REDIS09_HyperLogLog的概述基本命令UVPVDAUMAU首页UV如何进行统计处理
Posted 所得皆惊喜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了REDIS09_HyperLogLog的概述基本命令UVPVDAUMAU首页UV如何进行统计处理相关的知识,希望对你有一定的参考价值。
文章目录
①. 什么是UV、PV、DAU、MAU
-
①. UV:Unique Visitor,独立访客,一般理解为客户端IP(需要去重考虑)
-
②. PV:Page View,页面浏览量(不用去重)
-
③. DAU:日活跃用户量(登录或者使用了某个产品的用户数(去重复登录的用户))
-
④. MAU:MonthIy Active User,月活跃用户量
②. HyperLogLog的概述
- ①. 在Redis里面,每个HyperLogLog的键只需要花费12kb内存,就可以计算接近2^64个不同元素的基数

- ②. 去重复统计功能的基数估计算法-就是HyperLogLog
(用于统计一个集合中不重复的元素个数,就是对集合去重复后剩余元素的计算)
全集i=1,2,3,4,5,6,7,8,8,9,9,5
去掉重复的内容
基数=1,2,3,4,5,6,7,8,9
- ③. 有误差,非精确统计,牺牲准确率来换取空间,误差仅仅只是0.81%左右
这个误差如何来的?论文地址和出处,Redis之父安蒂雷斯回答

③. 去重复统计你先会想到哪些方式?
- ①. 使用HashSet进行去重处理
List<String> list=new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
list.add("c");
list.add("d");
HashSet<String>hashSet=new HashSet<>(list);
// a,b,c,d
System.out.println(hashSet);
- ②. 如果数据显较大亿级统计,使用bitmaps同样会有这个问题
- 基数计数则将每一个元素对应到bit数组中的其中一位,比如bit数组010010101(按照从零开始下标,有的就是1、4、6、8)
- 设一个样本案例就是一亿个基数位值数据,一个样本就是一亿
- 如果要统计1亿个数据的基数位值,大约需要内存100000000/8/1024/1024约等于12M,内存减少占用的效果显著。这样得到统计一个对象样本的基数值需要12M
- 如果统计10000个对象样本(1w个亿级),就需要117.1875G将近120G,可见使用bitmaps还是不适用大数据量下(亿级)的基数计数场景
- 但是bitmaps方法是精确计算的
- ③. 概率算法:
- 通过牺牲准确率来换取空间,对于不要求绝对准确率的场景下可以使用,因为概率算法不直接存储数据本身
- 通过一定的概率统计方法预估基数值,同时保证误差在一定范围内,由于又不储存数据故此可以大大节约内存
- HyperLogLog就是一种概率算法的实现
④. HyperLogLog的指令
- ①. HyperLogLog的基本指令
| 命令 | 作用 |
|---|---|
| pfadd key element | 将所有元素添加到key中 |
| pfcount key | 统计key的估算值(不准确) |
| pgmerge new_key key1 key2 | 合并key至新key |
- ②. 指令演示
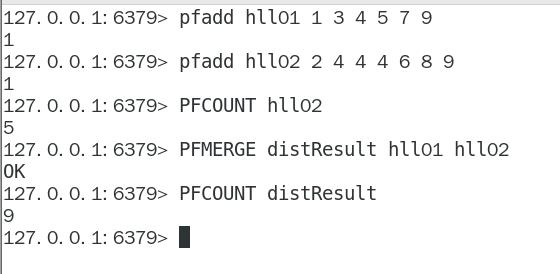
⑤. 首页UV的Redis统计方案
- ①. 需求:UV的统计需要去重
- 淘宝、天猫首页的UV,平均每天是1~1.5个亿左右
- 每天存1.5个亿的IP,访问者来了后先去查是否存在,不存在加入
- 一个用户一天内的多次访问只能算作一次
- ②. 方案讨论
- mysql,数据库巨大
- 用redis的hash结构存储 - redis——hash = <keyDay,<ip,1>>
按照ipv4的结构来说明,每个ipv4的地址最多是15个字节(ip = “192.168.111.1”,最多xxx.xxx.xxx.xxx)
某一天的1.5亿 * 15个字节= 2G,一个月60G,数据量巨大

- hyperloglog
为什么是12Kb?每个桶取6位,16384*6÷8 = 12kb,每个桶有6位,最大全部都是1,值就是63

- ③. 代码展示
@Service
@Slf4j
public class HyperLogLogService
@Resource
private RedisTemplate redisTemplate;
/**
* 模拟有用户来点击首页,每个用户就是不同的ip,不重复记录,重复不记录
*/
@PostConstruct
public void init()
log.info("------模拟后台有用户点击,每个用户ip不同");
//自己启动线程模拟,实际上产不是线程
new Thread(() ->
String ip = null;
for (int i = 1; i <=200; i++)
Random random = new Random();
ip = random.nextInt(255)+"."+random.nextInt(255)+"."+random.nextInt(255)+"."+random.nextInt(255);
Long hll = redisTemplate.opsForHyperLogLog().add("hll", ip);
log.info("ip=,该ip访问过的次数=",ip,hll);
//暂停3秒钟线程
try TimeUnit.SECONDS.sleep(3); catch (InterruptedException e) e.printStackTrace();
,"t1").start();
@RestController
@Slf4j
public class HyperLogLogController
@Resource
private RedisTemplate redisTemplate;
@ApiOperation("获得ip去重复后的首页访问量,总数统计")
@RequestMapping(value = "/uv",method = RequestMethod.GET)
public long uv()
//pfcount
return redisTemplate.opsForHyperLogLog().size("hll");
以上是关于REDIS09_HyperLogLog的概述基本命令UVPVDAUMAU首页UV如何进行统计处理的主要内容,如果未能解决你的问题,请参考以下文章