大数据Scala学习—列表 集与映射
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Scala学习—列表 集与映射相关的知识,希望对你有一定的参考价值。
▼Scala系列学习笔记:
- Scala概述与开发环境配置
- Scala基础学习之运算符
- Scala基础学习之for循环和while循环
- 一文掌握scala中的方法和函数
- Scala基础:类和对象、访问修饰符和构造器
- Scala的继承和抽象类
- Scala基础语法之Trait详解
- Scala学习之数组与元组
一、列表
列表(List)是Scala中最重要的, 也是最常用的一种数据结构。它存储的数据, 特点是: 有序, 可重复。
在Scala中,列表分为两种, 即: 不可变列表和可变列表。
解释:
1. 有序 的意思并不是排序, 而是指 元素的存入顺序和取出顺序是一致的
2. 可重复 的意思是 列表中可以添加重复元素
1.1 不可变列表
1.1.1 特点
不可变列表指的是: 列表的元素、长度都是不可变的。
1.1.2 语法

1.2.2 示例
需求
1. 创建一个不可变列表,存放以下几个元素(1,2,3,4)
2. 使用 Nil 创建一个不可变的空列表
3. 使用 :: 方法创建列表,包含-2、-1两个元素

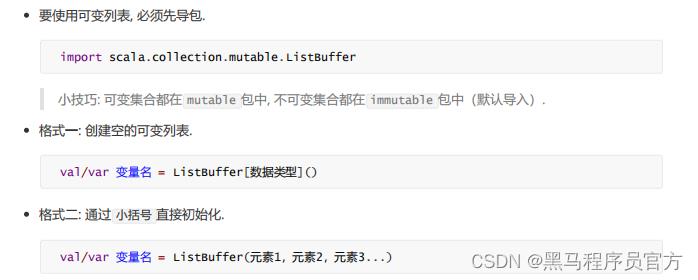
1.2 可变列表
1.2.1 特点
可变列表指的是列表的元素、长度都是可变的.
1.2.2 语法
1.2.3 示例
需求
1. 创建空的整形可变列表.
2. 创建一个可变列表,包含以下元素:1,2,3,4
参考代码


1.2.4 可变列表的常用操作
关于可变列表的常见操作如下:
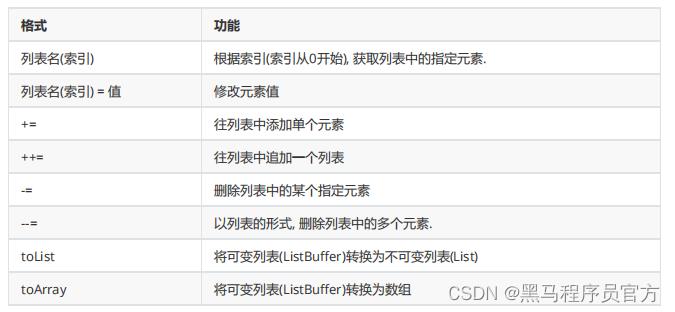
示例
1. 定义一个可变列表包含以下元素:1,2,3
2. 获取第一个元素, 并打印结果到控制台.
3. 添加一个新的元素:4
4. 追加一个列表,该列表包含以下元素:5,6,7
5. 删除元素7
6. 删除元素3, 4
7. 将可变列表转换为不可变列表
8. 将可变列表转换为数组
9. 打印结果


1.3 列表的常用操作
1.3.1 格式详解
在实际开发中, 我们经常要操作列表, 以下列举的是列表的常用的操作 :

1.3.2 示例一: 基础操作
需求
1. 定义一个列表list1,包含以下元素:1,2,3,4
2. 使用isEmpty方法判断列表是否为空, 并打印结果.
3. 再定义一个列表list2,包含以下元素: 4,5,6
4. 使用 ++ 将两个列表拼接起来, 并打印结果.
5. 使用head方法,获取列表的首个元素, 并打印结果.
6. 使用tail方法,获取列表中除首个元素之外, 其他所有的元素, 并打印结果.
7. 使用reverse方法将列表的元素反转, 并打印反转后的结果.
8. 使用take方法获取列表的前缀元素, 并打印结果.
9. 使用drop方法获取列表的后缀元素, 并打印结果.


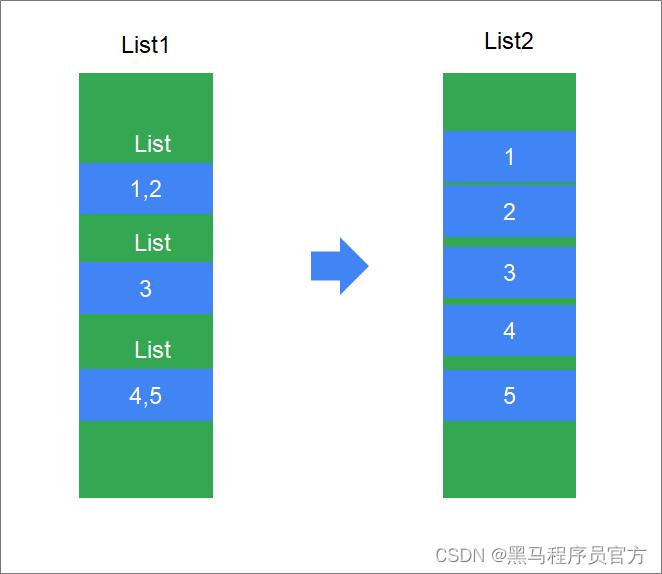
1.3.3 示例二: 扁平化(压平)
概述
扁平化表示将嵌套列表中的所有具体元素单独的放到一个新列表中. 如下图:
注意: 如果某个列表中的所有元素都是列表, 那么这样的列表就称之为: 嵌套列表
需求
1. 定义一个列表, 该列表有三个元素, 分别为:List(1,2)、List(3)、List(4,5)
2. 使用flatten将这个列表转换为List(1,2,3,4,5)
3. 打印结果

1.3.4 示例三: 拉链与拉开
概述
拉链:将两个列表,组合成一个元素为元组的列表
解释: 将列表List("张三", "李四"), List(23, 24)组合成列表List((张三,23), (李四,24))
拉开:将一个包含元组的列表,拆解成包含两个列表的元组
需求 1. 定义列表 names, 保存三个学生的姓名,分别为:张三、李四、王五 2. 定义列表 ages, 保存三个学生的年龄,分别为: 23, 24, 25 3. 使用 zip 将列表 names 和 ages, 组合成一个元素为元组的列表 list1 4. 使用 unzip 将列表 list1 拆解成包含两个列表的元组 tuple1 5. 打印结果 参考代码解释: 将列表List((张三,23), (李四,24))拆解成元组(List(张三, 李四),List(23, 24))

1.3.5 示例四: 列表转字符串
概述
将列表转换成其对应的字符串形式, 可以通过 toString方法或者mkString方法 实现, 其中
- toString方法: 可以返回List中的所有元素
- mkString方法: 可以将元素以指定分隔符拼接起来。
注意: 默认没有分隔符
需求 1. 定义一个列表,包含元素: 1,2,3,4 2. 使用 toString 方法输出该列表的元素 3. 使用 mkString 方法 , 用冒号将元素都拼接起来 , 并打印结果. 参考代码
3.3.6 示例五: 并集, 交集, 差集
概述 操作数据时, 我们可能会遇到求并集, 交集, 差集的需求, 这是时候就要用到union, intersect, diff这些方法了, 其中
- union: 表示对两个列表取并集,而且不去重
例如: list1.union(list2), 表示获取list1和list2中所有的元素(元素不去重).
如果想要去除重复元素, 则可以通过 distinct 实现.
- intersect: 表示对两个列表取交集
例如: list1.intersect(list2), 表示获取list1, list2中都有的元素.
- diff: 表示对两个列表取差集.
例如:list1.diff(list2),表示获取list1中有, 但是list2中没有的元素.
需求
1. 定义列表 list1 ,包含以下元素: 1,2,3,4 2. 定义列表 list2 ,包含以下元素: 3,4,5,6 3. 使用 union 获取这两个列表的并集 4. 在第三步的基础上 , 使用 distinct 去除重复的元素 5. 使用 intersect 获取列表 list1 和 list2 的交集 6. 使用 diffff 获取列表 list1 和 list2 的差集 7. 打印结果 参考代码

二、集
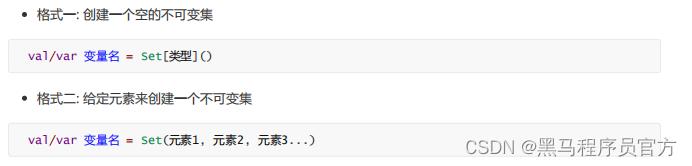
2.1 概述 Set( 也叫 : 集 ) 代表没有重复元素的集合 。特点是 : 唯一 , 无序 Scala中的集分为两种,一种是不可变集,另一种是可变集。解释 : 1. 唯一 的意思是 Set 中的元素具有唯一性 , 没有重复元素 2. 无序 的意思是 Set 集中的元素 , 添加顺序和取出顺序不一致2.2 不可变集 不可变集指的是 元素 , 集的长度都不可变 . 2.2.1 语法
 2.2.2
示例一
:
创建不可变集
需求
1.
定义一个空的整型不可变集
.
2.
定义一个不可变集,保存以下元素:
1,1,3,2,4,8.
3.
打印结果
.
参考代码
2.2.2
示例一
:
创建不可变集
需求
1.
定义一个空的整型不可变集
.
2.
定义一个不可变集,保存以下元素:
1,1,3,2,4,8.
3.
打印结果
.
参考代码
 2.2.3
示例二
:
不可变集的常见操作
格式
1.
获取集的大小(
size
)
2.
遍历集(
和遍历数组一致
)
3.
添加一个元素,生成一个新的
Set
(
+
)
4.
拼接两个集,生成一个新的
Set
(
++
)
5.
拼接集和列表,生成一个新的
Set
(
++
)
2.2.3
示例二
:
不可变集的常见操作
格式
1.
获取集的大小(
size
)
2.
遍历集(
和遍历数组一致
)
3.
添加一个元素,生成一个新的
Set
(
+
)
4.
拼接两个集,生成一个新的
Set
(
++
)
5.
拼接集和列表,生成一个新的
Set
(
++
)
需求 1. 创建一个集,包含以下元素: 1,1,2,3,4,5 2. 获取集的大小 , 并打印结果 . 3. 遍历集,打印每个元素 . 4. 删除元素 1 ,生成新的集 , 并打印 . 5. 拼接另一个集 Set(6, 7, 8), 生成新的集 , 并打印 . 6. 拼接一个列表 List(6,7,8, 9), 生成新的集 , 并打印. 参考代码注意:
1. - ( 减号 ) 表示删除一个元素 , 生成一个新的 Set 2. -- 表示批量删除某个集中的元素 , 从而生成一个新的 Set



三、映射
映射指的就是 Map 。它是由键值对 (key, value) 组成的集合。特点是 : 键具有唯一性 , 但是值可以重复 . 在 Scala中, Map 也分为不可变 Map 和可变 Map。注意 : 如果添加重复元素 ( 即 : 两组元素的键相同 ), 则 会用新值覆盖旧值
3.1 不可变Map
不可变 Map 指的是 元素 , 长度都不可变 . 语法 需求
1.
定义一个映射,包含以下学生姓名和年龄数据
:
张三
-> 23,
李四
-> 24,
李四
-> 40
2. 打印结果.
参考代码
需求
1.
定义一个映射,包含以下学生姓名和年龄数据
:
张三
-> 23,
李四
-> 24,
李四
-> 40
2. 打印结果.
参考代码

3.2 可变Map
特点 可变 Map 指的是 元素 , 长度都可变 . 定义语法与不可变 Map 一致 , 只不过需要先手动导包 : import scala.collection.mutable.Map 需求 1. 定义一个映射,包含以下学生姓名和年龄数据 : 张三 -> 23, 李四 -> 24 2. 修改张三的年龄为 30 3. 打印结果 参考代码
3.3 Map基本操作
格式 1. map(key) : 根据键获取其对应的值 , 键不存在返回 None. 2. map.keys : 获取所有的键 . 3. map.values : 获取所有的值 . 4. 遍历 map 集合 : 可以通过普通 for 实现 . 5. getOrElse: 根据键获取其对应的值 , 如果键不存在 , 则返回指定的默认值 . 6. + 号 : 增加键值对 , 并生成一个新的 Map. 注意 : 如果是可变 Map, 则可以通过 += 或者 ++= 直接往该可变 Map 中添加键值对元素 . 7. - 号 : 根据键删除其对应的键值对元素 , 并生成一个新的 Map. 注意 : 如果是可变 Map, 则可以通过 - = 或者 -- = 直接从该可变 Map 中删除键值对元素. 示例 1. 定义一个映射,包含以下学生姓名和年龄数据 : 张三 -> 23, 李四 -> 24 2. 获取张三的年龄 , 并打印 . 3. 获取所有的学生姓名 , 并打印 . 4. 获取所有的学生年龄 , 并打印 . 5. 打印所有的学生姓名和年龄 . 6. 获取 王五 的年龄,如果 王五 不存在,则返回 -1, 并打印 . 7. 新增一个学生:王五 , 25, 并打印结果 . 8. 将 李四 从可变映射中移除 , 并打印. 参考代码

以上是关于大数据Scala学习—列表 集与映射的主要内容,如果未能解决你的问题,请参考以下文章