手把手教你认识OPTIMIZER_TRACE
Posted 老叶茶馆_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手把手教你认识OPTIMIZER_TRACE相关的知识,希望对你有一定的参考价值。

作者 刘云 · 沃趣科技数据库技术专家
出品 沃趣科技
前 言
我们在日常维护数据库的时候,如果遇到慢语句查询的时候,我们一般会怎么做?执行EXPLAIN去查看它的执行计划?
是的。我们经常会这么做,然后看到执行计划展示给我们的一些信息,告诉我们mysql是如何执行语句的。
BUT,执行计划往往只给我们带来了最基础的分析信息,比如是否有使用索引,还有一些其他供我们分析的信息,比如使用了临时表、排序等等。我们能从这些信息里面找一些优化点,这样就足够了吗?

看看这张图里的执行计划,我们可以提很多问题:为什么t2表上明明使用了索引在Extra列中还是能看到temporary和filesort?如果possible_keys列中有多个索引的话,优化器是基于什么选定使用的索引?这些问题,并不能非常直观地从执行计划中看出来更多的信息,这个时候,我们可以开启OPTIMIZER_TRACE,基于OPTIMIZER_TRACE捕获的信息,去做更细致的追踪分析。一起来看看吧~
OPTIMIZER_TRACE是什么呢?
它是一个跟踪功能,跟踪执行的语句的解析优化执行的过程,并将跟踪到的信息记录到INFORMATION_SCHEMA.OPTIMIZER_TRACE表中。
可以通过optimizer_trace系统变量启停跟踪功能,MySQL从5.6开始提供了相关的功能,但是MySQL默认是关闭它的,我们在需要使用的时候才会手动去开启。
optimizer_trace可以是会话或者是全局开启,但是每个会话都只能跟踪它自己执行的语句,表中默认只记录最后一个查询的跟踪结果(表中记录的跟踪结果数可以通过optimizer_trace的参数设置)。
可跟踪语句对象:
SELECT/INSERT/REPLACE/UPDATE/DELETE
EXPLAIN
SET
DO
DECLARE/CASE/IF/RETURN
CALL
相关变量浅析
mysql > show variables like '%optimizer_trace%';
+------------------------------+----------------------------------------------------------------------------+
| Variable_name | Value |
+------------------------------+----------------------------------------------------------------------------+
| optimizer_trace | enabled=off,one_line=off |
| optimizer_trace_features | greedy_search=on,range_optimizer=on,dynamic_range=on,repeated_subselect=on |
| optimizer_trace_limit | 1 |
| optimizer_trace_max_mem_size | 16384 |
| optimizer_trace_offset | -1 |
+------------------------------+----------------------------------------------------------------------------+optimizer_trace
* enabled:启用/禁用optimizer_trace功能。
* one_line:决定了跟踪信息的存储方式,为on表示使用单行存储,否则以JSON树的标准展示形式存储。单行存储中跟踪结果中没有空格,造成可读性极差,但对于JSON解析器来说是可以解析的,将该参数打开唯一的优势就是节省空间,一般不建议开启。
optimizer_trace_features:该变量中存储了跟踪信息中可控的打印项,可以通过调整该变量,控制在INFORMATION_SCHEMA.OPTIMIZER_TRACE表中的trace列需要打印的JSON项和不需要打印的JSON项。默认打开该参数下的所有项。
optimizer_trace_max_mem_size :optimizer_trace内存的大小,如果跟踪信息超过这个大小,信息将会被截断。
optimizer_trace_limit & optimizer_trace_offset
* 这两个参数神似于SELECT语句中的“LIMIT offset, row_count”,optimizer_trace_limit 约束的是跟踪信息存储的个数,optimizer_trace_offset 则是约束偏移量。和 LIMIT 一样,optimizer_trace_offset 从0开始计算(最老的一个查询记录的偏移量为0)。
* optimizer_trace_offset 的正负值,不需要太过于去纠结,如下表所示,其实offset 0 = offset -5 ,它们是一个等价的关系,仅仅是表述方式不同。这样的表述方式和python中的切片的表述是一致的,了解python的童鞋们都知道,切片的时候经常用到-1取列表中最后一个数值或者是反向取值。
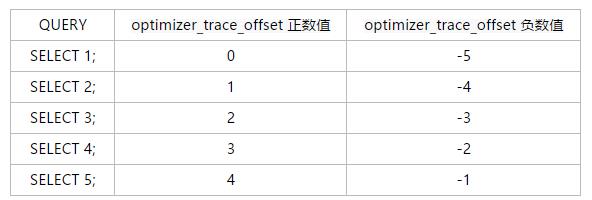
* 结合下MySQL给出的默认值进行解读,MySQL的默认值:optimizer_trace_limit = 1,optimizer_trace_offset = -1。optimizer_trace_limit = 1表示只存储一个查询信息,optimizer_trace_offset = -1 则是指向最近的一个查询,即,在INFORMATION_SCHEMA.OPTIMIZER_TRACE表中只存储最近最后执行的一行结果数据。
PS:修改optimizer_trace参数后INFORMATION_SCHEMA.OPTIMIZER_TRACE表会被清空。
如何跟踪分析
先来看看官网怎么说~官网的使用说明非常的简单粗暴了。
1、打开optimizer_trace参数
2、执行要分析的查询
3、查看INFORMATION_SCHEMA.OPTIMIZER_TRACE表中跟踪结果
4、循环2、3步骤
5、当不再需要分析的时候,关闭参数
# Turn tracing on (it's off by default):
SET optimizer_trace="enabled=on";
SELECT ...; # your query here
SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;
# possibly more queries...
# When done with tracing, disable it:
SET optimizer_trace="enabled=off";以上是官网给出的分析的示例流程,虽然看上去都非常简单明了,但是,如果你查看INFORMATION_SCHEMA.OPTIMIZER_TRACE,就不一定会那么认为了,我们进一步来分析一下OPTIMIZER_TRACE。
INFORMATION_SCHEMA.OPTIMIZER_TRACE
INFORMATION_SCHEMA.OPTIMIZER_TRACE表结构。
CREATE TEMPORARY TABLE `OPTIMIZER_TRACE` (
`QUERY` longtext NOT NULL,
`TRACE` longtext NOT NULL,
`MISSING_BYTES_BEYOND_MAX_MEM_SIZE` int(20) NOT NULL DEFAULT '0',
`INSUFFICIENT_PRIVILEGES` tinyint(1) NOT NULL DEFAULT '0'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;INFORMATION_SCHEMA.OPTIMIZER_TRACE表字段含义。
* QUERY:跟踪的SQL语句。
* TRACE:跟踪信息(JSON格式)。
* MISSING_BYTES_BEYOND_MAX_MEM_SIZE:跟踪信息过长时,被截断的跟踪信息的字节数。
* INSUFFICIENT_PRIVILEGES:执行跟踪语句的用户是否有查看对象的权限。当不具有权限时,该列信息为1且TRACE字段为空。一般出现在调用带有SQL SECURITY DEFINER的视图或者是存储过程的情况下。
跟踪结果解析
在此为了更全面的去认知,这里借用官网提供的案例的数据进行分析。案例参考:https://dev.mysql.com/doc/internals/en/tracing-example.html
相关配置:
* sql_mode = ''
* optimizer_prune_level = 1
QUERY&EXPLAIN
ORDER BY t1.col_int_key,t2.pk ;
# explain
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | t2 | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 91 | 100.00 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-----------------------+TRACE
整个OPTIMIZER_TRACE的重点就是TRACE的JSON树。TRACE中的JSON树大部分都又臭又长,个人更建议使用带有收缩代码格式的编辑器去围观这棵树,能更清晰地理顺这棵树,如下图所示,我们先来看看TRACE的大框架。在TRACE的JSON中有三个步骤构成:join_preparation(准备阶段)、join_optimization(优化阶段)、join_execution(执行阶段)。
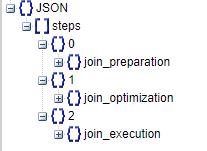
如下图所示中的左JSON树,该树是在基础层级上的展开,每个阶段下面都可以看到有“select# : N”,它表示当前的结构体是在跟踪分析第几个SELECT,因为语句仅仅只有一个SELECT语句,所以示例中的JSON树只有“select# : 1”。如果有多个SELECT就会出现“select# : 2”的情况,比如使用了“SELECT UNION SELECT”,可以参照下图所示中的右JSON树。

join_preparation(准备阶段)

如图示,是join_preparation阶段的JSON树,我们按着steps[0]->steps[1]的顺序,看看在这个示例中准备阶段时都做了什么事情。
step[0].expanded_query:对比下原始语句,可以看到这里的语句进行了格式化,补充了原有语句中隐式的库、表、列名。
step[1].transformations_to_nested_joins:这里进行了转换,将JOIN的ON条件句转换成了WHERE条件句(JOIN_condition_to_WHERE),并输出了新的expanded_query。对照下step[0].expanded_query的语句,新的expanded_query中将原有的ON条件句改写成了WHERE,这就是JOIN_condition_to_WHERE操作导致的。
在语句的补充和转换等操作完成之后,准备阶段结束并进入下一阶段。
join_preparation(优化阶段)
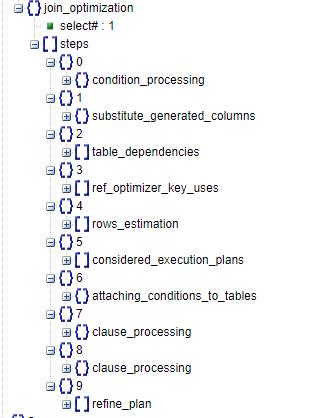
如图示,是join_optimization阶段的JSON树,优化阶段实际上是我们分析OPTIMIZER_TRACE的一个重点阶段,它的步骤非常多也相对复杂,先粗略看看steps下的每个步骤,大致都在做些什么。
steps[0].condition_processing :条件句处理。该步骤对WHERE条件句进行优化处理。
steps[1].substitute_generated_columns :替换虚拟生成列。
steps[2].table_dependencies :梳理表之间的依赖关系。
steps[3].ref_optimizer_key_uses :如果优化器认为查询可以使用ref的话,在这里列出可以使用的索引。
steps[4].rows_estimation :估算表行数和扫描的代价。如果查询中存在range扫描的话,对range扫描进行计划分析及代价估算。
steps[5].considered_execution_plans :对比各可行计划的代价,选择相对最优的执行计划。
steps[6].attaching_conditions_to_tables :添加附加条件,使得条件尽可能筛选单表数据。
steps[7&8].clause_processing :对DISTINCT、GROUP BY、ORDER BY等语句进行优化(每一种语句会产生一个clause_processing 结构体,示例语句中既有排序又有分组,所以会有7、8两个步骤)。
steps[9].refine_plan :优化后的执行计划。
1、condition_processing

条件句处理。该步骤对WHERE条件句进行优化处理。
处理对象:
* condition:优化对象类型。WHERE条件句或者是HAVING条件句(还记得么,准备阶段的ON条件句已经被转换为WHERE条件句了,所以这里不存在ON的条件句)。
* original_condition:优化前的原始语句。
处理步骤:
* 在图中可以看到有三次的语句优化的过程,每步都写明了转换类型(transformation),明确转换做的事情,以及转换之后的结果语句(resulting_condition)
* transformation:转换类型句。这三次的转换分别是equality_propagation(等值条件句转换),constant_propagation(常量条件句转换),trivial_condition_removal(无效条件移除的转换)。
* resulting_condition:转换之后的结果输出。从图示来说,原始的WHERE条件句检测到“=”,进行了等值条件句转换,但是其并不存在常量条件句与无效条件,故在equality_propagation步骤中进行转换之后,后面的步骤中并没有再次变化。
基于该案例,在这里提供一个三阶段都有转换的语句供参考观察,有兴趣的童鞋可以执行观测。
select * from t1 join t2 on t1.pk=t2.pk+1 where t2.pk = 5 and 1 =1 ;
2、table_dependencies

表依赖关系,会列出该语句中涉及到所有的表。
* table:涉及的表名及其别名。
* row_may_be_null:列是否允许为NULL,这里并不是指表中的列属性是否允许为NULL,而是指JOIN操作之后的列是否为NULL。比如说原始语句中如果使用了LEFT JOIN,那么后一张表的row_may_be_null则会显示为true。
* map_bit:表的映射编号,从0开始递增。
* depends_on_map_bits:依赖的映射表,这里主要是在使用STRAIGHT_JOIN进行强制连接顺序或者是LEFT JOIN/RIGHT JOIN有顺序差别时,会在depends_on_map_bits中列出前置表的map_bit。
3、ref_optimizer_key_uses

列出了所有可用的ref类型的索引。如果是使用了组合索引的多个部分,在ref_optimizer_key_uses下会列出多个结构体。单个结构体中会列出单表ref使用的索引及其对应值。
4、rows_estimation
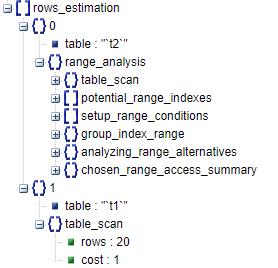
rows_estimation估算需要扫描的记录数,这一段以表对象做为结构体进行展开。如示例中对t2表和t1表分别进行了分析,其中t1表由于没有可用的索引,故其在此阶段的结构体非常简单,仅仅包括了一步table_scan(全表扫描)。t2表则进入range analysis阶段,经历了看上去繁多的步骤,以下依据t2表的range_analysis,解剖这些看似复杂的步骤。
range_analysis
table_scan:全表扫描的行数(rows)以及所需要的代价(cost)。图示可知示例中对t2表如果使用全表扫描,一共要扫描100行,其代价为23.1。

potential_range_indexes:该阶段会列出表中所有的索引并分析其是否可用,并且还会列出索引中可用的列字段。

group_index_range:评估在使用了GROUP BY或者是DISTINCT的时候是否有适合的索引可用。当语句中没有GROUP BY或者是DISTINCT的时候,该结构体下显示chosen='false' & cause = 'not_group_by_or_distinct';如果语句中在多表关联时使用了GROUP BY或DISTINCT时,在该结构体下显示chosen='false' & cause = 'not_single_table';其他情况下会去尝试分析可用的索引(potential_group_range_indexes)并且计算对应的扫描行数及其所需代价。

analyzing_range_alternatives :分析可选方案的代价。包括range_scan_alternatives(range扫描分析)、analyzing_roworder_intersect(index merge分析)两个阶段,分别针对不同的情况进行执行代价的分析,从中选择出更优的执行计划。

* range_san_alternatives:range扫描分析针对所有可用于range扫描的索引进行了代价分析,并根据分析结果确认选择使用的索引。
index:分析的索引名。
ranges:range扫描的条件句范围。
index_dives_for_eq_ranges:是否使用了index dive。这个值会被参数eq_range_index_dive_limit设定值影响,有兴趣的童鞋可以深入研究一下。
rowid_ordered:该range扫描的结果集是否根据PK值进行排序。
using_mrr:是否有使用mrr。
index_only:是否是覆盖索引。
rows:扫描行数。
cost:使用索引的代价。
chosen:是否选择使用该索引。
* analyzing_roworder_insersect:由于示例没有使用index merge,所以在这一段仅仅给出了不使用index merge的原因。如果是语句可以使用index_merge的情况,在该阶段会分析使用index_merge过程中消耗的代价(index_scan_cost、disk_sweep_cost等),并汇总merge的代价确认是否选择使用index_merge以及对应使用的索引。
chosen_range_access_summary:在前一个步骤中分析了各类索引使用的方法及代价,得出了一定的中间结果之后,在summary阶段汇总前一阶段的中间结果确认最后的方案。
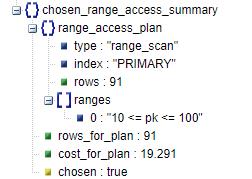
* range_access_plan:range扫描最终选择的执行计划。在该结构体中会给出执行计划的type,使用的索引以及扫描行数。如果range_access_plan.type是“index_roworder_intersect”(即index merge)的话,在该结构体下还会列intersect_of结构体给出index merge的具体信息。
* rows_for_plan:该执行计划的扫描行数。
* cost_for_plan:该执行计划的执行代价。
*chosen:是否选择该执行计划。
5、considered_execution_plans

considered_execution_plans的部分负责对比各可行计划的代价,选择相对最优的执行计划。在这里通过对比STRAIGHT_JOIN和JOIN的结构体来分析一波。
STRAIGHT_JOIN:在原始语句中,使用的是STRAIGHT_JOIN,这就意味着在执行的时候,连接顺序被强制性决定,而不是由优化器选择,这里强制了由t2表驱动t1表进行关联。所以STRAIGHT_JOIN的树中并不像JOIN的树中存在considered_execution_plans[1],因为关联顺序的固定,所以只有一种执行顺序的方案。而在considered_execution_plans[0]中直隶的字段信息与其下直隶的“rest_of_plan”结构体中的字段信息重复度非常高,两者的table对象分别是t2和t1,并且“rest_of_plan”下存在的“plan_prefix”(前置计划)是t1。从字面的英文释义和层级关系分析,considered_execution_plans[N]表示的是可选的执行顺序的一种,由于STRAIGHT_JOIN决定了只能是t2表驱动t1表,所以在该执行计划仅存在considered_execution_plans[0],在该结构体中先解析了t2表并估算其执行代价,再基于t2表解析t1表并估算整个查询的执行代价(在这里只有两张表之间的JOIN,如果是三张表之间的JOIN则可以看到在“rest_of_plan”下还会存在下级的“rest_of_plan”,在下级的“rest_of_plan”中会分析第三张表的代价信息)。
JOIN:将原始语句的STRAIGHT_JOIN修改为普通的JOIN。这时候连接顺序是由优化器计算比较执行代价后决定的,有可能是t1驱动t2,也有可能是t2驱动t1,所以在图示中可以看到considered_execution_plans[0]、considered_execution_plans[1]两种执行顺序。
字段补充释义:

前面也有说明,rest_of_plan的内容与considered_execution_plans的内容非常相近,它们分析的内容其实是一致的,仅仅是表对象不一致,所以在这将这两者合并起来进行说明。下面的说明中会用左图和右图的描述来表示considered_execution_plans的部分和considered_execution_plans.rest_of_plan的部分。
table:分析的表对象名称及其别名。可以看到右图是t2左图是t1,符合我们分析的由t2驱动t1的顺序。
plan_prefix:前置的执行计划(格式:顺序ID:表名)。由于STRAIGHT_JOIN的关系,语句强制性由t2驱动t1,可以看到右图中plan_prefix数组里面并没有内容,而左图中展示了plan_prefix是t2,这个符合我们语句分析中得出的t2表驱动t1表的执行顺序。
best_access_path:当前最优的执行顺序信息结果集,我们看看展开细节图可以发现主要内容实际上是considered_access_paths,这是一个选择比较的过程。根据索引的使用与否以及具体的使用方法可能会产生considered_access_paths[N],例如左图的considered_access_paths[0]是分析通过ref的方式使用PRIMARY索引,considered_access_paths[1]是通过range的方式使用PRIMARY索引。
* access_type表示使用索引的方式,可参照为explain中的type字段,除了前面提到的左图的使用方式,右图中使用的是“scan”(全表扫描或是索引扫描,如果是索引扫描会列出对应的index)方式。根据access_type的不同,在具体的分析过程中列出来的一些字段列就会有所不同。
* 使用了索引的情况类似于左图的considered_access_paths[N]。在considered_access_paths[0]中,由于该索引在ref方式下不可用(usable = false),所以最终没有使用该方案(chosen = false)。在considered_access_paths[1]中,给出了range方式下的扫描行数(rows_to_scan = 91)以及range扫描使用的索引(range_details.used_index = 'PRIMARY')。使用了range扫描的方式之后得到的最终结果集行数(resulting_rows)及该操作应需要的代价(cost),最后的是在选择比较的结果中是否选择了该方式(chosen)。
* 使用了扫描的情况类似于右图的considered_access_paths[0]。该结构体下列出了该表的扫描行数(rows_to_scan),由于这里没有列出index所以能分析出这里的access_type中的“scan”在这里指的是全表扫描。与左图中不同的是,右图还列出了关联过程中是否有使用到job_buffer(using_join_cache)以及使用的次数(buffers_needed),从这两个值中可以了解对于当前的查询来说,join_buffer的配置及使用是否恰当。
condition_filtering_pct:类似于explain中的filtered列,这是一个估算值。
rows_for_plan:该执行计划最终的扫描行数,这里的行数其实也是估算值,是由considered_access_paths的resulting_rows相乘之后再乘以condition_filtering_pct获得。
cost_for_plan:该执行计划的执行代价,由considered_access_paths的cost相加而得。
chosen:是否选择了该执行计划,这个值在左图中并不存在,因为左图只是considered_access_paths的前半部分,直到右图的结束才是一个完整的considered_access_paths[0],执行计划的是否选择,是在整个分析流程都走完了之后,才确定的。
6、attaching_conditions_to_tables

这一步是基于considered_execution_plans中已选执行计划改造原有的where条件句并针对表的增加适当的附加条件便于单表数据的筛选。这部分条件的增改主要是为了便于ICP,但是ICP是否开启并不影响该部分的构造。
original_condition:在准备阶段原始SQL语句以及considered_execution_plans中使用的索引基础上,改写语句,尽可能将原有语句中不能使用索引的条件句绑定到单表中对单表进行数据筛选。
attached_conditions_computation:使用启发式算法计算已使用的索引,如果已使用的索引的访问类型是ref的话,计算使用range方式访问是否能使用组合索引中更多的索引列,如果可以的话,用range的方式替换ref的访问方式。
attached_conditions_summary :针对上述的附加之后的情况汇总。
* table :对象表及其别名。
* attached:附加的条件或者是原语句中能直接下推给单表筛选的条件。
7&8、clause_processing
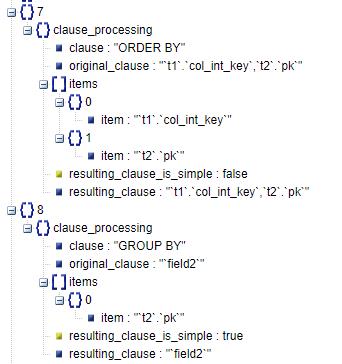
这部分结构体主要是对DISTINCT、GROUP BY、ORDER BY等语句进行优化。
clause:优化语句关键字(DISTINCT、GROUP BY、ORDER BY)。
original_clause:优化对象的原始语句。
items:original_clause中包含的对象。
* item:对象名。
* eq_ref_to_preceding_items:与前置表关联的是否是唯一索引。在这个示例中,并没有这样的情况所以没有列出。如果语句稍微改写一下,将原始查询语句改写为“t1 STRAIGHT_JOIN t2”,让t1去驱动t2表,就发现在分析items[1].item = t2.pk时出现了该字段。这是由于t1与t2通过t2的主键pk列进行关联,这就意味着,t1中的一行数据最多只能在t2中关联出一列,所以在后续优化的结果语句中order by 的t2.pk列被优化掉了,因为这一列已经确认唯一不需要再进行排序。
resulting_clause_is_simple:优化后的结果语句是否是简单语句。
resulting_clause:优化后的结果语句。
9、refine_plan

该阶段展示的是改善之后的执行计划,如图所示只展示了对应的表对象没有其他的字段的话,说明在之前已经确定的执行计划中没有需要再优化的地方,可直接应用。
* table:涉及的表名及其别名。
* pushed_index_condition:可使用到ICP的条件句。
* table_condition_attached:在attaching_conditions_to_tables阶段添加了附加条件的条件语句。
* access_type:优化后的索引访问类型。
join_execution(执行阶段)

join_execution是语句的执行阶段,我们前面提到trace有三大部分构成,其中join_preparation、join_optimization可以分析explain的过程,但是在join_execution阶段,如果分析的语句是explain的话,该阶段的代码是空结构体,只有在真正执行语句之后,该阶段的代码才会有具体的步骤过程。
在执行阶段中,本示例主要经历了图示中的这些步骤:creating_tmp_table(创建临时表)、filesort_information(文件排序信息)、filesort_priority_queue_optimization(文件排序-优先队列优化)、filesort_execution(文件排序执行)、filesort_summary(文件排序汇总信息)。我们接下来一一展开这些步骤进行分析。
1、creating_tmp_table

该阶段根据语句创建临时表,虽然在图示中没有展示,但如果临时表的大小超过了设置的max_heap_table_size或者是tmp_table_size参数的话,会在此步骤后引发多一个步骤:converting_tmp_table_to_ondisk(将临时表落地到磁盘中),有兴趣的童鞋可以改写一下这两个参数值召唤一下这个步骤。。
tmp_table_info:临时表信息 。
* table:临时表的名称。
* row_length:临时表的单行长度。
* key_length:临时表索引长度。
* unique_constraint:是否有使用唯一约束。
* location:表存储位置,比如内存表memory (heap),或者是转换到磁盘的物理表disk (InnoDB)。
* row_limit_estimate:该临时表中能存储的最大行数。
1、filesort
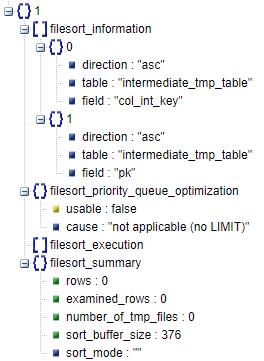
join_execution 阶段在创建临时表之后如果临时表不需要转换为磁盘表的话,即开始对文件排序进行处理。
filesort_information:文件排序信息(如果有多列,filesort_information下会有多个结构体)。
* 排序方式:排序列是升序还是降序。
* table:排序的表对象名。
* field:排序列。
filesort_priority_queue_optimization:优先队列优化排序,一般在使用limit子句的时候会使用优先队列。
* usable:是否有使用。
* cause:没有使用的原因。
filesort_execution:执行文件排序。
filesort_summary:文件排序汇总信息。
* rows:预计扫描行数。
* examined_rows:参与排序的行数。
* number_of_tmp_files:使用临时文件的个数,这个值为0代表全部使用sort_buffer内存排序,否则表示使用了磁盘文件排序。
* sort_buffer_size:使用的sort_buffer的大小。
* sort_mode:排序方式。
结束语
在整个optimizer_trace中我们重点其实就是在跟踪记录TRACE的JSON树,我们通过这棵树中的内容可以具体去分析优化器究竟做了什么事情,进行了哪些选择,是基于什么原因做的选择,选择的结果及依据。这一系列都可以辅助验证我们的一些观点及优化,更好的帮助我们对我们的数据库的实例进行调整。
如果真的能看到这一段,真的要佩服下各位的毅力了。在写这篇文章之初没有想过这篇文章会被我话痨到那么长,当然一方面的原因是optimizer_trace的东西的确很多,文章中仅仅只针对了单个案例来分析,并没有完全覆盖到optimizer_trace中trace记录的所有状态,官网中在这一部分也并没有找到对应的文档是描述optimizer_trace的trace结构体的具体内容的,所以难免还有缺漏的地方,需要后续不断去补充。
希望这篇文章对看到这里的你有所帮助。
| 作者简介
刘云·沃趣科技数据库工程师
熟悉MySQL体系结构、InnoDB存储引擎,丰富的数据库故障诊断、数据库优化经验。
Enjoy MySQL :)
全文完。
叶老师的「MySQL核心优化」大课已升级到MySQL 8.0,扫码开启MySQL 8.0修行之旅吧

以上是关于手把手教你认识OPTIMIZER_TRACE的主要内容,如果未能解决你的问题,请参考以下文章