超参数划分数据集偏差与方差正则化
Posted 劳埃德·福杰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超参数划分数据集偏差与方差正则化相关的知识,希望对你有一定的参考价值。
1.超参数(hyperparameters)
参数(Parameters): ,
, ,
, ,
, ,
, ,
, ...
...
超参数:能够控制参数W,b的参数,是在开始学习之前设置的参数。
比如:学习率 、梯度下降循环的数量#iterations、隐藏层数量#hidden layers、每一个隐藏层的隐藏单元数量#hidden units...
、梯度下降循环的数量#iterations、隐藏层数量#hidden layers、每一个隐藏层的隐藏单元数量#hidden units...
2.划分数据集
通常将数据集划分为训练集(train sets)、验证集(validation set)、测试集(test sets)。
训练集用来执行训练算法,验证集用来选择表现最好的模型,测试集用来最后评估算法的运行情况。
划分比例:
小数据时代(100~1w条数据):60%/20%/20%
大数据时代(百万条级别):验证集和测试集的比例更小,毕竟验证集只是为了测试哪种算法的性能更好一些,测试集是为了评估最后选择的模型的性能。比如,100w条数据,验证集和测试集各1w就够了。
数据更大的话,99.5%/0.25%/0.25%或99.5%/0.4%/0.1%的比例也是可以的。
没有测试集也是可以的。
3.偏差与方差(bias and variance)
偏差(bias)用来描述训练集错误率,高偏差(high bias)意味着高训练集错误率(train set error),也就是欠拟合(underfitting)。
方差(variance)用来描述对训练集中小波动的敏感度误差,高方差(high variance)意味着低训练集错误率(train set error)和高验证集错误率(validation set error),两者差距比较大,也就是过拟合(overfitting)。
Train set error | 1% | 15% | 15% | 0.5% |
validation set error | 11% | 16% | 30% | 1% |
high variance | high bias | high variance, high bias | low variance, low bias |
解决高偏差(high bias):训练更大的网络(含有更多的隐藏层),尝试更先进的优化算法。
解决高方差(high variance):准备更多的数据来训练,采用正则化(regularization)来减少过拟合。
4.正则化(Regularization)
以逻辑回归为例
 ,
, ,l表示第几层
,l表示第几层
在一个隐藏单元上实现正则化
L2正则化: ,λ是正则化参数(regularization parameter)。
,λ是正则化参数(regularization parameter)。
L1正则化: 。
。
 是欧几里得范数(Euclidean norm),即距离范数,指在m维空间中两个点之间的真实距离。
是欧几里得范数(Euclidean norm),即距离范数,指在m维空间中两个点之间的真实距离。
 是绝对值范数(Absolute-value norm),
是绝对值范数(Absolute-value norm), 表示输入特征x的个数。
表示输入特征x的个数。
在整个神经网络实现正则化

 ,弗罗贝尼乌斯范数(Frobenius norm):矩阵各项元素平方的和再开根。
,弗罗贝尼乌斯范数(Frobenius norm):矩阵各项元素平方的和再开根。
 矩阵的维度为(
矩阵的维度为( ,
, ),表示神经网络第l层所包含的隐藏单元数量,表示前一层的单元数量。结合上面逻辑回归的公式,可知公式中x的维度为(,1)。在每一个隐藏单元中,对于前一层的个输入,有个对应的参数
),表示神经网络第l层所包含的隐藏单元数量,表示前一层的单元数量。结合上面逻辑回归的公式,可知公式中x的维度为(,1)。在每一个隐藏单元中,对于前一层的个输入,有个对应的参数 。
。
5.为什么正则化能减少过拟合
以逻辑回归和常用的L2正则化为例。
当提高λ时,为了减小损失函数J(w,b),需要减小 ,也就是要减小wij,直观一点理解,就是让一部分wij=0,甚至有的隐藏单元中的参数wij全是0,它的影响就可以忽略,从而让整个网络变得简单。
,也就是要减小wij,直观一点理解,就是让一部分wij=0,甚至有的隐藏单元中的参数wij全是0,它的影响就可以忽略,从而让整个网络变得简单。
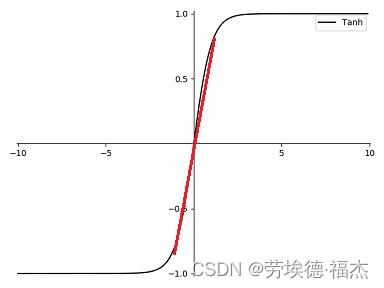
此外,w变小,z变小,代入tanh激活函数中,激活函数在z比较小的部分近似线性函数,相较于复杂的非线性函数,显然更简单一些。
6.Dropout 正则化
dropout可以随机删除神经网络中的一些神经单元。
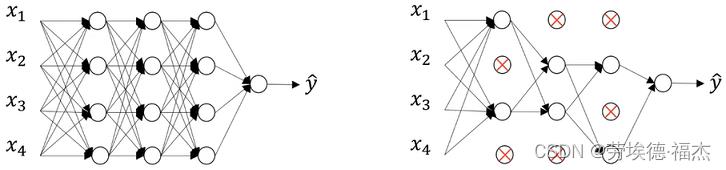
具体:遍历网络的每一层,并设置消除神经单元的概率。
7.其它正则化方法
①数据增强(data augmentation)
包括:通过对训练图片进行水平翻转、旋转剪裁,从而扩大训练集,对于一些字符形图片,还可以进行扭曲。


②提前停止(early stopping)
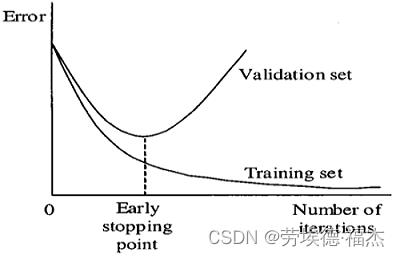
通过提早停止训练神经网络,来减少过拟合。缺点:提早停止梯度下降,但成本函数(cost funciton)还不够小。
以上是关于超参数划分数据集偏差与方差正则化的主要内容,如果未能解决你的问题,请参考以下文章