GRAPH ATTENTION NETWORKS 论文/GAT学习笔记
Posted Dodo·D·Caster
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GRAPH ATTENTION NETWORKS 论文/GAT学习笔记相关的知识,希望对你有一定的参考价值。
背景
目标:适用不同结构的图的模型
图卷积
- 基于谱的方法 :
- 这些方法学习得到的filters基于拉普拉斯特征基,而拉普拉斯特征基又基于图结构,所以在特定结构上训练的模型不能直接应用到具有不同结构的图。
- 代表:GCN
- 不基于谱的方法 :
- 直接在图上定义卷积 (对空间上近邻的群体使用),但是很难定义能够同时作用于不同数量领域并且保持CNNs权重共享特性的方法
- 代表:graphsage
注意力机制:可以处理可变大小的输入,专注于输入中最相关的部分来做出决定
- 可以跨节点邻居对并行计算,非常高效
- 可以通过为邻居指定任意权重来适用于具有不同度的图节点
- 适用于inductive学习方法
所以作者提出了基于注意力机制的方法来完成节点分类任务。其基本思想为:通过关注节点的邻居并遵循self-attention策略来计算图中每个节点的隐藏表征。
GAT架构
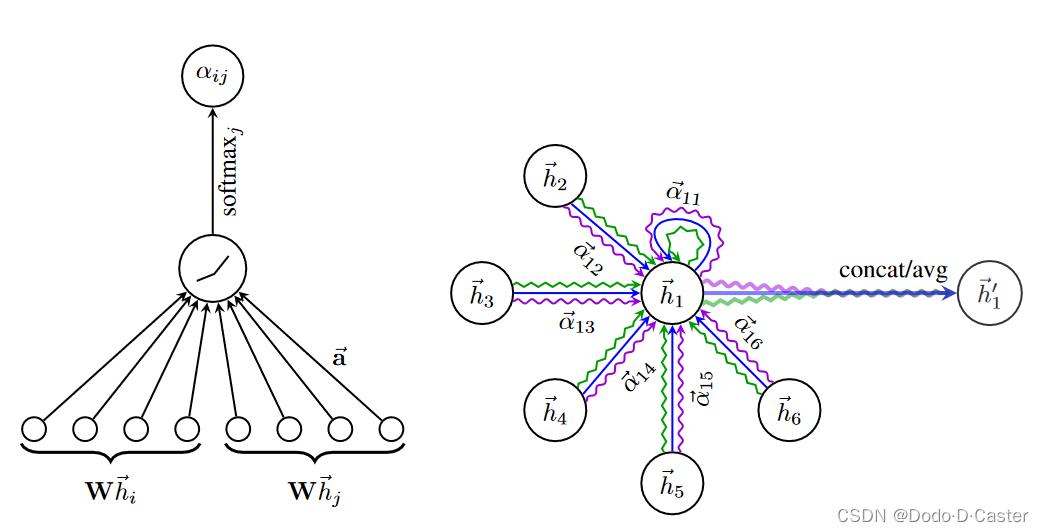
输入: h = h 1 ⃗ , h 2 ⃗ , . . . , h N ⃗ , h i ⃗ ∈ R F h = \\ \\vech_1, \\vech_2, ..., \\vech_N \\, \\vech_i \\in \\R ^F h=h1,h2,...,hN,hi∈RF
输出: h ′ = h 1 ′ ⃗ , h 2 ′ ⃗ , . . . , h N ′ ⃗ , h i ′ ⃗ ∈ R F ′ h' = \\ \\vech_1', \\vech_2', ..., \\vech_N' \\, \\vech_i' \\in \\R ^F' h′=h1′,h2′,...,hN′,hi′∈RF′
- N :节点数
- F :节点特征数
注意力系数 (attention coefficients) 代表节点 j 的特征对节点 i 的重要程度,其计算公式为:
e i j = a ( W h i ⃗ , W h j ⃗ ) e_ij = a (W \\vech_i, W \\vech_j ) eij=a(Whi,Whj)
- a : 一个共享的注意力机制 R F ′ × R F ′ → R \\R ^F' \\times \\R ^F' \\rightarrow \\R RF′×RF′→R
- W : 权重矩阵 W ∈ R F ′ × F W \\in \\R ^F' \\times F W∈RF′×F
标准化注意力系数:
α i j = s o f t m a x j ( e i j ) = e x p ( e i j ) ∑ k ∈ N i e x p ( e i k ) \\alpha _ij = softmax_j(e_ij)=\\fracexp(e_ij)\\sum _k \\in \\mathcalN _i exp(e_ik) αij=softmaxj(eij)=∑k∈Niexp(eik)exp(eij)
计算下一层特征:
h ⃗ i ′ = σ ( ∑ j ∈ N i α i j W h ⃗ j ) \\vech_i' = \\sigma (\\sum_j\\in \\mathcalN_i \\alpha _ij W \\vech_j ) hi′=σ(j∈Ni∑αijWhj)
使用multi-head attention来让学习过程更稳定:
h ⃗ i ′ = ∥ k = 1 K σ ( ∑ j ∈ N i α i j k W k h ⃗ j ) \\vech_i' = \\parallel _k=1^K \\sigma (\\sum_j\\in \\mathcalN_i \\alpha _ij^k W ^k\\vech_j ) hi′=∥k=1Kσ(j∈Ni∑αijkWkhj)
- ∣ ∣ || ∣∣ : 表示连接操作
- α i j k \\alpha _ij^k αijk : 表示由第k个注意力机制 a k a^k ak 计算的标准化注意力机制系数
- W k W^k Wk : 相应输入线性变化的权重矩阵
- h ′ h' h′ 会有 K F ′ K F'