python读取写入txt文本内容
Posted 普通网友
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python读取写入txt文本内容相关的知识,希望对你有一定的参考价值。
一、python 中打开文件,
python中读写txt文件,首先得打开文件,即使用open()函数,
lastpath1 = r'D:apache-jmeter-4.0insrcWaveId.txt'
file1 = open(lastpath,'r'')
可以使用不同的模式打开文件,如:r,r+,w,w+,a,a+,它们的区别如下:
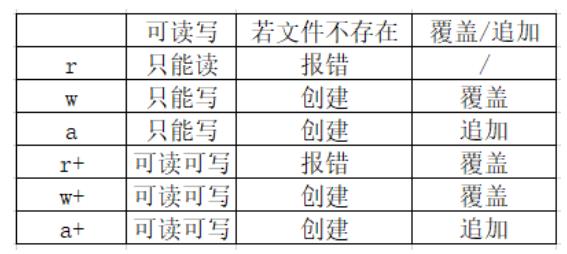
注意:write()会创建文件
二、读取txt文件
python常用的读取文件函数有三种read()、readline()、readlines()*
(1)、read() 一次性读全部内容 一次性读取文本中全部的内容,以字符串的形式返回结果
path1=r'D:Document est.txt'
file1=open(path1,'r')
content1=file1.read()
print(content1)
file1.close() #文件打开,使用完毕后需要关闭
(2)、readline() 读取第一行内容,只读取文本第一行的内容,以字符串的形式返回结果
path2=r'D:Document est.txt'
file2=open(path1,'r')
content2=file2.readline()
print(content2)
file2.close() #文件打开,使用完毕后需要关闭
(3)、readlines()读取文本所有内容,并且以数列的格式返回结果,
path3=r'D:Document est.txt'
file3=open(path3,'r')
content3=file3.readlines()
print(content3)
file3.close() #文件打开,使用完毕后需要关闭
返回结果:
['one
', 'two
', 'three
', 'four
', 'five']
因readlines()会读到换行符,所以一般配合for in使用去除换行符
f = open("test.txt", "r")
for line in f.readlines():
line = line.strip('
') #去掉列表中每一个元素的换行符
print(line)
f.close()
三、txt文件中写入
常用函数:write()
1、文件中写入内容,首先需要打开文件
2.wirte()写入后默认不换行
path2 = r'D:Document est2.txt'
file2 = open(path2,'w+')
file2.write('aaa')
b = 'ccc'
file2.write(b)
四、关闭文件
文件打开最后需要关闭,常用函数为close()
Python逐行读取txt文本,按符合分割词并逐行写入txt
背景Background:
我的txt文件里面存放的是搜索词,由于原始的query(搜索词)都是用/或者、来分割词,而我要达到的是每个词语是单独的一行,并且写入txt
第一步:按行读取txt文件
s = []
f = open(\'querylist.txt\',\'r\') #由于我使用的pycharm已经设置完了路径,因此我直接写了文件名
for lines in f:
# query_list.append(line.replace(\'/\',\'\').replace(\'、\',\'\').replace(\' \',\'\').strip(\'\\n\'))
ls = lines.strip(\'\\n\').replace(\' \',\'\').replace(\'、\',\'/\').replace(\'?\',\'\').split(\'/\')
for i in ls:
s.append(i)
f.close()
print(s)
第二步:逐行写入txt
把我们列表中s的每一个元素写入tet,一个元素为一行,方法有很多,我这里只列举一种
(提前在你的文件路径中建立好一个空的txt:query_result)
f1 = open(\'query_result.txt\',\'w\')
for j in s:
f1.write(j+\'\\n\')
f1.close()
大功告成,最后我输出的结果是:
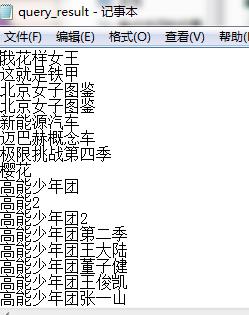
其他:分类汇总的反向操作
完整版:为每一个资源号ID下的query配置对应资源号
我现在有两个变量:资源ID 和对应的检索词,每个ID对应多个检索词,每个ID和对应的检索词成为一行,具体结构如下:
我希望能够实现:1)把每行的多个检索词分开成一个个的单词,每个单词占一行
2)每个检索词前面对应各自的ID
为了做这个,我做了一个实验:
# # d = {\'37186\':\'高能少年团,高能王俊凯\',\'37192\':\'世界杯\'}
# cc = [[\'高能少年团\',\'高能王俊凯\'],[\'shijiebei\',\'世界杯c罗\']]
# nn = [\'37186\',\'37192\']
# for i in range(0,2):
# for j in cc[i]:
# print(j+nn[i])
#step1:读取资源号ID
q_id = []
f2 = open(\'id.txt\',\'r\')
for lines in f2:
q_id.append(lines.strip(\'\\n\'))
f2.close()
# print(q_id)
# print(len(q_id))
#step2:读取检索词(参照上两步)
s = []
f = open(\'querylist.txt\',\'r\') #由于我使用的pycharm已经设置完了路径,因此我直接写了文件名
for lines in f:
# query_list.append(line.replace(\'/\',\'\').replace(\'、\',\'\').replace(\' \',\'\').strip(\'\\n\'))
ls = lines.strip(\'\\n\').replace(\' \',\'\').replace(\'、\',\'/\').replace(\'?\',\'\').split(\'/\')
for q in ls:
if q == \'\':
ls.remove(\'\')
s.append(ls) #这一步和上一步不同,是为了每一行的检索词单独成为一个列表中的小列表,后面才能实现对应到自己的资源号
f.close()
# print(s)
# print(len(s)) #要保证两个列表的长度相等,这里都是51个
if len(s) == len(q_id):
print(\'长度相等\')
#step3:对应ID和检索词,把这个结果写入空的txt:
dy = open(\'duiying.txt\',\'w\')
for i in range(0,52):
for j in s[i]:
print(q_id[i]+j)
dy.write(q_id[i]+j+\'\\n\')
dy.close()
大功告成:结果如图所示:
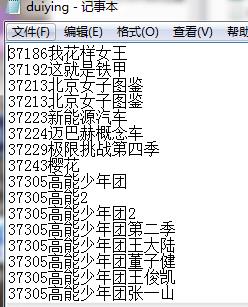
之后copy到excel里,使用分割功能分割一下就好啦~~~~~~开熏
以上是关于python读取写入txt文本内容的主要内容,如果未能解决你的问题,请参考以下文章