accuracy_score函数
Posted 千梦千微雨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了accuracy_score函数相关的知识,希望对你有一定的参考价值。
1.acc计算原理
sklearn中accuracy_score函数计算了准确率。
在二分类或者多分类中,预测得到的label,跟真实label比较,计算准确率。
在multilabel(多标签问题)分类中,该函数会返回子集的准确率。如果对于一个样本来说,必须严格匹配真实数据集中的label,整个集合的预测标签返回1.0;否则返回0.0.
2.acc的不适用场景:
在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc,即使全部预测成负类(不点击)acc也有 99% 以上,没有意义。因此,单纯靠准确率来评价一个算法模型是远远不够科学全面的。在类别不平衡没那么太严重时,该指标具有一定的参考意义。
3.metrics.accuracy_score()的使用方法
不管是二分类还是多分类,还是多标签问题,计算公式都为:
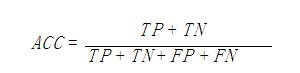
只是在多标签问题中,TP、TN要求更加严格,必须严格匹配真实数据集中的label。
sklearn.metrics.accuracy_score(y_true, y_pred, *, normalize=True, sample_weight=None)
输入参数:
y_true:真是标签。二分类和多分类情况下是一列,多标签情况下是标签的索引。
y_pred:预测标签。二分类和多分类情况下是一列,多标签情况下是标签的索引。
normalize:bool, optional (default=True),如果是false,正确分类的样本的数目(int);如果为true,返回正确分类的样本的比例,必须严格匹配真实数据集中的label,才为1,否则为0。
sample_weight:array-like of shape (n_samples,), default=None。Sample weights.
输出:
如果normalize == True,返回正确分类的样本的比例,否则返回正确分类的样本的数目(int)。
以上是关于accuracy_score函数的主要内容,如果未能解决你的问题,请参考以下文章