Python爬虫怎么抓取html网页的代码块
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫怎么抓取html网页的代码块相关的知识,希望对你有一定的参考价值。
比如在这段代码中,我想抓取table align="center" border=7 class="base_index">到<td width="25%" class="head_td top_bottom"><a href="MinGe/Index.htm">民歌民乐</a></td>的内容,先不考虑编码的问题,为什么我用body = re.findall('<table align="center" border=7 class="base_index">(.*?)<td width="25%" class="head_td top_bottom"><a href="MinGe/Index.htm">',code,re.S)抓取之后输出的是一个list元组呢?

import re
def gethtml(url):
page = urllib.request.urlopen(url)
html = page.read()
html = html.decode('GBK')
return html
def getMeg(html):
reg = re.compile(r'******')
meglist = re.findall(reg,html)
for meg in meglist:
with open('out.txt',mode='a',encoding='utf-8') as file:
file.write('%s\n' % meg)
if __name__ == "__main__":
html = getHtml(url)
getMeg(html) 参考技术A
范围匹配大点,像这种
re.findall('(<div class="moco-course-wrap".*?</div>)',source,re.S)
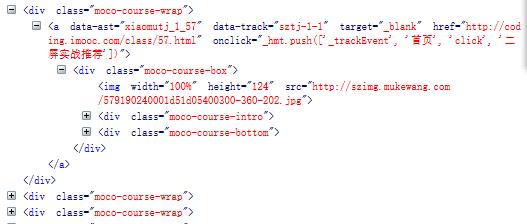
可以看下这个
http://blog.csdn.net/tangdou5682/article/details/52596863
以上是关于Python爬虫怎么抓取html网页的代码块的主要内容,如果未能解决你的问题,请参考以下文章