基于YOLOv5的输电线路绝缘子缺陷检测项目
Posted share_data
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于YOLOv5的输电线路绝缘子缺陷检测项目相关的知识,希望对你有一定的参考价值。
目录
1 项目背景
随着输电网络规模不断增大,输电线路巡检任务日益加重,实现输电 线路的高效率巡检已刻不容缓。传统的巡检技术较为落后,主要依靠人工的方式,存在耗时长等问题,尤其对于复杂环境下的人工巡检,弊端更为凸显。对于输电线路而言,若不及时处理故障,将对电力系统的稳定运行产生不良影响。目前,基于深度学习的输电线路巡检方法逐步取代传统人工巡检,本项目基于YOLOv5算法,针对488幅绝缘子缺陷图像,开展其缺陷的智能检测和识别研究。
2 图像数据集介绍


绝缘子破损会造成其绝缘性能的下降,若在巡检中发现应该及时更换。
输电线路绝缘子缺陷检测图像数据集共包含绝缘子破损、闪络缺陷、防震锤、正常绝缘子四类目标,采用旋转的方式进行扩充,并利用labelimg对其进行标注。
| 缺陷名称 | 正常绝缘子 | 破损 | 闪络 | 防震锤 |
| 标签数 | 2022 | 1260 | 2723 | 421 |
图像翻转扩充的python代码如下(需安装cv2和numpy)
import cv2
import numpy as np
def show_image(image, labels, h, w, winname):
image = image.copy().astype(np.uint8)
for l in labels:
x1 = int((l[1]-l[3]/2) * w)
y1 = int((l[2]-l[4]/2) * h)
x2 = int((l[1]+l[3]/2) * w)
y2 = int((l[2]+l[4]/2) * h)
# print(image.shape, (x1, y1), (x2, y2))
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 0, 255), 3)
cv2.imshow(winname, image)
if __name__ == '__main__':
image0 = cv2.imread('lena.jpg')
h, w = image0.shape[:2]
labels0 = np.array([[0, 50., 50, 20, 20], [0, 150, 150, 30, 30]])
labels0[:, 1::2] = labels0[:, 1::2] / w
labels0[:, 2::2] = labels0[:, 2::2] / h
image = image0.copy()
show_image(image, labels0, h, w, 'raw img')
#fliplr
image = image0.copy()
labels = labels0.copy()
image = np.fliplr(image)
labels[:, 1] = 1 - labels[:, 1]
show_image(image, labels, h, w, 'fliplr')
#flipud
image = image0.copy()
labels = labels0.copy()
image = np.flipud(image)
labels[:, 2] = 1 - labels[:, 2]
show_image(image, labels, h, w, 'flipud')
#rot90
image = image0.copy()
labels = labels0.copy()
image = np.rot90(image)
labels = labels[:, [0, 2, 1, 4, 3]]
labels[:, 2] = 1 - labels[:, 2]
show_image(image, labels, h, w, 'rot90')
#rot180
image = image0.copy()
labels = labels0.copy()
image = np.rot90(image)
image = np.rot90(image)
labels[:, 1:3] = 1 - labels[:, 1:3]
show_image(image, labels, h, w, 'rot180')
#rot270
image = image0.copy()
labels = labels0.copy()
image = np.rot90(image)
image = np.rot90(image)
image = np.rot90(image)
labels = labels[:, [0, 2, 1, 4, 3]]
labels[:, 1] = 1 - labels[:, 1]
show_image(image, labels, h, w, 'rot270')
cv2.waitKey(0)3 模型训练部分
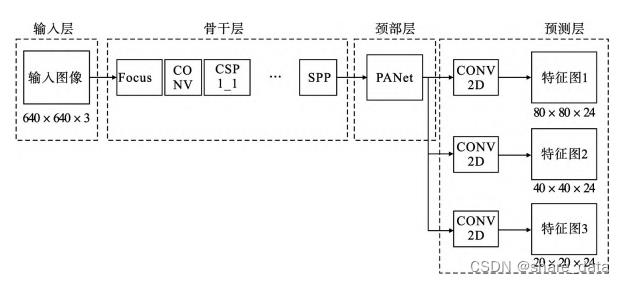
YOLOv5 模型是 Ultralytics 公司于 2020 年 6 月 9 日公开发布的。YOLOv5 模型是基于 YOLOv3 模型基础上改进而来的,有 YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x 四个模型。YOLOv5 模型由骨干网络、颈部和头部组成。
3.1 骨干特征提取网络backbone
YOLOv5 模型的骨干网络主要由 Focus、BottleneckCSP 和 SSP 网络构成,其中主要包括 Focus、Conv 卷积块、BottleneckCSP 和 SSP 等模块。
from functools import wraps
import tensorflow as tf
from tensorflow.keras import backend as K
from tensorflow.keras.initializers import RandomNormal
from tensorflow.keras.layers import (Add, BatchNormalization, Concatenate,
Conv2D, Layer, MaxPooling2D,
ZeroPadding2D)
from tensorflow.keras.regularizers import l2
from utils.utils import compose
class SiLU(Layer):
def __init__(self, **kwargs):
super(SiLU, self).__init__(**kwargs)
self.supports_masking = True
def call(self, inputs):
return inputs * K.sigmoid(inputs)
def get_config(self):
config = super(SiLU, self).get_config()
return config
def compute_output_shape(self, input_shape):
return input_shape
class Focus(Layer):
def __init__(self):
super(Focus, self).__init__()
def compute_output_shape(self, input_shape):
return (input_shape[0], input_shape[1] // 2 if input_shape[1] != None else input_shape[1], input_shape[2] // 2 if input_shape[2] != None else input_shape[2], input_shape[3] * 4)
def call(self, x):
return tf.concat(
[x[..., ::2, ::2, :],
x[..., 1::2, ::2, :],
x[..., ::2, 1::2, :],
x[..., 1::2, 1::2, :]],
axis=-1
)
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
darknet_conv_kwargs = 'kernel_initializer' : RandomNormal(stddev=0.02), 'kernel_regularizer' : l2(kwargs.get('weight_decay', 5e-4))
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2, 2) else 'same'
try:
del kwargs['weight_decay']
except:
pass
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
def DarknetConv2D_BN_SiLU(*args, **kwargs):
no_bias_kwargs = 'use_bias': False
no_bias_kwargs.update(kwargs)
if "name" in kwargs.keys():
no_bias_kwargs['name'] = kwargs['name'] + '.conv'
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(momentum = 0.97, epsilon = 0.001, name = kwargs['name'] + '.bn'),
SiLU())
def Bottleneck(x, out_channels, shortcut=True, weight_decay=5e-4, name = ""):
y = compose(
DarknetConv2D_BN_SiLU(out_channels, (1, 1), weight_decay=weight_decay, name = name + '.cv1'),
DarknetConv2D_BN_SiLU(out_channels, (3, 3), weight_decay=weight_decay, name = name + '.cv2'))(x)
if shortcut:
y = Add()([x, y])
return y
def C3(x, num_filters, num_blocks, shortcut=True, expansion=0.5, weight_decay=5e-4, name=""):
hidden_channels = int(num_filters * expansion)
x_1 = DarknetConv2D_BN_SiLU(hidden_channels, (1, 1), weight_decay=weight_decay, name = name + '.cv1')(x)
x_2 = DarknetConv2D_BN_SiLU(hidden_channels, (1, 1), weight_decay=weight_decay, name = name + '.cv2')(x)
for i in range(num_blocks):
x_1 = Bottleneck(x_1, hidden_channels, shortcut=shortcut, weight_decay=weight_decay, name = name + '.m.' + str(i))
route = Concatenate()([x_1, x_2])
return DarknetConv2D_BN_SiLU(num_filters, (1, 1), weight_decay=weight_decay, name = name + '.cv3')(route)
def SPPBottleneck(x, out_channels, weight_decay=5e-4, name = ""):
#---------------------------------------------------#
#---------------------------------------------------#
x = DarknetConv2D_BN_SiLU(out_channels // 2, (1, 1), weight_decay=weight_decay, name = name + '.cv1')(x)
maxpool1 = MaxPooling2D(pool_size=(5, 5), strides=(1, 1), padding='same')(x)
maxpool2 = MaxPooling2D(pool_size=(9, 9), strides=(1, 1), padding='same')(x)
maxpool3 = MaxPooling2D(pool_size=(13, 13), strides=(1, 1), padding='same')(x)
x = Concatenate()([x, maxpool1, maxpool2, maxpool3])
x = DarknetConv2D_BN_SiLU(out_channels, (1, 1), weight_decay=weight_decay, name = name + '.cv2')(x)
return x
def resblock_body(x, num_filters, num_blocks, expansion=0.5, shortcut=True, last=False, weight_decay=5e-4, name = ""):
#----------------------------------------------------------------#
#----------------------------------------------------------------#
# 320, 320, 64 => 160, 160, 128
x = ZeroPadding2D(((1, 0),(1, 0)))(x)
x = DarknetConv2D_BN_SiLU(num_filters, (3, 3), strides = (2, 2), weight_decay=weight_decay, name = name + '.0')(x)
if last:
x = SPPBottleneck(x, num_filters, weight_decay=weight_decay, name = name + '.1')
return C3(x, num_filters, num_blocks, shortcut=shortcut, expansion=expansion, weight_decay=weight_decay, name = name + '.1' if not last else name + '.2')
-----------------------#
def darknet_body(x, base_channels, base_depth, weight_decay=5e-4):
# 640, 640, 3 => 320, 320, 12
x = Focus()(x)
# 320, 320, 12 => 320, 320, 64
x = DarknetConv2D_BN_SiLU(base_channels, (3, 3), weight_decay=weight_decay, name = 'backbone.stem.conv')(x)
# 320, 320, 64 => 160, 160, 128
x = resblock_body(x, base_channels * 2, base_depth, weight_decay=weight_decay, name = 'backbone.dark2')
# 160, 160, 128 => 80, 80, 256
x = resblock_body(x, base_channels * 4, base_depth * 3, weight_decay=weight_decay, name = 'backbone.dark3')
feat1 = x
# 80, 80, 256 => 40, 40, 512
x = resblock_body(x, base_channels * 8, base_depth * 3, weight_decay=weight_decay, name = 'backbone.dark4')
feat2 = x
# 40, 40, 512 => 20, 20, 1024
x = resblock_body(x, base_channels * 16, base_depth, shortcut=False, last=True, weight_decay=weight_decay, name = 'backbone.dark5')
feat3 = x
return feat1,feat2,feat3
3.2 颈部neck
YOLOv5 使用的 BottleneckCSP1 和 BottleneckCSP2 能在保证准确的同时,提高网络速度。YOLOv5 的颈部采用 BottleneckCSP2 模块减少模型参数量,通过上采样操作 80*80*512 大小的特征图,上采样过程由 2 组 BottleneckCSP2、大小为 1 步长为 1的 Conv、Upsample 和 Concat 连接完成。
from tensorflow.keras.layers import (Concatenate, Input, Lambda, UpSampling2D,
ZeroPadding2D)
from tensorflow.keras.models import Model
from nets.CSPdarknet import (C3, DarknetConv2D, DarknetConv2D_BN_SiLU,
darknet_body)
from nets.yolo_training import yolo_loss
#---------------------------------------------------#
def yolo_body(input_shape, anchors_mask, num_classes, phi, weight_decay=5e-4):
depth_dict = 's' : 0.33, 'm' : 0.67, 'l' : 1.00, 'x' : 1.33,
width_dict = 's' : 0.50, 'm' : 0.75, 'l' : 1.00, 'x' : 1.25,
dep_mul, wid_mul = depth_dict[phi], width_dict[phi]
base_channels = int(wid_mul * 64) # 64
base_depth = max(round(dep_mul * 3), 1) # 3
inputs = Input(input_shape)
#---------------------------------------------------#
#---------------------------------------------------#
feat1, feat2, feat3 = darknet_body(inputs, base_channels, base_depth, weight_decay)
P5 = DarknetConv2D_BN_SiLU(int(base_channels * 8), (1, 1), weight_decay=weight_decay, name = 'conv_for_feat3')(feat3)
P5_upsample = UpSampling2D()(P5)
P5_upsample = Concatenate(axis = -1)([P5_upsample, feat2])
P5_upsample = C3(P5_upsample, int(base_channels * 8), base_depth, shortcut = False, weight_decay=weight_decay, name = 'conv3_for_upsample1')
P4 = DarknetConv2D_BN_SiLU(int(base_channels * 4), (1, 1), weight_decay=weight_decay, name = 'conv_for_feat2')(P5_upsample)
P4_upsample = UpSampling2D()(P4)
P4_upsample = Concatenate(axis = -1)([P4_upsample, feat1])
P3_out = C3(P4_upsample, int(base_channels * 4), base_depth, shortcut = False, weight_decay=weight_decay, name = 'conv3_for_upsample2')
P3_downsample = ZeroPadding2D(((1, 0),(1, 0)))(P3_out)
P3_downsample = DarknetConv2D_BN_SiLU(int(base_channels * 4), (3, 3), strides = (2, 2), weight_decay=weight_decay, name = 'down_sample1')(P3_downsample)
P3_downsample = Concatenate(axis = -1)([P3_downsample, P4])
P4_out = C3(P3_downsample, int(base_channels * 8), base_depth, shortcut = False, weight_decay=weight_decay, name = 'conv3_for_downsample1')
P4_downsample = ZeroPadding2D(((1, 0),(1, 0)))(P4_out)
P4_downsample = DarknetConv2D_BN_SiLU(int(base_channels * 8), (3, 3), strides = (2, 2), weight_decay=weight_decay, name = 'down_sample2')(P4_downsample)
P4_downsample = Concatenate(axis = -1)([P4_downsample, P5])
P5_out = C3(P4_downsample, int(base_channels * 16), base_depth, shortcut = False, weight_decay=weight_decay, name = 'conv3_for_downsample2')
out2 = DarknetConv2D(len(anchors_mask[2]) * (5 + num_classes), (1, 1), strides = (1, 1), weight_decay=weight_decay, name = 'yolo_head_P3')(P3_out)
out1 = DarknetConv2D(len(anchors_mask[1]) * (5 + num_classes), (1, 1), strides = (1, 1), weight_decay=weight_decay, name = 'yolo_head_P4')(P4_out)
out0 = DarknetConv2D(len(anchors_mask[0]) * (5 + num_classes), (1, 1), strides = (1, 1), weight_decay=weight_decay, name = 'yolo_head_P5')(P5_out)
return Model(inputs, [out0, out1, out2])
def get_train_model(model_body, input_shape, num_classes, anchors, anchors_mask, label_smoothing):
y_true = [Input(shape = (input_shape[0] // 0:32, 1:16, 2:8[l], input_shape[1] // 0:32, 1:16, 2:8[l], \\
len(anchors_mask[l]), num_classes + 5)) for l in range(len(anchors_mask))]
model_loss = Lambda(
yolo_loss,
output_shape = (1, ),
name = 'yolo_loss',
arguments =
'input_shape' : input_shape,
'anchors' : anchors,
'anchors_mask' : anchors_mask,
'num_classes' : num_classes,
'label_smoothing' : label_smoothing,
'balance' : [0.4, 1.0, 4],
'box_ratio' : 0.05,
'obj_ratio' : 1 * (input_shape[0] * input_shape[1]) / (640 ** 2),
'cls_ratio' : 0.5 * (num_classes / 80)
)([*model_body.output, *y_true])
model = Model([model_body.input, *y_true], model_loss)
return model
3.3 头部 YOLO head
YOLOv5 的头部采用多尺度特征图用于检测,用大图像检测小目标,小图像检测大目标。对颈部三种不同尺度特征图,通过 Conv2d 卷积操作,最终得到三个大小分别为 80*80*255、40*40*255、20*20*255 的特征图。
3.4 输出层output
在三个不同尺度特征图上生成候选框,由于本文对绝缘子缺陷的检测有 4 类,对 YOLOv5 的 3 个尺度特征图使用 3 种大小不同的候选框对四类目标进行预测,最后输出采用加权非极大值的方式对目标框进行筛选对生成的候选框进行筛选,输出目标分类和边框回归。
YOLOv5模型简易结构
模型训练过程中采用余弦退火衰减算法、并采用adam优化完成对模型权值参数的更新,其中训练集:测试集=9:1,冻结原始预训练YOLOv5模型前234层,迭代训练100个epoch,batchsize1=8,再解冻迭代训练200个epoch,batchsize2=4,3060ti显卡。
4 模型性能测试
| 缺陷名称 | 正常绝缘子 | 破损 | 闪络 | 防震锤 |
| AP值 | 97.00% | 75.00% | 81.00% | 80.00% |

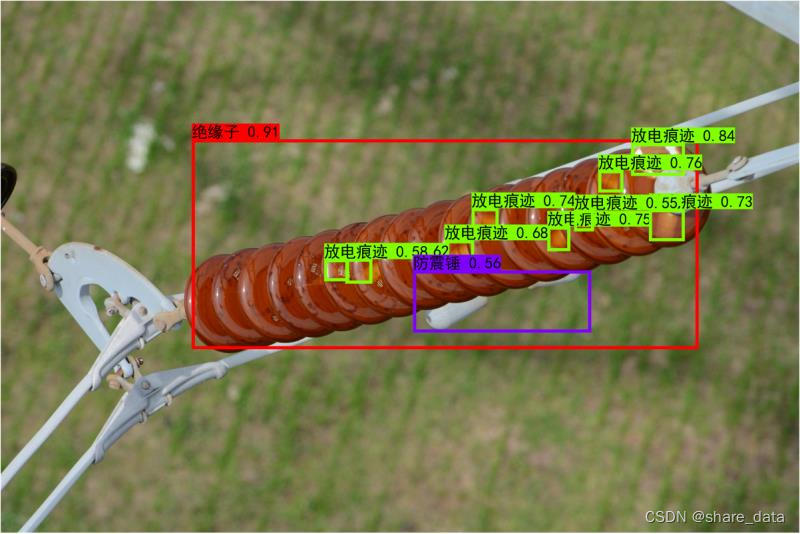
以上是关于基于YOLOv5的输电线路绝缘子缺陷检测项目的主要内容,如果未能解决你的问题,请参考以下文章