《深度学习:算法到实战》第二周卷积神经网络笔记
Posted 朝阳学长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《深度学习:算法到实战》第二周卷积神经网络笔记相关的知识,希望对你有一定的参考价值。
【第二周】卷积神经网络
第一部分:代码练习
MNIST 数据集分类
1、加载数据,train_loader.dataset.__getitem__(i)函数可能是默认从数据集里面取,导致修改的shuffle参数无法可视化在图像上。
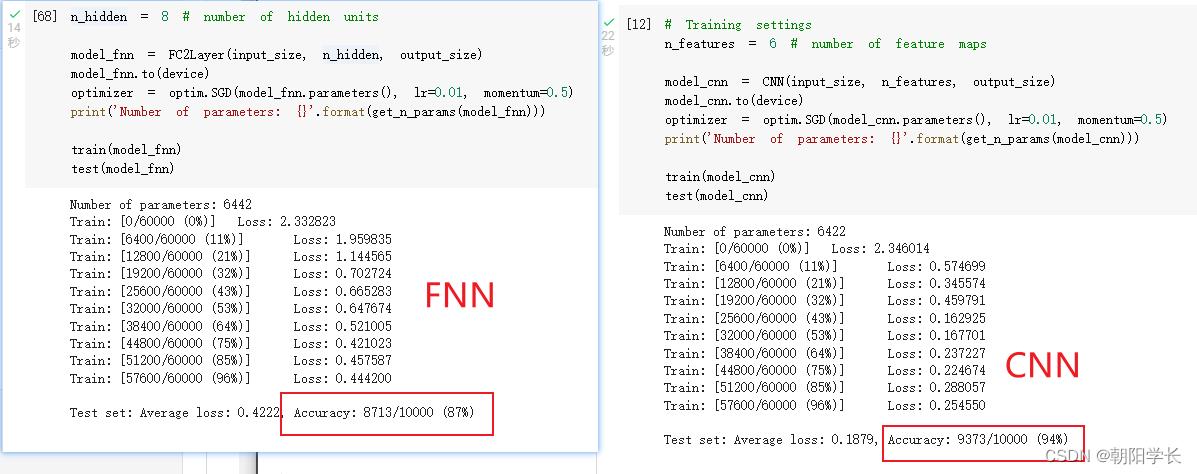
2、创建网络,一个是小型全连接网络和另一个是卷积神经网络,结果可以看出卷积神经网络准确率明显高于小型全连接网络。
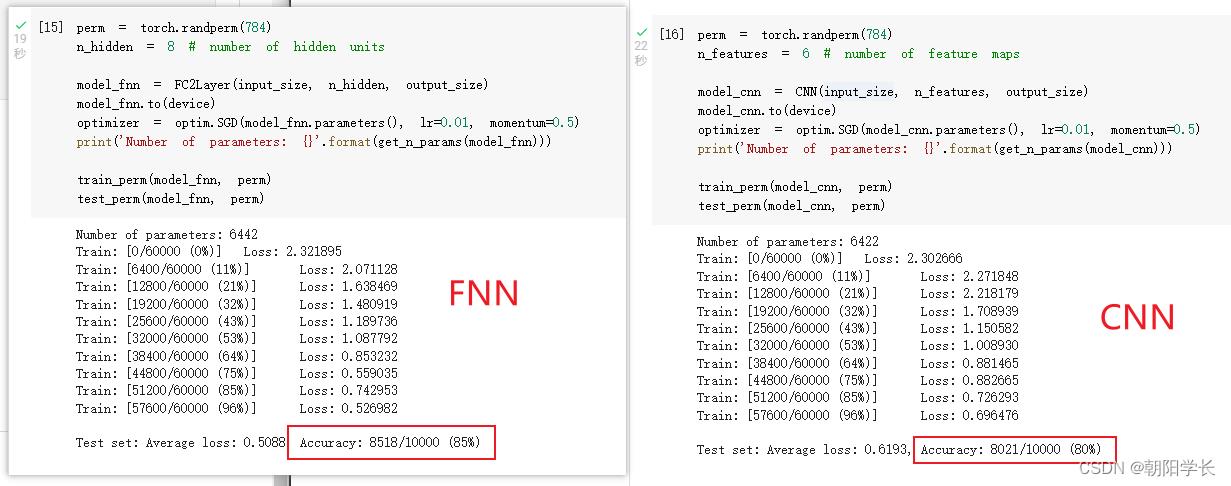
3、将图片的像素打乱

4、将乱序像素的图片作为input,再次对比FNN和CNN的训练效果,可以看出FNN准确率基本没有变化,CNN准确率明显下降。
CIFAR10 数据集分类
1、加载需要库以及数据集
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 注意下面代码中:训练的 shuffle 是 True,测试的 shuffle 是 false
# 训练时可以打乱顺序增加多样性,测试是没有必要
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=8,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
2、展示数据集图片
def imshow(img):
plt.figure(figsize=(8,8))
img = img / 2 + 0.5 # 转换到 [0,1] 之间
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 得到一组图像
# images, labels = iter(trainloader).next()
# '_MultiProcessingDataLoaderIter' object has no attribute 'next'
images, labels = next(iter(trainloader))
# 展示图像
imshow(torchvision.utils.make_grid(images))
# 展示第一行图像的标签
for j in range(8):
print(classes[labels[j]])

3、定义网络以及训练网络
# 定义网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 网络放到GPU上
net = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
# 训练网络
for epoch in range(5): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
Epoch: 1 Minibatch: 1 loss: 2.302
Epoch: 1 Minibatch: 101 loss: 1.944
Epoch: 1 Minibatch: 201 loss: 1.673
Epoch: 1 Minibatch: 301 loss: 1.557
Epoch: 1 Minibatch: 401 loss: 1.477
Epoch: 1 Minibatch: 501 loss: 1.610
Epoch: 1 Minibatch: 601 loss: 1.511
Epoch: 1 Minibatch: 701 loss: 1.721
Epoch: 2 Minibatch: 1 loss: 1.678
Epoch: 2 Minibatch: 101 loss: 1.382
Epoch: 2 Minibatch: 201 loss: 1.474
Epoch: 2 Minibatch: 301 loss: 1.752
Epoch: 2 Minibatch: 401 loss: 1.449
Epoch: 2 Minibatch: 501 loss: 1.465
Epoch: 2 Minibatch: 601 loss: 1.173
Epoch: 2 Minibatch: 701 loss: 1.464
Epoch: 3 Minibatch: 1 loss: 1.232
Epoch: 3 Minibatch: 101 loss: 1.497
Epoch: 3 Minibatch: 201 loss: 1.223
Epoch: 3 Minibatch: 301 loss: 1.065
Epoch: 3 Minibatch: 401 loss: 1.142
Epoch: 3 Minibatch: 501 loss: 1.257
Epoch: 3 Minibatch: 601 loss: 1.403
Epoch: 3 Minibatch: 701 loss: 1.228
Epoch: 4 Minibatch: 1 loss: 1.078
Epoch: 4 Minibatch: 101 loss: 0.850
Epoch: 4 Minibatch: 201 loss: 1.223
Epoch: 4 Minibatch: 301 loss: 1.207
Epoch: 4 Minibatch: 401 loss: 1.258
Epoch: 4 Minibatch: 501 loss: 1.187
Epoch: 4 Minibatch: 601 loss: 1.454
Epoch: 4 Minibatch: 701 loss: 1.144
Epoch: 5 Minibatch: 1 loss: 1.188
Epoch: 5 Minibatch: 101 loss: 0.969
Epoch: 5 Minibatch: 201 loss: 1.350
Epoch: 5 Minibatch: 301 loss: 1.237
Epoch: 5 Minibatch: 401 loss: 1.140
Epoch: 5 Minibatch: 501 loss: 0.866
Epoch: 5 Minibatch: 601 loss: 0.873
Epoch: 5 Minibatch: 701 loss: 0.900
Finished Training
4、获得一组图片以及标签
# 得到一组图像
images, labels = next(iter(testloader))
# 展示图像
imshow(torchvision.utils.make_grid(images))
# 展示图像的标签
for j in range(8):
print(classes[labels[j]])

5、展示测试结果
outputs = net(images.to(device))
_, predicted = torch.max(outputs, 1)
# 展示预测的结果
for j in range(8):
print(classes[predicted[j]])
cat
car
ship
plane
deer
frog
car
frog
6、最终准确率59%
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
7、使用VGG16对CIFAR10分类优化,类方法如下
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
# 不改小点跑的好慢...
self.cfg = [64, 'M', 64, 'M', 64, 64, 'M', 64, 64, 'M', 64, 64, 'M']
self.features = self._make_layers(self.cfg)
self.classifier = nn.Linear(64, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
8、训练代码将训练轮数改为10后,执行结果如下
Epoch: 1 Minibatch: 1 loss: 1.801
Epoch: 1 Minibatch: 101 loss: 1.398
Epoch: 1 Minibatch: 201 loss: 1.214
Epoch: 1 Minibatch: 301 loss: 1.266
Epoch: 2 Minibatch: 1 loss: 1.181
Epoch: 2 Minibatch: 101 loss: 1.010
Epoch: 2 Minibatch: 201 loss: 1.080
Epoch: 2 Minibatch: 301 loss: 0.821
Epoch: 3 Minibatch: 1 loss: 0.988
Epoch: 3 Minibatch: 101 loss: 0.657
Epoch: 3 Minibatch: 201 loss: 0.928
Epoch: 3 Minibatch: 301 loss: 1.000
Epoch: 4 Minibatch: 1 loss: 0.745
Epoch: 4 Minibatch: 101 loss: 0.779
Epoch: 4 Minibatch: 201 loss: 0.727
Epoch: 4 Minibatch: 301 loss: 0.838
Epoch: 5 Minibatch: 1 loss: 0.651
Epoch: 5 Minibatch: 101 loss: 0.759
Epoch: 5 Minibatch: 201 loss: 0.662
Epoch: 5 Minibatch: 301 loss: 0.607
Epoch: 6 Minibatch: 1 loss: 0.677
Epoch: 6 Minibatch: 101 loss: 0.635
Epoch: 6 Minibatch: 201 loss: 0.678
Epoch: 6 Minibatch: 301 loss: 0.656
Epoch: 7 Minibatch: 1 loss: 0.596
Epoch: 7 Minibatch: 101 loss: 0.638
Epoch: 7 Minibatch: 201 loss: 0.599
Epoch: 7 Minibatch: 301 loss: 0.489
Epoch: 8 Minibatch: 1 loss: 0.446
Epoch: 8 Minibatch: 101 loss: 0.733
Epoch: 8 Minibatch: 201 loss: 0.670
Epoch: 8 Minibatch: 301 loss: 0.480
Epoch: 9 Minibatch: 1 loss: 0.513
Epoch: 9 Minibatch: 101 loss: 0.532
Epoch: 9 Minibatch: 201 loss: 0.701
Epoch: 9 Minibatch: 301 loss: 0.414
Epoch: 10 Minibatch: 1 loss: 0.382
Epoch: 10 Minibatch: 101 loss: 0.559
Epoch: 10 Minibatch: 201 loss: 0.524
Epoch: 10 Minibatch: 301 loss: 0.567
Finished Training
9、最终准确率提高到了80%
Accuracy of the network on the 10000 test images: 80.78 %
第二部分:问题总结
1、dataloader 里面 shuffle 取不同值有什么区别?
shuffle:在每个epoch中对整个数据集data进行shuffle重排,默认为False。
当值为False的时候,每次打印出的数据集都是一样的。
当值为True的时候,每次打印出的数据集都是随机被打乱的。
2、transform 里,取了不同值,这个有什么区别?
计算公式为: i n p u t [ c h a n n e l ] = ( i n p u t [ c h a n n e l ] − m e a n [ c h a n n e l ] ) s t d [ c h a n n e l ] input[channel] = \\frac(input[channel] - mean[channel]) std[channel] input[channel]=std[channel](input[channel]−mean[channel])
当全取0.1时,可以看出图片很白,根据公式可以得到区间范围为[-0.2,1.8]

当全取1时,可以看出图片很黑,根据公式可以得到区间范围为[-1,0]

可以看出这个是rgb3个通道的转换方式,做出映射。
3、epoch 和 batch 的区别?
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一次epoch。
(也就是说,所有训练样本在神经网络中都 进行了一次正向传播 和一次反向传播 )
然而,当一个Epoch的样本(也就是所有的训练样本)数量可能太过庞大(对于计算机而言),
就需要把它分成多个小块,也就是就是分成多个Batch 来进行训练。
4、1x1的卷积和 FC 有什么区别?主要起什么作用?
1*1的卷积核是输入map大小不固定的;而全连接是固定的。
1*1的卷积核主要都是加入非线性的激活函数增加非线性,使得网络可以表达更加复杂的特征。
FC(全连接层)主要是在卷积神经网络中起到分类器的作用,将网络输出的结果映射到目标集中。
5、residual learning 为什么能够提升准确率?
在残差网络中,它的网络深度比VGG以及GoogLeNet大幅增加,并且有效避免了梯度消失问题。
再次证明了神经网络越深准确率越高。
6、代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
代码练习2中使用的为最大池化,激活函数是ReLu。
LeNet中使用的为平均池化,激活函数是Sigmoid。
7、代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
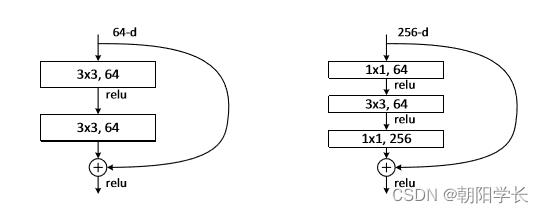
考虑padding,通过变换就可以使得卷积之后size不变。
考虑1*1的卷积,可以方便的进行升维。
8、有什么方法可以进一步提升准确率?
1.加入Dropout,防止过拟合。
2.优化网络结构,使用更深的网络。
3.选择更好的激活函数。
4.选择更好的损失函数。
5.增加更多训练时间。
以上是关于《深度学习:算法到实战》第二周卷积神经网络笔记的主要内容,如果未能解决你的问题,请参考以下文章