PyTorch 深度学习实战 | 基于 ResNet 的花卉图片分类
Posted TiAmo zhang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch 深度学习实战 | 基于 ResNet 的花卉图片分类相关的知识,希望对你有一定的参考价值。

“工欲善其事,必先利其器”。如果直接使用 Python 完成模型的构建、导出等工作,势必会耗费相当多的时间,而且大部分工作都是深度学习中共同拥有的部分,即重复工作。所以本案例为了快速实现效果,就直接使用将这些共有部分整理成框架的 TensorFlow 和 Keras 来完成开发工作。TensorFlow 是 Google 公司开源的基于数据流图的科学计算库,适合用于机器学习、深度学习等人工智能领域。Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow、CNTK 或 Theano 作为后端运行。Keras 的开发重点是支持快速的实验,所以,本案例中,大部分与模型有关的工作都是基于 Keras API 来完成的。而现在版本的 TensorFlow 已经将 Keras 集成了进来,所以只需要安装 TensorFlow 即可。注意,由于本案例采用的 ResNet 网络较深,所以模型训练需要消耗的资源较多,需要 GPU 来加速训练过程。
1、环境安装
安装 TensorFlow 的 GPU 版本是相对比较繁杂的事情,需要找对应的驱动,安装合适版本的 CUDA 和 cuDNN。而一种比较方便的办法就是使用 Anaconda 来进行 tensorflow-gpu 的安装。具体的安装过程可以参考本书的附录 A.2 部分。其他需要安装的依赖包的名称及版本号如下:
其他依赖包可以在 Anaconda 界面上进行选择安装,也可以将其添加到 requirements.txt 文件,然后使用 conda install -yes -file requirements.txt 命令进行安装。另外,Conda 可以创建不同的环境来支持不同的开发要求。例如,有些工程需要 TensorFlow 1.15.0 环境来进行开发,而另外一些工程需要 TensorFlow 2.1.0 来进行开发,替换整个工作环境或者重新安装 TensorFlow 都不是很好的选择。所以,本案例使用 Conda 创建虚拟环境来解决。
2、数据集简介
在进行模型构建和训练之前,需要进行数据收集。为了简化收集工作,本案例采用已标记好的花卉数据集 Oxford 102 Flowers。数据集可以从 VGG 官方网站上进行下载。单击如图 1 所示的 Downloads 区域的 1、4 和 5 对应的超链接就可以下载所需要的文件。
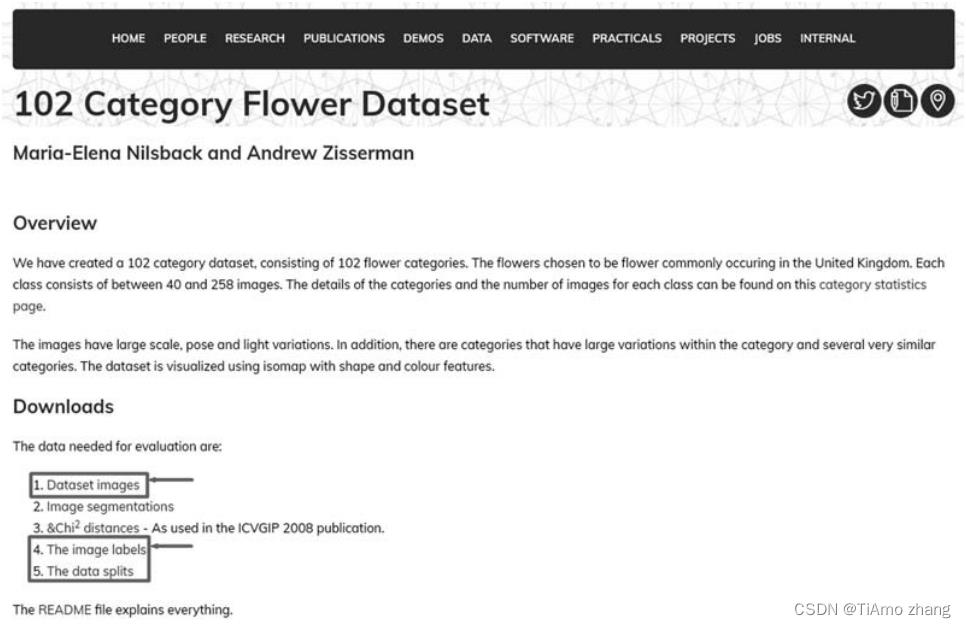
■ 图 1 Oxford 102 Flowers 数据集下载网站
该数据集由牛津大学工程科学系于 2008 年发布,是一个英国本土常见花卉的图片数据集,包含 102 个类别,每类包含 40 ~ 258 张图片。在基于深度学习的图像分类任务中,这样较为少量的图片还是比较有挑战性的。Oxford 102 Flowers 的分类细节和部分类别的图片及对应的数量如图 2 所示。
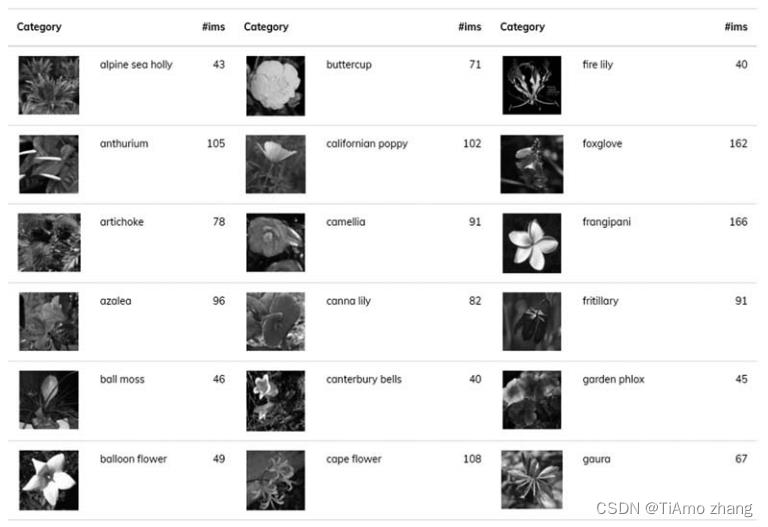
■ 图 2 Oxford 102 Flowers 的分类细节和部分类别的图片及对应的数量
除了图片文件(dataset images),数据集中还包含图片分割标记文件(image segmentations)、分类标记文件(the image iabels)和数据集划分文件(the data splits)。由于本案例中不涉及图片分割,所以使用的是图片、分类标记和数据集划分文件。
3、数据集的下载与处理
Python urllib 库提供了 urlretrieve()函数可以直接将远程数据下载到本地。可以使用 urlretrieve()函数下载所需文件;然后把压缩的图片文件进行解压,并解析分类标记文件和数据集划分文件;再根据数据集划分文件并分成训练集、验证集和测试集;最后,向不同类别的数据集中按图片所标识的花的种类分类存放图片文件。代码及详细注释如代码清单 1 所示。
代码清单 1
import os
from urllib.request import urlretrieve
import tarfile
from scipy. io import loadmat2
from shutil import copyfile
import glob
import numpy as np
"""
函数说明:按照分类(labels)复制未分组的图片到指定的位置10
Parameters:
data path - 数据存放目录
labels - 数据对应的标签,需要按标签放到不同的目录
"""
def copy_data_files(data path, labels) :
if not os. path, exists( data path) :
os.mkdir(data path)
# 创建分类目录
for i in range(0,102) :
os.mkdir(os.path.join( data path, str(i)))
for label in labels:
src path = str(label[0])
dst path = os.path. join(data path, label[1], src path. split(os. sep)[ - 1])
copyfile(src path, dst path)
if_name_ _== '_main_':
# 检查本地数据集目录是否存在,若不存在,则需创建
data set path = "./data'
if not os. path. exists( data set path) :
os.mkdir(data set path)
#下载 102 Category Elower 数据集并解压
flowers archive file = "102flowers.tgz'
flowers_url frefix = "https://www,robots.ox.ac.uk/~vgg/data/flowers/102/'
flowers archive path = os.path, join(data set path, flowers archive file)
if not os path.exists(flowers archive path) :
print("正在下载图片文件...")
urlretrieve(flowers url frefix + flowers archive file, flowers archive path)
print("图片文件下载完成.")
print("正在解压图片文件...")
tarfile. open(flowers archive path)..extractall(path = data set_path)
print("图片文件解压完成,")
# 下载标识文件,标识不同文件的类别
flowers labels file = "imagelabels.mat'
flowers labels path = os.path. join(data set path, flowers labels file)
if not os.path.exists(flowers labels path) :
print("正在下载标识文件...")
urlretrieve(flowers url frefix + flowers labels file, flowers labels path)
print("标识文件下载完成")
flower_labels = loadmat(flowers_labels_path)['labels'][0] - 1
#下载数据集分类文件,包含训练集、验证集和测试集
sets splits file = "setid.mat"
sets splits_path = os.path. join(data set path, sets splits file)
if not os.path,exists( sets splits path) :
print("正在下载数据集分类文件...")
urlretrieve(flowers url frefix + sets splits file, sets splits path)
print("数据集分类文件下载完成")
sets_splits = loadmat( sets splits path)
# 由于数据集分类文件中测试集数量比训练集多,所以进行了对调
train set = sets splits['tstid'][0] - 1
valid set = sets splits[ 'valid'][0] - 1
test_set = sets splits['trnid'][0] - 1
# 获取图片文件名并找到图片对应的分类标识
image files = sorted(glob.glob(os.path. join(data set path, 'jpg', ' x .jpg')))
image labels = np.array([i for i in zip(image files, flower labels)])
# 将训练集、验证集和测试集分别放在不同的目录下
print("正在进行训练集的复制...")
copy_data files(os.path. join(data set path, 'train'), image labels[train set, :]
print("已完成训练集的复制,开始复制验证集...")
copy_data files(os.path. join(data_set_path, 'valid'), image labels[valid set, :]
print("已完成验证集的复制,开始复制测试集...")
copy_data files(os.path, join(data set_path, 'test'), image labels[test set, :]
print("已完成测试集的复制,所有的图片下载和预处理工作已完成.")下载的图片数据有 330MB 左右。国外的网站有时候下载比较慢,可以用下载工具下载,或者使用参考书前言中提供的二维码进行下载。
需要说明的是,分类标记文件 imagelabels.mat 和数据集划分文件 setid.mat 是 MATLAB 的数据存储的标准格式,可以用 MATLAB 程序打开进行查看。本案例中使用 scipy 库的 loadmat()函数对 .mat 文件进行读取。图片分类后的目录结构如图 3 所示。

■ 图 3 图片分类后的目录结构
以上是关于PyTorch 深度学习实战 | 基于 ResNet 的花卉图片分类的主要内容,如果未能解决你的问题,请参考以下文章