网页抓取 - 完整指南
Posted 海拥✘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网页抓取 - 完整指南相关的知识,希望对你有一定的参考价值。
目录
介绍
Web Scraping,也称为数据提取或数据抓取,是从网站或其他来源以文本、图像、视频、链接等形式提取或收集数据的过程。
当特定网站没有官方 API 或对数据访问有限制时,Web Scraping 很有用。它具有价格监控、媒体监控、情感分析等多种用途。
数据现在已成为市场上的新石油。如果使用得当,企业可以通过领先于竞争对手来实现目标。这样,他们就可以利用这一优势来超越竞争对手。“你拥有的相关数据越多,你做出的决定就越明智。”
在此博客中,我们将了解有关网络抓取的所有内容、其方法和用途、正确的做法,以及与之相关的各种其他信息。
什么是网页抓取?
Web Scraping 是借助网站服务器上的 HTTP 请求从单个或多个网站中提取数据以访问特定网页的原始 html,然后将其转换为你想要的格式的过程。
我们有时会从网页复制内容并将其嵌入到 Excel 文件或其他文件中。它就是网络抓取,但规模很小。对于大规模抓取,开发人员使用 Web 抓取 API,它可以快速收集大量数据。
使用网络抓取 API 的好处是你不必定期从网站复制数据,但你可以使用 API 来自动执行该过程并节省你宝贵的时间和精力。
网页抓取的用途
Web 抓取是一种功能强大且有用的工具,可用于多种用途:

Web 抓取可用于从Google 等搜索引擎中提取大量数据,然后可以使用这些抓取的信息来跟踪关键字、网站排名等。这对你的业务很有用,因为借助数据驱动的研究,你可以提高产品在市场上的知名度。
数据挖掘
在网络抓取的帮助下,人们可以收集大量关于他们的竞争对手和产品的数据,揭示他们的战略,并可以根据市场上可用的数据做出明智的决策。
价格监控
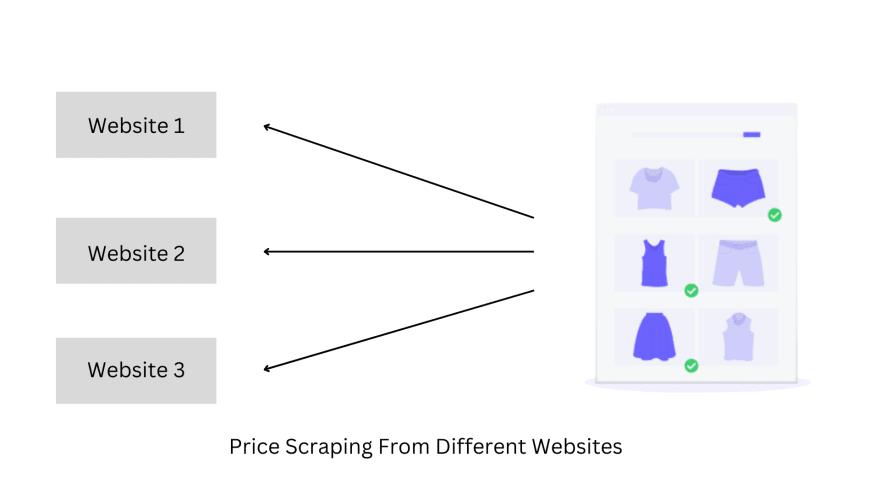
它是网络抓取最流行的用途之一。价格监控可用于从市场上的竞争对手或多家在线零售商那里收集定价数据,并可以帮助消费者找到市场上最优惠的价格,从而节省资金。
新闻与媒体监测
Web 抓取可用于跟踪世界上发生的当前新闻和事件。在网络抓取的帮助下,你可以访问纽约时报、华盛顿邮报、经济时报等大型新闻机构的大量文章。
如果你经营一家公司,新闻中会不时出现,你想知道谁在说你的公司或品牌,那么抓取新闻数据对你来说可能是一件有益的事情。
领先一代
Web 抓取可以帮助你的公司从各种在线资源中为你公司的潜在客户生成潜在客户。你可以针对一组特定的人,而不是发送大量电子邮件,这对你的产品销售有利。
因此,根据用户的规格和要求,网络抓取有多种用途。从 SEO 到 Lead Generation,网络抓取可以帮助企业做出数据驱动的决策。
Web Scraping 可以帮助你不费时费力地提取大量数据。使用网络抓取工具比手动为每个网站复制一段数据要高效得多。
网页抓取的方法
你可以使用多种网络抓取方法来抓取网站。以下是一些有助于有效抓取网站的方法:
设计你的抓取工具
设计你的爬虫涉及到用某种编程语言编写代码,这将自动完成导航到网站和提取所需数据的过程。你可以使用各种编程语言编写脚本,如 Python、javascript、C++ 等。Python 是目前最流行的网络抓取语言,但 Javascript 中也有一些功能强大的库,如 Unirest、Cheerio 和 Puppeteer,它们具有非常高的性能-性能。
在设计你的抓取工具时,你必须首先通过检查 HTML 代码来搜索你想要抓取的某些元素标签,然后在你开始解析 HTML 时将它们嵌入到你的代码中。
解析是从 HTML 文档中提取结构化数据的过程。Beautiful Soup (Python)、Cheerio (JavaScript) 和 group (Java) 是 Web 解析的一些首选库。
确定所需的标签后,你可以借助所选编程语言的网络抓取库向特定网站发送 HTTP 请求,然后使用网络解析库解析提取的数据。
同样重要的是要注意,在设计你的抓取工具时,你必须牢记你的抓取机器人不会违反网站的条件条款。也建议不要在较小的网站上进行大量请求,每个人的预算都不像以前大企业那样高。
优点:完全控制你的刮板允许你根据你的刮板需求定制刮板。
缺点:如果你没有正确地进行刮擦,那么制作刮刀有时会成为一个耗时的过程。
手动网页抓取
手动网页抓取是在你的网络浏览器中导航到特定网站并将所需数据从该网站复制到 Excel 或任何其他文件中的过程。这个过程是手动完成的,在这种类型的网络抓取中没有使用脚本或数据提取服务。
你可以通过多种不同的方式进行手动网络抓取。你可以将整个网页下载为 HTML 文件,然后在电子表格或任何其他文件中使用的任何文本编辑器的帮助下,从 HTML 文件中过滤出所需的数据。
另一种手动抓取网站的方法是使用浏览器检查工具,你可以在其中识别并选择包含要提取的数据的元素。
这种方法适用于小规模的网络数据提取,但在大规模进行时会产生错误,而且比自动网络抓取需要更多的时间和精力。
优点:复制粘贴是基本功。你在这里不需要任何类型的技术技能。
缺点:如果你要抓取大量网站,此方法需要付出很大的努力并且非常耗时。
网页抓取服务
许多公司和自由职业者为他们的客户提供网络抓取服务,你只需向他们提供 URL,他们就会以所需格式向你发送数据。
如果你想抓取大量数据并且不想搞乱复杂的抓取过程,这是最好的方法之一。
一般来说,为客户提供网络抓取服务的公司已经有了现成的脚本,并且他们还有一个专家团队来处理抓取 URL 时可能出现的任何错误,如 IP 禁令、验证码、超时错误等。他们可以更有效地处理大量数据,并且可以比你自己更快地完成任务。
优势:从长远来看,Web 抓取服务具有成本效益,因为它们可以使用现成的基础设施抓取数据,速度比你自己的快得多。
缺点:无法控制抓取过程。
另一件重要的事情是,对于这些可以提供你想要的高质量数据的大型任务,人们应该只信任信誉良好的服务。
网页抓取 API
Web Scraping API是一种可以使用 API 调用从网站上抓取数据的 API。你不必直接访问网页的 HTML 代码,但 API 将处理整个抓取过程。
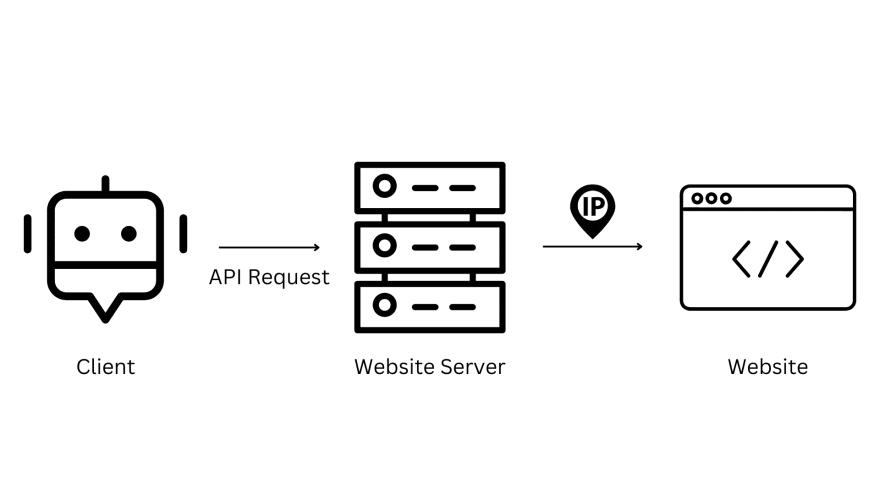
API(应用程序编程接口)是一组定义和协议,允许一个软件系统与另一个软件系统进行通信。
Web Scraping API 易于使用,不需要此类技术知识,只需在其端点传递 URL,它将以结构良好的格式返回结果。它们具有高度可扩展性,这意味着你可以抓取大量数据而不必担心任何 IP 禁令或验证码。
优势:它们具有高度可扩展性,你收到的数据准确、完整且质量高。
缺点:某些 Web Scraping API 会限制你每单位时间可以发送的请求数,从而限制你可以收集的数据量。
因此,你可以根据自己的抓取需求应用多种网络抓取方法。如果你想省钱,那么方法一和方法二最适合你。这两种方法还可以让你完全控制抓取过程。如果你不想搞乱 IP 禁令、验证码和处理大量数据,那么最后两种方法是你的最佳选择。
网页抓取合法吗?
Web Scraping 的合法性仍然是一个不断发展的过程,但判断取决于各种因素,例如你如何抓取任何特定数据以及如何使用它。
一般来说,如果你想将数据用于研究目的、教育项目、价格比较等,网络抓取可以被认为是合法的。但如果网站在其条款中严格禁止任何类型的网络抓取,则合法性可能会受到影响未经其许可。
如果网页抓取被用于获得相对于竞争对手的任何不公平优势,或者用于未经授权的目的,例如从网站窃取敏感数据,则网页抓取也可能被视为非法。你还可能在从网站提取数据的过程中被阻止,并因违反任何版权法而被起诉。
总的来说,如果使用正确,网络抓取是一种有价值的工具,但如果恶意执行,则必须牢记法律后果。尊重网站的服务条款并且不以任何方式损害其服务或功能也很重要。
Web 抓取的最佳语言
根据你的需要,你可以使用多种编程语言进行网络抓取。让我们讨论这些:

Python: Python 是开发人员中最流行的网络抓取语言,这要归功于它的简单性和大量的库和框架,包括 Scrapy 和 Beautiful Soup。此外,当我们谈论 Python 时,社区在网络抓取方面的支持非常好。
Javascript: Javascript 也正在成为网络抓取的首选选择之一,因为它能够从使用 JavaScript 动态加载网页的网站抓取数据。Unirest、Puppeteer 和 Cheerio 等库使 JavaScript 中的数据抓取变得更加容易。
Java: Java 是另一种广泛用于大型项目的流行语言。像 Jsoup 这样的库可以更容易地从网站上抓取数据。
Ruby:一种高级编程语言,带有 Nokogiri 和 Mechanize 等库,可以更轻松地从网站上抓取数据。
可以有更多这样的例子,比如 C#、R、php 等,可以用于网络抓取,但最终取决于项目的要求。
如何学习网页抓取?
Web Scraping 现在正在成为一项可以赚钱的重要技能,几乎每个网站都需要潜在客户来扩展他们的业务,这只有通过 Web Scraping 才有可能,每个活跃的网站都希望跟踪其在 Google 上的排名,这只有通过 Google Scraping 才有可能. 因此,Web Scraping 已成为业务增长的主要支柱之一。
在本节中,我们将讨论开始使用网络抓取的各种方法:
自学:你也可以通过自己制作小项目来学习网络抓取。首先,当你对较小的项目感到满意时,开始对它们进行研究,尝试从更难抓取的网站中提取数据。
在线教程:你还可以参加Udemy、Coursera等教育平台上的各种在线课程。老师经验丰富,将带你从初学者到高级有条理。
但它也需要你学习你想要开始使用网络抓取的编程语言。首先从基础到中级学习这门语言,然后当你获得足够的经验时,加入这些课程以启动你的网络抓取之旅。
加入在线社区:建议加入与你的编程语言或网络抓取相关的社区,这样你可以在制作抓取工具时遇到错误时提出任何问题。你可以加入 Reddit、Discord 等平台上的各种社区。他们的服务器上有一些非常有经验的人,他们甚至可以轻松解决高级问题。
阅读文章:互联网上有大量关于网络抓取的文章,可以让你从零级成为网络抓取专家。你可以在这些教程中学习如何抓取 Google、Amazon 和 LinkedIn 等高级网站,并提供完整的说明。
因此,有很多方法可以开始学习网络抓取,但最终的关键是在学习新事物时保持一致和专注。你可以从每天至少投入 1 小时开始,然后慢慢增加,以投入你的 100%。这将使你在抓取方面有很好的帮助,并使你成为熟练的学习者。
结论
在本教程中,我们了解了网络抓取、抓取网站的一些方法,以及如何启动你的网络抓取之旅。
我们还了解到网络抓取是一项有价值的技能,它允许你从不同的网站抓取数据,可用于基于研究的目的,如价格监控、媒体监控、搜索引擎优化等。我们还可以为我们的业务产生大量的潜在客户借助网络抓取在竞争中保持领先地位。
⭐️ 好书推荐
《大数据导论》

【内容简介】
本书围绕新工科背景下大数据人才培养需求编写,系统介绍了大数据采集与预处理、大数据存储与管理、大数据处理与分析、大数据可视化处理流程;重点分析了科大讯飞大数据平台在政务、交通、金融和用户画像等实际场景中的应用,还介绍了大数据实验环境的详细搭建步骤;最后介绍了大数据治理中法律政策、行业标准建设的最新进展,分析了大数据可能带来的伦理风险和应对策略。
📚 京东自营购买链接:《大数据导论》
以上是关于网页抓取 - 完整指南的主要内容,如果未能解决你的问题,请参考以下文章