入门」全方位盘点和总结调优技术专题指南
Posted 洛神灬殇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了入门」全方位盘点和总结调优技术专题指南相关的知识,希望对你有一定的参考价值。
专题⽬标
本系列专题的目标是希望可以帮助读者们系统和全访问掌握应⽤系统调优的思路与方案以及相关的调优工具的使用,虽然未必会覆盖目前的所有的问题场景,但是还是提供了较为丰富的案例和调优理论,会帮助大家打开思维去⽀撑系统服务体系优化能力。
适合人员
Java相关的开发人员、系统架构师、数据库DB人员以及运维人员等。
什么是调优
调优手段就是让计算机的硬件或软件在正常地⼯作基础上,非常出色的发挥其应有的性能,并且将所承担的负担降低到最低的技术手段。在Java应用服务体系中有大致可以分为5个维度的调优方向。
调优技术的五个维度
- 应⽤⾃身的调优
- 运⾏环境的调优(JVM的调优)
- 存储上的调优(数据库的调优)
- 操作系统的调优
- 架构上的调优
如下图所示。

一般从上到下系统优化的层面成本越来越高,而从下到上系统优化层面的成本越来月底,而且难度也适当下降,建议自下而上的去进行调优规划。
调优技术的四条准则
借助监控预防问题、发现问题,监控 + 告警
采用监控和预防的手段去实现提前发现问题:zabbix、promethus等等
借助⼯具定位问题
问题排查工具使用机制
定期复盘,防⽌同类问题再现
定期进行排查和复盘相关的代码问题,加深我们对问题的印象以及防止问题再次发生
定好规范,⼀定程度上规避问题
制定标准规范,约束问题的发生。
调优的原则
有问题,解决问题。not broken, don’t fix.
应⽤调优
应⽤调优-⼯具篇
-
⼯具旨在帮助我们快速找到应⽤的性能瓶颈。
-
⽇志分析⼯具⽐较与分析
-
ELK、GrayLog、SLSLog…
-
ELK搭建与使⽤
-
现场演示
-
调⽤链跟踪⼯具与对⽐
-
Skywalking、Sleuth + Zipkin、Jaeger…
-
Skywalking快速发现性能瓶颈
应⽤调优常⽤技巧-池化技术-对象池
通过复⽤对象,减少对象创建、垃圾回收的开销
适⽤场景
维护⼀些很⼤、创建很慢的对象,提升性能
缺点:有学习成本、增加了代码的复杂度
对象池框架
Apache Commons-Pool2
- 官⽹:https://commons.apache.org/proper/commons-pool
- GitHub:https://github.com/apache/commons-pool
Commons-Pool2详解
两⼤类对象池:ObjectPool & KeyedObjectPool
ObjectPool
实现类如下,其中,最重要、功能最强、使⽤最⼴泛的GenericObjectPool,这个对象池⾮常的强⼤,它⽐较的通⽤,⽽且封装得也⾮常完备。
- BaseObjectPool:抽象类,⽤来扩展⾃⼰的对象池
- ErodingObjectPool:“腐蚀”对象池,代理⼀个对象池,并基于factor参数,为其添加“腐蚀”⾏为。归还的对象被腐蚀后,将会丢弃,⽽不是添加到空闲容量中。
- GenericObjectPool:⼀个可配置的通⽤对象池实现。
- ProxiedObjectPool:代理⼀个其他的对象池,并基于动态代理(⽀持JDK代理和CGLib代理),返回⼀个代理后的对象。该对象池主要⽤来增强对池化对象的控制,⽐如防⽌在归还该对象后,还继续使⽤该对象等。
- SoftReferenceObjectPool:基于软引⽤的对象池
- SynchronizedObjectPool:代理⼀个其他对象池,并为其提供线程安全的能⼒。
核⼼API如下
- borrowObject() 从对象池中借对象
- returnObject() 将对象归还到对象池
- invalidateObject() 失效⼀个对象
- addObject() 增加⼀个空闲对象,该⽅法适⽤于使⽤空闲对象预加载对象池
- clear() 清空空闲的所有对象,并释放相关资源
- close() 关闭对象池,并释放相关资源
- getNumIdle() 获得空闲的对象数量
- getNumActive() 获得被借出对象数量
KeyedObjectPool
这种对象池和ObjectPool的区别在于,它是通过key找对象的,从设计上来看和ObjectPool没什么区别。实现类如下,使⽤最⼴的是GenericKeyedObjectPool。
- ErodingKeyedObjectPool 类似ErodingObjectPool
- GenericKeyedObjectPool 类似GenericObjectPool
- ProxiedKeyedObjectPool 类似ProxiedObjectPool
- SynchronizedKeyedObjectPool 类似SynchronizedObjectPool
使⽤
new GenericObjectPool(PooledObjectFactory<T> factory)
new GenericObjectPool(PooledObjectFactory<T> factory, GenericObjectPoolConfig<T> config)
new GenericObjectPool(PooledObjectFactory<T> factory, GenericObjectPoolConfig<T> config, AbandonedConfig abando
nedConfig)
最重要的参数是PooledObjectFactory,⼀般来说,⼯⼚是需要我们⾃⼰根据业务需求去实现的。它是⽤来创建对象的,这其实就是设计模式⾥⾯的⼯⼚模式。
⽬前PooledObjectFactory有两个实现类。
- BasePooledObjectFactory:抽象类,⽤于扩展⾃⼰的PooledObjectFactory
- PoolUtils.SynchronizedPooledObjectFactory:内部类,代理⼀个其他的PooledObjectFactory,实现线程同步,⽤ PoolUtils.synchronizedPooledFactory() 创建
Factory核⼼⽅法:
- makeObject 创建⼀个对象实例,并将其包装成⼀个PooledObject
- destroyObject 销毁对象
- validateObject 校验对象,确保对象池返回的对象是OK的
- activateObject 重新初始化对象
- passivateObject 取消初始化对象。GenericObjectPool的addIdleObject、returnObject、evict调⽤该⽅法。
Commons-Pool2总体分析
- ObjectPool:对象池,最核⼼:GenericObjectPool、 GenericKeyedObjectPool。
- Factory:创建&管理PooledObject,⼀般要⾃⼰扩展
- PooledObject:包装原有的对象,从⽽让对象池管理,⼀般⽤DefaultPooledObject即可
Factory示例
class MyPooledObjectFactory implements PooledObjectFactory<Model>
public static final Logger LOGGER = LoggerFactory.getLogger(MyPooledObjectFactory.class);
@Override
public PooledObject<Model> makeObject() throws Exception
DefaultPooledObject<Model> object = new DefaultPooledObject<>(new Model(1, "S"));
LOGGER.info("makeObject..state = ", object.getState());
return object;
@Override
public void destroyObject(PooledObject p) throws Exception
LOGGER.info("destroyObject..state = ", object.getState());
@Override
public boolean validateObject(PooledObject p)
LOGGER.info("validateObject..state = ", object.getState());
return true;
@Override
public void activateObject(PooledObject p) throws Exception
LOGGER.info("activateObject..state = ", p.getState());
@Override
public void passivateObject(PooledObject p)
LOGGER.info("passivateObject..state = ", object.getState());
return true;
所有操作面向的都是PooledObject这个参数,makeObject返回的是PooledObject,其他API为什么操作的也是 PooledObject,⽽不是直接操作我们创建的对象呢?
这其实也是commons-pool设计巧妙之处。Pooledobject可以对原始对象进⾏包装,从⽽被对象池管理。⽬前 pooledobject有两个实现类:
- DefaultPooledObject:包装原始对象,实现监控(例如创建时间、使⽤时间等)、状态跟踪等
- PooledSoftReference:封装了DefaultPooledObject,⽤来和SoftReferenceObjectPool配合使⽤。
DefaultPooledObject定义了对象的若⼲种状态
- IDLE 对象在队列中,并空闲。
- ALLOCATED 使⽤中(即出借中)
- EVICTION 对象当在队列中,正在进⾏驱逐测试
- EVICTION_RETURN_TO_HEAD 对象驱逐测试通过后,放回到队列头部
- VALIDATION 对象当前在队列中,空闲校验中
- VALIDATION_PREALLOCATED 对象当前不在队列中,出借前校验中 VALIDATION_RETURN_TO_HEAD 对象当前不在队列中,校验通过后放回头部 INVALID 对象失效,驱逐测试失败、校验失败、对象销毁,都会将对象置为 INVALID。
- ABANDONED 放逐中,如果对象上次使⽤时间超过removeAbandonedTimeout的配置,则将其标记为ABANDONED。标记为ABANDONED的对象即将变成 INVALID。
- RETURNING 对象归还池中。
JVM调优
本系列专题将针对于Oracle Java HotSpot虚拟机为为开发者们提供不同的Java Heap内存空间的较为深入的分析介绍。对于任何接触的开发者都是非常重要的理论依据。频繁遇到的内存问题,提供生产环境的优化调整。那么适当的实战层级的Java虚拟机的内存空间分析能力是至关重要的。
前提概述
- Java虚拟机是你的Java程序运行的基础,它为你提供动态的分配内存服务、垃圾收集、线程调度和切换、IO处理和本机操作等
- Java堆空间是运行时Java程序的内存“容器”,它提供给您的Java应用程序所需的适当内存空间(Java堆、本机堆),并由JVM本身去管理。
JVM HotSpot内存被划分2类和5空间:
- Heap堆内存空间:属于线程共享区域,也是我们JVM的内存管理范畴的最大的一部分运行时内存区域。
- 方法区(永久代/元空间):属于线程共享区域,往往我们会忽略了这个区域的内存回收能力。
- 本地堆 (C-Heap):本地方法的调用栈。
- 虚拟机栈:Java方法的调用栈。
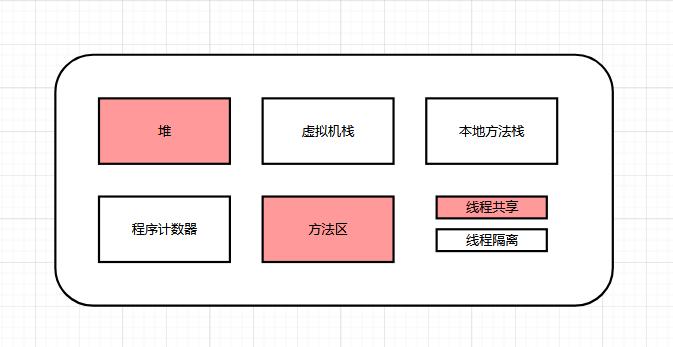
Heap堆内存空间
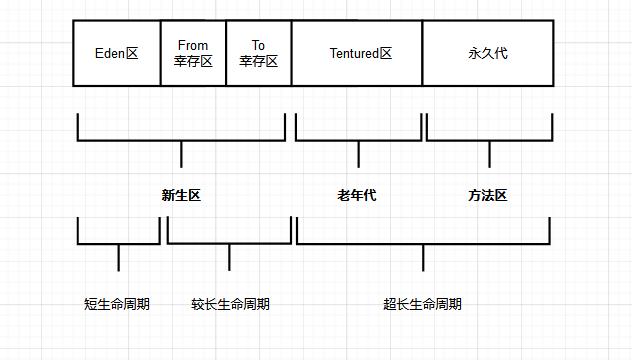
JVM的堆空间的变化在<18的版本之内,主要有一个分水岭,主要集中在8之前和8之后。
JDK8之前的对空间
JDK8之前的Heap空间如下图所示:
JDK8之后的Heap空间如下图所示:

主要时针对于方法区的实现机制:永久代 -> 元空间结构模型,接下来我们看看元数据空间在方法区中的分布结构模型。
后续版本中的-元空间和方法去的内存才能出分配关系
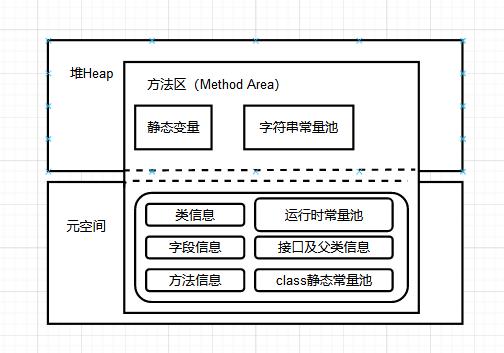
可以看到JDK8之后,方法去的实现有元空间和一部分堆内存组成。之前主要只有单纯的永久代去实现的。
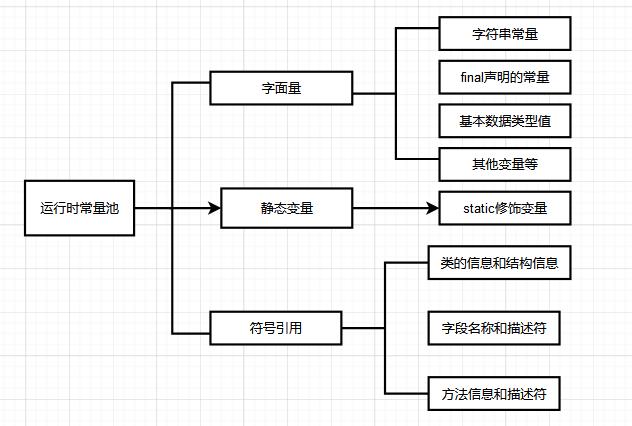
常量池
常量池主要有静态常量池和运行时常量池组成。
- 类信息
- 类的版本
- 字段描述信息
- 方法描述信息
- 接口和父类等描述信息
- class文件常量池(静态常量池)
静态常量池,也叫class⽂件常量池,主要存放:
- 字⾯量:例如⽂本字符串、 final修饰的常量。
- 符号引⽤:例如类和接⼝的全限定名、字段的名称和描述符、⽅法的名称和描述符。
运⾏时常量池
当类加载到内存中后,JVM就会将静态常量池中的内容存放到运⾏时的常量池中;运⾏时常量池⾥⾯存储的主要是编译期间⽣成的字⾯量、符号引⽤等等。如下图对应的字符串常量在字符串常量池中的存储模式。
字符串常量池
字符串常量池,也可以理解成运⾏时常量池分出来的⼀部分,类加载到内存的时候,字符串,会存到字符串常量池⾥⾯。
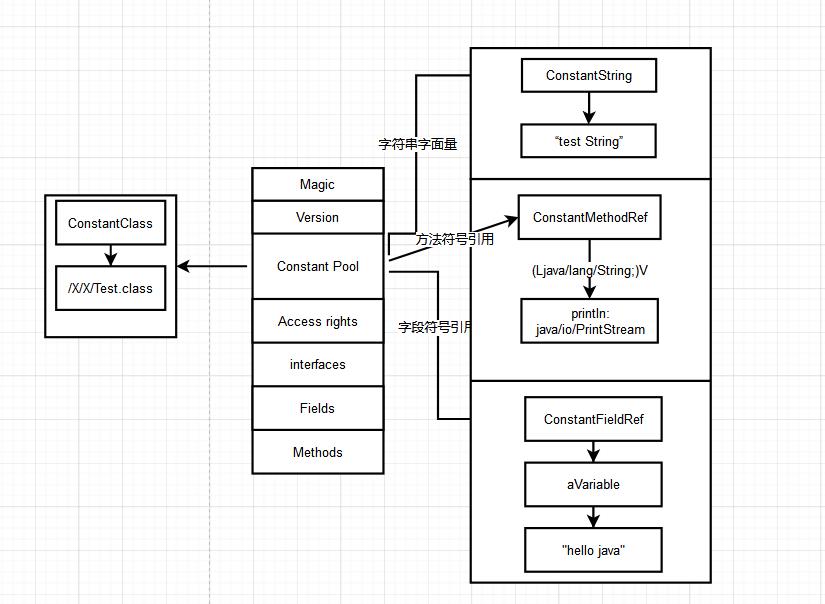
对象和类在内存分布
针对于代码的执行和存储在JVM的分布,主要集中在栈空间和堆空间、方法区。它们各个的职能不同,对应的能力也是不同的。我们针对于一段代码块进行分析和介绍
虚拟机栈的基本结构模型
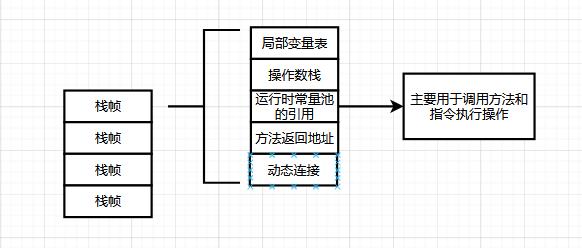
代码在堆栈中的存储结构信息

内存泄漏怎么排查[java内存溢出排查]
top 等查看系统内存概况
top:显示所有进程运行情况,按M键按照内存大小排序。
使用格式
top [-] [d] [p] [q] [c] [C] [S] [s] [n]
参数说明
- d:指定每两次屏幕信息刷新之间的时间间隔,当然用户可以使用s交互命令来改变之。
- p:通过指定监控进程ID来仅仅监控某个进程的状态。
- q:该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。
- S:指定累计模式。
- s:使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。
- i:使top不显示任何闲置或者僵死进程。
- c:显示整个命令行而不只是显示命令名。
命令说明
- jmx 快速发现jvm中的内存异常项
【实战阶段】JVM排查问题优化参数
jps [-q] [-mlvV] [<hostid>]
参数如下:
- -q 只显示进程号
- -m 显示传递给main⽅法的参数
- -l 显示应⽤main class的完整包名应⽤的jar⽂件完整路径名
- -v 显示传递给JVM的参数
- -V 禁⽌输出类名、JAR⽂件名和传递给main⽅法的参数,仅显示本地JVM标识符的列表
hostid的参数格式
- hostid:想要查看的主机的标识符,格式为: [protocol:][[//]hostname][:port][/servername] ,其中:
- protocol:通信协议,默认rmi
- hostname:⽬标主机的主机名或IP地址
- port:通信端⼝,对于默认 rmi 协议,该参数⽤来指定 rmiregistry 远程主机上的端⼝号。如省略该参数,并且该
- protocol指示rmi,则使⽤默认使⽤1099端⼝。
- servicename:服务名称,取值取决于实现⽅式,对于rmi协议,此参数代表远程主机上RMI远程对象的名称
今天就写到这里,未完待续,等待下一部分的内容。
以上是关于入门」全方位盘点和总结调优技术专题指南的主要内容,如果未能解决你的问题,请参考以下文章