selenium+python爬虫全流程教程
Posted 苏格拉没有鞋底
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了selenium+python爬虫全流程教程相关的知识,希望对你有一定的参考价值。
python+selenium爬虫全流程详解
selenium+python爬虫简介
该教程许多内容基于个人经验,部分内容有些口语化
如有错误的地方麻烦及时指正(可评论或者私信)
selenium测试脚本
selenium实际上是web自动化测试工具,能够通过代码完全模拟人使用浏览器自动访问目标站点并操作来进行web测试。
python+selenium
通过python+selenium结合来实现爬虫十分巧妙。
由于是模拟人的点击来操作,所以实际上被反爬的概率将大大降低。
selenium能够执行页面上的js,对于js渲染的数据和模拟登陆处理起来非常容易。
该技术也可以和其它技术结合如正则表达式,bs4,request,ip池等。
当然由于在获取页面的过程中会发送很多请求,所以效率较低,爬取速度会相对慢,建议用于小规模数据爬取。
selenium安装,直接通过pip安装即可
pip3 install selenium
导入包
from selenium import webdriver
模拟浏览器----以chrome为例
浏览器驱动安装
链接: https://registry.npmmirror.com/binary.html?path=chromedriver/
我们只需要在上面链接内下载对应版本的驱动器,并放到python安装路径的scripts目录中即可。
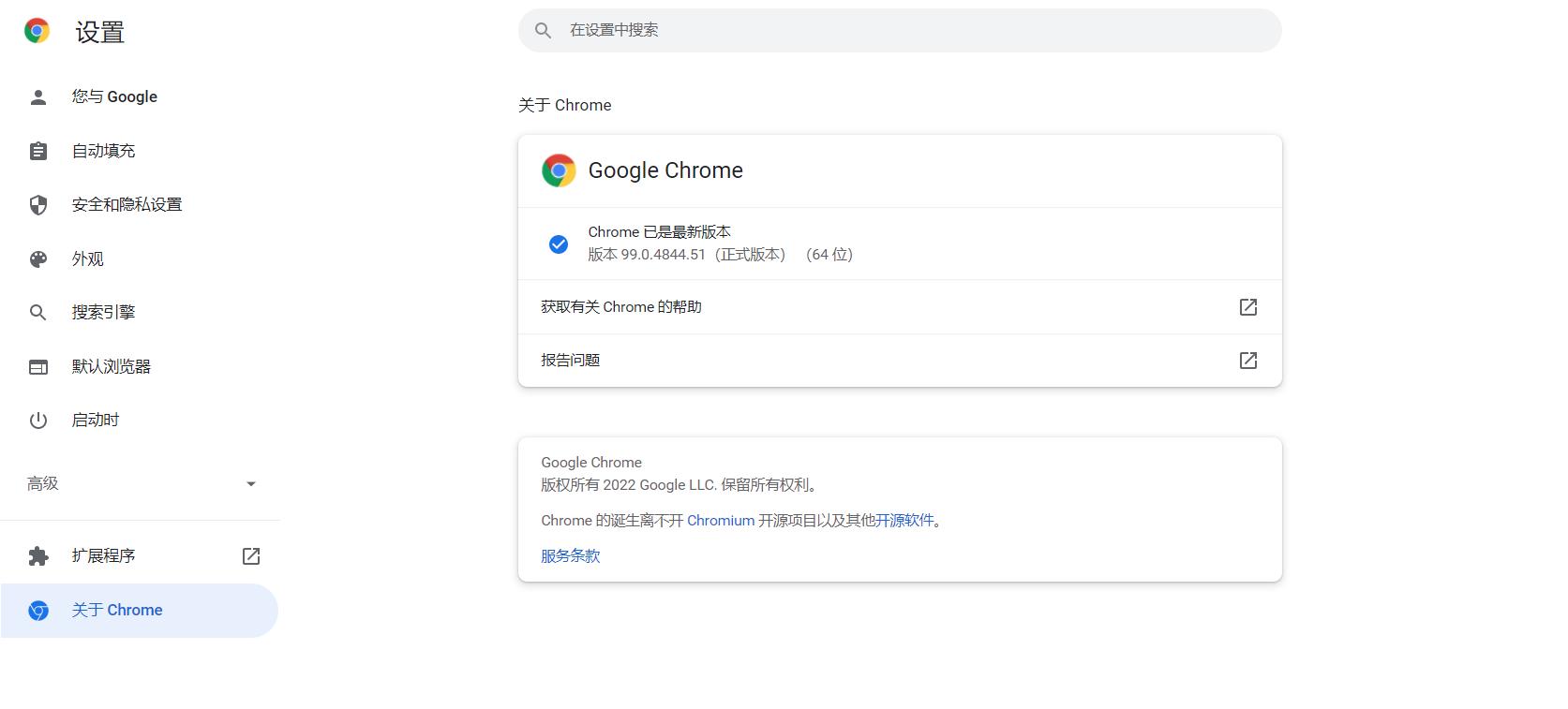
浏览器版本可在设置–关于Chrome中看到
 当然由于浏览器时常会自动更新,我们也记得使用前要更新相对应的驱动
当然由于浏览器时常会自动更新,我们也记得使用前要更新相对应的驱动
浏览器模拟基本操作
browser = webdriver.Chrome() # 打开浏览器
driver.maximize_window() # 最大化窗口
browser.minimize_window() # 最小化窗口
url='https://www.bilibili.com/v/popular/rank/all'#以该链接为例
browser.get(url)#访问相对应链接
browser.close#关闭浏览器
爬取数据–web定位
以下知识需要一些web相关知识为前提
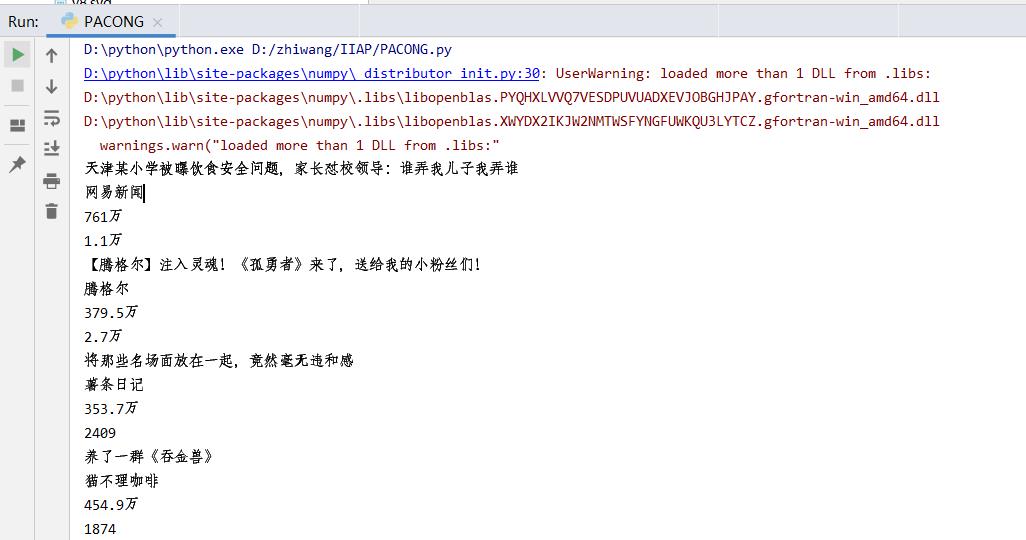
案例–b站排行榜
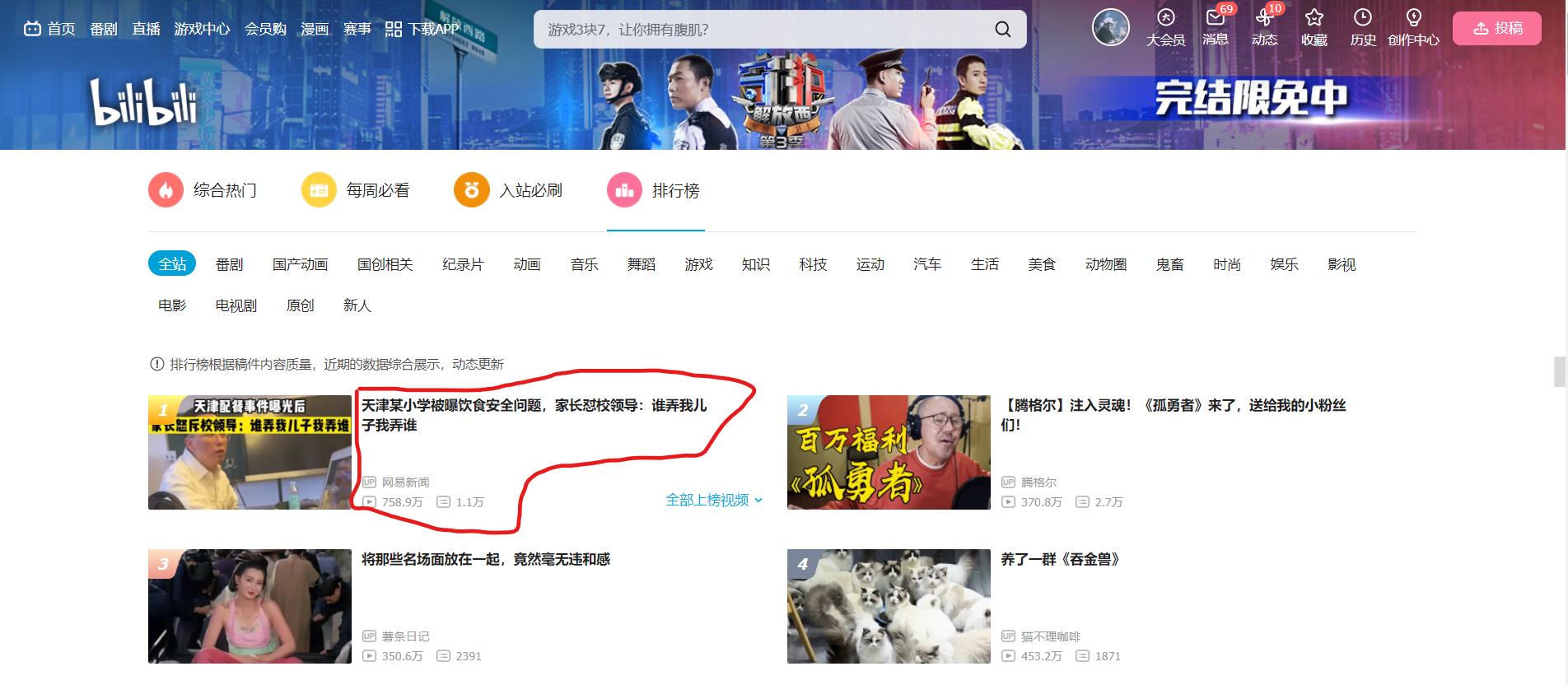
假设我们需要爬取上图红圈中的文本数据,那么我们需要定位到该地方的点位
定位方法以及实操
定位方法的选择主要根据目标网页的情况来定
#find_elements_by_xxx的形式是查找到多个元素(当前定位方法定位元素不唯一)
#结果为列表
browser.find_element_by_id('')# 通过标签id属性进行定位
browser.find_element_by_name("")# 通过标签name属性进行定位
browser.find_elements_by_class_name("")# 通过class名称进行定位
browser.find_element_by_tag_name("")# 通过标签名称进行定位
browser.find_element_by_css_selector('')# 通过CSS查找方式进行定位
browser.find_element_by_xpath('')# 通过xpath方式定位
#在chrome中可以通过源代码目标元素右键--Copy--Copy XPath/Copy full XPath
browser.find_element_by_link_text("")# 通过搜索 页面中 链接进行定位
browser.find_element_by_partial_link_text("")# 通过搜索 页面中 链接进行定位 ,可以支持模糊匹配
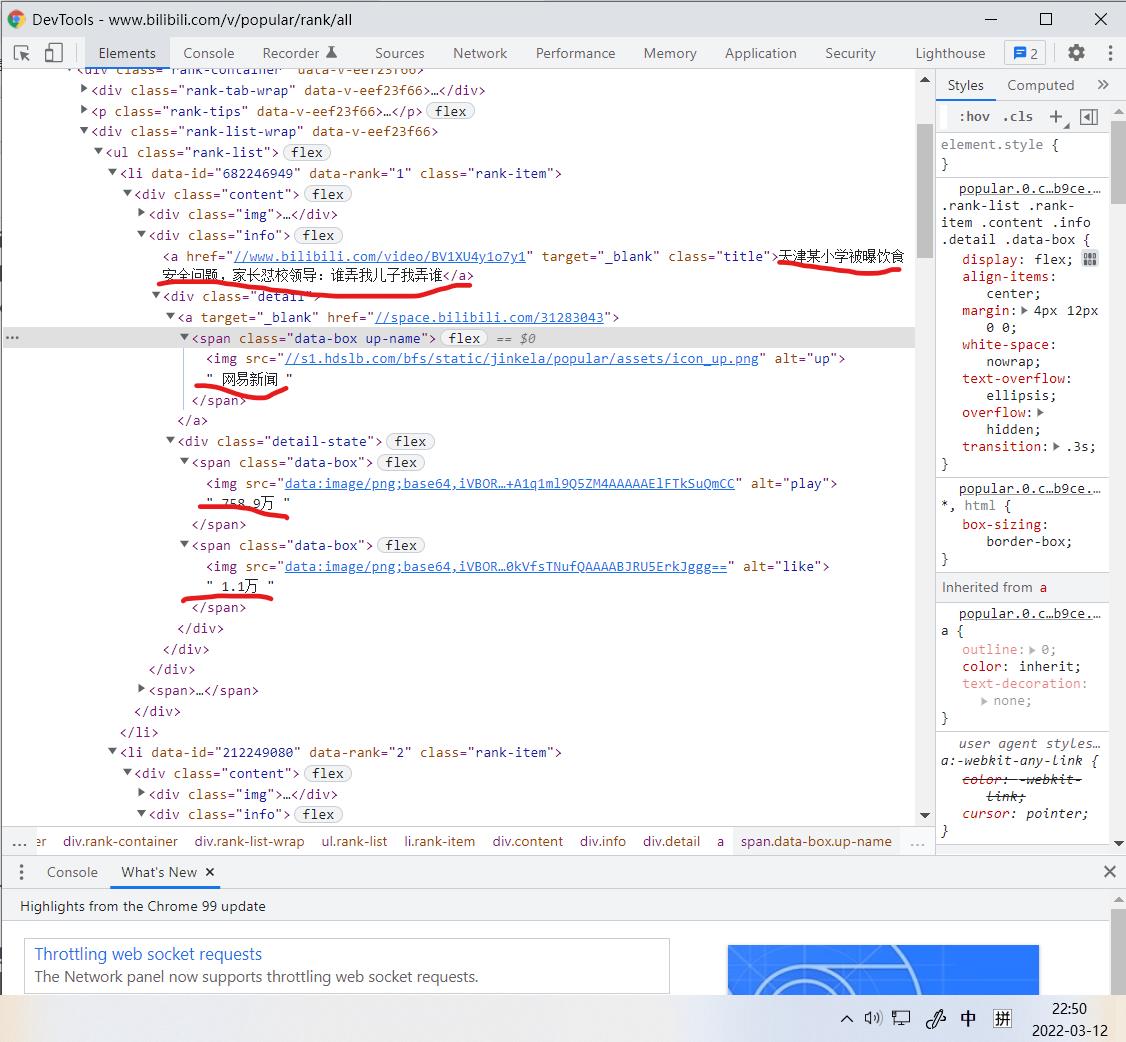
在案例网站中我们根据class名称来爬取,标签内class=“info”
from selenium import webdriver
browser = webdriver.Chrome()
# browser.minimize_window() # 最小化窗口
url='https://www.bilibili.com/v/popular/rank/all'
browser.get(url)
info=browser.find_elements_by_class_name('info')
#在目标网站中网站中标题class名称都为"info",所以用elements
for i in info:
print(i.text)
#.text为定位元素底下的所有文本,当然我们也可以获取标签里的东西(用其它函数),如视频链接:
# print(i.find_elements_by_tag_name('a')[0].get_attribute('href'))
结果
部分可能会用到的方法(辅助爬虫/降低反爬)
加快网页加载速度(不加载js,images等)
options = webdriver.ChromeOptions()
prefs =
'profile.default_content_setting_values':
'images': 2,
'permissions.default.stylesheet':2,
'javascript': 2
options.add_experimental_option('prefs', prefs)
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=options)
异常捕捉
from selenium.common.exceptions import NoSuchElementException
网页等待加载
由于网速的问题等,进入该网址后页面还没加载出来需要等待
selenium自带的加载方式
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载
wait=WebDriverWait(browser,10) #显式等待:指定等待某个标签加载完毕
wait1=browser.implicitly_wait(10) #隐式等待:等待所有标签加载完毕
wait.until(EC.presence_of_element_located((By.CLASS_NAME,'tH0')))
用time等待时间
import time
time.sleep(2)
在输入框中输入数据
ele = driver.find_element_by_id("kw") # 找到id为kw的节点
ele.send_keys("名称") # 向input输入框输入名称
#也可以driver.find_element_by_id("kw").send_keys("名称")
网页点击(如点击下一页,或者点击搜索)
ele = driver.find_element_by_id("kw") # 找到id为kw的节点
ele.send_keys("数学") # 向input输入框输入数据
ele = driver.find_element_by_id('su') # 找到id为su的节点(百度一下)
ele.click() # 模拟点击
打印网页信息
print(driver.page_source) # 打印网页的源码
print(driver.get_cookies()) # 打印出网页的cookie
print(driver.current_url) # 打印出当前网页的url
切换iframe
有时候会碰到网页用iframe来作为文档框架
driver.switch_to.frame("iframe的id")
网页滚动(更像真人)
# 1.滚动到网页底部
js = "document.documentElement.scrollTop=800"
# 执行js
driver.execute_script(js)
# 滚动到顶部
js = "document.documentElement.scrollTop=0"
driver.execute_script(js) # 执行js
随机等待几秒再操作(更像真人)
import time
import random
time.sleep(random.randint(0,2))
讲在最后
python+selenium爬虫技术仍还有很多可以写,该教程仅仅涉及一大部分,大家应该根据实际需求进行调整,进行搜索。
多进行实践,多百度,总结面对不同网页情况或者不同反爬情况的经验,这样我们才能不断成长。
实践是检验真理的唯一标准。
多谢各位阅读,也希望各位能有所收获。
以上是关于selenium+python爬虫全流程教程的主要内容,如果未能解决你的问题,请参考以下文章