Python数据分析分组聚合重采样典型例题及其解法
Posted uestc_Venn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据分析分组聚合重采样典型例题及其解法相关的知识,希望对你有一定的参考价值。
快速浏览
文件下载链接(csv)
题目
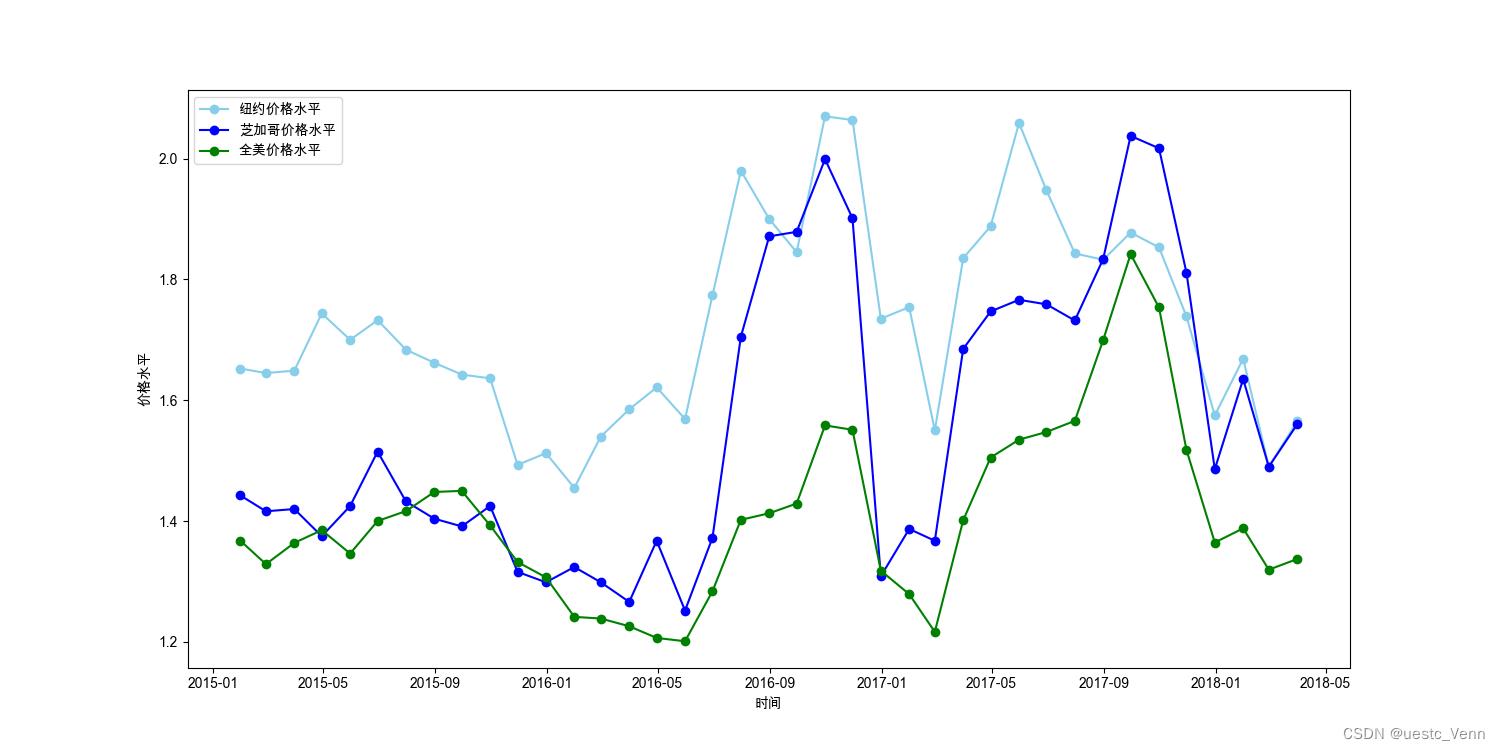
Date表示价格调查的日期,AveragePrice表示当天的平均价格,region表示调查的城市。
彬彬想要获取2015-2018中纽约(“NewYork”)与芝加哥(“Chicago”)每月牛油果平均价格,并计算全美国的每月牛油果平均价格,画出3条折线图进行比较。
具体步骤如下:
- 导入模块、读取文件、并将字体设置为"Arial Unicode MS"
- 根据城市(“region”),将原数据分组、采样聚合,获取纽约和芝加哥两个城市每个月的牛油果平均价格
- 在这之后,以月份为x轴,绘制展示纽约牛油果每月均价的折线图,并将折线颜色设置为skyblue,标记点的样式设置为"o",图例设置为"纽约价格水平"
- 同时,以月份为x轴,绘制展示芝加哥牛油果每月均价的折线图,并将折线颜色设置为blue,标记点的样式为"o",图例设置为"芝加哥价格水平"
- 利用所学知识,计算全美国每个月的牛油果均价,并制作对应的折线图,将折线颜色设置为green,标记点的样式为"o",图例设置为"全美价格水平"
- 最后,将x轴标题为"时间",y轴标题设置为"价格水平",图例显示在左上角
本人代码
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv("/Users/binbin/avocado.csv" )
#设置字体
plt.rcParams["font.sans-serif"] = "Arial Unicode MS"
#将Date转换为时间数据
data["Date"] = pd.to_datetime(data["Date"])
data = data.set_index("Date")
#根据region和时间分组
groupByRegion = data.groupby(data["region"]).resample("M").mean()
#获取纽约和芝加哥两个城市每个月的牛油果平均价格
averagePriceNY = groupByRegion.loc["NewYork"]["AveragePrice"]
averagePriceCH = groupByRegion.loc["Chicago"]["AveragePrice"]
#计算全美国每月的牛油果均价
averagePriceUSA = data.resample("M").mean()
#以月份为x轴,绘制展示纽约牛油果每月均价的折线图,并将折线颜色设置为skyblue,marker设置为"o",图例设置为"纽约价格水平"
#NewYork
plt.plot(averagePriceNY.index, averagePriceNY, color="skyblue", marker="o", label="纽约价格水平")
plt.legend(loc="upper left")
plt.xlabel("时间")
plt.ylabel("价格水平")
#Chicago
plt.plot(averagePriceCH.index, averagePriceCH, color="blue", marker="o", label="芝加哥价格水平")
plt.legend(loc="upper left")
plt.xlabel("时间")
plt.ylabel("价格水平")
#America
plt.plot(averagePriceUSA.index, averagePriceUSA, color="green", marker="o", label="全美价格水平")
plt.legend(loc = "upper left")
plt.xlabel("时间")
plt.ylabel("价格水平")
plt.show()
方法解释
plt.rcParams["font.sans-serif"] = "Arial Unicode MS": 将字体设置为Arial Unicode MSpd. to_datetime: 将str类型数据转换为datetime类型数据data.set_index(): 将data中的某一列作为data新的行索引(index)groupByRegion = data.groupby(data["region"]).resample("M").mean():将data按照"region"分组,并以每月为单位重采样来计算每月的平均价格averagePriceNY = groupByRegion.loc["NewYork"]["AveragePrice"]
averagePriceCH = groupByRegion.loc["Chicago"]["AveragePrice"]:将groupByRegion中行索引对应"NewYok"和"Chicago"的行分别截取出来,并根据列索引(columns)为"AveragePrice"来截取数据赋值
运行结果
以上是关于Python数据分析分组聚合重采样典型例题及其解法的主要内容,如果未能解决你的问题,请参考以下文章