手把手带你入门MySql数据库
Posted 程序猿是小贺
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手把手带你入门MySql数据库相关的知识,希望对你有一定的参考价值。
mysql入门宝典
- 1.前言
- 2.Linux下安装MySQL
- 3.mysql服务端和数据库的关系
- 4.基本操作
- 5.navicat连接数据库
- 6.MYSQL数据类型分类
- 7.表的约束
- 8.数据库表的相关操作
- 9.复合查询(重要)
- 10.事务
- 11. 索引特性(重点)
- 视图
1.前言
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL 软件采用了双授权政策,分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择 MySQL 作为网站数据库。
2.Linux下安装MySQL
- 付费版本:MySQL5.7
- free版本:MariaDB
安装mariadb的方法
首先要切换至root用户,可以使用yum包管理器进行安装
yum install -y mariadb
yum install -y mariadb-server
yun install -y mariadb-devel
2.1 查看当前机器是否安装了mysql
mariadb
rpm -qa | grep mariadb

MySQL5.7
rpm -qa | grep mysql
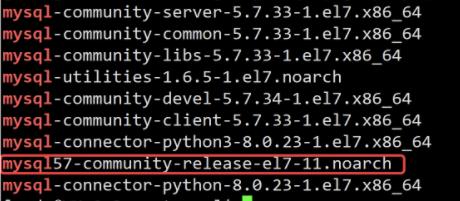
2.2 关于mariadb和mysql
对于一个初学者来说,我建议可以使用最简单的mariadb方式,如果要使用mysql则需要单独去下载mysql的安装包并且要在此之前将mariadb卸载掉,MariaDB是MySQL的二进制替代品
- mariadb
1.查看mysql服务端的运行情况
service mariadb status;
2.启动mariadb
service mariadb start
3.停止mariadb
service mariadb stop
4.重启mariadb
service mariadb restart
- mysql
启动:systemctl start mysqld
停止:systemctl stop mysqld
重启:systemctl restart mysqld
对于mariadb在初始化登录时不需要密码,对于mysq5.7而言,在初始化时需要密码
在mysql5.7获取临时密码
在root用户下输入
cat /var/log/mysqld.log | grep "temporary password"

3.mysql服务端和数据库的关系
3.1 mysql服务端的守护进程
不论是mariadb还是mysql5.7都是mysql的服务端软件,是用来管理若干个数据库的软件

mysqld_safe的职责
1.在启动mysql阶段,实现启动mysqld_safe这个进程,由该进程创建子进程,让子进程程序替换成为mysqld进程
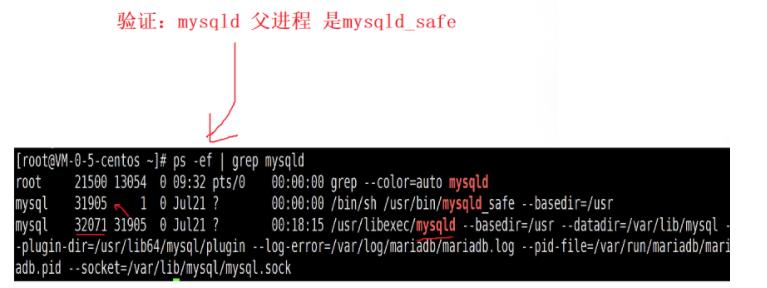
2.mysqld_safe 时时刻刻监控mysqld的运行情况,一旦mysqld崩溃或者卡死,重启一个mysqld进程。
验证:直接将mysqld进程kill掉,过一会再来查看,mysqld进程是否启动

结论:服务端进程是24小时不间断来进行服务的
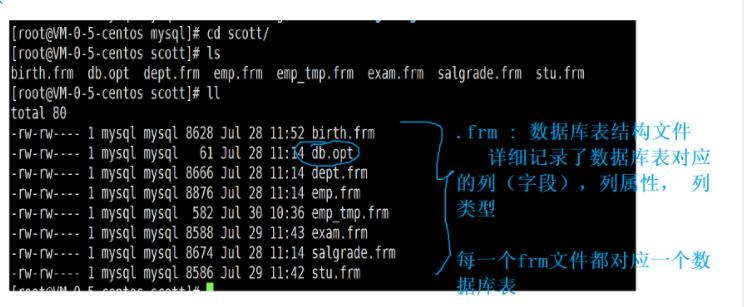
db.opt :保存当前数据的字符集以及校对规则
ibdatal :保存数据库表记录的文件
3.2 mysql客户端和mysql服务端
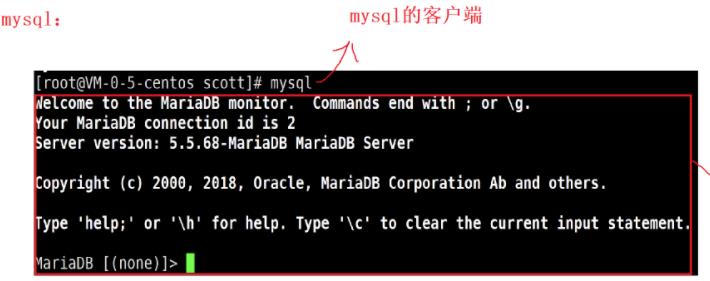
3.2.1mysql客户端
没有密码情况
直接输入mysql
mysql的客户端连接成功mysql的服务端,此时在该界面中就可以操作mysqld管理的mysql数据库了
有密码:
mysql -u 用户名(eg:xiaohe) -p
回车之后,再输入你想设置的密码即可

3.2.2 mysql服务端

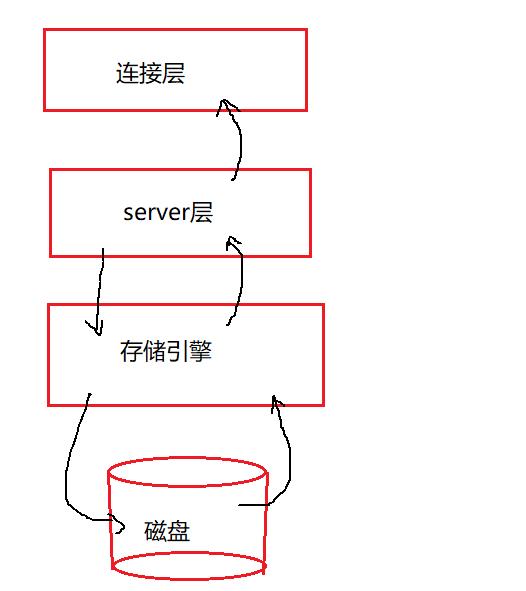
3.3 mysql服务端的架构
3.3.1 连接层
1.接收客户端的连接
1.1客户端来自不同的机器(跨网络)使用到tcp协议
1.2客户端和服务端在同一台机器(本地域套接字,AF_UNIX)
2.检验用户的合法性
2.1登录的用户名是否合法
2.2登录的用户名使用密码合法性
2.3校验当前用户登录的位置(对客户端持有的ip进行合法性校验)
3.创建线程为客户端服务
3.3.2 server层
1.sql语句的语法语义的检测
2.优化sql语句
3.执行sql语句(与存储引擎打交道)
3.3.3 存储引擎
存储引擎决定了数据服务端针对该数据库当中的数据,如何保存,如何建立索引,如何进行更新,如何进行查询等等
- InnoDB(支持事务)
数据存储在:ibdata1文件当中
InnoDB支持行级锁。行级锁可以最大程度的支持并发,行级锁是由存储引擎层实现的。
锁:锁的主要作用是管理共享资源的并发访问,用于实现事务的隔离性
类型:共享锁(读锁)、独占锁(写锁)
MySQL锁的力度:
表级锁(开销小、并发性低),通常在服务器层实现
行级锁(开销大、并发性高),只会在存储引擎层面进行实现 - MyISAM


草图了解过程
4.基本操作
4.1 mysql数据库的操作
1. 查看mysql数据库
show databases;

2.创建数据库
create database 数据库名称;

3.使用数据库
use 数据库名;

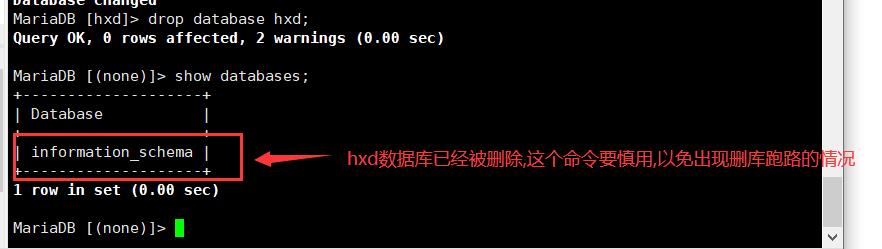
4.删除数据库
drop database 数据库名称;
4.2 数据库表结构的操作:
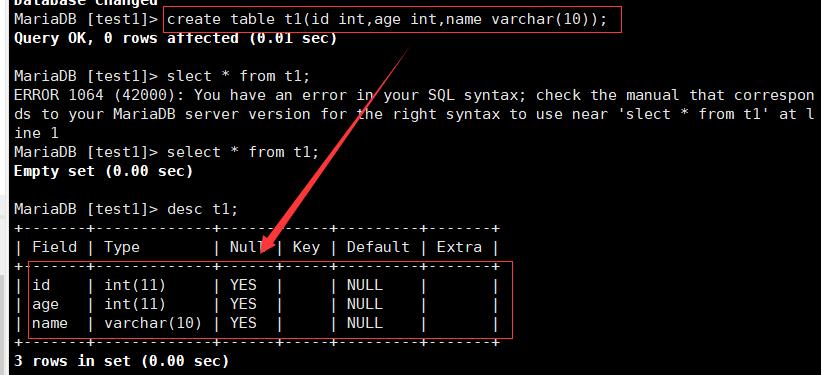
1.创建数据库表:指定数据库表的列(字段)名称,列类型,列属性
sql范式:create table [表名称](列名称 列类型「属性],列名称 列类型〔属性],...);
2.查看数据库表show tables

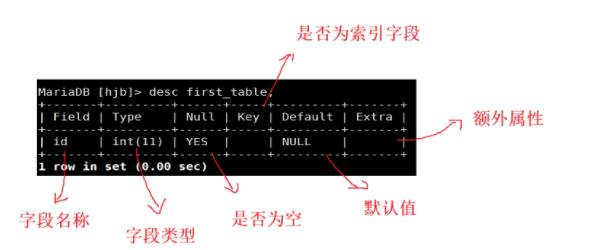
3.查看数据库表结构
desc[表名称]
4.查看数据表的创建
show create table[表名称] ;
带有格式的show create table[表名称] \\G
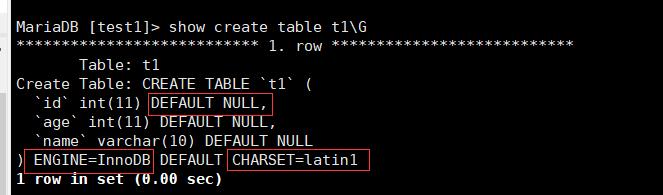
DETAULT NULL :当前列的属性信息,默认取值为NULL
ENGINE:存储引擎,采用InnoDB(默认是支持事务)
CHARSET :字符集,决定了数据库到底可以存储什么样的字符,定义了可以表示字符的范围。
- ASCII码:一个字符占用的空间为1字节,
ASCII能够表示的字符是从0~127,总共128个字符
字符集决定了数据库在保存字符的时候,一个字符占用多少字节。 - latin1 : 一个字符占用的字节数量为1字节
- utf8:一个字符占用的字节数量**(1~3)字节**
需要在创建数据库时,将数据库的字符集设置成为utf8
在创建数据库时,可以直接设置数据库的字符集,当在数据库中创建数据库表时,数据库表的字符集默认使用数据库的字符集。
4.插入数据:
全列插入,指定列插入,多行插入
这里先只带大家了解一下全列插入,其他的下面了解
全列插入:sql命令范式:insert into [表名称] values(字段1的值,字段2的值,...);
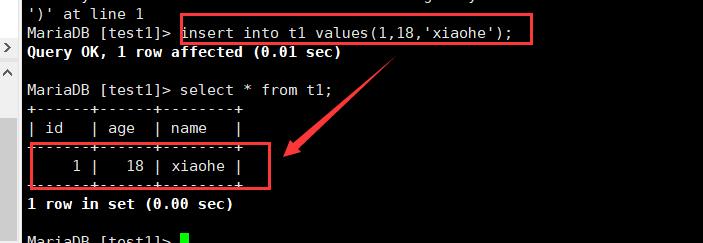
5.查询
全列查询,指定列查询,带有约束条件的查询,子查询,多表查询
这里也一样,先只了解全列查询
全列查询sql命令范式:select * from [表名称]

6.删除数据库表
drop table [数据库表名称]
一定要慎用,一旦将数据库表删掉,数据库表中的数据也就被删掉了
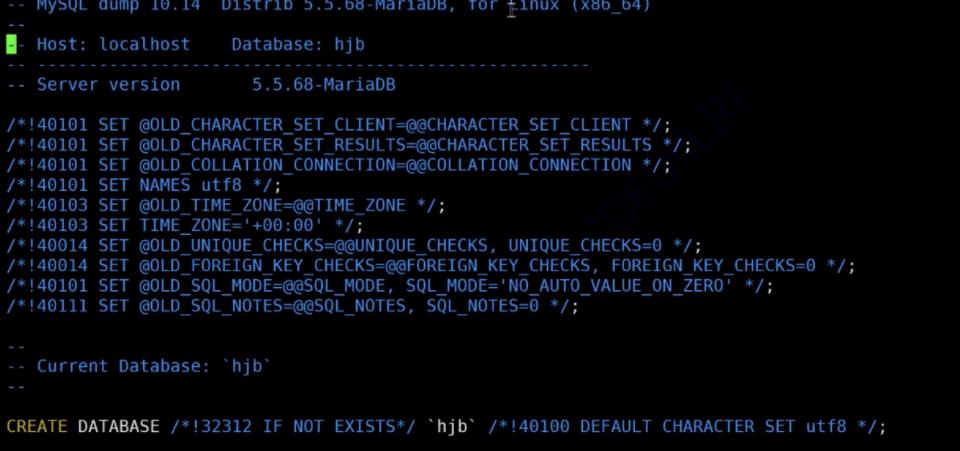
7.数据库的备份
mysqldump是mysql的备份工具(本质上就是一个可执行程序)
备份数据库
命令范式: mysqldump -P3306 -u root -p 密码 -B 数据库名 〉数据库备份存储的文件路径
在命令行输入这条语句,并不是在mysql里面进行输入,也可以指定其他的文件路径存储文件

可以用vim打开查看这个备份文件
备份某一个数据库表
命令范式:mysqldump -P3306 -u root [数据库] [数据库表] > 数据库备份存储的文件路径
恢复:使用mysql登录上数据库服务端之后,使用source命令进行恢复
命令范式:source [备份文件]
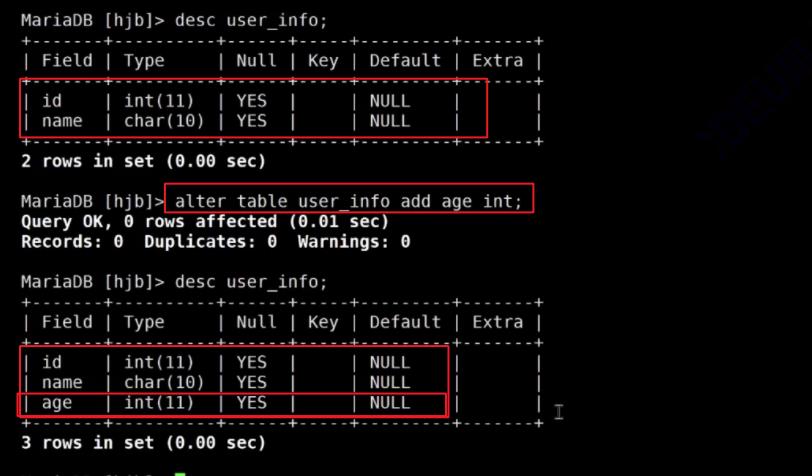
8.修改表:
增加表字段、删除表字段、修改表字段名字、修改表字段类型等等
命令行范式:alter table [table_name] add/drop/modify/change [列名称 [列类型]]
增加表字段
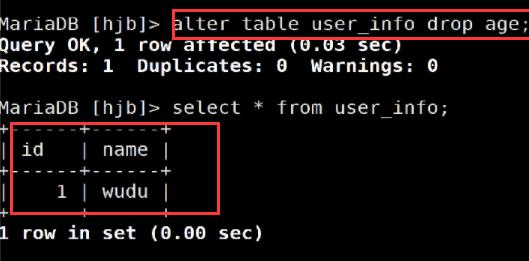
删除表字段
当使用alter关键字删除表字段时,同时会将该表的字段对应的列内容也删除掉!
删除时不需要指定列类型
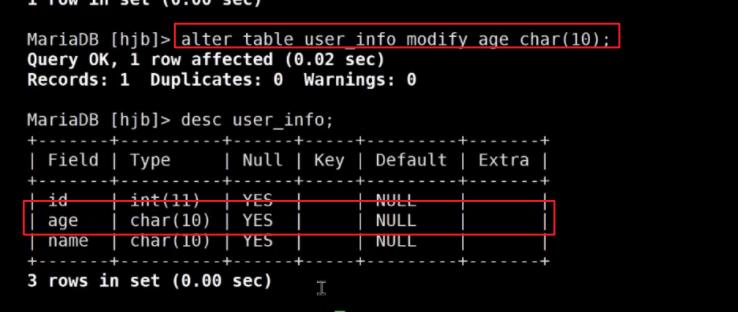
修改表字段类型
5.navicat连接数据库
5.1 操作
1.是一款可视化的数据库连接软件,可以连接mysql的服务端并且操作数据库
2.下载连接


创建数据库用户并且设置密码
create user '用户名' @ '登陆主机/ip' identified by '密码'
刚刚被创建出来的用户,是没有操作权限的,需要给用户进行赋值权限,使其可以操作数据库。
赋值权限:
grant权限列表 on 库.对象名 to '用户名'@’登陆位置’[identified by '密码’]
回收用户权限:
revoke 权限列表 on 库.对象名 from ’用户名’@’登陆位置’
5.2 结论
- 如果需要navicat连接mysql,必须要有一个用户可以从远端继续登录(%)。
- 创建用户之后,需要给用户赋值权限,否则当前用户即使登录上mysql服务端,也什么都操作不了。
- 赋值权限可以按照细分的权限给赋值,也可以使用all,分配全部权限。
- 也可以只给用户分配某一个数据库某一个数据库表的权限。
- 赋值权限之后,也可以回收权限。
6.MYSQL数据类型分类
6.1数值类型
MySQL支持所有标准SQL数值数据类型。
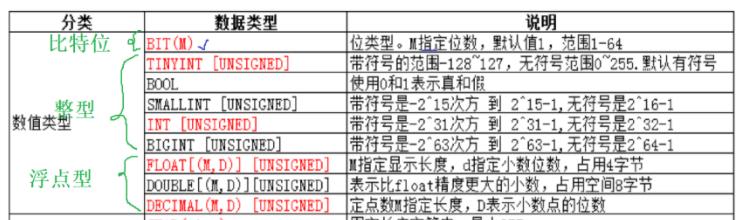
BIT类型
1.M代表的是二进制位的个数,可以决定当前字段到底能够保存多大的数。
2.展示数据的时候是按照ASCII码来展示数据的。
tinyint
1.占用一个字节,默认是有符号的,-128~127。
⒉.后期在业务开发当中,该类型除了特殊情况,一般不会使用,会使用表示范围更大的类型( int, bigint)。
bool :0表示假,1表示真。
smallint占用两个字节,默认有符号,-2^15 ~2^15- 1。
int占用4字节,默认有符号。
bigint占用8字节,默认有符号。
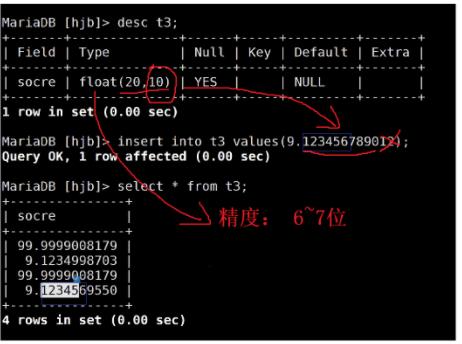
float类型:
1.M表示展示的长度,展示的长度不包含小数点,D表示小数点后的位数。
2.占用4字节。
3.小数部分如果超过长度,会四舍五入。
eg:score float(6,4)能够表示最大的数字:99.9999
4.如果保存的数字超过类型表示的范围,就默认取最大值
5.float类型的精度位6~7位
double :
1.占用8字节
2.double的精度位15~16位
decimal
1.存储浮点型
2.保证的数据精度为小数点后的30位(mysql独有的类型)
6.2 日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。

6.3 字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。

- CHAR和VARCHAR类型
char:固定长度字符串
1.char(num) : num表示当前字符长度
info char(10):表示info这个字段最大保存的字符长度为10
2.具体使用多少字节,是与字符集和字符长度有关系
字符集定义每个字符占用的字节数量 * 字符长度
3.不管有没有使用字段开辟出来的空间,字节都是被占用的。
varchar:可变长度字符串
1.varchar (num) : num表示字符长度
2.varchar是按照实际保存的字符串来计算字符串占用的字节数量的;
varchar字符串最大的长度为21844
*21844 3 =65532 +3 = 65535
varchar最大占用的字节数量为65535字节
BINARY和VARBINARY类类似于CHAR和VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB是一个二进制大对象,可以容纳可变数量的数据。有4种BLOB类型:TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB。它们只是可容纳值的最大长度不同。
有4种TEXT类型:TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT。这些对应4种BLOB类型,有相同的最大长度和存储需求。
set:集合,“多选”类型,支持在一个字段当中选择多个设定的值
7.表的约束
指的是约束表的字段,表的字段在定义时,一定存在类型,约束是为了约束该字段的值
1.空属性:
NULL :表示该字段的值可以为空
NOT NULL :该字段的值不能为空
2.默认值
当插入数据没有给字段值时,采用默认值。
定义字段约束时,default [默认值]
3.列描述
当前列的解释(备注),对于数据的存储、获取没有任何影响。
定义:comment[具体的描述]
4.zerofill
格式化输出,如果输出的数字的位数不够整型表示的位数,则高位补0之后进行输出
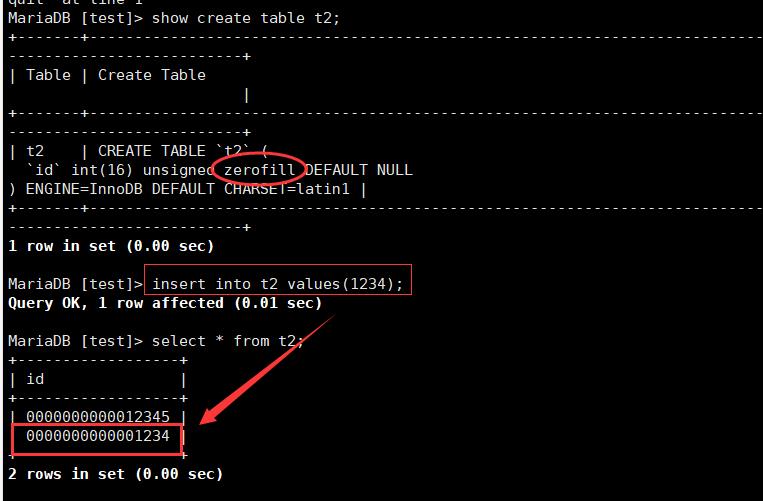
5.主键(重要)
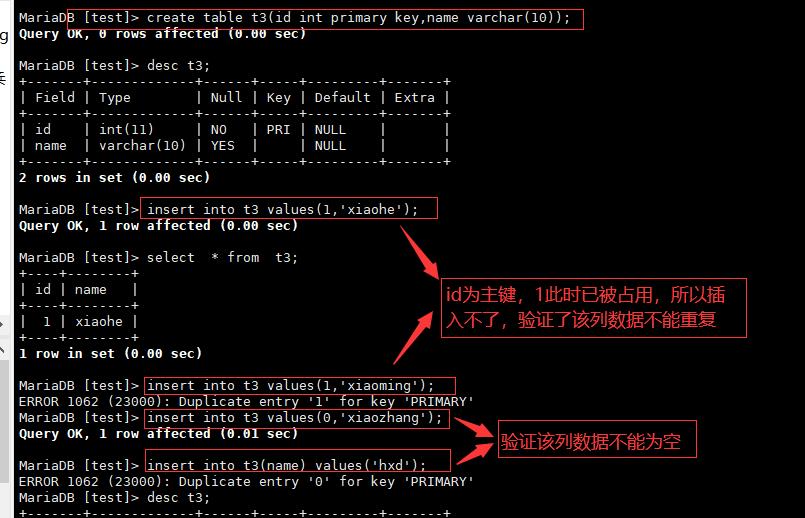
5.1在表当中定义一个主键,并不是重新增加一列,而是给某一字段设置上主键属性
5.2主键属性保证了该列的数据不能为空,不能重复
5.3 一张表当中只能有一个主键列
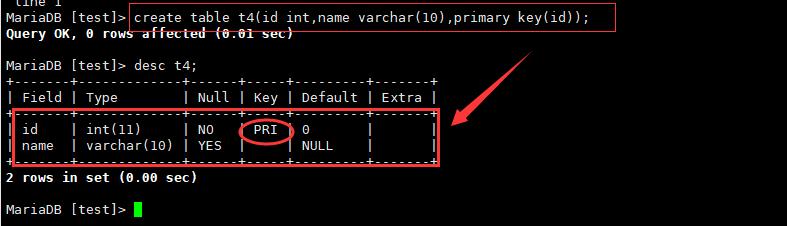
5.4 定义主键:
1.在创建数据库表时,在字段的后面加上primary key
2.定义完毕所有字段之后,在最后一个字段当中添加主键列
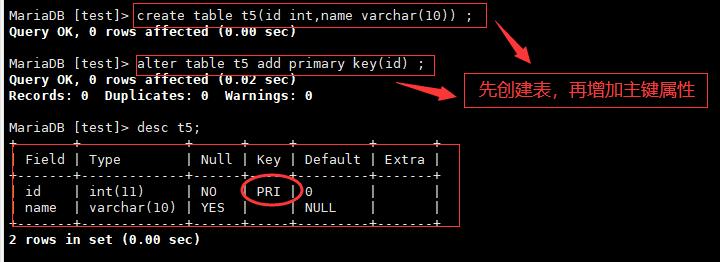
3.修改表结构
5.5主键列的列类型应该为整型
主键列的优势
1.主键列的值可以在全表当中唯一标识一行记录
2.被设置成为主键的列,数据库会针对当前列构建一个B+树,方便使用主键列进行查找(检索)数据。
当数据表没有任何主键/唯一键/索引列时,查询数据都是依次往后遍历查询的。
删除主键:alter table [table] drop primary key
相应的为主键列构建的B+树也会被删除掉

6.复合主键:
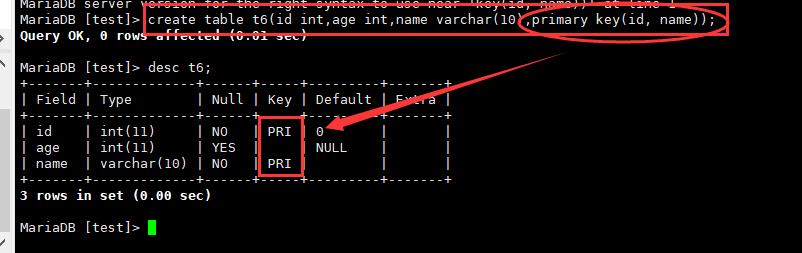
7.自增长:
我们设置列属性为自增长属性,当插入数据且不给该列数据赋值时,则系统会自动生成一个+1的数值赋值进去
auto_increment,针对于整型列进行设置的

8.唯一键:unique
1.定义为唯一键的列,数据不能重复,可以为空
2.一张表当中可以给多个列定义唯一键属性
3.唯一键属性+NOT NULL ,就能够满足当前列既不能为空也不能重复(相当于主键属性)
4.定义列为唯一键时也会为该列创建B+树

外键:foreign key 从表列名 references 主表列名
前提:给从表当中的某一列定义为外键属性时,外键属性的约束来自于主表的主键列
外键就是为了增加表和表之间的约束关系
8.数据库表的相关操作
针对表内容的操作
8.1 插入:insert
1.全列插入:
给表当中的所有字段进行插入

2.指定列插入:
选择给表当中的某些列进行插入数据
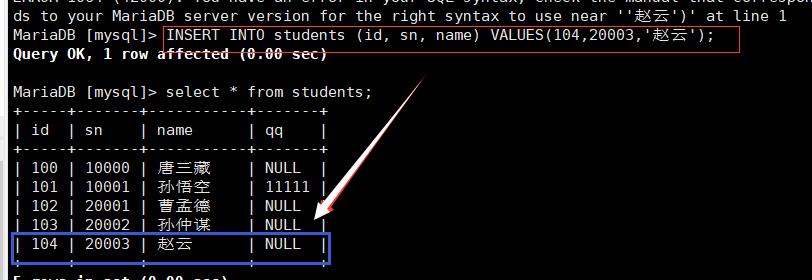
3.多行插入:
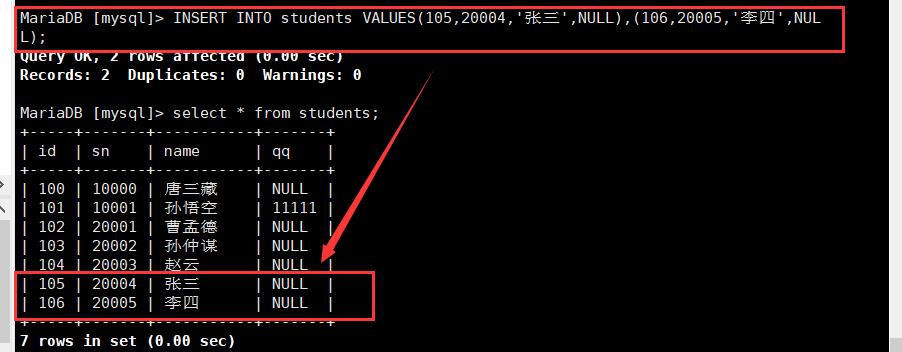
一次性插入多行
3.1全列插入多行
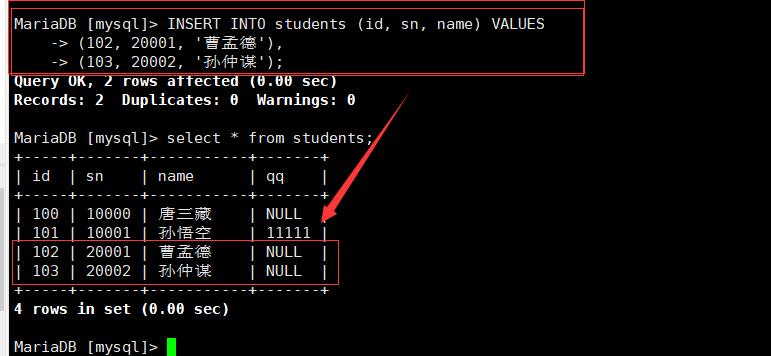
3.2指定列插入多行数据
8.2 替换:replace
1.替换表当中的数据
2.一定要有一列数据能够唯一标识这一行数据(主键/唯一键)
3.替换的时候,如果替换的数据和表当中的数据没有主键或者唯一键的冲突,则直接插入,如果有冲突,则将之前的数据先删除掉,再进行插入
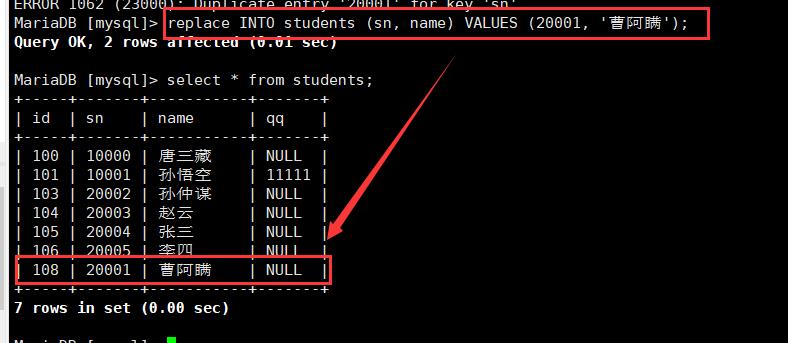
8.3 去重:DISTINCT
select distinct 列名 from 表名;
8.4 查找:select
1.全列检索
select * from [table_name]

2.指定列查找
select[字段名称1],「字段名称2] from [table_name]
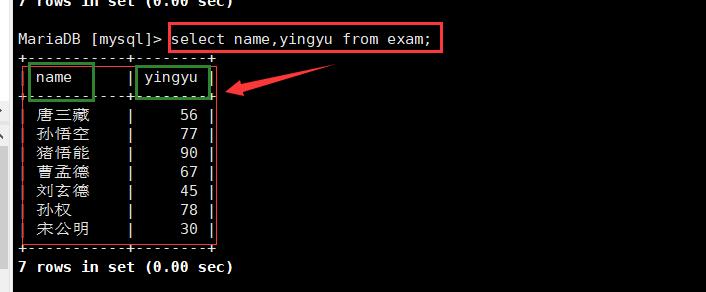
3.带有where约束子句的查找
where子句 : where字段名称 [运算符] [比较的值]
eg:查询数学成绩小于80分的同学的成绩和姓名

比较运算符

逻辑运算符

8.5 结果排序:order by
ASC 为升序(从小到大)
– DESC 为降序(从大到小)
– 默认为 ASC

多字段排序,排序优先级随书写顺序
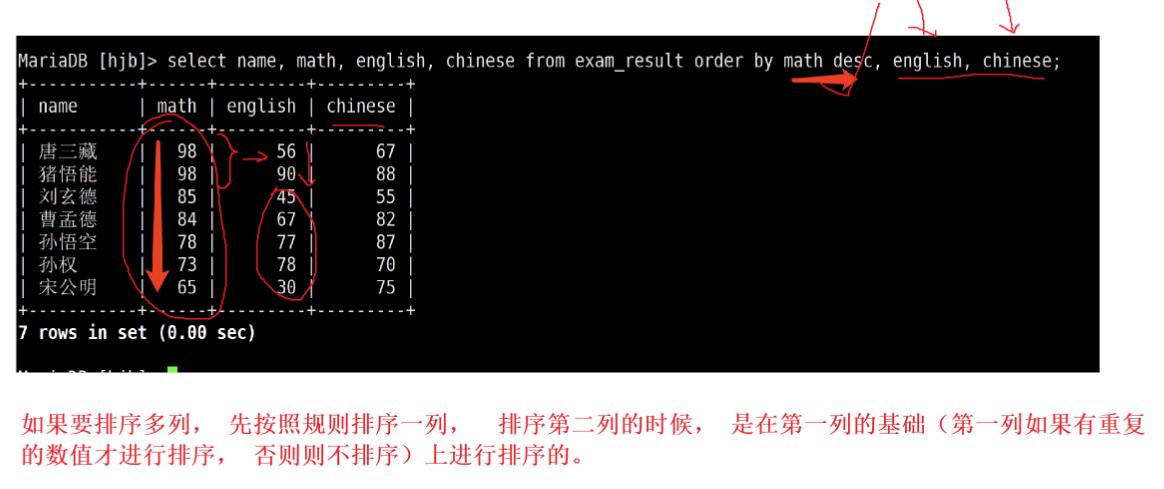
注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
8.6 筛选分页结果:limit
起始下标为 0
– 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
– 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
– 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET n;
8.7 更新:update
1.update [table_name] set[列名称]=[列的值] where ... order by ...

注意:在更新的sql语句当中没有 where进行约束,则会将更改的列对应的所有的行的值全部更新掉!!
如果我们更新完毕之后,在查询的时候,就不能按照之前的方式进行查询了。
因为原先的倒数前三名的数学成绩已经被增加了30;
如果在按照之前的方式进行查找之前的倒数前三名,有可能数据的排序是有变化
8.8 删除表数据:delete
只针对表数据,而不针对于表结构(删除表数据,不会删除表结构)
命令行范式: delete from [table] where [约束条件]
where框定要删除的数据

3.如何没有where条件框定要删除的行,则默认是全表删除!(慎用!! ! )
4.删除表数据不会重置(清空)auto_increment选项
8.9 截断表:truncate
不仅会将表数据清空(物理删除数据),也会将表结构重置
命令范式:truncate [table_name]
8.10 聚合函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的最小值,不是数字没有意义 |
count与sum区别
一句话概括就是Sum(列) 是求和,把所有列的值进行汇总求和;
COUNT(列) 是行数汇总,只要列的值不为Null,就会增加1;
8.11 分组查询:group by
场景:求每一个班级的最高分数以及平均分数
1.先按照某一个规则进行分组
2.分组完毕之后,针对分组的结果在进行聚合函数的使用
命令范式:select ..... +group by[某一列]:按照某一列的内容进行分组
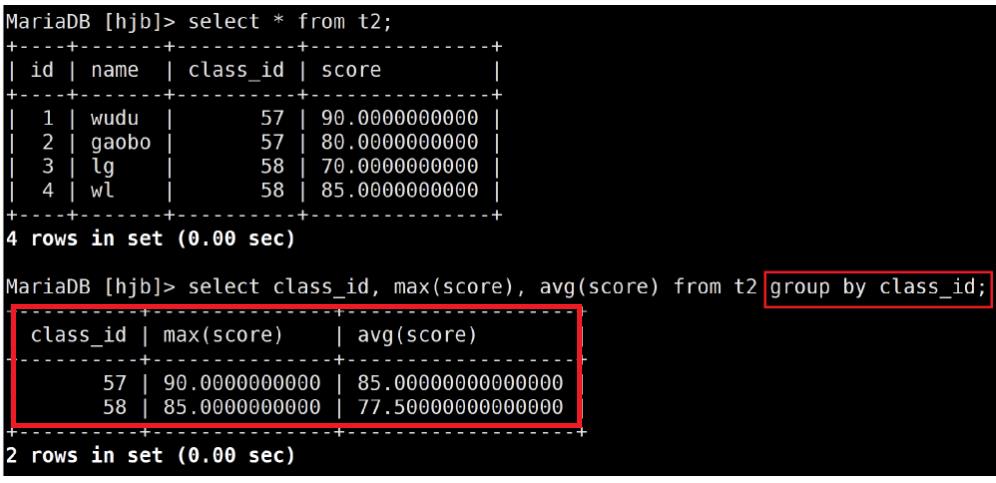
having和group by配合使用,对group by结果进行过滤,having在group by之后
8.12 函数部分
1 .日期函数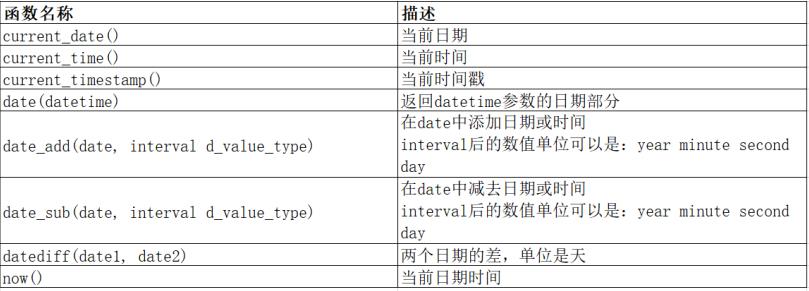
eg:获取当前时间:年-月-日
2. 字符串函数

**注意:length函数返回字符串长度,以字节为单位。**如果是多字节字符则计算多个字节数;如果是单字节字符则算作一个字节。比如:字母,数组算作一个字节,中文表示多个字节数(与字符集编码有关)
eg:显示exam表中的信息,显示格式:“XXX的语文是XXX分,数学XXX分,英语XXX分”

3.数学函数
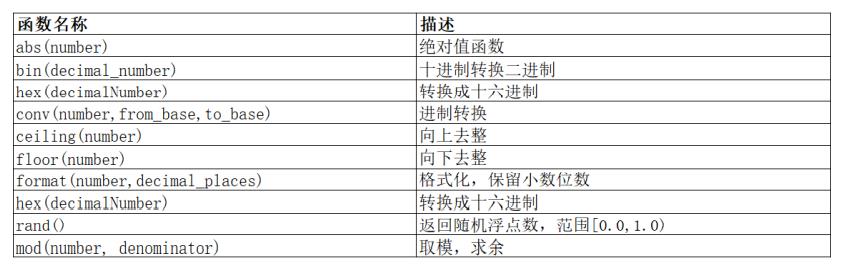
eg:产生随机数

4.其他函数
1.user() 查询当前用户
select user();
2.md5(str)对一个字符串进行md5摘要,摘要后得到一个32位字符串
select md5('admin')
3.database()显示当前正在使用的数据库
select database();
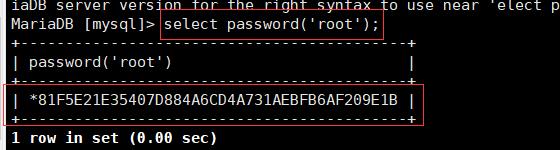
4.password()函数,MySQL数据库使用该函数对用户加密
select password('root');
5.ifnull(val1, val2) 如果val1为null,返回val2,否则返回val1的值
9.复合查询(重要)
1.多表查询
从多个表当中查询数据进行组合,形成笛卡尔积;
注意:如果多个表中存在字段名称相同的情况,那么在多表查询时,一定要指定相同字段名称的字段是属于哪一个表的
2.自连接
自连接是指在同一张表连接查询
3. 子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
3.1单行子查询:
返回一行记录的子查询
3.2多行子查询:
嵌套的select语句查询出来的结果是多行单列的
- in :只要满足多行单列结果当中的任意一个,则条件满足
- any :只要满足多行单列结果当中一个,则条件满足
- all :需要满足多行单列结果当中的所有
3.4合并查询:
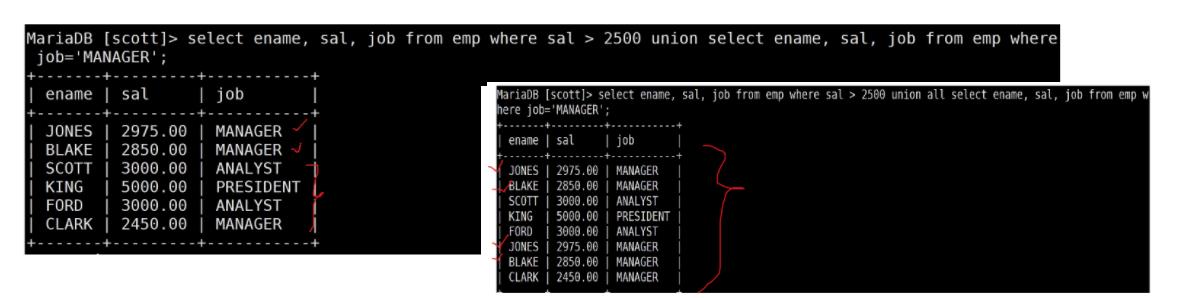
- 为了合并多个select的查询结果
union :将两个select查询出来的结果进行合并并且去重
union all :将两个select的查询结果直接合并起来
内外连接:
内连接
实际上就是利用where子句对两种表形成的笛卡儿积进行筛选
外连接
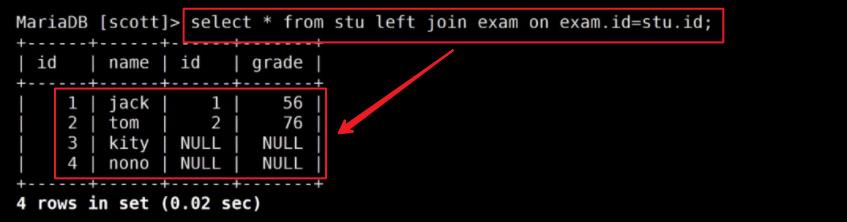
左外连接:多张表联合查询,左侧的表完全显示
命令范式:select * from [table1] left join [table2] on [约束条件]
完全展示的是左边表的内容table1
右外连接:多张表联合查询,右侧的表完全显示我们就说是,右外连接。
命令范式:select * from [table1] right join [table2] on [约束条件]
完全展示右边的表的内容table2

10.事务
事务就是一组DML语句,这些语句在逻辑上存在相关性,这一组DML语句要么全部成功,要么全部失败,是一个整体

1.SQL分类
DDL 【data definition language】数据定义语言,
用来维护存储数据的结构,代表指令:create,drop,alter
DML【data manipulation language】数据操纵语言
用来对数据进行操作,代表指令insert , delete, undate
DML中又单独分了一个DQL,数据查询语言,
代表指令:select
. DCL【data control language】数据控制语言
主要负责权限管理和事务,代表指令:grant,revoke,commit
- 事务作用:
保证了多个mysql的客户端在访问(插入,删除,检索,更新,替换)同一张表的时候,不会产生二义性。
事务的基本操作:
1.开启事务
start transaction;
回滚
2.创建保存点:
savepoint[保存点的名称]
3.回滚
rol1back to[保存点名称]
4.提交事务
commit
代码演示
mysql> start transaction; --开启事务
Query OK, 0 rows affected (0.00 sec)
mysql> savepoint aa; --设置保存点aa
Query OK, 0 rows affected (0.00 sec)
mysql> insert into account values(1, '张三', 10); --添加一条记录
Query OK, 1 row affected (0.00 sec)
mysql> savepoint bb; -- 设置保存点bb
Query OK, 0 rows affected (0.00 sec)
mysql> insert into account values(2, '李四', 10000); --再添加一条记录
Query OK, 1 row affected (0.00 sec)
mysql> select * from account; --两条记录都在了
+----+--------+----------+
| id | name | balance |
+----+--------+----------+
| 1 | 张三 | 10.00 |
| 2 | 李四 | 10000.00 |
+----+--------+----------+
2 rows in set (0.00 sec)
mysql> rollback to bb; -- 发现后来添加这一条记录是误操作。所以回滚到bb状态
Query OK, 0 rows affected (0.01 sec)
mysql> select * from account; -- 第二条记录没有了
+----+--------+---------+
| id | name | balance |
+----+--------+---------+
| 1 | 张三 | 10.00 |
+----+--------+---------+
1 row in set (0.03 sec)
事务操作的注意事项

事务的隔离级别
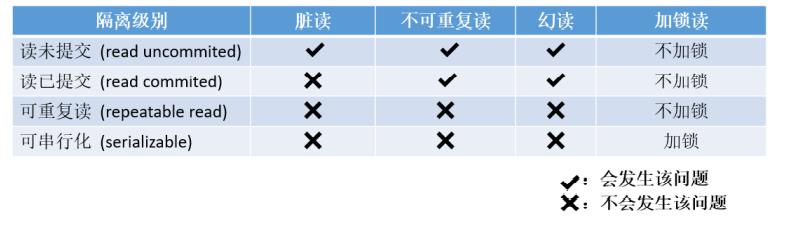
- 读未提交【Read Uncommitted】: 在该隔离级别,所有的事务都可以看到其他事务没有提交的执行结果。(实际生产中不可能使用这种隔离级别的),但是相当于没有任何隔离性,也会有很多并发问题,如脏读,幻读,不可重复读等。
- 读提交【Read Committed】∶ 该隔离级别是大多数数据库的默认的隔离级别〈不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看到其他的已经提交的事务所做的改变。这种隔离级别会引起不可重复读,即一个事务执行时,如果多次select,可能得到不同的结果。
- 可重复读【Repeatable Read】: 这是MySQL默认的隔离级别,它确保同一个事务,在执行中,多次读取操作数据时,会看到同样的数据行。但是会有幻读问题。
- 串行化【Serializable】: 这是事务的最高隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决了幻读的问题。它在每个读的数据行上面加上共享锁,。但是可能会导致超时和锁竞争(这种隔离级别太极端,实际生产基本不使用)
从上至下由弱至强
设置当前会话的隔离级别:
set session transaction isolation level [隔离级别];
查看当前的隔离级别:
select @@tx_isolation;
说明:mysql默认的隔离级别是可重复读,一般情况下不要修改
事务的ACID特性
- 原子性(Atomicity):
事务是应用中最小的执行单位,就如原子是自然界的最小颗粒,具有不可再分的特征一样,事务是应用中不可再分的最小逻辑执行体。 - 一致性(Consistency):
事务执行的结果,必须使数据库从一个一致性状态,变到另一个一致性状态。当数据库只包含事务成功提交的结果时,数据库处于一致性状态。如果系统运行发生中断,某个事务尚未完成而被迫中断,而改未完成的事务对数据库所做的修改已被写入数据库,此时数据库就处于一种不正确(不一致)的状态。因此一致性是通过原子性来保证的。 - 隔离性(Isolation):
各个事务的执行互不干扰,任意一个事务的内部操作对其他并发事务都是隔离的。也就是说,并发执行的事务之间不能看到对方的中间状态,并发执行的事务之间不能互相影响。 - 持久性(Durability):
持久性是指一个事务一旦被提交,它对数据库所做的改变都要记录到永久存储其中(如:磁盘)。
11. 索引特性(重点)
索引:提高数据库的性能,索引是物美价廉的东西了。不用加内存,不用改程序,不用调sql,只要执行正确的create index ,查询速度就可能提高成百上千倍。但是天下没有免费的午餐,查询速度的提高是以插入、更新、删除的速度为代价的,这些写操作,增加了大量的IO。所以它的价值,在于提高一个海量数据的检索速度。
常见索引分为:
-
主键索引(primary key)
在一张表当中将某列设置为主键属性,则会默认使用该列的数值,创建主键索引,索引底层就是B+树。当前字段的值和整条记录的关系当使用索引列作为约束条件查询数据的时候,则会先通过B+树找到整条记录的位置,然后直接返回;
创建主键有几种方式,创建主键索引也就有几种方式
1.直接在字段后指定primary key
2.所有字段之后,指定primary key (主键列)
3.alter关键字修改表,为表当中的某列增加主键属性,同时会为该列创建主键索引 -
唯一索引(unique)
当在表当中指定某列为唯一键的时候,则会创建一个唯一索引

-
普通索引(index)
如果某列需要创建索引,但是该列有重复的值,那么我们就应该使用普通索引 -
全文索引(fulltext)
当对文章字段或有大量文字的字段进行检索时,会使用到全文索引。MySQL提供全文索引机制,但是有要求,要求表的存储引擎必须是MyISAM,而且默认的全文索引支持英文,不支持中文。
基本原理
