PE文件格式全解读
Posted 江南无妖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PE文件格式全解读相关的知识,希望对你有一定的参考价值。
PE文件格式
PE文件包括DOS部分、PE文件头和节表和节数据。从DOS头(DOS header)到节区头(Sectionheader)是PE头部分,其下的节区合称PE体。节数据包括代码(.text)、数据(.data)、资源(.rsrc)节,分别保存。

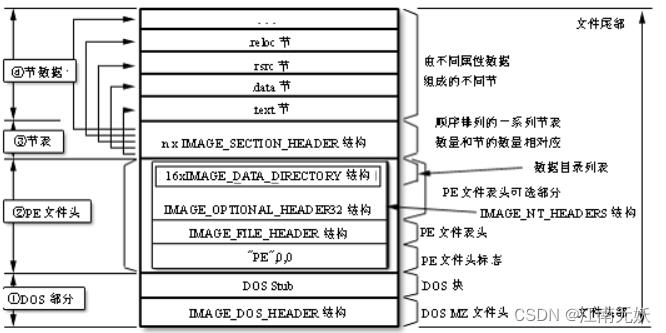
1.DOS部分:
- IMAGE_DOS_HEADER (MZ文件头 0x40)

IMAGE_DOS_HEADER结构体的大小为40字节,需要注意的2个重要成员:
| 0x0-0x01 | e_magic: DOS签名,表文件开始标识 | 0x4d5a=”MZ” |
| 0x3c-0x3f | e_lfanew:PE头部分的偏移 | 0x000000b0. |

- dos stub
DOS存根位于DOS头下方,是个可选项,且大小不固定,即使没有DOS存根,文件也能正常运行,DOS存根由代码与数据混合而成。

2.PE头部分:IMAGE_NT_HEADERS


IMAGE_NT_HEADERS结构体大小为F8,由3个成员组成,第一个成员为签名结构体,其值为50450000h("PE"00),另外两个成员分别为文件头与可选头结构体。
- signature(0x04字节)

| 0x00-0x03 | PE标记,PE\\0\\0 | 50h 45h 00h 00h |
- IMAGE_FILE_HEADER 映像文件头(0x14字节)


| 0x04-0x05 | machine | 0x014c=”x86” |
| 0x06-0x07 | NumberOfSections文件中节的个数 | 0x0003=3 |
| 0x14-0x15 | SizeOfOptionalHeader:可选文件头大小 | 0x000e=14 |
- IMAGE_OPTIONAL_HEADER()

| 0x28-0x2b | AddressOfEntryPoint, RVA值,代码起始地址 | 0x00001000 |
| 0x34-0x37 | ImageBase,文件的优先装入地址,基址。 文件地址:ImageBase+AddressOfEntryPoint=0x401000. | 0x00400000 |
| 0x38-0x3b | SectionAlignment,内存中的对齐粒度 | 0x1000 |
| 0x3c-0x3f | FileAlignment,文件中的对齐粒度 | 0x200 |
| 0x74-0x77 | NumberOfRvaAndSIzes 用来指定数据目录列表data_directory的个数。 | 0x00000010 |
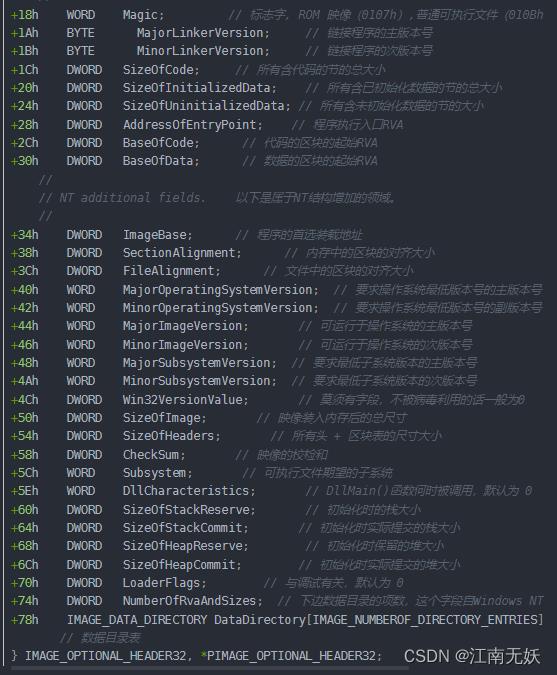
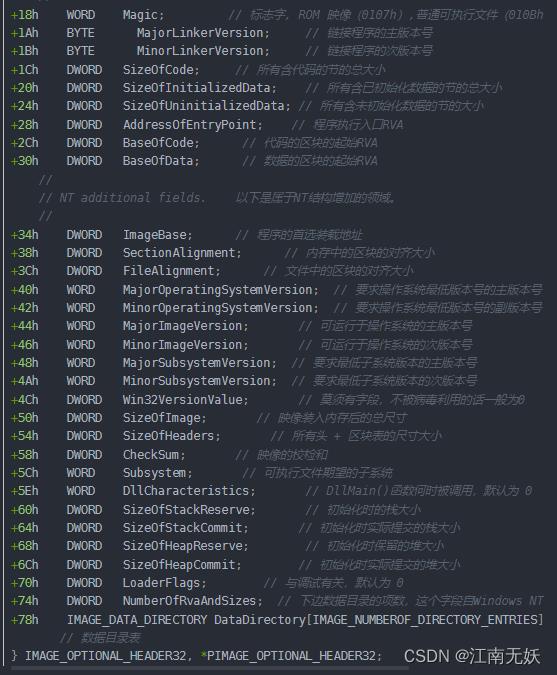
SizeOfImage
加载PE文件到内存时,SizeOfImage指定了PE Image在虚拟内存中所占空间的大小,一般而言,文件的大小与加载到内存的大小是不同的。
SizeofHeader
用来指出整个PE头的大小,该值也必须是FileAlignment的整数倍。
(3)节表IMAGE_SECTION_HEADER
可以看到有三个节表项,text,rdata,data,每个节表项是40字节


| 0x0-0x7 | 节表名称,例如“.text” 或者code | 2e 74 65 78 74 .text 63 6f 64 65 code |
| 0x8-0xB | Virtual size , 内存中大小(内存对齐前的长度),即节区真实大小 因为内存的对齐粒度是0x1000 所以,节区在内存中的大小是0x1000 因为文件的对齐粒度是0x200 所以,节区在文件中的大小是0x200 | 0x00000046 |
| 0x0c-0x0f | VirtualAddress:内存中节区RVA 所以,在内存中的实际地址为: Imagebase+virtualaddress=0x401000 | 0x00001000 |
| 0x10-0x13 | SizeOfRawData:文件中大小(文件对齐后的长度) | 0x00000200 (46<200) |
| 0x14-0x17 | PointerToRawData:文件中节区RVA | 0x00000400 |
| 0x24-0x27 | Characteristics:节区属性 | 0x60000020 |

节的解析请看下一章
2500 字全方面解读 Python 的格式化输出

作者 | 欣一
来源 | Python爱好者集中营
今天小编来和大家聊聊Python当中的格式化输出,希望会对大家所有帮助
%占位符的使用
我们先来看一下下面的这个例子,
country_ = "France"
currency_ = "Euro"
print("%s is the currency of %s" % (currency_, country_))output
Euro is the currency of France当然我们除了%s之外,代表的是字符串,还有%f代表的是浮点数以及%d代表的是整数,我们来看下面的这个例子,
name = '欣一'
age = 24
height = 1.88
print('我是:%s, 年龄:%d, 身高:%fm' % (name,age,height))output
我是:欣一, 年龄:24, 身高:1.880000m我们可以依据保留小数点后面固定的位数,默认的精度为6位,即是小数点后6位,当然我们也可以保留例如2位小数,代码如下
print('我是:%s, 年龄:%d, 身高:%.2fm' % (name,age,height))output
我是:欣一, 年龄:24, 身高:1.88m当然有时候我们指定了字符串的最终长度,但是现有的字符串远远没有那么长,因为我们就需要添加空格的方式来填充,可以填充在左边当然也可以填充在右边,代码如下
## 左填充
display('%10s' % ('欣一'))
## 右填充
display('%-10s' % ('欣一'))output
' 欣一'
'欣一 'f-string格式化
我们将上面的案例稍稍做一个修改,代码如下
country_ = "France"
currency_ = "Euro"
print(f"currency_ is the currency of country_")output
Euro is the currency of France使用f-string格式化的方法好就好在可以直接使用变量名来填充句子当中的内容,当然我们也可以拿它直接来进行数值运算,代码如下
print(f'计算结果是:2*10 + 3*15')output
65或者直接和Python当中的内置函数以及lambda方法联用,代码如下
string_test = 'Python is awesome'
print(f'我想说 string_test.lower()')output
我想说 python is awesome以及
a = 100
b = 10
print(f'计算的结果是:(lambda x,y:x+y)(a,b)')output
计算的结果是:110format关键字
format关键字来格式化输出字符串有多种方式,
不指定位置
我们来看一下下面的这个例子,代码如下
print('我是:, 年龄:, 身高:m'.format (name,age,height))output
我是:欣一, 年龄:24, 身高:1.88m位置默认开始从0计算,然后对应位置填入数据
指定位置
也可以是指定位置的填入数据,代码如下
print('我是:0, 年龄:1, 身高:2m'.format (name,age,height))
print('我是:0, 年龄:1, 身高:1m'.format (name,age,height))
print('我是:0, 年龄:2, 身高:1m'.format (name,age,height))output
我是:欣一, 年龄:24, 身高:1.88m
我是:欣一, 年龄:24, 身高:24m
我是:欣一, 年龄:1.88, 身高:24m关键字配对
我们也可以按照关键字配对的方式来进行内容的填充,代码如下
print('我是:name, 年龄:age, 身高:heightm'.format(name='欣一', age=25, height=1.88))output
我是:欣一, 年龄:25, 身高:1.88m字典参数
当我们数据是以字典的形式来展现的时候,就可以这么来做
dic = 'name':'欣一','age':24,'height':1.88
print('我是:name, 年龄:age, 身高:heightm'.format(**dic))output
我是:欣一, 年龄:24, 身高:1.88m列表参数
同样的,当我们的数据是以列表的形式来展现的时候,就可以这么来做
foods = ['fish', 'beef', 'fruit']
s = 'i like eat and and '.format(*foods)
print(s)output
i like eat fish and beef and fruit或者是有根据位置来进行填充,代码如下
foods = ['fish', 'beef', 'fruit']
s = 'i like eat 2 and 0 and 1'.format(*foods)
print(s)output
i like eat fruit and fish and beef精度
有时候我们碰到需要对小数点后面的数字保留几位小数,代码上可以这么来操作
pi = 3.1415926
print(":.2f".format(pi)) # 保留两位小数
print(":+.3f".format(pi)) # 带符号保留3位小数
print(":.2%".format(pi)) # 百分比保留两位小数output
3.14
+3.142
314.16%千分位分隔符
主要是用于货币数据的格式化输出,例如是将“100000”变化成“100,000”,代码如下
print(':,'.format(100000000))output
100,000,000有时候我们还需要在前面添加上货币符号,代码如下
print('$:,'.format(100000000))output
$100,000,000
往
期
回
顾
技术
资讯
技术
资讯

分享

点收藏

点点赞

点在看
以上是关于PE文件格式全解读的主要内容,如果未能解决你的问题,请参考以下文章