逻辑回归 算法推导与基于Python的实现详解
Posted 专注算法的马里奥学长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了逻辑回归 算法推导与基于Python的实现详解相关的知识,希望对你有一定的参考价值。
文章目录
1 逻辑回归概述
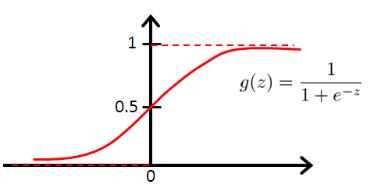
逻辑回归(Logistic Regression)是一种用于分类问题的统计学习方法。它基于线性回归的原理,通过将线性函数的输出值映射到[0,1]区间上的概率值,从而进行分类。
逻辑回归的输入是一组特征变量,它通过计算每个特征与对应系数的乘积,加上截距项得到线性函数,然后将该函数的输出值经过sigmoid函数的映射,得到概率值。
逻辑回归常用于二分类问题,即将样本分为两类,如判断一封邮件是否为垃圾邮件。逻辑回归还可以扩展到多分类问题,如将样本分为三类或更多类别。
逻辑回归具有简单、高效、易于理解等优点,在实际应用中被广泛使用,如金融风控、医学诊断、推荐系统等领域。
2 逻辑回归公式推导与求解
2.1 公式推导
P
(
y
=
1
∣
x
)
=
1
1
+
e
−
(
β
0
+
β
1
x
1
+
β
2
x
2
+
.
.
.
+
β
p
x
p
)
P(y=1|x) = \\frac11+e^-(\\beta_0+\\beta_1x_1+\\beta_2x_2+...+\\beta_px_p)
P(y=1∣x)=1+e−(β0+β1x1+β2x2+...+βpxp)1
逻辑回归的公式大家可能很熟悉,但并不知道推导过程,事实上这一推导过程也十分简单。
给定输入特征 x \\mathbfx x,逻辑回归模型的输出 y y y 可以表示为:
y = P ( y = 1 ∣ x ) = σ ( w T x ) y = P(y=1|\\mathbfx) = \\sigma(\\mathbfw^T \\mathbfx) y=P(y=1∣x)=σ(wTx)
其中, σ ( z ) \\sigma(z) σ(z) 表示 sigmoid 函数,定义为: σ ( z ) = 1 / ( 1 + e − z ) \\sigma(z) = 1 / (1 + e^-z) σ(z)=1/(1+e−z)。这一函数在之后的深度学习中也会经常用到。
至于什么使用sigmoid函数,原因也很简单,很多教材都把这个重要的思考环节忽略了,博主在此进行补充。
我们希望找到一个函数的值域在[0,1]的函数,但是这种函数并不容易找到,线性回归使用的公式 y = θ x y=\\theta x y=θx的值域是(-∞,+∞)。因此,我们引入了odds(几率)的概念。 o d d s = P 1 − P odds=\\fracP1-P odds=1−PPodds的取值为(0,+∞),而对于log函数,其定义域刚好为(0,+∞),值域为(-∞,+∞)。因此,我们便可以构造一个函数 log ( P 1 − P ) = θ x \\log(\\fracP1-P)=\\theta x log(1−PP)=θx对P进行求解,即得到了逻辑回归的基本形式 P = 1 1 + e − x P=\\frac11+e^-x P=1+e−x1也就是我们所常说的sigmoid函数。
2.2公式求解
为了方便推导,我们假设训练数据集包含 m m m 个样本,每个样本有 n n n 个特征,即 X ∈ R m × n \\mathbfX \\in \\mathbbR^m\\times n X∈Rm×n,标签为 y ∈ 0 , 1 m y \\in \\0, 1\\^m y∈0,1m。为了构建模型,我们需要使用训练数据集求解模型参数 w \\mathbfw w。
我们使用最大似然估计来求解模型参数。最大似然估计的目标是找到一组模型参数 w \\mathbfw w,使得训练数据集出现的概率最大。设训练数据集中的第 i i i 个样本的输入特征为 x i \\mathbfx_i xi,输出为 y i y_i yi,其概率表示为:
P ( y i ∣ x i ; w ) = σ ( w T x i ) y i ( 1 − σ ( w T x i ) ) 1 − y i P(y_i|\\mathbfx_i; \\mathbfw) = \\sigma(\\mathbfw^T \\mathbfx_i)^y_i (1 - \\sigma(\\mathbfw^T \\mathbfx_i))^1-y_i P(yi∣xi;w)=σ(wTxi)yi(1−σ(wTxi))1−yi
训练数据集的概率可以表示为:
P ( y ∣ X ; w ) = ∏ i P ( y i ∣ x i ; w ) = ∏ i σ ( w T x i ) y i ( 1 − σ ( w T x i ) ) 1 − y i P(y|\\mathbfX; \\mathbfw) = \\prod_i P(y_i|\\mathbfx_i; \\mathbfw) = \\prod_i \\sigma(\\mathbfw^T \\mathbfx_i)^y_i (1 - \\sigma(\\mathbfw^T \\mathbfx_i))^1-y_i P(y∣X;w)=i∏P(yi∣xi;w)=i∏σ(wTxi)yi(1−σ(wTxi))1−yi
对数似然函数为:
L ( w ) = log P ( y ∣ X ; w ) = ∑ i [ y i log ( σ ( w T x i ) ) + ( 1 − y i ) log ( 1 − σ ( w T x i ) ) ] L(\\mathbfw) = \\log P(y|\\mathbfX; \\mathbfw) = \\sum_i [y_i \\log(\\sigma(\\mathbfw^T \\mathbfx_i)) + (1-y_i) \\log(1 - \\sigma(\\mathbfw^T \\mathbfx_i))] L(w)=logP(y∣X;w)=i∑[yilog(σ(wTxi))+(1−yi)log(1−σ(wTxi))]
我们的目标是最大化对数似然函数 L ( w ) L(\\mathbfw) L(w)。使用梯度上升算法来求解最优参数 w \\mathbfw w。对 L ( w ) L(\\mathbfw) L(w) 求导,得到: ∂ L ( w ) ∂ w = ∑ i ( σ ( w T x i ) − y i ) x i \\frac\\partial L(\\mathbfw)\\partial \\mathbfw = \\sum_i(\\sigma(\\mathbfw^T \\mathbfx_i) - y_i)\\mathbfx_i ∂w∂L(w)=