prometheus 实践
Posted xyc1211
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了prometheus 实践相关的知识,希望对你有一定的参考价值。
文章目录
常用场景
增长率
increase( counter类型的范围向量)
计算范围向量中时间序列的增加量
算法:第一个样本 - 最后一个样本
rate( counter类型的范围向量)
计算范围向量中时间序列的每秒平均增长率
算法:(第一个样本 - 最后一个样本)/ 时间(秒)
源数据粗粒度,用rate按秒计算会有很多空值,形成断点、断链
rate比increase适合 源数据细粒度的情况
长尾效应:使用了平均值,很容易把峰值削平。体现不出访问量激增的情况
不够灵敏,适合做分期长期趋势或告警规则
- 使用建议
建议将 rate 计算的范围向量的时间至少设为抓取间隔的四倍。这将确保即使抓取速度缓慢,且发生了一次抓取故障,您也始终可以使用两个样本。此类问题在实践中经常出现,因此保持这种弹性非常重要。例如,对于 1 分钟的抓取间隔,您可以使用 4 分钟的 rate 计算,但是通常将其四舍五入为 5 分钟。
irate(范围向量)
计算范围向量中时间序列每秒的瞬时增长率
算法:取最后两个数据,算差值
最多可向后查询 5分钟:
灵敏,适合短期
预测
predict_linear 增长预测
常见问题
长尾问题
-
平均值显示不出瞬时变化
-
要体现瞬时变化对采样频率有要求
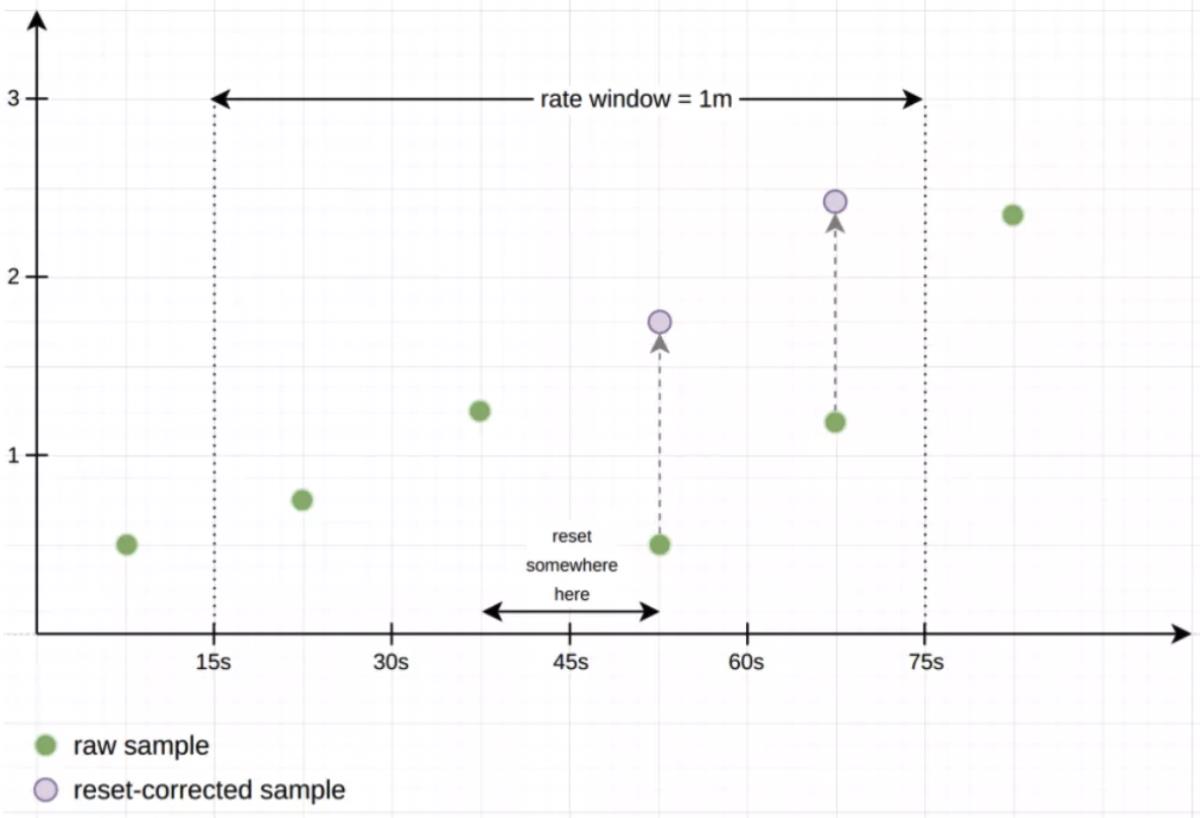
Counter重置(跳变)问题
Counter重置为0 。会这些重置解释成负rate
跳变问题是计算时解决,不是落库时解决:Counter 的数据有下降之后自动处理
- rate 会自动处理 counter 重置的问题,
counter 一般都是一直变大的,例如一个 exporter 启动,然后崩溃了。
本来以每秒大约 10 的速率递增,但仅运行了半个小时,则速率(x_total [1h])将返回大约每秒 5 的结果。
另外,counter 的任何减少也会被视为 counter 重置。例如,如果时间序列的值为[5,10,4,6],则将其视为[5,10,14,16]。
数据外推(拟合)
-
问题:
对于只有整数增量的counter,increase() 也可能返回非整数结果,如2.5883 -
原因:
rate()和increase()函数的推算行为 -
数据外推
时间窗口中的第一个和最后一个样本,永远不会与规定时间窗口的开始和结束100%重合。
因此 increase() 、rate()会在窗口与窗口的界限中外推第一个和最后一个数据点之间的斜率,
得出一个平均而言更接近整个窗口内预期增长的数值(如果在窗口边界确实有样本)。
推测一个虚拟值 拿来计算
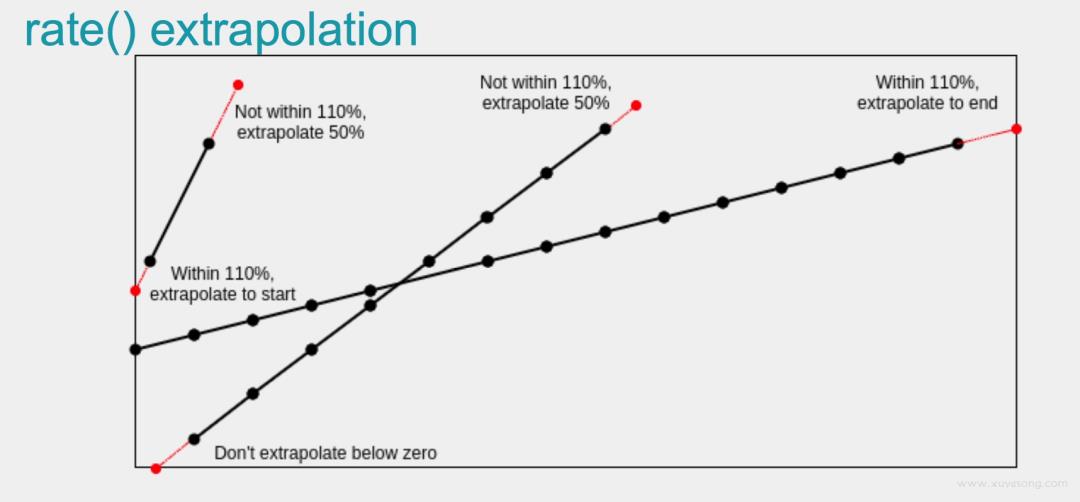
irate()只看两个样本间每秒的增长,所以它不做这种外推。
开源监控系统 Prometheus 最佳实践

作者:jimmiehan(韩金明) , 腾讯PCG后台开发工程师, Prometheus/Thanos contributor
Prometheus 是目前最流行的开源监控系统之一, 这里以我在基于 Prometheus 构建天机阁 2.0Metrics 子系统的实践谈一谈 Prometheus 的一些最佳实践, 最佳实践的理念是 Prometheus 系统简单稳定高效运行的关键。(注: 天机阁 2.0 是新一代云原生可观测性系统)
埋点思路
最好将原始指标暴露给 Prometheus, 而不是在应用程序端进行计算. 如不需要在应用程序端计算错误率, 而应该埋点总量和错误量两个 counter, 查询时用 PromQL 处理原始数据, 相除得到错误率。
在线服务: RED 方法, Requests(请求量), Errors(错误量), Duration(耗时);
离线服务: USE 方法, Utilisation(使用率, 如满载程度), Saturation(饱和度, 如排队任务数), Errors 错误量。
开源项目例子:
内部代码例子:
天机阁 Go SDK tps-sdk-go
Opentelemetry Oteam Go 生态 SDK opentelemetry-go-ecosystem
卡片服务 we-feed-card
指标名字
指标命名的整体结构是 name_unit_suffix , 符合正则[a-zA-Z*][a-zA-Z0-9_]\\*
name:
name 要做到望文生义, 类似变量名, 应具有良好的可读性. 如 http_requests_total, process_resident_memory_bytes, queue_size, queue_limit. 可参考 k8s/etcd/prometheus/grafana/tidb 等开源项目;
指标名称是全局的, 携带命名空间可以有效避免命名冲突. 如 process_xxx 表示进程指标, rpc_xxx 表示 RPC 指标, followsys_xxx 表示关注系统业务指标;
指标名称不要带环境名/应用名, 这些元信息适合用 label 承载, Prometheus 在抓取指标时自动附加, 不需要在埋点代码中定义. 在接入天机阁时会自动给指标附加 app/server/env_name/container_name/namespace 这些元信息;
Prometheus 自定义指标如果要携带中文指标名, 我们约定放在名字为_name 的 label 中。
unit:
指标名可以带上单位, 如 request_bytes_total , request_latency_seconds;
值总是使用基本单位, 如 秒/米/字节, 单位展示可读性的事情则交给 Grafana 等展示 UI 来处理。
suffix:
信息类指标以_info 为后缀, 类型为 gauge,值为 1;
指标名称不要带 _sum _count _bucket 后缀,以免与 histogram/summary 类型生成的指标名混淆。
指标 label
label 对于多维监控非常有用,一个指标的基数是指标中所有 label 枚举值组合的笛卡尔乘积. 一个进程中一个指标一千的基数是合理的上限。一个进程的总基数是所有指标的基数之和, 一个进程一万总基数是合理的上限,因此:
label 中不适合放 用户 ID/设备 ID/URL 参数 等高基数的值. 单个 label 值不超过 128 个字符;
避免一个指标过多的 label 组合, 不必要的组合 label 可以拆解为多个指标, 以便降低指标基数, 提高该指标的查询性能. 参考: https://www.robustperception.io/cardinality-is-ke;
Metrics 更关注系统级别的高效指标而不是单个请求级别, 不要在 Metrics 中放过多的细节 label, 单独 Metrics 无法解决所有的可观测性问题, 详细的信息应记录 Logs 和 Traces 中, 或者在 Exemplar 带上 traceID, 充分利用三大信号 Metrics/Logs/Traces 关联 一起来观测系统
PromQL
对于 counter, 要先 rate 后 sum, 因为rate/irate/increase 函数才有 counter 跳变检测;
聚合语句模式中
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]without 是移除特定标签, by 则是保留某些标签. without 能在聚合移除高基数标签的同时保留更多的上下文信息;向量匹配 on 语句 join info 类型的指标可以达到在查询结果中附加元信息的效果. 例如下面的 promQL 在查询服务内存占用的同时附加实例的 Go 版本。
process_resident_memory_bytes{app="xx", server="xxx",namespace="Production"}
* on(instance) group_left(version)
go_info{app="xx", server="xxx",namespace="Production"}relabel_configs
relabel_configs是很通用很有用的 metrics label processor:
relabel_configs 发生在抓取之前, 可以对目标的每条时间序列附加元数据;
metrics_relabel_configs 发生在抓取之后, 可以对 label 进行重命名/drop 等操作;
alert_relabel_configs 发生在执行规则后发送 alert 至 alertmanager 之前, 如 drop 掉 replica 这个 label 用于 alertmanager 去重;
write_relabel_configs 发生在 remote write 时, 用于 drop 掉 replica label 、drop 某些指标。
查询性能
Prometheus 查询性能与查询语句计算所命中的时间序列数量、样本数以及返回的数据大小 强相关. 正常小查询响应是毫秒级的. 界面展示的大查询(涉及时间序列超过 10k 以上的), 如租户内的所有请求量/server 级别的 CPU 使用列表 这些大查询需要用 recording_rule 定时计算好, 将查询所需的时间序列数降低;
展示单个信息或表格使用 instantQuery 即时查询, 只返回最新时刻计算的数据即可. 展示时间图形才需要使用 rangeQuery 范围查询, 返回时间区间内计算的所有数据。
图表
自定义 Dashboard 需要避免一个面板图形中太多的线条, 5 条以内比较合理, 以免图表看不清及卡顿. 对于容器实例级别的指标可以用 topk 函数限制曲线数量;
对于模板变量下拉, 其语句每次打开 Dashboard之前都会查询 series 接口, 若因为返回结果太大而加载 Dashboard 太慢, 则需要使用 recording_rule 优化;
Grafana 官网面板中心有大量面板可以导入及参考。
recording_rule
对于页面上展示的热查询, 如果涉及时间序列太多, 则会变得缓慢. 一般涉及时间序列大于 10K 的 InstantQuery 和时间序列大于 1K 的 RangeQuery, 是比较昂贵的。
Prometheus 提供了recording_rule功能, 其会定时如 1 分钟对 promQL 表达式定时执行 instantQuery, 执行结果形成新的时间序列, 数据来自内存 TSDB, 完全内存操作, 性能很高。
例子 1 Istio 可观测性最佳实践
命名 维度:指标名:聚合方式 , 如 server:rpc_request_started_total:rate5m. 参见:
https://prometheus.io/docs/practices/rules/#naming-and-aggregation
alert rule
Awesome Prometheus alerts 包含各种 exporter 导出的指标的告警规则例子;
rule 也遵循 label based 机制, 触发告警时, label 集合是 rule 中自定义的静态 label 加上语句查询结果的 label 组合. 在 alertmanager 中根据 label 进行去重、分组、通知路由、静默、抑制;
一些告警语句与流量周期相关, 可以在 alertmanager 的配置 route 级别的周期性屏蔽, 也可以在 rule 表达式中使用 on hour/day/month 函数周期屏蔽, 如以下 rule 会在每天 23 点~9 点总是不触发。
expr: |
xxx < 100
# 增加条件每天23点~9点总是不触发, 转换为UTC则 hour 15点~1点
and on() (hour() <= 15 and hour()>= 1)annotation 中支持 go template 语法, 内置query 函数可以执行额外的查询语句, 这是丰富告警信息的利器, 比如下方配置的语句可以在异常率告警中带上错误码、数量和错误码描述.
annotations:
description: |
{{- with printf "sum(increase(rpc_server_handled_total{tenant_id='%s', app='%s', server='%s',namespace='%s', callee_service='%s', callee_method='%s',code_type='exception'}[1m])) by (code_type, code, code_desc)> 0" $labels.teannt_id $labels.app $labels.server $labels.namespace $labels.callee_service $labels.callee_method | query -}}
{{- range $i,$v := . -}}
错误码:{{ $v.Labels.code }},数量:{{ printf "%.0f" $v.Value -}},描述:{{ $v.Labels.code_desc }}
{{- end -}}
{{- end -}}可以使用promtool 对 alert rule 进行单元测试, 用于验证告警规则有效性及 template 渲染。
存储
Prometheus tsdb的压缩算法基于Facebook Gorilla 论文, 可以将每个样本点 time+value 16 字节压缩至平均 1.3~2 字节, time 采用 delta-of-delta 方式压缩率比较稳定, value 采用 XOR 方式压缩率跟真实数据相关, 可通过自身指标计算得到实际的样本点大小值。
(rate(prometheus_tsdb_compaction_chunk_size_bytes_sum[2h]) / rate(prometheus_tsdb_compaction_chunk_samples_sum[2h]))Thanos
集群中的 Prometheus 需要设置不同的 external-label, 其分片机制依赖 external-label relabel 进行垂直分片. 历史数据基于时间分片;
性能优化: Thanos Query 执行 promQL 时通过 gRPC 双向流方法流式获取样本数据, 如果涉及 Store 节点还需 Range 请求对象存储, 而 Prometheus 直接通过内存或磁盘。由于多次网络调用,Thanos Query 性能会比直接查询 Prometheus 要慢一些, 优化手段主要有:
Query-Frontend 组件对 RangeQuery 按时间分解并行查询和查询缓存;
Store 节点基于 external-label relabel 分片和基于时间范围的分片;
Store 节点开启 index cache, bucket cache;
Compact 节点压缩合并 block 和降采样。
参考:
https://github.com/OpenObservability/OpenMetrics/blob/main/specification/OpenMetrics.md
https://github.com/cncf/tag-observability/blob/main/whitepaper.md
最近热文:

腾讯程序员视频号最新视频
以上是关于prometheus 实践的主要内容,如果未能解决你的问题,请参考以下文章