Hadoop高可用(HA)方案总结
Posted 大愚若智_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop高可用(HA)方案总结相关的知识,希望对你有一定的参考价值。
一 、Hadoop1.0时期的NameNode及Secondary NameNode
- 在早期的hadoop时代,hdfs集群存在严重的单点问题,即集群只有一个NameNode节点,尽管有SecondaryNameNode,CheckPointNode,BackupNode这些机制来对单点的问题做一定的防反,但单点问题是依然存在的。在主NameNode挂掉之后,集群的管理不能自动的切换到另外一个NameNode来接管集群,只能通过重启挂掉来解决问题,对线上应用是一个极大的安全隐患。
- 在这里简要介绍一些NameNode,Secondary NameNode的作用
NameNode:主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等。当它运行的时候,这些信息是存在内存中的,但是这些信息也可以持久化到磁盘上
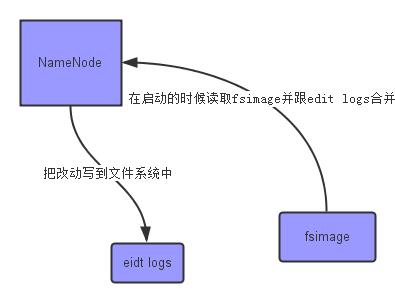
- 其中fsimage 是在NameNode启动时对整个文件系统的快照,edit logs是在NameNode启动后,对文件系统的改动进行记录的日志。因此在NameNode长时间运行后,edit logs会越写越大 这样也会导致后期越写越慢,同时在NameNode启动的时候,需要把edit logs合并到fsimage中,导致该节点的启动时间大大增加,甚至一次启动需要耗费几个小时。为了解决edit logs合并的问题,hadoop1.0时期引入了SecondaryNameNode,SecondaryNameNode定时去NameNode上拉取新的edit logs ,并把新的edit logs合并到SecondaryNameNode下的fsimage文件中,再把这个新的fsimage复制到NameNode上。fsimage在文件命名上会加上最后一次合并edit logs的最后的时间戳,已确保哪些edit logs是已经合并入fsimage的。
- 具体的细节可以参考Hadoop1.0的相关工具书,在此不表。我们需要注意的是,增加了SecondaryNameNode后,NameNode挂掉后导致集群无法服务问题依然存在 只是缩短了重启NameNode节点时合并edit logs需要的时间,但是fsimage文件毕竟很大,不是秒级耗时就能重启成功的。
二、Hadoop2.0时期的HA
在Hadoop2.0时期,为了解决NameNode的单点问题,在架构上进行了重大的调整,引入了Standby NameNode及Journal集群,在集群架构和部署上相对麻烦了一些,但是确实实现了高可用了,不经做到了主NameNode的数据同步复制备份,也做到了从NameNode的自动接管即Failover控制。
新的高可用方案由以下几个关键组件组成:
-
NameNode(Active)
-
NameNode(Standby)
-
Failover Controllers
-
Journal Nodes
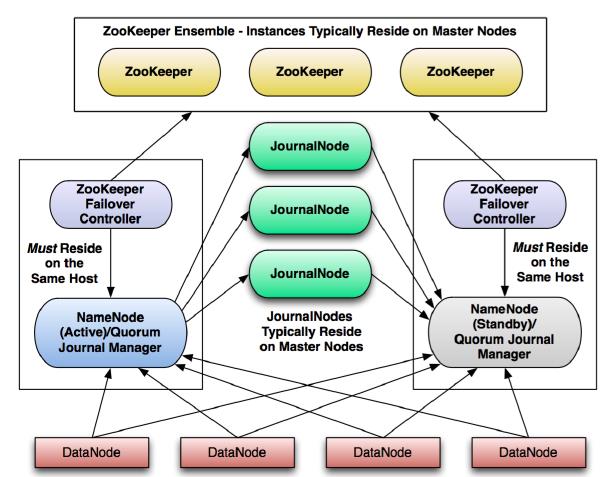
它们在集群中的位置和角色如下图所示:
-
Active NameNode:
接受client的RPC请求并处理,同时写自己的Editlog和共享存储上的Editlog,接收DataNode的Block report, block location updates和heartbeat; -
Standby NameNode:
同样会接到来自DataNode的Block report, block location updates和heartbeat,同时会从共享存储的Editlog上读取并执行这些log操作,使得自己的NameNode中的元数据(Namespcae information + Block locations map)都是和Active NameNode中的元数据是同步的。所以说Standby模式的NameNode是一个热备(Hot Standby NameNode),一旦切换成Active模式,马上就可以提供NameNode服务 -
JounalNode:
用于Active NameNode , Standby NameNode 同步数据,本身由一组JounnalNode结点组成,该组结点基数个,支持Paxos协议,保证高可用 -
ZKFC:
监控NameNode进程,是集群中的Failover controllers,进行自动备援
以上是关于Hadoop高可用(HA)方案总结的主要内容,如果未能解决你的问题,请参考以下文章