Web挖掘
Posted 懵懂的菜鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Web挖掘相关的知识,希望对你有一定的参考价值。
Web挖掘
Web挖掘的目标是从Web的超链接、网页内容和使用日志中探寻有用的信息。依据Web挖掘任务,可以划分为三种主要类型:Web结构挖掘、Web内容挖掘和Web使用挖掘。Web结构挖掘简单的说就是从表征Web结构的超链接中找寻有用的知识。例如:从这些链接中可以找到重要的网页,也可以发掘具有共同兴趣的用户社区。Web内容挖掘从网页中抽取有用的信息知识库。例如:根据网页的主题,可以自动进行聚类和分类,例如可以抽取网页中的商品描述、论坛回帖等,这些信息可以作为进一步分析来挖掘用户的态度。Web使用挖掘从记录每位用户点击情况的使用日志中挖掘用户的访问模式。例如点击流数据的预处理,以便用来挖掘合适的信息。
Web数据挖掘与数据挖掘十分相似,区别通常只是数据收集。对于Web而言,数据收集是一项十分重要的任务,尤其是在Web结构挖掘和内容挖掘的时候,需要爬取大量的网页。一旦数据收集完毕,既可以进行通常数据处理的三项工作,数据预处理、Web数据挖掘和数据后处理。
基于一些Web数据挖掘的准备,需要具备关联规则和序列模式、监督学习、无监督学习和部分监督学习的知识。
1 信息检索和Web搜索
信息检索(Information Retrieval,IR)是搜索的根基,其目的是帮助用户从大规模的文本文档中找到所需信息的研究领域。在用户给出一个能够描述信息需求的查询后,信息检索系统就会从这些文档中找出和该请求相关的文档集,这也正是搜索引擎的工作原理。IR系统的基本架构如图1-1所示。
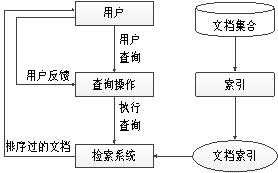
图1-1 IR系统的基本架构
在图1-1中,用户通过查询操作模块发送一个查询到检索系统。检索模块使用文档索引找到包含这些查询词的文档,并且计算这些文档的相关度分数,然后根据分数给这些文档排序。进过排序的文档返回给用户。同时,文档数据集为了有效的检索已经建立了索引。
用户查询的形式分为:关键词查询、布尔查询、短语查询、临近查询、全文搜索、自然语言查询。
查询操作需要对查询问题做预处理之后再将查询发送给检索系统,例如需要把自然语言问题转化成可执行的查询问题。索引器模块是为了更有效的查询而建立的。在搜索引擎以及大多数的IR系统中会使用到倒排索引。这种索引简单而且有效。检索系统会为每个索引文件计算与查询的相关度分数。文档会根据它们的相关度分数排序来进行反馈。
1.1 信息检索模型
信息检索模型将决定文档和查询的表示以及文档与用户查询相关度的定义。
信息检索模型通常分为三类:基于内容的信息检索模型,结构化模型和浏览型数学模型。其中
(1)基于内容的信息检索模型有:
集合论模型:布尔模型、模糊集合模型、扩展布尔模型
代数模型:向量空间模型、广义向量空间模型、潜在的语义标引模型、神经网络模型
概率模型:经典点概率论模型、推理网络模型、置信网络模型
(2)结构化模型:非重叠链表模型、临近节点模型
(3)浏览型数学模型:平面、结构导航、超文本
常用的信息检索模型包括布尔模型,向量模型和概率模型。这三种模型在表示文档和查询上有所不同,但是他们都是使用相同的框架。IR模型可以表示为一个四元组
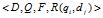
其中D是一个文档集合,Q是一个查询集合,F是一个对文档和查询建模的框架, 是一个排序函数。
是一个排序函数。
- 文档集合
设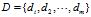 ,为了满足检索匹配所要求的快速与便利,文档
,为了满足检索匹配所要求的快速与便利,文档 通常由从文档中抽取的能够表达内容的特征项(如索引项/检索项/关键词)来表示。设
通常由从文档中抽取的能够表达内容的特征项(如索引项/检索项/关键词)来表示。设 为系统索引项集合,则
为系统索引项集合,则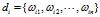 ,
,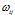 表示索引词
表示索引词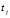 在文档
在文档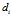 中的重要性(即权重)。
中的重要性(即权重)。
- 查询集合
用户查询集合是指用户需求的各种状态,包括潜在的真实需求,意识到或感知到的需求,表达出的需求和用户查询。用户查询一般采用与文档类似的形式化表示。– q= (Wq1 , Wq2 , …,Wqn )
ps:
– wij→文档dj中的关键词j的权重,
– wqj→查询式q中的关键词j的权重
- 文档与查询建模的框架
用以构建文档、查询以及它们之间关系的模型。
- 排序函数
它给查询 和文档
和文档 之间的相关度赋予一个排序值。
之间的相关度赋予一个排序值。
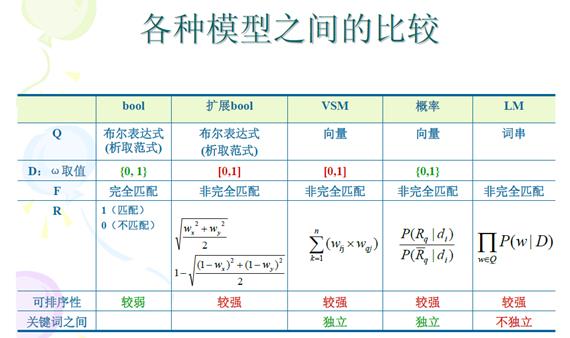
1.2 布尔模型
布尔模型(Boolean Model)目前仍然应用于商业模型中,典型系统为:Lucene。为了方便计算文档d和查询q之间的相关度,布尔模型一般将查询q的布尔表达式转换成析取范式(DNF)。
布尔模型简单而容易理解,但是由于二值判断的标准,无法体现文档之间的细微差别。
1.3 向量空间模型
向量空间模型(Vector Space Model,VSM)是信息检索技术研究的基础。代表系统为SMART(System for the Manipulation and Retrieval of Text)。向量空间模型以相似度为基础,常用的相似度计算方法包括内积、余弦向量度量法、Jaccard系数法。



向量空间反映出了不同关键词在文档中的重要性;可以根据结果文档对于查询串的相关度通过Cosine Ranking等公式对结果文档进行排序;可以控制输出结果的数量。但是向量空间模型认为关键词之间是相互独立的,这一假设不符合自然语言的实际情况。
1.4 概率模型
 概率模型亦称为二值独立检索模型。给定一个用户查询,存在一个文档集合,该集合只包含与查询完全相关的文档而不包含与他不相关的文档,称该集合为理想结果集合。该集合具有怎样的属性,基于相关反馈的原理,需要一个逐步求精的过程。将信息获取看做一个过程,用户提交一个查询,系统提供给用户它所认为的相关结果列表;用户考察这个集合后给出一些辅助信息,系统再进一步根据辅助信息得到一个新的相关结果列表,以此继续。如果每次结果列表中的元素总是按照和查询相关的概率递减排序的话,则系统效果最好。概率模型一贝叶斯定理为基础。
概率模型亦称为二值独立检索模型。给定一个用户查询,存在一个文档集合,该集合只包含与查询完全相关的文档而不包含与他不相关的文档,称该集合为理想结果集合。该集合具有怎样的属性,基于相关反馈的原理,需要一个逐步求精的过程。将信息获取看做一个过程,用户提交一个查询,系统提供给用户它所认为的相关结果列表;用户考察这个集合后给出一些辅助信息,系统再进一步根据辅助信息得到一个新的相关结果列表,以此继续。如果每次结果列表中的元素总是按照和查询相关的概率递减排序的话,则系统效果最好。概率模型一贝叶斯定理为基础。
概率模型有严格的数学理论基础,以相关反馈原理为基础,但是开始时需要把文档分为相关和不相关两个集合,一般来说比较难;同时这种模型没有考虑到关键词在文档中的概率。
参考文献:
[1] https://wenku.baidu.com/view/d7cc11c7aa00b52acfc7ca01.html
[2] https://wenku.baidu.com/view/8b7075dbad51f01dc281f11c.html
以上是关于Web挖掘的主要内容,如果未能解决你的问题,请参考以下文章