神经网络激活函数随机初始化
Posted 劳埃德·福杰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络激活函数随机初始化相关的知识,希望对你有一定的参考价值。
1.双层神经网络

计算神经网络层数的时候不包括输入层。
2.逻辑回归的神经网络如何实现
隐藏单元如何计算?


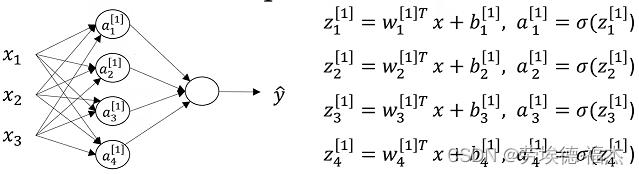
 ,3x1矩阵
,3x1矩阵
 ,3x1矩阵,上标[1]表示第一层
,3x1矩阵,上标[1]表示第一层
向量化(单个训练样本):
隐藏层: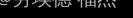 ,
, ,
, 为4x3矩阵,x为3x1矩阵,
为4x3矩阵,x为3x1矩阵, 为4x1矩阵,
为4x1矩阵, 为4x1矩阵
为4x1矩阵
输出层: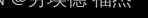 ,
, ,
, 为1x4矩阵,
为1x4矩阵, 为4x1矩阵,
为4x1矩阵, 为1x1矩阵,
为1x1矩阵, 为1x1矩阵
为1x1矩阵
向量化(m个训练样本,n个输入特征,隐藏层有k个神经元):
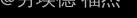 ,
, ,
, ,
,
为kxn矩阵,X为nxm矩阵,为kxm矩阵, 为kxm矩阵...
为kxm矩阵...
3.激活函数
①sigmoid函数

一般只在二元分类的输出层会用到,因为它值域为[0,1],预测某个物体的概率的取值范围也是[0,1]
②tanh函数
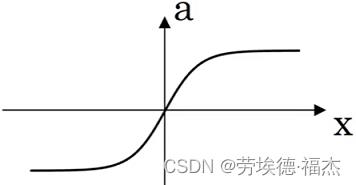
 ,值域为[-1,1]
,值域为[-1,1]
③Relu(Rectified linear unit修正线性单元)
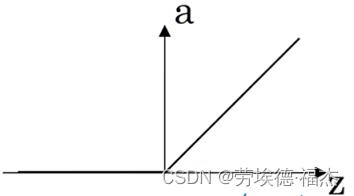

sigmoid函数和tanh函数的缺点在于:当z很大或很小时,导数的梯度(函数的斜率)接近0,会拖慢梯度下降算法。通常隐藏层的激活函数都用Relu,Relu的缺点是z<0时,导数为0。
④leak Relu(带泄露的Relu)
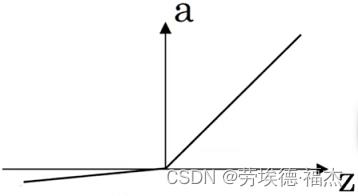
a=max(0.01z,z)
比Relu更好,但是不常用。
4.随机初始化(Random initialization)
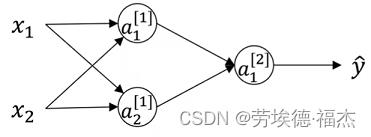
为什么要随机初始化参数?
假设参数都一样,比如 ,
, 。那么,隐藏单元都在做同样的运算,弄这么多隐藏单元就没有必要了。
。那么,隐藏单元都在做同样的运算,弄这么多隐藏单元就没有必要了。
随机初始化:
 =np.random.randn((2,2))*0.01,=np.zero((2,1)),[1]上标表示第一层
=np.random.randn((2,2))*0.01,=np.zero((2,1)),[1]上标表示第一层
为什么乘0.01,不乘100?
 ,
,
乘0.01目的是让尽可能小,如果很大,代入tanh函数时,导数的斜率(梯度)就很小,那么梯度下降法下降的速度就很慢。
以上是关于神经网络激活函数随机初始化的主要内容,如果未能解决你的问题,请参考以下文章