Spring Data Commons主要梳理
Posted 老猫烧须
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring Data Commons主要梳理相关的知识,希望对你有一定的参考价值。
这篇文章是在看Spring Data Commons文档的时候梳理的内容,都是与Spring Data相关的,里面可能会涉及到Spring Data JPA的内容,但更多的是Commons的内容,Spring Data JPA只是一个具体的实现而已。
1. Spring Data 模块关系
Spring Data家族有多个模块:
- Spring Data JPA
- Spring Data Mongo
- …
但所有的模块都基于Spring Data Commoms模块进行扩展。例如Spring Data JPA是针对JPA做扩展的一个子模块;Spring Data Mongo是针对MongoDB的子模块,但是共同的接口都是Spring Data。
可以说Spring Data Commons是其所有子模块的抽象,定义了一系列的操作标准及接口。
2. 独立使用Spring Data
Spring Data提供了RepositoryFactory,可以独立于Spring容器之外使用:
RepositoryFactorySupport factory = … // Instantiate factory here
UserRepository repository = factory.getRepository(UserRepository.class);
3. Repository - dao - 存储仓库
在Spring Data中,都是基于存储仓库Repository对实体类对象进行CRUD操作的。
其中,最核心的是Repository接口,在org.springframework.data.repository包中定义。
Repository接口需要指定操作的实体类的类型、实体类ID的类型。在该接口中,是没有任何方法的,只是用于标记让Spring Data知道。
通常我们会使用CurdRepository这个接口,当然,这个接口也是不包含JPA特性的,我们需要使用JPA特性的话,一般用的是JpaRepository接口。
下面给出Spring Data JPA中,JpaRepository的继承结构:
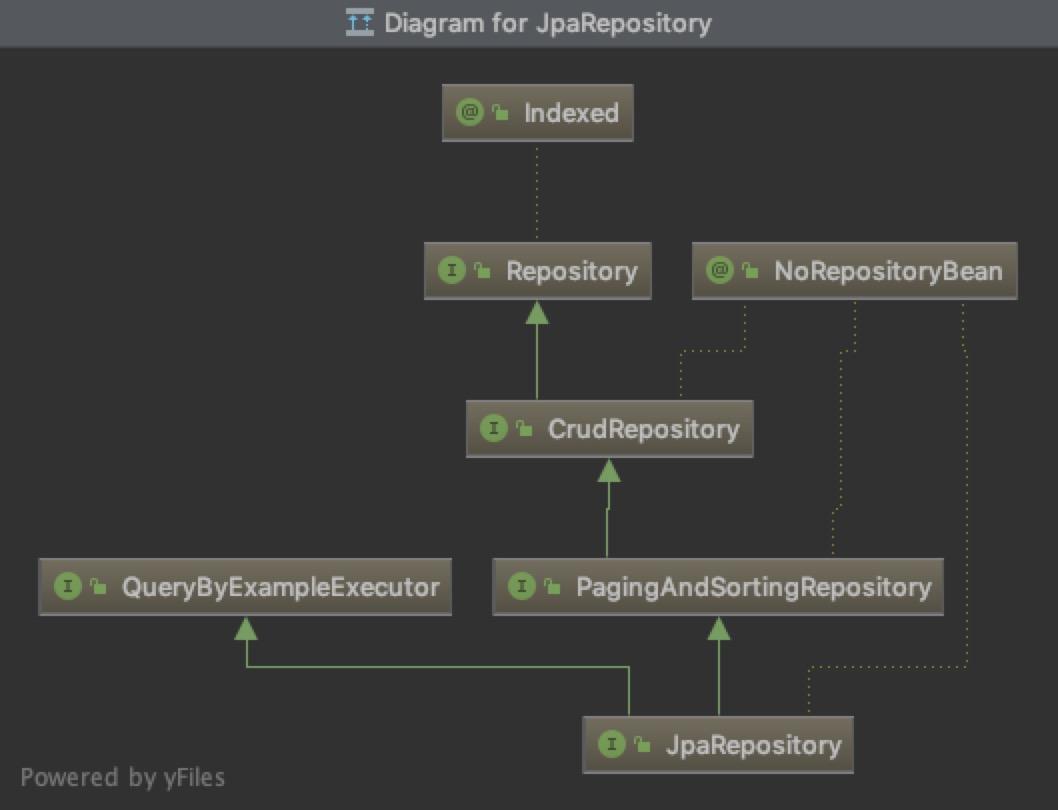
4. 使用指定Spring Data模块
上面一开始说了Spring Data有很多个不同的子模块,每个子模块对应一种数据存储方式或数据源,统称Spring Data *吧。
要让Spring Data在运行的时候知道我们使用哪个模块,就要进行指定,指定模块的方法有两种:
存储库使用Spring Data模块特定的接口指定类型实体类使用Spring Data模块模块特定的注解指定类型
如果都不指定,在单模块的情形下是不存在问题的,但是如果项目中引入了不同的Spring Data模块,那么Spring Data在实际运行中就无法确定到底需要使用哪个模块。
5. 查询方法的拆分
Spring Data以方法中的结构为findBy...、deleteBy...,其结构都是动词加上By,By是整个语句拆分的关键点。通常By后面跟着的是查询的参数列表,通过And、Or来连接。
在By后面的参数中,首先将整个内容作为一个属性,如果找不到,然后再参数中以大写字母为分割,直到找到对应的参数为止。
6. 分页查询、排序查询、限制查询、流式结果查询
6.1 排序查询
Spring Data接受使用Sort类型参数来进行排序查询的工作,Sort主要有两个参数构成:
- 排序方向:ASC(升序)、DESC(降序)
- 排序字段
6.2 分页查询参数
Pageable是Spring Data提供出来进行分页查询参数输入的接口,里面主要定义多个与页面设定的方法:
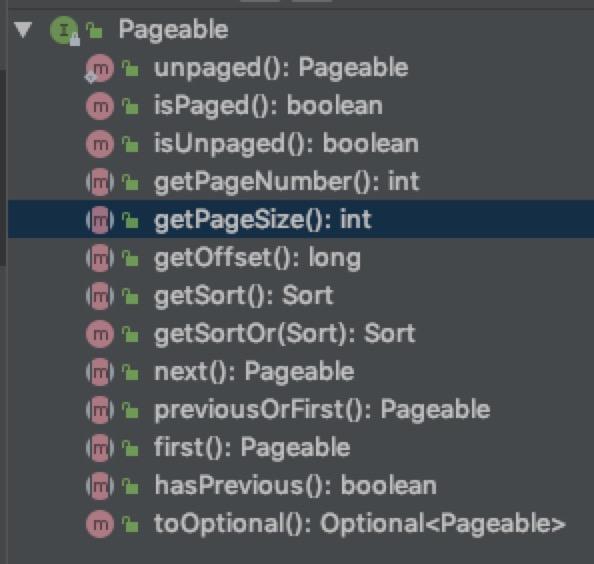
实现有很多,最常用的是PageRequest:
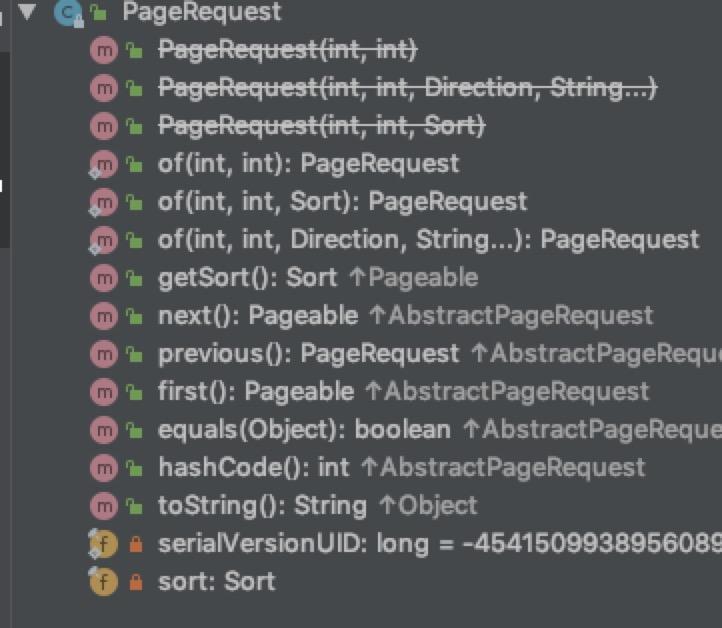
PageRequest废弃了原本的new方式来构建分页参数,建议使用类中提供的of(...)静态方法来创建相关的分页参数实体。
of(...)分页查询中允许带上排序字段以及排序方向两个参数,在源码中,这两个共同构建成了Sort实体。这是很多业务中需要使用上的,首先需要讲内容进行排序,然后再分页列出。
分页查询中,next()、previous()返回的分别是下一页、上一页的分页参数实体,
6.3 分页查询结果(返回值)
除了支持常用的集合List、Set等查询结果集作为分页查询结果,Spring Data还有以下几种结果:
Page<T>Slice<T>List<T>Set<T>
6.4 limit查询
在mysql中,我们需要获得前N个结果,使用limit关键字。
在Spring Data中可以使用:
topfirst
来进行限定最终的结果数,在top、first关键字后面可以加上数字表示最大结果大小,默认值为1:
User findFirstByUsername(String username)List<Article> findFirst10Bytitle(String title)
当然,这个是支持使用Pageable、Sort的。
6.5 流式查询结果
Spring Data支持使用Stram<T>流式API使用。
@Query("select u from User u")
Stream<User> findAllByCustomQueryAndStream();
Stream<User> readAllByFirstnameNotNull();
@Query("select u from User u")
Stream<User> streamAllPaged(Pageable pageable);
一般在try-with-resources中使用:
try (Stream<User> stream = repository.findAllByCustomQueryAndStream())
stream.forEach(…);
7. 自定义实现dao存储库
7.1 自定义存储库片段
都知道当使用Spring Data之后,大部分的CRUD操作我们都不需要去实现。但是当某些情况下,例如有些查询方法需要不同的行为或者无法通过Spring查询实现时,我们确实是要自己手动实现查询方法的。这种做法叫Repository fragments,存储库片段。
步骤如下:
- 做出一个自己的接口:
interface CustomizedUserRepository
void someCustomMethod(User user);
- 实现接口,就是很普通的接口实现
class CustomizedUserRepositoryImpl implements CustomizedUserRepository
public void someCustomMethod(User user)
// Your custom implementation
注:
- 上面的实现中,一定要以
Impl为结尾- 接口的实现可以作为一个普通的
Bean存在
- 让
*Repository存储库扩展(继承)这个接口:
interface UserRepository extends CrudRepository<User, Long>, CustomizedUserRepository
// Declare query methods here
注:
当有两个片段提供相同的方法和签名,那么将按照继承顺序覆盖。
但是别忘了,每个片段的实现
上面这种做法可以组合Spring Data提供的CURD以及自定义实现的接口。相对自由,但是也相对复杂。
注:
而且对于领域设计的角度来说,能不把业务放到dao层就千万不要这么做!!
7.2 使用命名空间来配置自定义存储库片段Bean
在XML和Java Config中的配置base-package,Spring Data的基础架构会在启动的时候到配置的路径下去扫描对应的存储库包,找到实现并配置为Bean。
因此,在上面说了实现片段需要后缀为Impl。
如果不是,可以通过repository-impl-postfix来配置对应的后缀,如:
<repositories base-package="com.acme.repository" repository-impl-postfix="MyPostfix" />
如果是使用Java Config:
@EnableJpaRepositories(basePackages = "cn.marer", repositoryImplementationPostfix = "DAO")
public class ....
后缀是可以配置多个的,不同的后缀就扫描不同的结果。
7.3 自定义BaseRepository - 基类
在Spring Data出现之前我们会使用BaseDao来实现一些基本的数据库的操作,现在也可以这样做:
class MyRepositoryImpl<T, ID extends Serializable>
extends SimpleJpaRepository<T, ID>
private final EntityManager entityManager;
MyRepositoryImpl(JpaEntityInformation entityInformation,
EntityManager entityManager)
super(entityInformation, entityManager);
// Keep the EntityManager around to used from the newly introduced methods.
this.entityManager = entityManager;
@Transactional
public <S extends T> S save(S entity)
// implementation goes here
注:
- 该类需要具有特定于商店的存储库工厂实现所使用的超类的构造函数。
- 如果存储库基类具有多个构造函数,则覆盖使用EntityInformation加号存储特定基础结构对象(例如,EntityManager模板类)的构造函数。
然后还需要在Java Config中指定存储库基类:
@Configuration
@EnableJpaRepositories(repositoryBaseClass = MyRepositoryImpl.class)
class ApplicationConfiguration …
这个就类似于为基类配置一个Bean。
8. 发布事件
直接官方机翻:
由存储库管理的实体是聚合根。在域驱动设计应用程序中,这些聚合根通常会发布域事件。Spring Data提供了一个注释@DomainEvents,可以在聚合根的方法上使用,以使该发布尽可能简单,如以下示例所示:
class AnAggregateRoot
@DomainEvents
Collection<Object> domainEvents()
// … return events you want to get published here
@AfterDomainEventPublication
void callbackMethod()
// … potentially clean up domain events list
使用的方法
@DomainEvents可以返回单个事件实例或事件集合。它不能使用任何参数。
在所有事件发布后,我们有一个注释的方法@AfterDomainEventPublication。它可用于潜在地清除要发布的事件列表(以及其他用途)。
9. Spring Data对Spring MVC支持
9.1 打开Spring data对web的支持
Spring Data提供了对web的友好支持,特别是下面将说到的领域类型(可以先看作实体类)转换的支持以及分页、排序的支持,要打开支持,有两种方式:
- Java Config
- XML
还是比较推荐使用Java Config的方式,毕竟Spring Boot大多数都是注解形式嘛:
@EnableSpringDataWebSupport
piublic class WebConfiguration
...
XML开启:
<bean class="org.springframework.data.web.config.SpringDataWebConfiguration" />
按照官方文档,如果打开了这个支持,Spring会自动配置了下面三个Bean:
-
DomainClassConverter- 允许在不用通过存储库手动查找的情况下,直接在SpringMVC的控制器方法的签名(参数)中直接使用领域对象 -
PageableHandlerMethodArgumentResolver- 允许通过请求参数将Pageable对象注入到controller方法参数 Pageable中 -
SortHandlerMethodArgumentResolver- 允许通过请求参数将Sort对象注入到controller方法参数 Sort中
9.2 DomainClassConverter - 领域类型转换器支持
DomainClassConverter可以在不用通过存储库手动查找的情况下,直接在SpringMVC的控制器方法的签名(参数)中直接使用领域对象。
需要按照上面的两种方式其中一个打开对web的支持。
现在假定有User这个领域对象和UserRepository这个存储库,那么可以直接使用:
@RestController
public class UserController
@PostMapping("/user/info/id")
public User getUserInfo(@PathVariable("id") User user)
logger.info("Get user info By Spring data web support");
return user;
上面方法中,并没有通过UserRepository存储库对象来获取相对应的用户数据。
SpringMVC将提交上来的参数id通过@PathVariable获得ID,然后调用findById(...)查找出对应的实体并注入到方法参数中。所以可以直接通过返回User参数,算是偷懒方式。
注意:
- 领域类型对应的存储库最起码是要实现
CurdRepository才可以实现这个功能,- 如果找不到数据,会返回
500 Internal Server Error,需要对数据做校验或者做异常处理。
9.3 HandlerMethodArgumentResolvers - 分页、排序的支持
在上面说了,需要让Spring Data支持分页或排序功能,就需要在存储库Repository接口方法中传入Pageable或Sort对象,Pageable分页的对象里面也包含了Sort排序。Spring Data会自动解析并对分页、排序进行limit、order by查询。
而Spring Data也对web提供了分页、排序的支持,让我们可以在访问http提交请求参数的时候直接将pageable、sort参数注入到controller的方法参数。
主要是配置了@EnableSpringDataWebSupport后,Spring Data会生成PageableHandlerMethodArgumentResolver、SortHandlerMethodArgumentResolver两个Bean实例。在我们的Controller的方法中加入参数即可:
@RestController
public class UserController
@GetMapping("/user/info/all/page")
public List<User> getAllUserPage(Pageable pageable)
logger.info(“try to find user with pageable.”);
return userRepository.findAll(pageable).getContent();
在上面的例子中,要做的是:分页显示用户。使用了Pageable作为例子,因为我们知道Pageable里面包含了Sort,因此Sort的例子在这里就不再叙述了。
上面的例子里面,提交的参数为:
- page - 第几页,默认为0
- size - 页面数据数量,默认为20
- sort - 排序方向,默认为升序
ASC
假设:查询第一页的用户并根据用户名降序排序,页面大小为15。则请求API如下:
/user/info/all/page?page=0&size=15&sort=username,DESC
注意:
上面这个例子是GET请求方法的,如果是POST请求方法,请把请求参数放到请求体里面
更多关于Spring Data对Web支持请移步到:
https://docs.spring.io/spring-data/jpa/docs/2.1.3.RELEASE/reference/html/#core.web
此文同时在简书发布:https://www.jianshu.com/p/cb5a3ab2727e
此文同时在CSDN发布:https://blog.csdn.net/nthack5730/article/details/84939027
转载要加原文链接!谢谢支持!
以上是关于Spring Data Commons主要梳理的主要内容,如果未能解决你的问题,请参考以下文章