用。
3 实现方法
首先介绍图像超分辨率重建技术,图像超分辨率重建技术分为两种,一种是从多张低分辨率图像合成一张高分辨率图像,另外一种是从单张低分辨率图像获取高分辨率图像,在本专栏中,我们使用单幅图像超分辨率重建技术(SISR)。
在这些方法中,可以分为三类,基于插值,基于重建,基于学习。基于插值的方法实现简单,已经广泛应用,但是这些线性的模型限制住了它们恢复高频能力的细节。基于稀疏表示的技术[1]通过使用先验知识增强了线性模型的能力。这类技术假设任意的自然图像可以被字典的元素稀疏表示,这种字典可以形成一个数据库且从数据库中学习到低分辨率图像到高分辨率图像的映射,但是这类方法计算复杂,需要大量计算资源。
基于CNN(卷积神经网络)的模型SRCNN[2]首先将CNN引入SISR中,它仅仅使用三层网络,就取得了先进的结果。随后,各种基于深度学习的模型,进入SISR领域,大致分为以下两个大的方向。一种是追求细节的恢复,以PSNR,SSIM等评价标准的算法,其中以SRCNN模型为代表。另外一种以降低感知损失为目标,不注重细节,看重大局观,以SRGAN[3]为代表的一系列算法。两种不同方向的算法,应用的领域也不相同。在医学图像领域,医生需要图像的细节,以致于做出精确的判断,而不是追求图像整体的清晰,因此,本专栏中将研究追求细节恢复的算法,以及在医学上的应用。
追求细节恢复的算法,也分为两个流派,一是使用插值作为预处理的算法,二是不使用插值,将上采样过程融入网络中的算法。
4 SRResNet算法原理
SRCNN的网络结构图如下
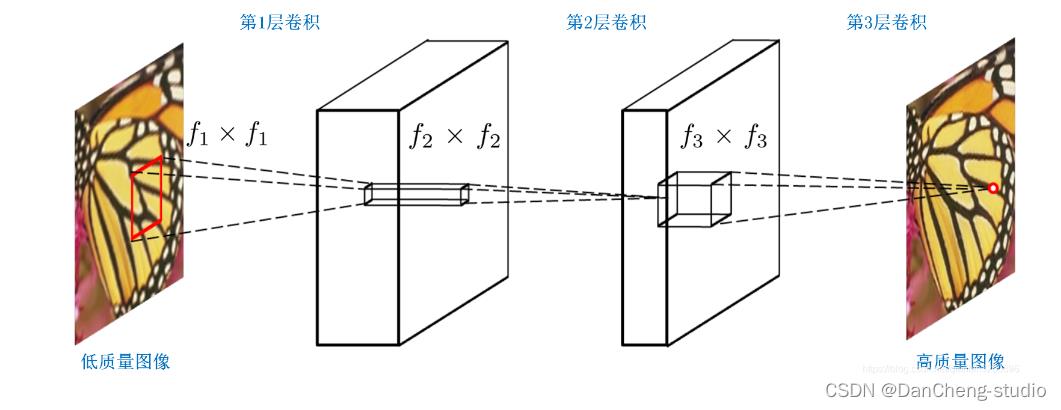
三层的作用
在进入网络之前会有将input图像用双三次插值放大至目标尺寸的预处理。
LR 特征提取(Patch extraction and representation),这个阶段主要是对LR进行特征提取,并将其特征表征为一些feature maps;
特征的非线性映射(Non-linear mapping),这个阶段主要是将第一阶段提取的特征映射至HR所需的feature maps;
HR重建(Reconstruction),这个阶段是将第二阶段映射后的特征恢复为HR图像。
网络结构细节
LR特征提取可表征为“卷积层(cf1f1卷积核)+RELU",c是通道数,f1是卷积核的大小。
非线性映射可表征为“全连接层+RELU”,而全连接层又可表征为卷积核为1x1的卷积层,因此,本层最终形式为“卷积层(n111卷积核)+RELU";n1是第一层卷积核的个数。
HR重建可直接表征为“卷积层(n2f3f3)”;n2是第二层卷积核的个数。
5 SRCNN设计思路
这个思路是从稀疏编码得来的,并把上述过程分别表述为:Patch extraction, Non-linear mapping, Reconstruction。
Patch extraction: 提取图像Patch,进行卷积提取特征,类似于稀疏编码中的将图像patch映射到低分辨率字典中。基于样例的算法目的是找到一组可以表达之前预处理后所得到图像块的一组“基”,这些基是沿着不同方向的边缘,稀疏系数就是分配给各个基的权重。作者认为这部分可以转化为用一定数量的滤波器(卷积核)来代替。

Non-linear mapping: 将低分辨率的特征映射为高分辨率特征,类似于字典学习中的找到图像patch对应的高分辨字典。基于样例的算法将第一步得到的表达图像块的高维向量映射到另外一个高维向量中,通过这个高维向量表达高分辨率图像块,用于最后的重建。作者认为这一步骤可以使用1*1的卷积来实现向量维数的变换。
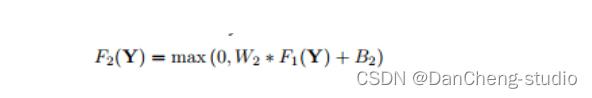
Reconstruction:根据高分辨率特征进行图像重建。类似于字典学习中的根据高分辨率字典进行图像重建。基于样例的算法将最后得到的高分辨率图像块进行聚合(重合的位置取平均)形成最后的高分辨率图像。作者认为这一部分可以看成是一种线性运算,可以构造一个线性函数(不加激活函数)来实现。
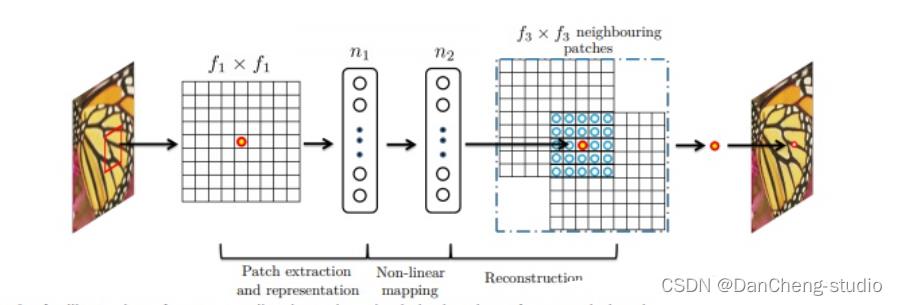
从实际操作上来看,整个超分重建分为两步:图像放大和修复。所谓放大就是采用某种方式(SRCNN采用了插值上采样)将图像放大到指定倍数,然后再根据图像修复原理,将放大后的图像映射为目标图像。超分辨率重建不仅能够放大图像尺寸,在某种意义上具备了图像修复的作用,可以在一定程度上削弱图像中的噪声、模糊等。因此,超分辨率重建的很多算法也被学者迁移到图像修复领域中,完成一些诸如jpep压缩去燥、去模糊等任务。

6 代码实现
6.1 代码结构组织

项目根目录下有8个.py文件和2个文件夹,下面对各个文件和文件夹进行简单说明。
- create_data_lists.py:生成数据列表,检查数据集中的图像文件尺寸,并将符合的图像文件名写入JSON文件列表供后续Pytorch调用;
- datasets.py:用于构建数据集加载器,主要沿用Pytorch标准数据加载器格式进行封装;
- models.py:模型结构文件,存储各个模型的结构定义;
- utils.py:工具函数文件,所有项目中涉及到的一些自定义函数均放置在该文件中;
- train_srresnet.py:用于训练SRResNet算法;
- train_srgan.py:用于训练SRGAN算法;
- eval.py:用于模型评估,主要以计算测试集的PSNR和SSIM为主;
- test.py:用于单张样本测试,运用训练好的模型为单张图像进行超分重建;
- data:用于存放训练和测试数据集以及文件列表;
- results:用于存放运行结果,包括训练好的模型以及单张样本测试结果;
整个代码运行顺序如下:
- 运行create_data_lists.py文件用于为数据集生成文件列表;
- 运行train_srresnet.py进行SRResNet算法训练,训练结束后在results文件夹中会生成checkpoint_srresnet.pth模型文件;
- 运行eval.py文件对测试集进行评估,计算每个测试集的平均PSNR、SSIM值;
- 运行test.py文件对results文件夹下名为test.jpg的图像进行超分还原,还原结果存储在results文件夹下面;
- 运行train_srgan.py文件进行SRGAN算法训练,训练结束后在results文件夹中会生成checkpoint_srgan.pth模型文件;
- 修改并运行eval.py文件对测试集进行评估,计算每个测试集的平均PSNR、SSIM值;
- 修改并运行test.py文件对results文件夹下名为test.jpg的图像进行超分还原,还原结果存储在results文件夹下面;
6.2 train_srresnet
代码过多,仅展示关键代码,需要源码的可以call学长
import torch.backends.cudnn as cudnn
import torch
from torch import nn
from torchvision.utils import make_grid
from torch.utils.tensorboard import SummaryWriter
from models import SRResNet
from datasets import SRDataset
from utils import *
# 数据集参数
data_folder = './data/' # 数据存放路径
crop_size = 96 # 高分辨率图像裁剪尺寸
scaling_factor = 4 # 放大比例
# 模型参数
large_kernel_size = 9 # 第一层卷积和最后一层卷积的核大小
small_kernel_size = 3 # 中间层卷积的核大小
n_channels = 64 # 中间层通道数
n_blocks = 16 # 残差模块数量
# 学习参数
checkpoint = None # 预训练模型路径,如果不存在则为None
batch_size = 400 # 批大小
start_epoch = 1 # 轮数起始位置
epochs = 130 # 迭代轮数
workers = 4 # 工作线程数
lr = 1e-4 # 学习率
# 设备参数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
ngpu = 2 # 用来运行的gpu数量
cudnn.benchmark = True # 对卷积进行加速
writer = SummaryWriter() # 实时监控 使用命令 tensorboard --logdir runs 进行查看
def main():
"""
训练.
"""
global checkpoint,start_epoch,writer
# 初始化
model = SRResNet(large_kernel_size=large_kernel_size,
small_kernel_size=small_kernel_size,
n_channels=n_channels,
n_blocks=n_blocks,
scaling_factor=scaling_factor)
# 初始化优化器
optimizer = torch.optim.Adam(params=filter(lambda p: p.requires_grad, model.parameters()),lr=lr)
# 迁移至默认设备进行训练
model = model.to(device)
criterion = nn.MSELoss().to(device)
# 加载预训练模型
if checkpoint is not None:
checkpoint = torch.load(checkpoint)
start_epoch = checkpoint['epoch'] + 1
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
if torch.cuda.is_available() and ngpu > 1:
model = nn.DataParallel(model, device_ids=list(range(ngpu)))
# 定制化的dataloaders
train_dataset = SRDataset(data_folder,split='train',
crop_size=crop_size,
scaling_factor=scaling_factor,
lr_img_type='imagenet-norm',
hr_img_type='[-1, 1]')
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=workers,
pin_memory=True)
# 开始逐轮训练
for epoch in range(start_epoch, epochs+1):
model.train() # 训练模式:允许使用批样本归一化
loss_epoch = AverageMeter() # 统计损失函数
n_iter = len(train_loader)
# 按批处理
for i, (lr_imgs, hr_imgs) in enumerate(train_loader):
# 数据移至默认设备进行训练
lr_imgs = lr_imgs.to(device) # (batch_size (N), 3, 24, 24), imagenet-normed 格式
hr_imgs = hr_imgs.to(device) # (batch_size (N), 3, 96, 96), [-1, 1]格式
# 前向传播
sr_imgs = model(lr_imgs)
# 计算损失
loss = criterion(sr_imgs, hr_imgs)
# 后向传播
optimizer.zero_grad()
loss.backward()
# 更新模型
optimizer.step()
# 记录损失值
loss_epoch.update(loss.item(), lr_imgs.size(0))
# 监控图像变化
if i==(n_iter-2):
writer.add_image('SRResNet/epoch_'+str(epoch)+'_1', make_grid(lr_imgs[:4,:3,:,:].cpu(), nrow=4, normalize=True),epoch)
writer.add_image('SRResNet/epoch_'+str(epoch)+'_2', make_grid(sr_imgs[:4,:3,:,:].cpu(), nrow=4, normalize=True),epoch)
writer.add_image('SRResNet/epoch_'+str(epoch)+'_3', make_grid(hr_imgs[:4,:3,:,:].cpu(), nrow=4, normalize=True),epoch)
# 打印结果
print("第 "+str(i)+ " 个batch训练结束")
# 手动释放内存
del lr_imgs, hr_imgs, sr_imgs
# 监控损失值变化
writer.add_scalar('SRResNet/MSE_Loss', loss_epoch.val, epoch)
# 保存预训练模型
torch.save(
'epoch': epoch,
'model': model.module.state_dict(),
'optimizer': optimizer.state_dict()
, 'results/checkpoint_srresnet.pth')
# 训练结束关闭监控
writer.close()
if __name__ == '__main__':
main()
6.3 训练效果
训练共用时15小时19分6秒(没有用显卡),训练完成后保存的模型共17.8M。下图展示了训练过程中的损失函数变化。可以看到,随着训练的进行,损失函数逐渐开始收敛,在结束的时候基本处在收敛平稳点。

倍缩放比率下不同超分辨率方法的结果比对效果

🧿 选题指导, 项目分享:
7 最后
学习笔记之——基于深度学习的图像超分辨率重建
最近开展图像超分辨率( Image Super Resolution)方面的研究,做了一些列的调研,并结合本人的理解总结成本博文~(本博文仅用于本人的学习笔记,不做商业用途)
本博文涉及的paper已经打包,供各位看客下载哈~https://download.csdn.net/download/gwplovekimi/10728916
目录
SRCNN(Super-Resolution Convolutional Neural Network)
FSRCNN(Fast Super-Resolution Convolutional Neural Networks)
ESPCN(Efficient Sub-Pixel Convolutional Neural Network)
VESPCN(Video Efficient Sub-Pixel Convolutional Neural Network)
VDSR(VeryDeep Convolutional Networks)
DRCN(Deeply-Recursive Convolutional Network)
RED(very deep Residual Encoder-Decoder Networks)
DRRN(Deep Recursive Residual Network)
LapSRN(Laplacian PyramidSuper-Resolution Network)
SRGAN(SRResNet,super-resolution generative adversarial network)
EDSR(enhanced deep super-resolution network)
超分辨率(Super Resolution,SR)
超分辨率是计算机视觉的一个经典应用。SR是指通过软件或硬件的方法,从观测到的低分辨率图像重建出相应的高分辨率图像(说白了就是提高分辨率),在监控设备、卫星图像遥感、数字高清、显微成像、视频编码通信、视频复原和医学影像等领域都有重要的应用价值。
超分分为以下两种:
- Image SR。只参考当前低分辨率图像,不依赖其他相关图像的超分辨率技术,称之为单幅图像的超分辨率(single image super resolution,SISR)。
- Video SR。参考多幅图像或多个视频帧的超分辨率技术,称之为多帧视频/多图的超分辨率(multi-frame super resolution)。对于video SR,其核心思想就是用时间带宽换取空间分辨率。简单来讲,就是在无法得到一张超高分辨率的图像时,可以多取相邻几帧,然后将这一系列低分辨率的图像组成一张高分辨的图像。
一般来讲Video SR相比于Image SR具有更多的可参考信息,并具有更好的高分辨率视频图像的重建质量,但是其更高的计算复杂度也限制了其应用。本博文主要介绍SISR。SISR是一个逆问题,对于一个低分辨率图像,可能存在许多不同的高分辨率图像与之对应,因此通常在求解高分辨率图像时会加一个先验信息进行规范化约束。在传统的方法中,这个先验信息可以通过若干成对出现的低-高分辨率图像的实例中学到。而基于深度学习的SR通过神经网络直接学习分辨率图像到高分辨率图像的端到端的映射函数。
传统的图像超分辨率重建技术简介
基于插值的图像超分
通过某个点周围若干个已知点的值,以及周围点和此点的位置关系,根据一定的公式,算出此点的值,就是插值法。对于如何把原图像的点摆放在新图中并确定具体坐标;未知的点计算时,需要周围多少个点参与,公式如何,如何计算,不同的方案选择,就是不同的插值算法。图像处理中,常用的插值算法有:最邻近元法,双线性内插法,三次内插法等等。
例如:现有一张分辨率为3 x 2的图片,原图每个像素点的亮度值是:

我们要把它变成分辨率为6 x 4的图片,把这6个已经知道的点,放在他们大概应该在新图的位置:
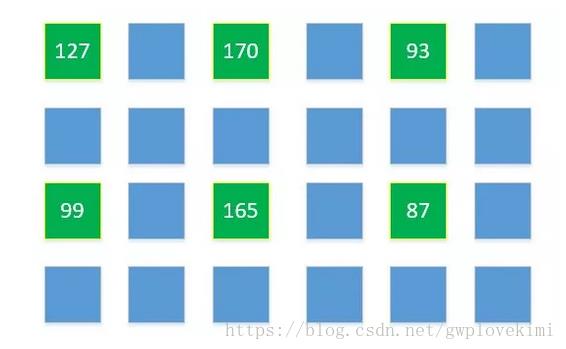
那么我们已经知道6 x 4新图中6个已知的点(绿色),下面只需要求剩余18个点(蓝色)的值即可。通过某个点周围若干个已知点的值,以及周围点和此点的位置关系,根据一定的公式,算出此点的值,就是插值法。如何把原图像的点摆放在新图中(确定具体坐标);未知的点计算时,需要周围多少个点参与,公式如何。不同的方案选择,就是不同的插值算法。图像处理中,常用的插值算法有:最邻近元法,双线性内插法,三次内插法等等。但是实际上,通过这些插值算法,提升的图像细节有限,所以使用较少。通常,通过多幅图像之间的插值算法来重建是一个手段。另外,在视频超分辨重建中,通过在两个相邻帧间插值添加新帧的手段,可以提升视频帧率,减少画面顿挫感。
基于重建的图像超分辨率
基于重建的方法通常都是基于多帧图像的,需要结合先验知识。有如下方法:
-
凸集投影法(POCS)
-
贝叶斯分析方法
-
迭代反投影法(IBP)
-
最大后验概率方法
-
正规化法
-
混合方法
基于学习的图像超分辨率
机器学习领域(非深度学习邻域)的图像超分方法如下:
-
Example-based方法
-
邻域嵌入方法
-
支持向量回归方法
-
虚幻脸
-
稀疏表示法
基于深度学习的图像超分辨率重建技术
基于深度学习的图像超分辨率重建的研究流程如下:
1,首先找到一组原始图像Image1;
2,然后将这组图片降低分辨率为一组图像Image2;
3,通过各种神经网络结构,将Image2超分辨率重建为Image3(Image3和Image1分辨率一样)
4,通过PSNR等方法比较Image1与Image3,验证超分辨率重建的效果,根据效果调节神经网络中的节点模型和参数
5,反复执行,直到第四步比较的结果满意
两种常用的评价超分的指标——PSNR和SSIM
对SR的质量进行定量评价常用的两个指标是PSNR(Peak Signal-to-Noise Ratio)和SSIM(Structure Similarity Index)。这两个值越高代表重建结果的像素值和标准越接近。
1、PSNR(Peak Signal to Noise Ratio)峰值信噪比:
MSE表示当前图像X和参考图像Y的均方误差(Mean Square Error),H、W分别为图像的高度和宽度
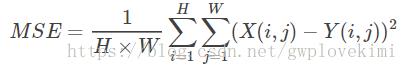
PSNR的单位是db,数值越大表示失真越小。n为每像素的比特数,一般的灰度图像取8,即像素灰阶数为256.
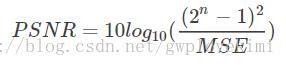
SRCNN(Super-Resolution Convolutional Neural Network)
(Learning a Deep Convolutional Network for Image Super-Resolution, ECCV2014)
code: http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html
传统的SR方法都是学习compact dictionary or manifold space to relate low/high-resolution patches。
SRCNN是深度学习在图像超分辨率重建上的开山之作,通过采用卷积神经网络来实现低分辨率到高分辨率图像之间端到端的映射。网络的结构如下图所示:
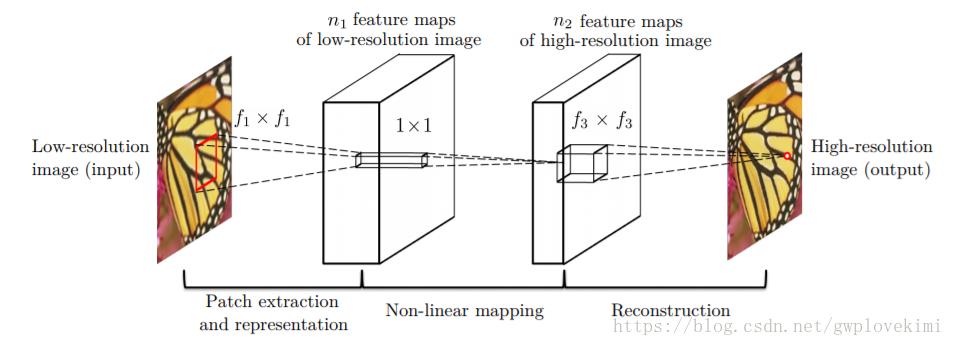
对于一个低分辨率得图像,首先采用双三次插值(bicubic)将低分辨率图像放大成目标尺寸,接着通过三层卷积网络拟合非线性映射,最后输出高分辨率图像结果。在文种,作者将三层卷积的结构解释成三个步骤:图像块的提取和特征表示,特征非线性映射和最终的重建。三个卷积层使用的卷积核的大小分为为9x9,,1x1和5x5,前两个的输出特征个数分别为64和32。用Timofte数据集(包含91幅图像)和ImageNet大数据集进行训练。使用均方误差(Mean Squared Error, MSE)作为损失函数,有利于获得较高的PSNR。

SRCNN的流程为:
step1:图像块提取(Patch extraction and representation)。先将低分辨率图像使用双三次(实际上,bicubic也是一个卷积的操作,可以通过卷积神经网络实现)插值放大至目标尺寸(如放大至2倍、3倍、4倍,属于预处理阶段),此时仍然称放大至目标尺寸后的图像为低分辨率图像(Low-resolution image),即图中的输入(input)。从低分辨率输入图像中提取图像块,组成高维的特征图。
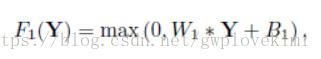
其中,W1和B1为超参。激活函数采样ReLu
step2:非线性映射(Non-linear mapping)。第一层卷积:卷积核尺寸9×9(f1×f1),卷积核数目64(n1),输出64张特征图;第二层卷积:卷积核尺寸1×1(f2×f2),卷积核数目32(n2),输出32张特征图;这个过程实现两个高维特征向量的非线性映射;
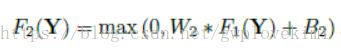
W2为n1*1*1*n2。采用了1*1卷积(single convolutional layer,目的应该是压缩feature map的深度,同时也起到非线性映射的作用)。
step3:重建(Reconstruction)。第三层卷积:卷积核尺寸5×5(f3×f3),卷积核数目1(n3),输出1张特征图即为最终重建高分辨率图像;
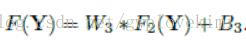
模型参数结构如下:
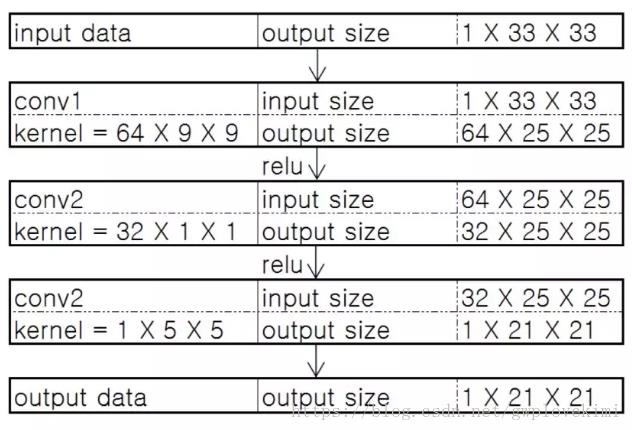
- 第一层卷积:卷积核尺寸9×9(f1×f1),卷积核数目64(n1),输出64张特征图;
- 第二层卷积:卷积核尺寸1×1(f2×f2),卷积核数目32(n2),输出32张特征图;
- 第三层卷积:卷积核尺寸5×5(f3×f3),卷积核数目1(n3),输出1张特征图即为最终重建高分辨率图像。
LOSS function(Mean Squared Error (MSE))。估计超参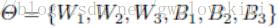 。
。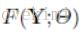 为重构的结果,
为重构的结果,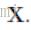 为ground truth。Using MSE as the loss function favors a high PSNR.
为ground truth。Using MSE as the loss function favors a high PSNR.
下面是SRCNN与传统算法得结果对比
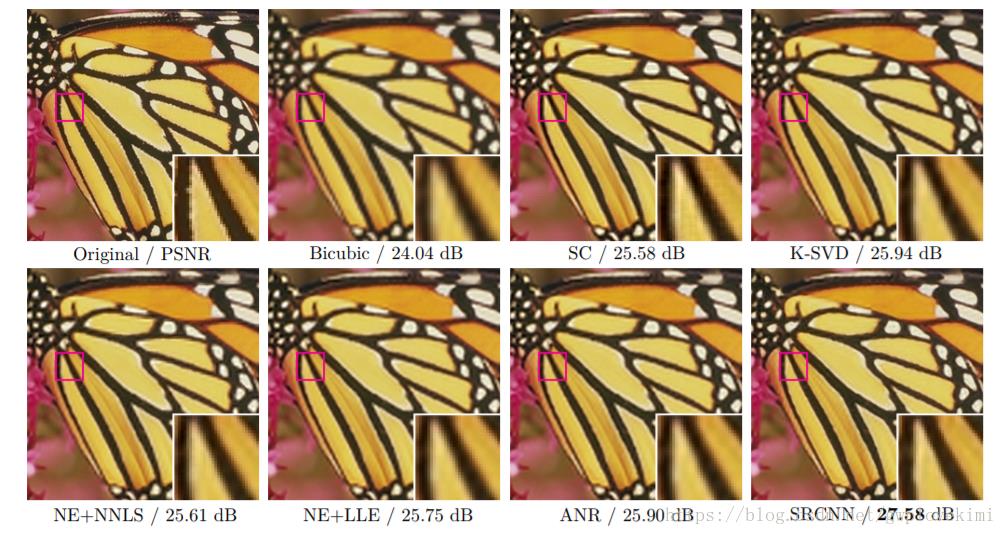
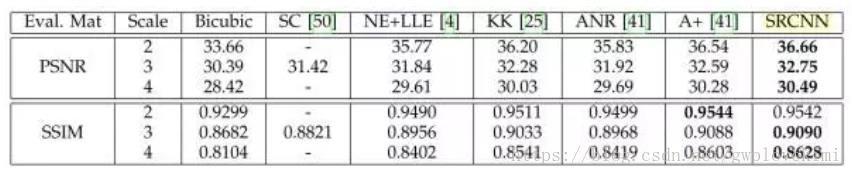
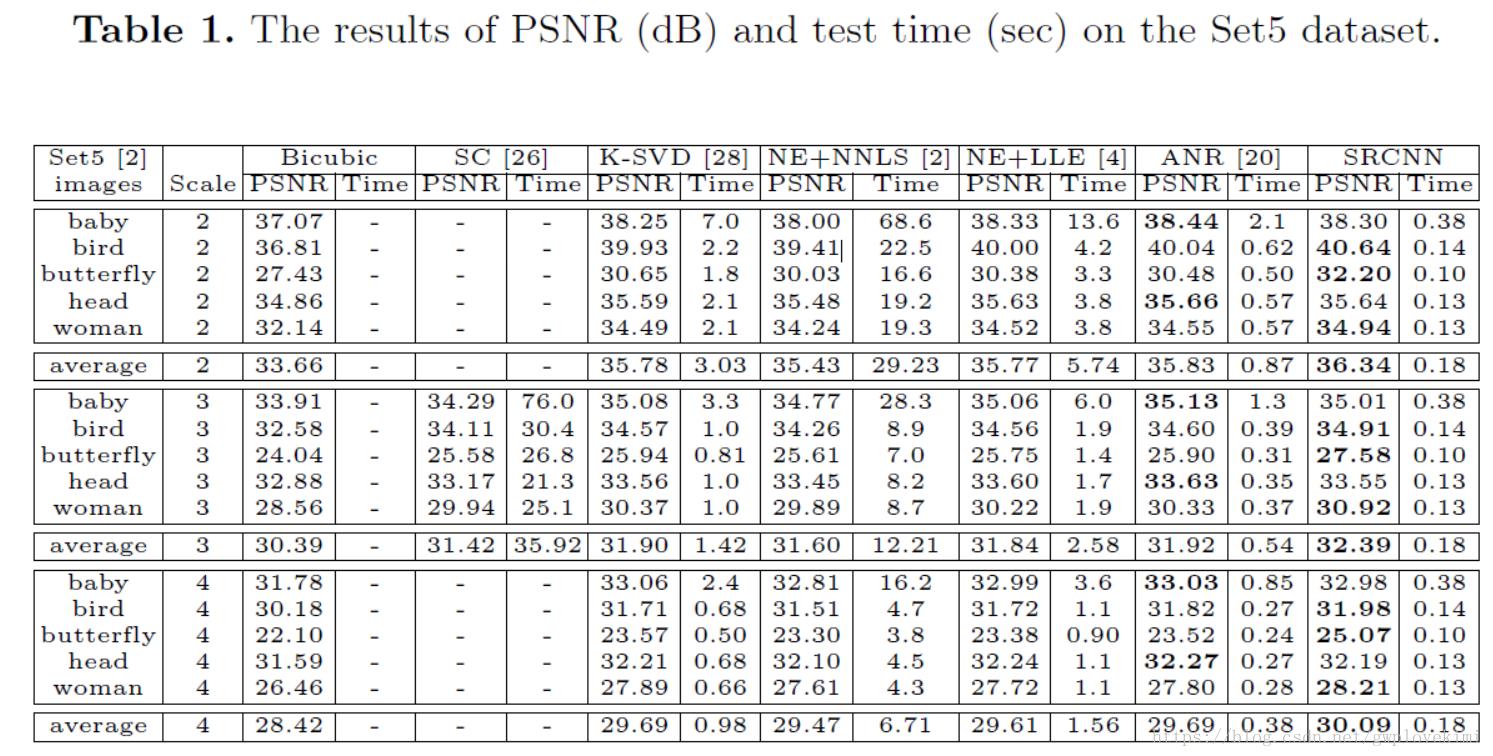
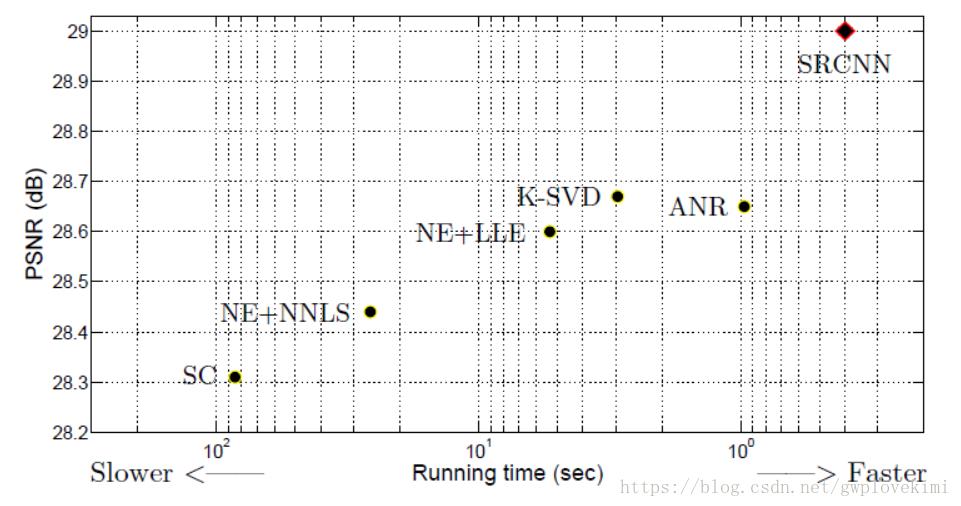
SRCNN的本质就是用了深度卷积网络实现了稀疏编码的方法。只不过稀疏编码的参数需要人工优化,而且能优化的参数有限。但是SRCNN能根据输入的训练集自动优化学习所有参数。因此效果比以前的方法要好。
FSRCNN(Fast Super-Resolution Convolutional Neural Networks)
(Accelerating the Super-Resolution Convolutional Neural Network, ECCV2016)
code: http://mmlab.ie.cuhk.edu.hk/projects/FSRCNN.htmlhttp://
对于一幅240*240的图片,要放大三倍,SRCNN的速度为1.32fps(而实际要求起码要到24fps)
FSRCNN是对SRCNN的改进(主要起到加速的作用,40times)。改进结果体现在非常快的处理速度上和稍稍提高的输出质量。其主要贡献有三点:
- 在最后使用了一个反卷积层(deconvolution layer)放大尺寸(并将反卷积层放于最后,可以缩少计算时间),因此可以将原始的低分辨率图像直接输出到网络中,不需要先通过bicubic interpolation方法放大尺寸,直接对低分辨率图像进行处理(去掉预处理阶段,可以大大提升速度);
- 非线性映射部分也十分耗费计算时间(通过shrink the network scale来提高实时性)。改变特征维数,更小的卷积核,更多的映射层;在映射前缩少输入特征的维数,然后再扩展;
- 可共享其中的卷积层,如需训练不同上采样倍率的模型,只需fine-tuning最后的反卷积层。only need to do convolution operations once, and upsample an image to different scales using the corresponding deconvolution layer.
由于FSRCNN不需要在网络外部进行放大图像尺寸(小的图片尺寸可以降低训练时间),同时用一些小的卷积层来代替SRCNN中的大卷积层,因此速度上FSRCNN有较大的提升。且如果仅仅需要FSRCNN得到不同分辨率的图片,只需单独训练反卷积层即可,更加省时,不需要重新训练整个网络。SRCNN与FSRCNN的网络结构对比如下图所示:
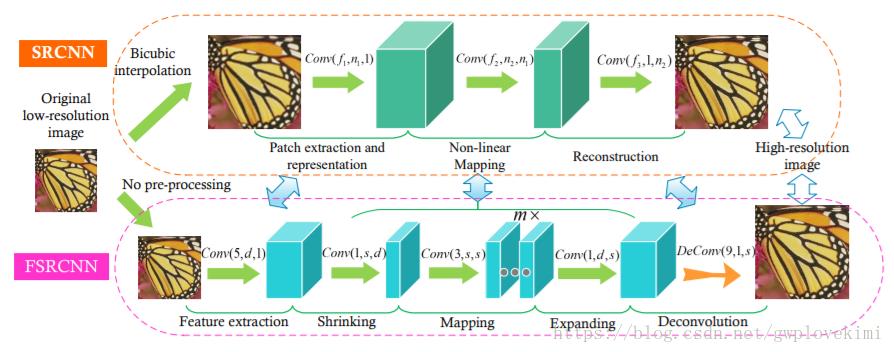
FSRCNN分为五个步骤(每个卷积层的激活函数采用PReLU):
step1:特征的提取(feature extraction)。SRCNN中针对的是插值后的低分辨率图像,选取的核大小为9×9。而FSRCNN是直接是对原始的低分辨率图像进行操作,因此可以选小一点,设置为5×5。
step2:收缩(shrinking)。在SRCNN中,特征提取完就进行非线性映射,但当feature map的深度较大时,计算复杂度较高。故此在FSRCNN中,通过应用1×1的卷积核进行降维,减少网络的参数(降低深度),降低计算复杂度。
step3:非线性映射(mapping,The non-linear mapping step is the most important part that affects the SR performance,主要体现在每一层的滤波器数目,以及层数(也即是深度))。感受野大,能够表现的更好。在SRCNN中,采用的是5×5的卷积核,但是5×5的卷积核计算量会比较大。用两个串联的3×3的卷积核可以替代一个5×5的卷积核,同时两个串联的小卷积核需要的参数3×3×2=18比一个大卷积核5×5=25的参数要小。FSRCNN网络中通过m个核大小为3×3的卷积层进行串联。
step4:扩张(expanding)。作者发现低维度的特征带来的重建效果不是太好,因此应用1×1的卷积核进行扩维,相当于收缩的逆过程(用1*1的卷积核进行扩张,增加深度)。
step5:反卷积层(deconvolution,卷积层的逆操作)。如果步长为n,那么尺寸放大n倍,实现了上采样的操作。
For convolution, the filter is convolved with the image with a stride k, and the output is 1=k times of the input. Contrarily, if we exchange the position of the input and output, the output will be k times of the input。如下图所示
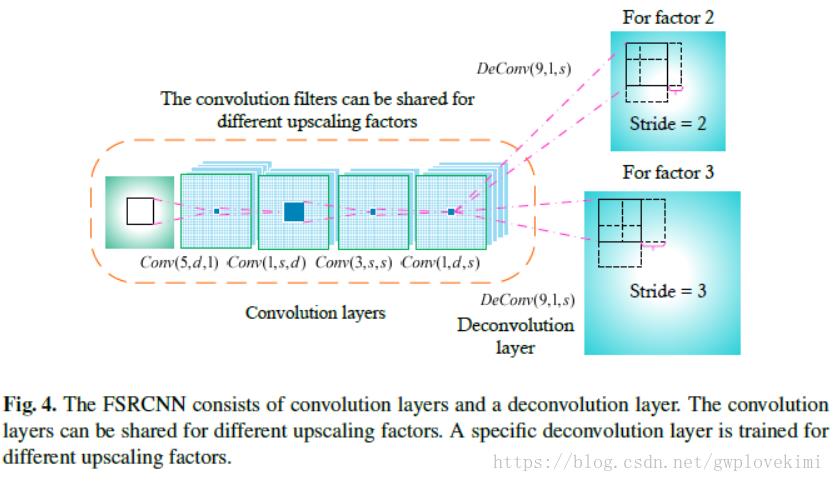
卷积与反卷积的示意:
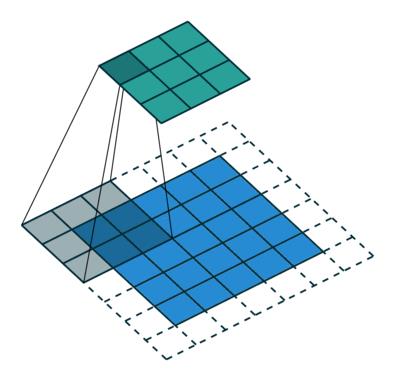
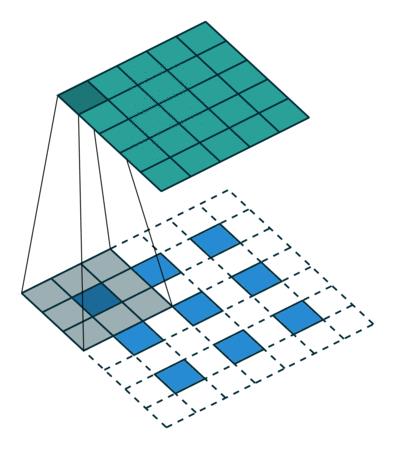
整个结构为:
loss function 跟SRCNN一样
结果对比如下:


ESPCN(Efficient Sub-Pixel Convolutional Neural Network)
(Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network, CVPR2016)
github(tensorflow): https://github.com/drakelevy/ESPCN-TensorFlowhttps://
github(pytorch): https://github.com/leftthomas/ESPCNhttps://
github(caffe): https://github.com/wangxuewen99/Super-Resolution/tree/master/ESPCNhttps://
(本文同时实现了video和image的超分)
本文的作者提到:对于类似于SRCNN的方法,由于需要将低分辨率图像通过上采样插值得到与高分辨率图像相同大小的尺寸,再输入到网络中,这意味着要在交大的尺寸上进行卷积操作,从而增加了计算复杂度。为此本文作者提出了一种直接在低分辨率图像尺寸上提取特征,计算得到高分辨率图像的高效方法(efficient sub-pixel convolution layer 来代替插值处理)。ESPCN网络结构如下图所示。
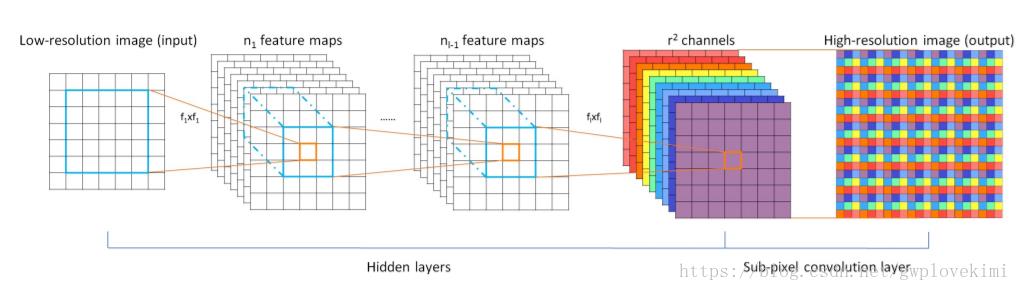
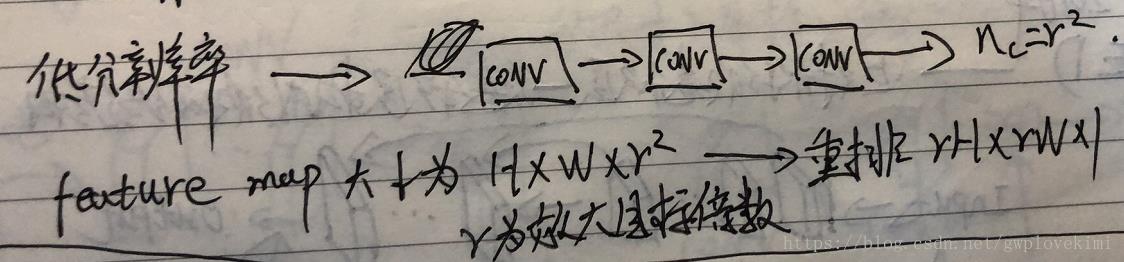
ESPCN的核心概念是亚像素卷积层(sub-pixel convolutional layer)。网络的输入是原始低分辨率的图像,经过三个CONV后,得到通道数为 的与输入图像大小一样的特征图像。再将特征图像每个像素的
个通道重新排列成一个
的区域,对应高分辨率图像中一个
大小的子块,从而大小为
的特征图像被重新排列成
的高分辨率图像(理解如下图所示)。而图像尺寸放大过程的插值函数被隐含地包含在前面的卷积层中,有神经网络自己学习到。由于卷积运算都是在低分辨率图像尺寸大小上进行,因此效率会较高。
其效果如下图所示:
(对 1080 HD 格式的视频进行3倍放大,SRCNN 每帧需要0.435s,而 ESPCN 则只需0.038s)


VESPCN(Video Efficient Sub-Pixel Convolutional Neural Network)
(Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation,CVPR2017)
STN(Spatial Transform Networks, STN)
CNN分类时,通常需要考虑输入样本的局部性、平移不变性、缩小不变性,旋转不变性等,以提高分类的准确度。而实现这些不变性的传统方法实际上就是对图像进行空间坐标变换,我们所熟悉的一种空间变换就是仿射变换,图像的仿射变换公式可以表示如下:
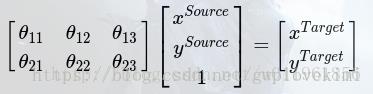
式中, 表示原图像像素点,
表示原图像像素点,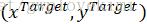 表示仿射变换后的图像像素点。系数矩阵θ即为仿射变换系数,可以通过调整系数矩阵θ,实现图像的放大、缩小、平移、旋转等。
表示仿射变换后的图像像素点。系数矩阵θ即为仿射变换系数,可以通过调整系数矩阵θ,实现图像的放大、缩小、平移、旋转等。
而STN网络提出了一种叫做空间变换网络的模型,该网络不需要关键点的标定,能够根据分类或者其它任务自适应地将数据进行空间变换和对齐(包括平移、缩放、旋转以及其它几何变换等)。在输入数据空间差异较大的情况下,这个网络可以加在现有的卷积网络中,提高分类的准确性。该空间变换网络包括三个部分,网络结构如下图所示:
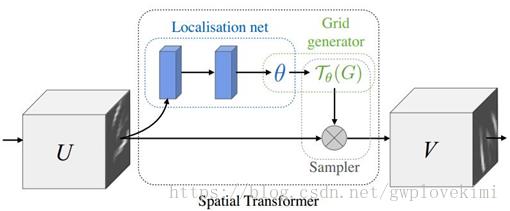
Localisation Network——该网络就是一个简单的回归网络。将输入的图片进行几个卷积操作,然后全连接回归出6个角度值(假设是仿射变换),2*3的矩阵。
Grid generator——网格生成器负责将V中的坐标位置,通过矩阵运算,计算出目标图V中的每个位置对应原图U中的坐标位置。即生成T(G)
Sampler——采样器根据T(G)中的坐标信息,在原始图U中进行采样,将U中的像素复制到目标图V中。
简而言之,STN网络首先通过一个简单的回归网络生成6个θ,用以进行原图的仿射变换。然后依据θ矩阵,将目标图上每个点与原图进行对应。最后使用采样器,将原图上的像素值采样到目标图中。流程如下图:
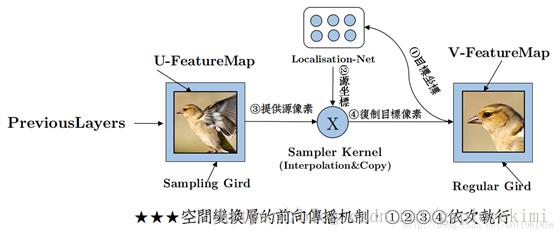
但是,在VESPCN中,并不按照这个变换顺序。作者使用一个近10层的卷积网络,计算整一张输入图片的光流。即直接实现了STN网络中的第二部分,然后再利用二次插值进行采样操作。作者同样将这个操作称为Spatial Transform。
好,介绍完STN后,正式介绍VESPCN。
在视频图像的SR问题中,相邻几帧间具有很强的关联性。VESPCN(属于video超分)提出使用视频中的时间序列图像进行高分辨率重建(可以达到实时性处理)。算法主要包括以下三个方面:
step 1:纠正相邻帧的位移偏差,先通过Motion estimation(动作补偿,可采用光流法)估计出位移,然后利用位移参数对相邻帧进行空间变换,将二者对齐;
step 2:把对齐后的相邻若干帧叠放在一起,当作一个三维数据;在低分辨率的三维数据上使用三维卷积,得到的结果大小为
step 3:采用ESPCN,将特征图像被重新排列成的高分辨率图像;
VESPCN的网络结构如下图所示
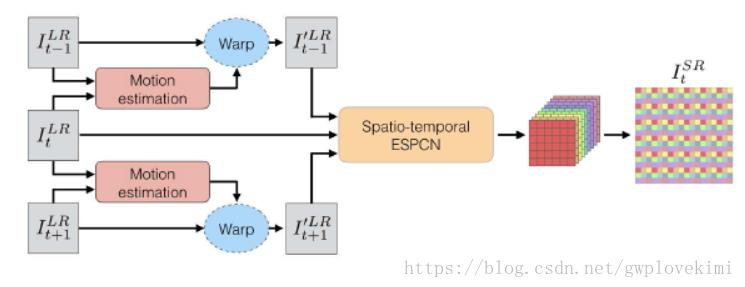
VESPCN主要分为两块:相邻帧之间的位移估计和SR重建,两者都通过神经网络来实现(Spatio-temporal networks & Subpixel convolution SR)。SR重建采用的就是上面介绍的ESPCN。下面介绍一下动作补偿
Motion estimation这个过程可以通过传统的光流算法来计算,VESPCN使用了STN网络进行动作补偿(其框架如下图所示)。Spatial Transformer Networks, 通过CNN来估计空间变换参数。首先通过初始的两帧(低的分辨率上)估计粗糙的光流,并生成粗糙的目标帧,这两个再与原始的两个帧插值(高的分辨率)输入网络,得到精细的光流。精细的光流和粗糙光流一起得到最后的帧。输出使用tanh激活层。
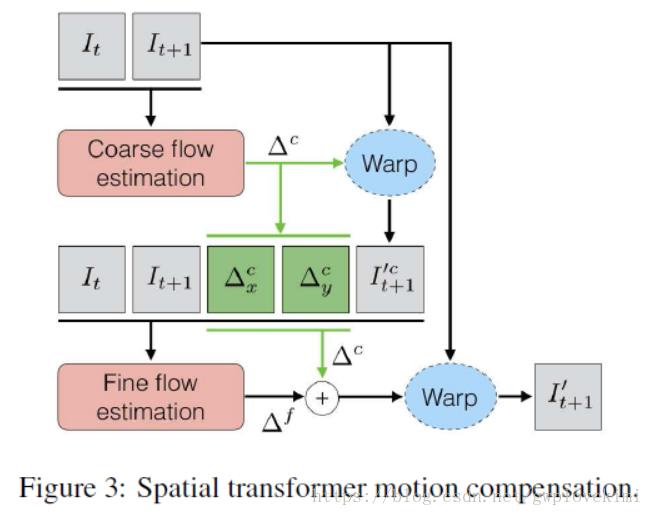
具体来说,在VESPCN中,是利用video前后两帧图像的信息来进行高分辨率的重建,然而在视频序列中,前后两帧中的场景与物体会发生(微小)的位移,因此在SR前,要先对两帧图像进行“对齐”。“对齐”的过程可以看作是对图像做仿射变换的过程,图片并不是只通过平移就可以“对齐”,还要进行旋转、缩放等操作。因此作者借鉴了STN网络和光流的思想,使用动作补偿网络来实现两帧图片的对齐功能。具体步骤如下:
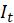 与
与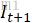 代表前后两帧图片,首先将它们进行堆叠(即在第三维上拼接),后通过一个6层的卷积网络(如下图)得到长宽与原图相同,通道数为2的一张feature map,即图中的∆c(
代表前后两帧图片,首先将它们进行堆叠(即在第三维上拼接),后通过一个6层的卷积网络(如下图)得到长宽与原图相同,通道数为2的一张feature map,即图中的∆c(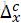 代表其x方向分量),称为粗糙光流。
代表其x方向分量),称为粗糙光流。

- Warp是STN网络的步骤,即利用得到的光流图对
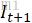 进行仿射变换(对齐)得到
进行仿射变换(对齐)得到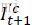 。这样做得到的动作补偿仍然达不到理想要求。因此还要计算精细光流。
。这样做得到的动作补偿仍然达不到理想要求。因此还要计算精细光流。 - 将原图的前后两帧(
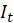 和
和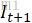 )、粗糙光流、
)、粗糙光流、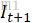 经过首次warp之后得到的图片(即
经过首次warp之后得到的图片(即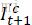 ),三张图进行堆叠,使用一个6层的卷积网络(上图)计算得到一张通道数为2的精细光流。
),三张图进行堆叠,使用一个6层的卷积网络(上图)计算得到一张通道数为2的精细光流。 - 将粗糙光流图与精细光流图相加,得到联合光流图(图中
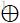 )。再利用联合光流图对
)。再利用联合光流图对 进行仿射变换,即使用STN。得到最终的经过动作补偿后的
进行仿射变换,即使用STN。得到最终的经过动作补偿后的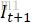 。
。
loss function
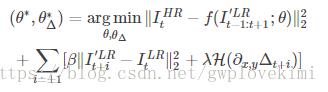
损失函数由三个部分组成:
1. 高分辨率输出图MSE损失 (ESPCN网络的损失函数)
2. [前一帧+当前]动作补偿图MSE损失 + Huber 损失 (光流与STN)
3. [后一帧+当前]动作补偿图MSE损失 + Huber 损失 (光流与STN)
图像融合
Spatio-temporal networks可以处理输入为许多帧的情况,对于前中后三帧(多个帧)融合的方法有early fusion,slow fusion,3D convolution三种。其中3D convolution是slow fusion的权重共享的形式。如下图所示
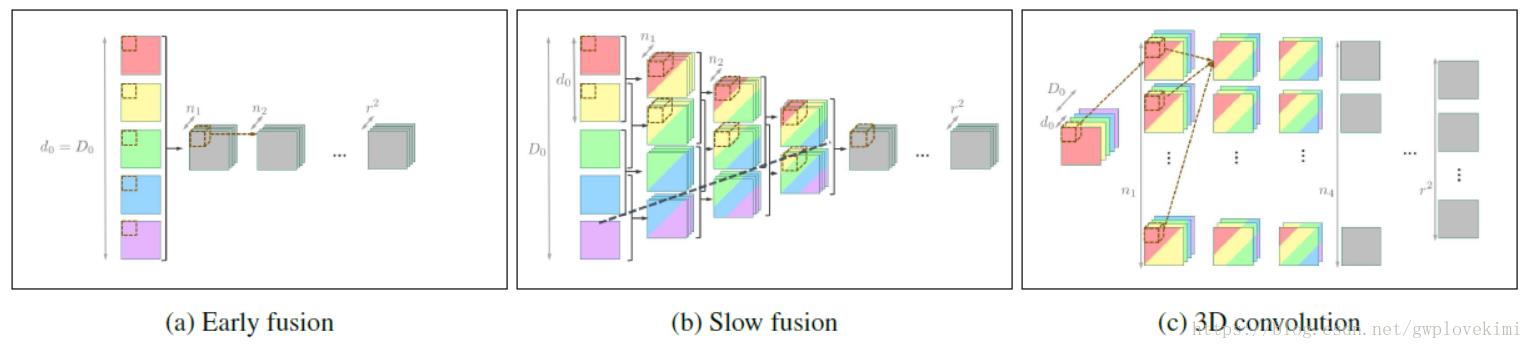
在VESPCN中使用的是early fusion方法,即在三张图片输入网络之前就进行堆叠。但是论文作者认为slow fusion在网络变深时效果才好于early fusion。
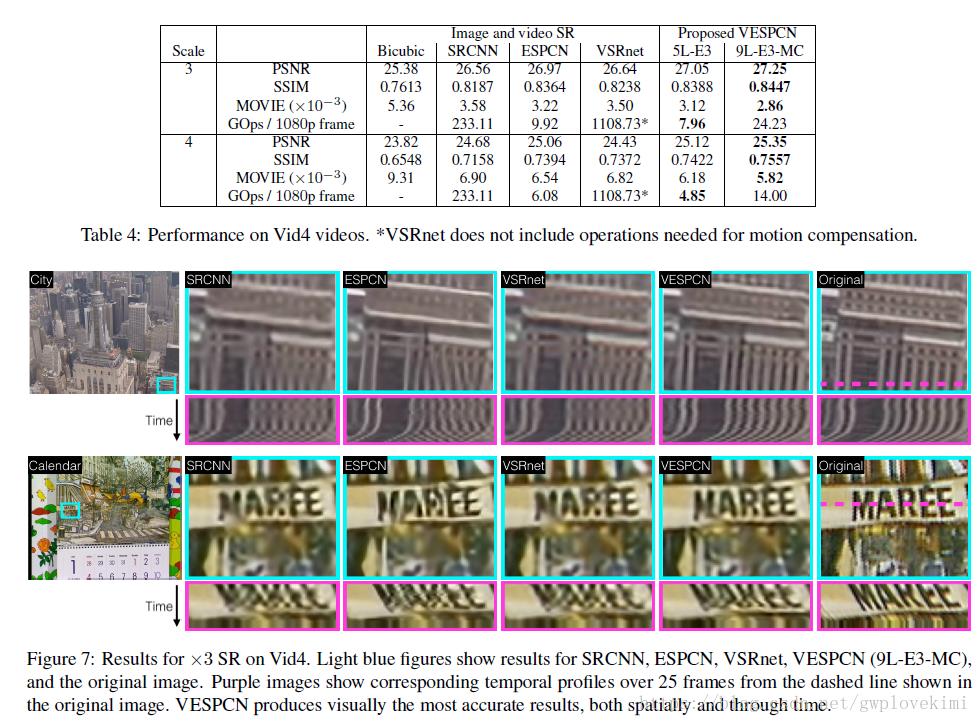
结果展示:


VDSR(VeryDeep Convolutional Networks)
(Accurate Image Super-Resolution Using Very Deep Convolutional Networks, CVPR2016)
code: https://cv.snu.ac.kr/research/VDSR/
github(caffe): https://github.com/huangzehao/caffe-vdsrhttps://
github(tensorflow): https://github.com/Jongchan/tensorflow-vdsrhttps://
github(pytorch): https://github.com/twtygqyy/pytorch-vdsrhttps://
VDSR是从SRCNN的基础上改进的网络。正如它的名字Very Deep Super-Resolution,其最大的结果特点就是层数很多。它的最终效果准确率非常地高,并且还比SRCNN快。作者认为SRCNN有三个缺点:
1、学习的信息有限。
SR是一个逆问题,解决SR问题是借助大量的学习信息得到结果。直观地认为,如果学习的数据越多,学习的上限越大,那么得到的准确性越高。在深度学习中,就是感受野越大,理论上得到的准确性越高。而SRCNN只有三层,得到感受野只有13*13,结果受限于那13*13个像素。
2、收敛太慢。
虽然SRCNN相比于当时其他的SR算法已经算快了,但在还是无法满足实际需求,SRCNN训练一个网络花了一星期之久,而SR的应用领域之非常多,要实现实际的应用,对算法收敛速度的提升是很有必要的。
3、无法实现统一模型的多尺度方法。
虽然放大倍数是在训练前认为设计的,但在生活中人们放大一张图可以是任意倍数的(包括小数)。SRCNN一个网络只能训练一个放大倍数,倘若对每一个倍数都训练一个SRCNN,那是不现实的。所以我们期望一种新的网络能实现不同倍数的超分辨。
这三个缺点,也是作者针对SRCNN的改进方向,最终创造一种多层网络能优化以上缺点,命名为VDSR。
对于超分的问题,实际上,输入的低分辨率图像与输出的高分辨率图像在很大程度上是相似的。也就是,低分辨率图像的低频信息与高分辨率图像的低频信息相近。那么实际上,低分辨率图片与高分辨率图片只是缺乏高频部分的残差,若训练的时候,仅仅训练高分辨率和低分辨率之间的高频残差部分,那么就不需要在低频部分花太多的时间。为此,作者引入了ResNet的思想(参见博文:学习笔记之——基于深度学习的分类网络(未完待续))输出的结果=低分辨率输入(经过插值变成目标尺寸的低分辨率图像)+网络学习到的残差。残差网络结构的思想特别适合用来解决超分辨率问题,可以说影响了之后的深度学习超分辨率方法。VDSR是最直接明显的学习残差的结构,其网络结构如下图所示
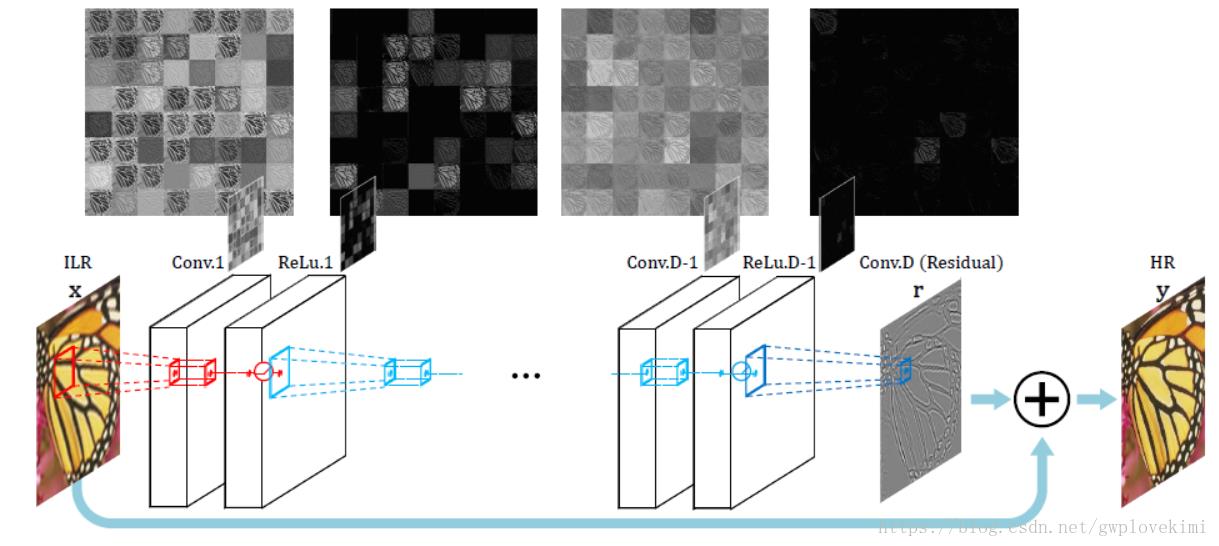
VDSR的改进:
1.加深了网络结构(20层),使得越深的网络层拥有更大的感受野。文章选取3×3的卷积核,深度为D的网络拥有(2D+1)×(2D+1)的感受野。
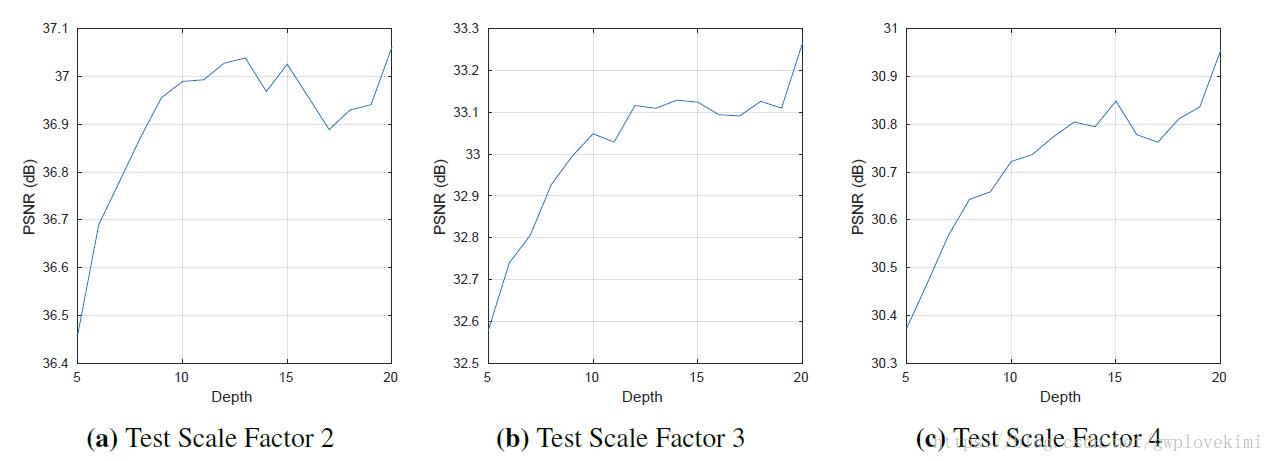
本文的作者认为多层网络对提高SR的准确性非常有帮助,原因有两个:(i)多层网络能获得非常大的感受野理论上,感受野越大,学习的信息越多,准确率越大。对于一个m层全卷积网络,如果每层的过滤器大小(假设长和宽相等)是fi,那么用数学归纳法最终得到的感受野为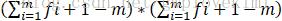 当m=20,fi=3。得到的感受野为(20*3+1-20)* (20*3+1-20),即为41*41。(ii)多层网络能现实复杂的非线性映射,如下图所示,为层数对VDSR的效果影响,可以看出层数越多,效果越好
当m=20,fi=3。得到的感受野为(20*3+1-20)* (20*3+1-20),即为41*41。(ii)多层网络能现实复杂的非线性映射,如下图所示,为层数对VDSR的效果影响,可以看出层数越多,效果越好
但太多层网络也有不好的地方。首先是多层网络的收敛问题,SRCNN层提出4层的网络,但训练了一星期得出的结果不好。作者认为这是由于4层SRCNN的收敛速度低和收敛稳定不好而导致的。为了解决收敛问题,作者采用了残差学习和自适应梯度剪切的方法。
2.采用残差学习,残差图像比较稀疏,大部分值都为0或者比较小,因此收敛速度快。VDSR还应用了自适应梯度裁剪(Adjustable Gradient Clipping),将梯度限制在某一范围,也能够加快收敛过程。与此同时再采用高学习率。
残差学习
由于输入图像和输出图像有着高度的相似性(高分率图像可以看出是低分辨率图像+高分率图像的信息)。所以我们可以改用学习输出与输入的残差(即高分辨率的特征)取代直接学习全部(高分辨率的特征+低分辨率的特征)。输入图像是x,f(x)是经过学习得到的残差,r=y-x是实际的残差。那么损失函数为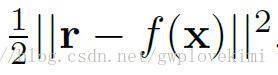 ,当损失函数够小时,f(x)+x就能逼近y了。残差学习能提高收敛速度,因为只需学习高分辨率的特征。从上面网络结构图中的特征图上可以看到,很多是空的,残差学习只学习了高分辨率的特征。下图为用残差学习和不用残差学习的算法比较。可以看到残差学习(蓝色的线)的学习速度非常的快(Epochs很小的时候就收敛了)
,当损失函数够小时,f(x)+x就能逼近y了。残差学习能提高收敛速度,因为只需学习高分辨率的特征。从上面网络结构图中的特征图上可以看到,很多是空的,残差学习只学习了高分辨率的特征。下图为用残差学习和不用残差学习的算法比较。可以看到残差学习(蓝色的线)的学习速度非常的快(Epochs很小的时候就收敛了)
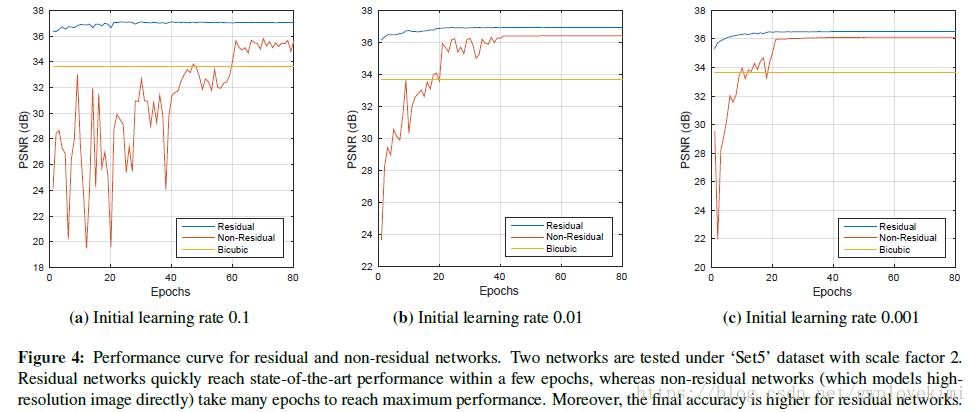
上图中为VDSR的论文原图,作者用VDSR(使用残差学习)和另外一个不用残差学习的网络比较。但这可能并非严格的控制变量法,论文的描述为“Performance curve for residual and non-residual networks.”VDSR除了使用残差学习,还用了多层网络、自适应梯度剪切、高学习率等技巧。如果拿VDSR和SRCNN比较,并不能说明残差学习的优越。
自适应梯度剪切
由于链式法则的计算,当网络的层数非常多时,经常出现梯度消失或者梯度爆炸的现象。体现在图像,就是损失函数有一个悬崖式的变化。如果设置的学习率太大,那么可能出现修改过度,甚至丢失已经优化好的数据。而自适应梯度剪切就是根据你的学习率,调整梯度的角度,确保收敛的稳定性。
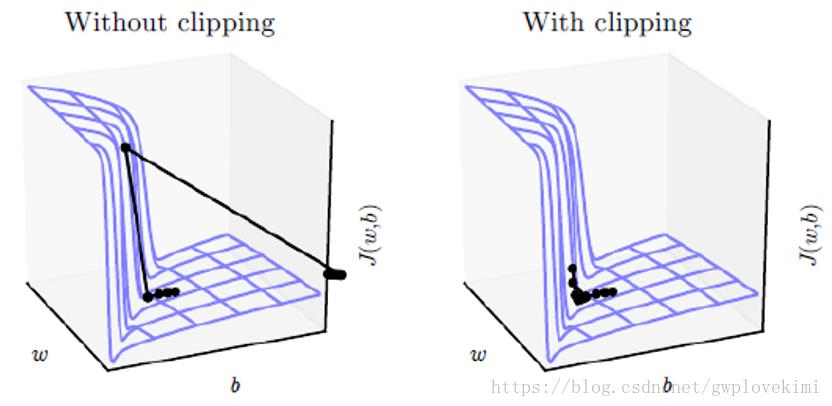
高学习率
提高收敛速度的最直接方式就是增大学习率,但单纯的增大高学习率会产生收敛问题(收敛不稳定),虽然作者已经用了自适应梯度剪切的方法来增大收敛稳定性。但作者在设置学习率时,也能使用一下技巧来增强收敛稳定性。具体的做法是,一开始设置一个很大的学习率(CDSR简单地令每层的学习率相同),每过20个epochs,将学习率缩小十倍。这么做的原理也很直观,一开始训练时网络损失函数还较大,能够大胆地用高学习率来缩短收敛时间,随着训练次数得增多,模型趋向收敛,如果继续用高学习率,就会破坏收敛稳定性,所以改用小学习率,确保网络收敛。这么多次缩小学习率,进一步缩小了收敛时间。
3.对于采用非常深的网络来预测输出,会导致每一次进行卷积运算,feature map的大小都会减少,这样甚至会造成高清新图像的尺寸会比低分辨图像的尺寸小。这与其他超分辨率方法是一致的,因为许多方法需要周围的像素来正确地推断中心像素。这个中心环绕关系是有用的,因为周围区域为这个超分辨率这个病态问题提供了更多的约束。对于图像边界附近的像素影响最大,因为边界像素与周边像素的关系最强,随着尺度变小,周边像素的影响力减小,对边界像素的学习不是好事。许多SR方法对结果图像进行裁剪。然而,如果所需的环绕区域非常大,这种方法就无效了。裁剪后,最终的图像太小,无法达到视觉效果。为了解决这个问题,VDSR在每次卷积前都对图像进行补0操作,这样保证了所有的特征图和最终的输出图像在尺寸上都保持一致,解决了图像通过逐步卷积会越来越小的问题,又突出了边界像素的特征。文中说实验证明补0操作对边界像素的预测结果也能够得到提升。
4.多尺度学习。VDSR将不同尺度的图像混合在一起训练,这样训练出来的一个模型就可以解决不同倍数的超分辨率问题(同一个模型学习多个尺度的放大)。那么就不存在SRCNN中网络只适用于单一规模的问题了。

可以根据实验结果得出几点结论。
- 对于低倍数图像,用多尺度训练的网络几乎和用单尺度训练的网络一样
- 对于高倍数图像,采用多尺度训练的效果比采用单尺度训练的网络的效果好
原因是高倍数放大和低倍数放大有相似之处,它们间可以互相学习,尤其是高倍数的放大,能从低倍数放大的学习中额外获得新的信息,从而导致对于高倍数图像,采用多尺度训练的网络比采用单尺度训练的网络好。
VDSR之后,几乎所有的网络都借鉴了其学习残差的思想,原因在下图的效果图里就可以看出来
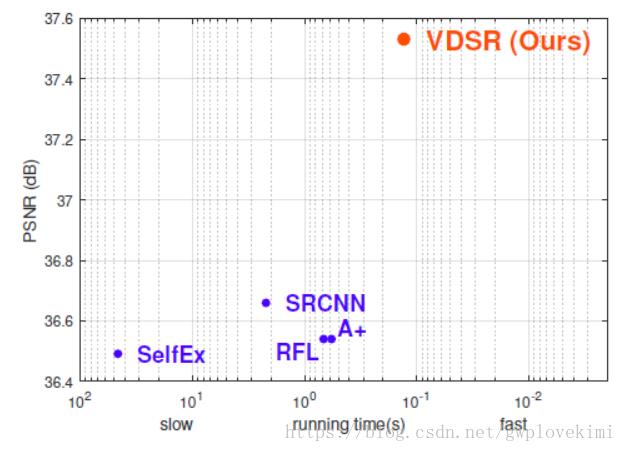
结果对比如下图所示:
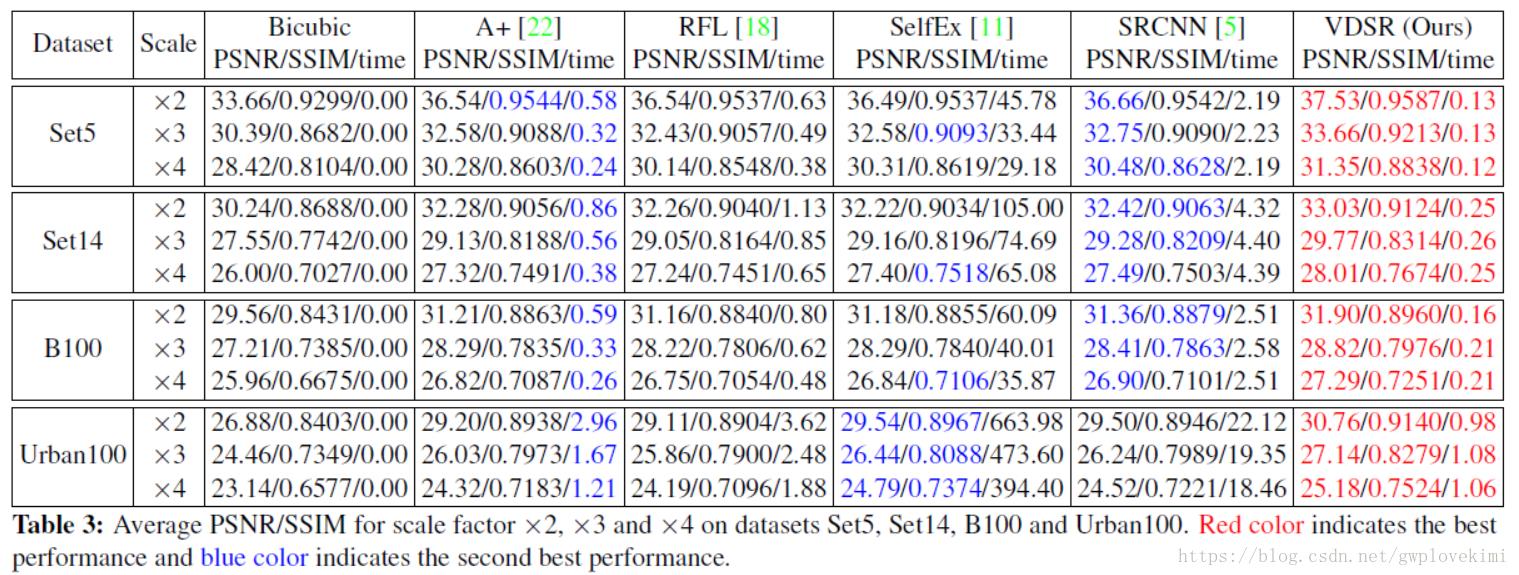

DRCN(Deeply-Recursive Convolutional Network)
(Deeply-Recursive Convolutional Network for Image Super-Resolution, CVPR2016)
code: https://cv.snu.ac.kr/research/DRCN/
githug(tensorflow): https://github.com/jiny2001/deeply-recursive-cnn-tfhttps://
DRCN与上面的VDSR都是来自首尔国立大学计算机视觉实验室的工作,两篇论文都发表在CVPR2016上,两种方法的结果非常接近。其贡献主要如下:
1、将RNN(递归神经网络,Recursive Neural Network)的结构应用于SR中。RNN用于非线性映射时,通过RNN,数据循环多次地通过该层,而将这个RNN展开的话,就等效于使用同一组参数的多个串联的卷积层;
2、利用了ResNet的思想,加入了skip-connection,加深了网络结构(16个递归),增加了网络感受野,提升了性能。DRCN网络结构如下图所示:
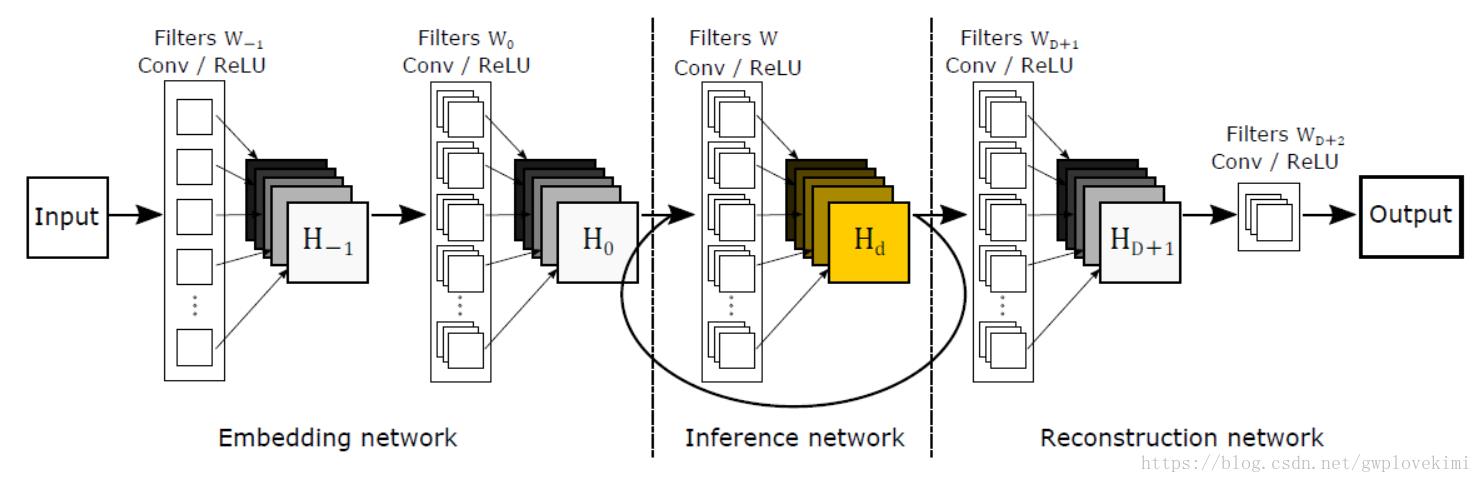
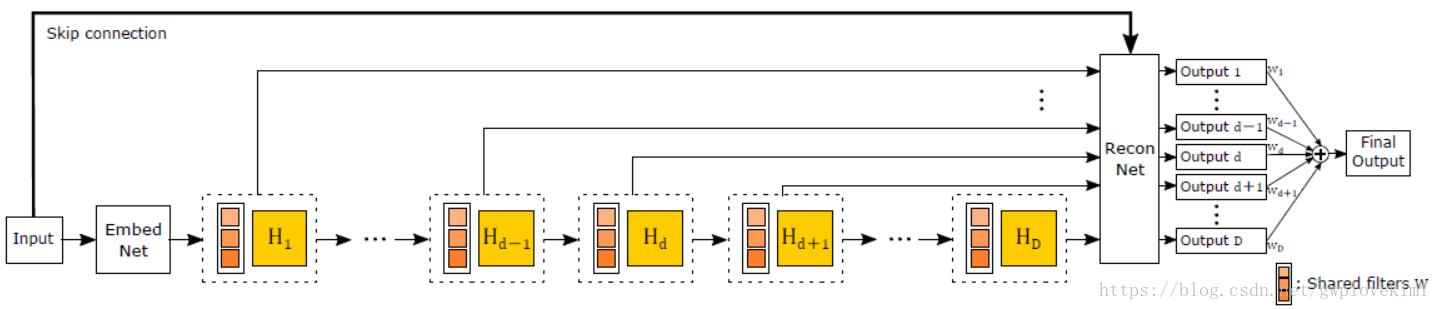
DRCN输入的是插值后的图像,分为三个模块,第一个是Embedding network,相当于特征提取,第二个是Inference network, 相当于特征的非线性映射,第三个是Reconstruction network,即从特征图像恢复最后的重建结果。其中的Inference network是一个递归网络,即数据循环地通过该层多次。将这个循环进行展开,等效于使用同一组参数的多个串联的卷积层,如下图所示。
其中的 以上是关于毕业设计基于深度学习的图像超分辨率重建 - opencv python cnn的主要内容,如果未能解决你的问题,请参考以下文章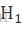 到
到 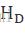 是D个共享参数的卷积层。将这D个卷积层的每一层的结果都通过相同的Reconstruction Net,在Reconstruction Net中与输入的图像相加,得到D个输出重建结果。这些所有的结果在训练时都同时被监督,即所有的递归都被监督,作者称之为递归监
是D个共享参数的卷积层。将这D个卷积层的每一层的结果都通过相同的Reconstruction Net,在Reconstruction Net中与输入的图像相加,得到D个输出重建结果。这些所有的结果在训练时都同时被监督,即所有的递归都被监督,作者称之为递归监